
【Python数据分析基础】: 数据缺失值处理
关键时刻,第一时间送达!

作者:xiaoyu
阅读全文需要10分钟
圣人曾说过:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
再好的模型,如果没有好的数据和特征质量,那训练出来的效果也不会有所提高。数据质量对于数据分析而言是至关重要的,有时候它的意义会在某种程度上会胜过模型算法。
本篇开始分享如何使用Python进行数据分析,主要侧重介绍一些分析的方法和技巧,而对于pandas和numpy等Pyhon计算包的使用会在问题中提及,但不详细介绍。本篇我们来说说面对数据的缺失值,我们该如何处理。文末有博主总结的思维导图。
1 数据缺失的原因
首先我们应该知道:数据为什么缺失?数据的缺失是我们无法避免的,可能的原因有很多种,博主总结有以下三大类:
无意的:信息被遗漏,比如由于工作人员的疏忽,忘记而缺失;或者由于数据采集器等故障等原因造成的缺失,比如系统实时性要求较高的时候,机器来不及判断和决策而造成缺失;
有意的:有些数据集在特征描述中会规定将缺失值也作为一种特征值,这时候缺失值就可以看作是一种特殊的特征值;
不存在:有些特征属性根本就是不存在的,比如一个未婚者的配偶名字就没法填写,再如一个孩子的收入状况也无法填写;
总而言之,对于造成缺失值的原因,我们需要明确:是因为疏忽或遗漏无意而造成的,还是说故意造成的,或者说根本不存在。只有知道了它的来源,我们才能对症下药,做相应的处理。
2 数据缺失的类型
在对缺失数据进行处理前,了解数据缺失的机制和形式是十分必要的。将数据集中不含缺失值的变量称为完全变量,数据集中含有缺失值的变量称为不完全变量。而从缺失的分布来将缺失可以分为完全随机缺失,随机缺失和完全非随机缺失。
完全随机缺失(missing completely at random,MCAR):指的是数据的缺失是完全随机的,不依赖于任何不完全变量或完全变量,不影响样本的无偏性,如家庭地址缺失;
随机缺失(missing at random,MAR):指的是数据的缺失不是完全随机的,即该类数据的缺失依赖于其他完全变量,如财务数据缺失情况与企业的大小有关;
非随机缺失(missing not at random,MNAR):指的是数据的缺失与不完全变量自身的取值有关,如高收入人群不原意提供家庭收入;
对于随机缺失和非随机缺失,直接删除记录是不合适的,原因上面已经给出。随机缺失可以通过已知变量对缺失值进行估计,而非随机缺失的非随机性还没有很好的解决办法。
3 数据缺失的处理方法
重点来了,对于各种类型数据的缺失,我们到底要如何处理呢?以下是处理缺失值的四种方法:删除记录,数据填补,和不处理。
1. 删除记录
优点:
最简单粗暴;
缺点:
牺牲了大量的数据,通过减少历史数据换取完整的信息,这样可能丢失了很多隐藏的重要信息;
当缺失数据比例较大时,特别是缺失数据非随机分布时,直接删除可能会导致数据发生偏离,比如原本的正态分布变为非正太;
这种方法在样本数据量十分大且缺失值不多的情况下非常有效,但如果样本量本身不大且缺失也不少,那么不建议使用。
Python中的使用:
可以使用 pandas 的 dropna 来直接删除有缺失值的特征。
#删除数据表中含有空值的行
df.dropna(how='any')
2. 数据填补
对缺失值的插补大体可分为两种:替换缺失值,拟合缺失值,虚拟变量。替换是通过数据中非缺失数据的相似性来填补,其核心思想是发现相同群体的共同特征,拟合是通过其他特征建模来填补,虚拟变量是衍生的新变量代替缺失值。
替换缺失值
均值插补:
注:此方法虽然简单,但是不够精准,可能会引入噪声,或者会改变特征原有的分布。
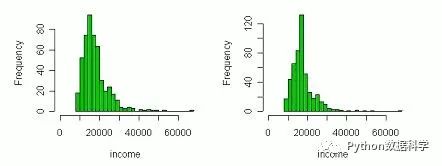
下图左为填补前的特征分布,图右为填补后的分布,明显发生了畸变。因此,如果缺失值是随机性的,那么用平均值比较适合保证无偏,否则会改变原分布。
Python中的使用:
#使用price均值对NA进行填充
df['price'].fillna(df['price'].mean())
df['price'].fillna(df['price'].median())
热卡填补(Hot deck imputation):
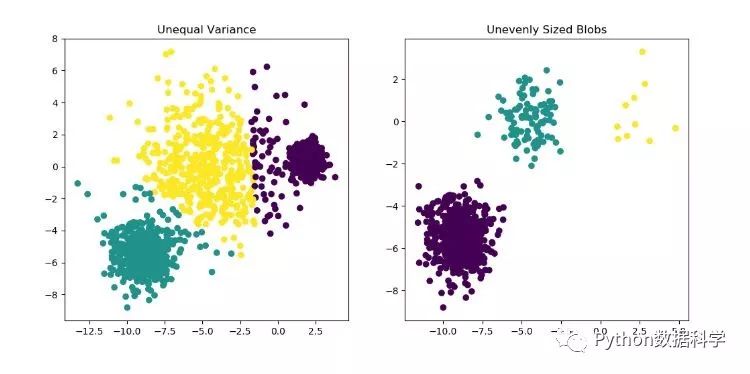
K最近距离邻法(K-means clustering)
注:缺失值填补的准确性就要看聚类结果的好坏了,而聚类结果的可变性很大,通常与初始选择点有关,并且在下图中可看到单独的每一类中特征值也有很大的差别,因此使用时要慎重。
拟合缺失值
拟合就是利用其它变量做模型的输入进行缺失变量的预测,与我们正常建模的方法一样,只是目标变量变为了缺失值。
注:如果其它特征变量与缺失变量无关,则预测的结果毫无意义。如果预测结果相当准确,则又说明这个变量完全没有必要进行预测,因为这必然是与特征变量间存在重复信