
一篇包罗万象的场景文本检测算法综述
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
就在明天,极市直播第64期:非受控环境下的表情识别。来自中国科学院深圳先进技术研究院的彭小江副研究员和王锴将为我们介绍分享自注意力策略在这些问题上的两个探索工作,详情点这里。在极市平台后台回复“64”,即可获取直播链接。
相关背景介绍
 文本识别demo
文本识别demo
本文将介绍以下几部分

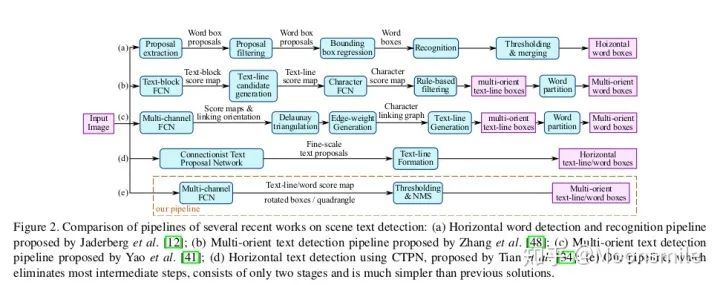
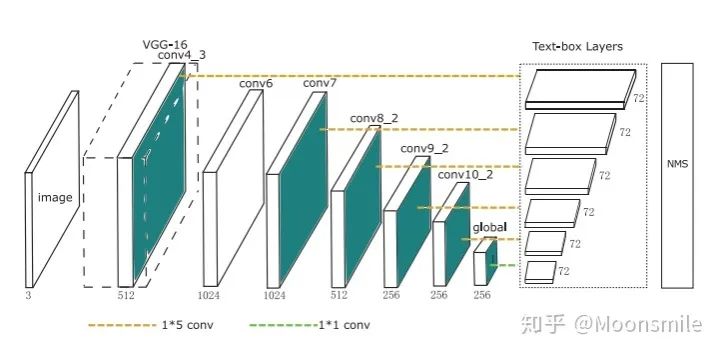
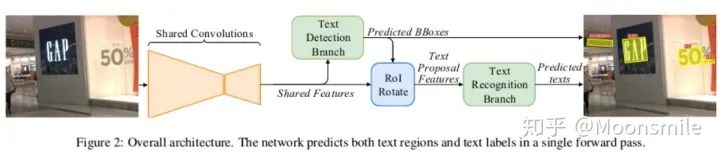
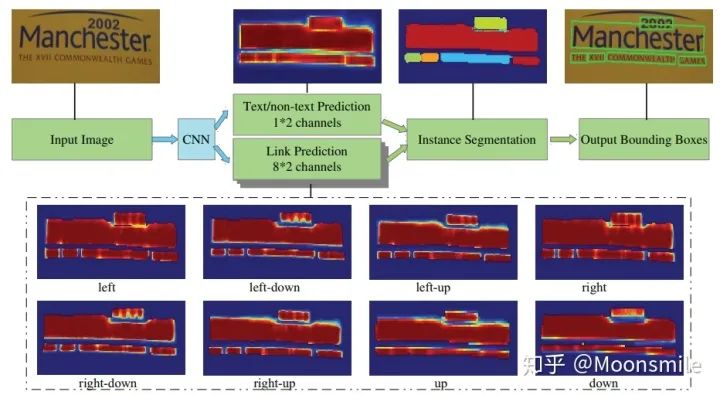
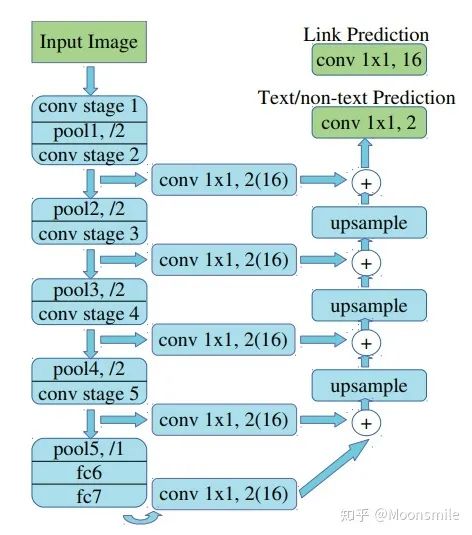
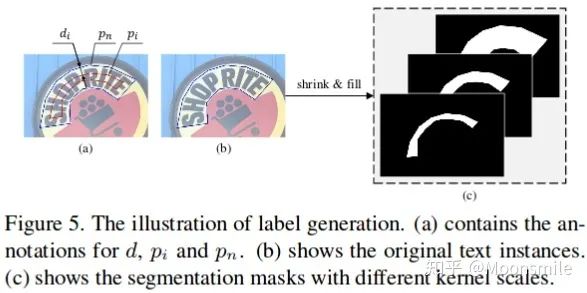
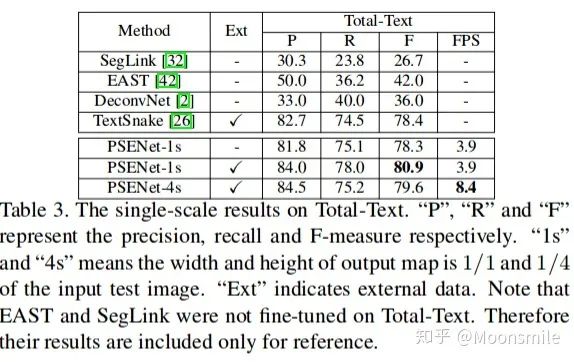
 网络
网络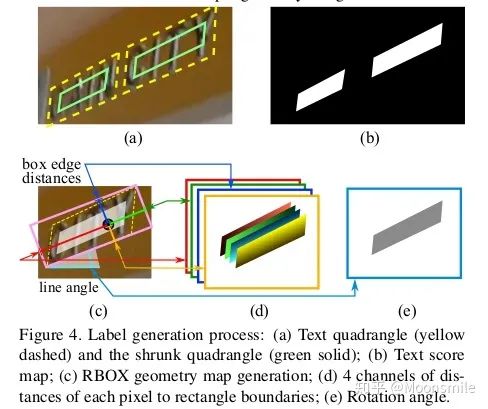
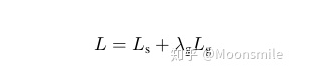
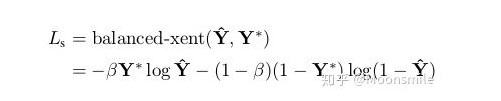
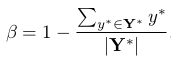

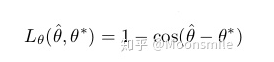
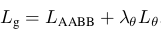
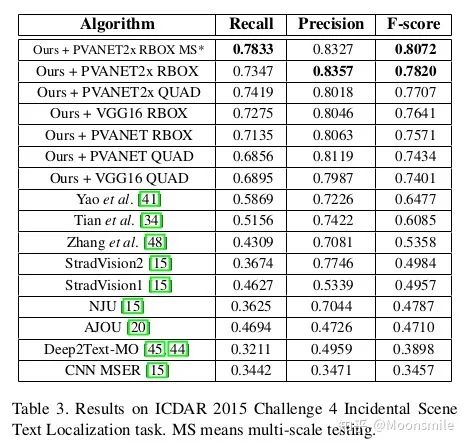
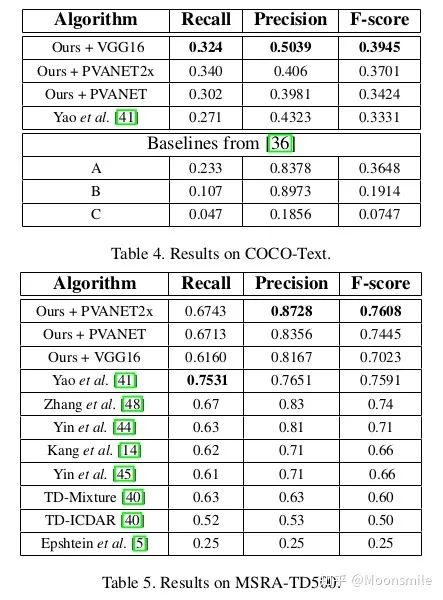
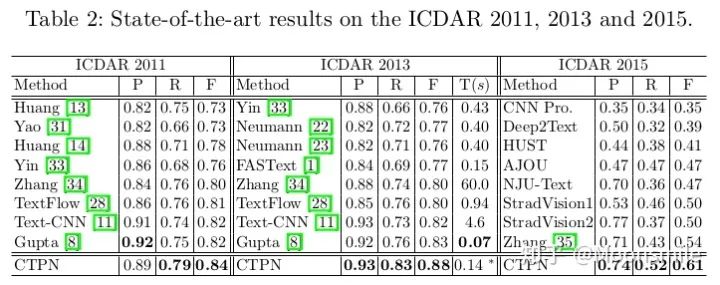
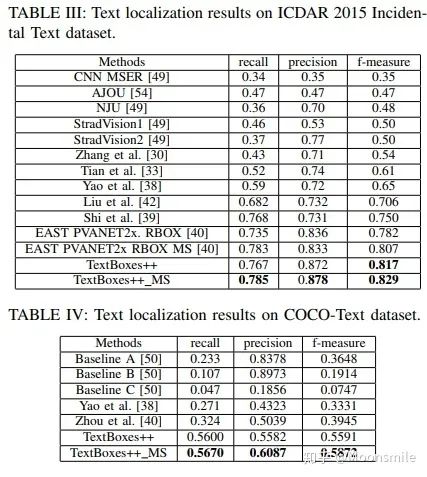
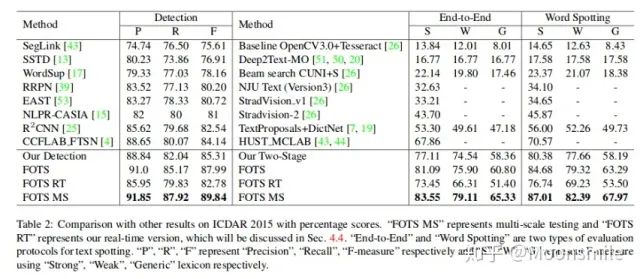
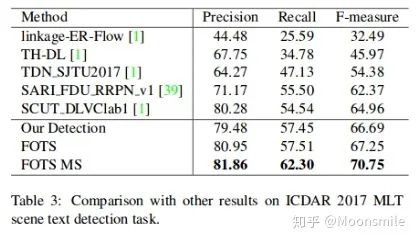
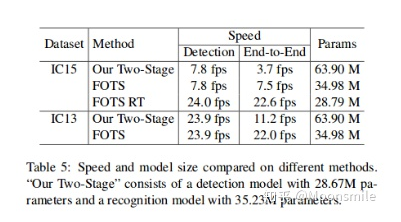
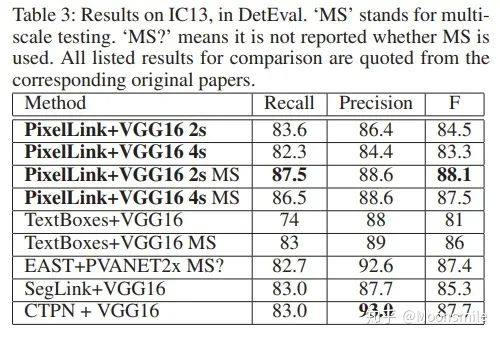
总结分析:
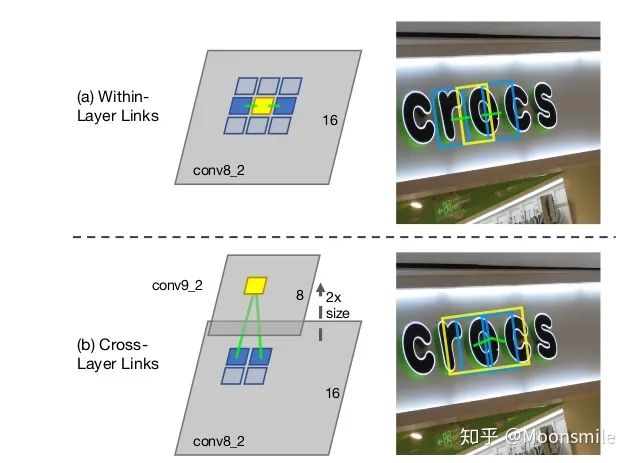
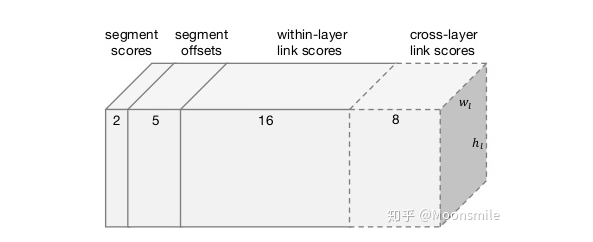
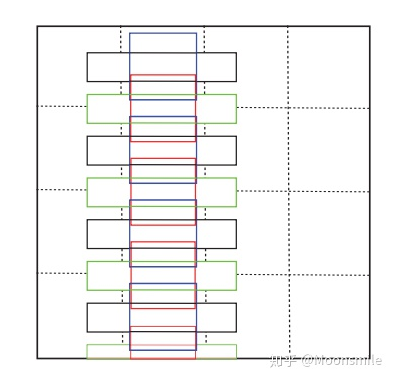
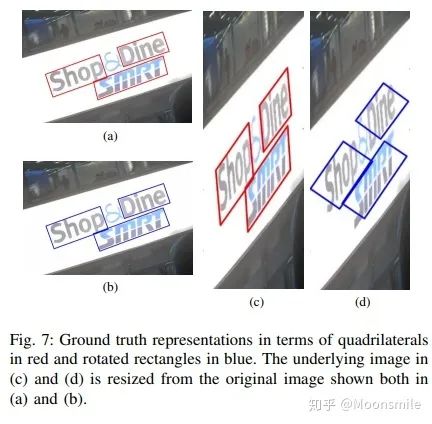
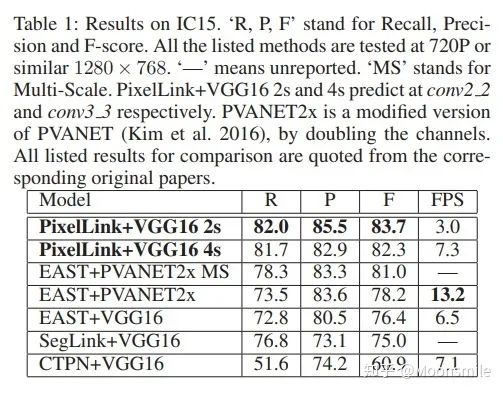
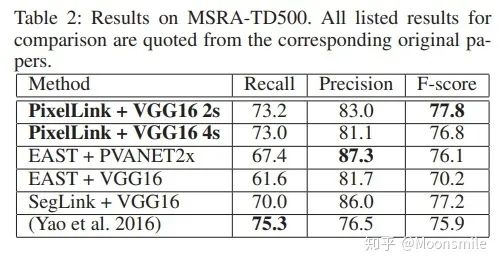
 segment 与 link
segment 与 link











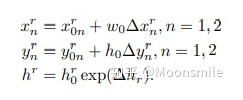


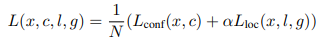











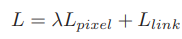







Vedastr:基于PyTorch的场景文本识别工具箱 时隔一年,盘点CVPR 2019影响力最大的20篇论文 51篇最新CV领域综述论文速递!涵盖14个方向:目标检测/图像分割/医学影像/人脸识别等方向

评论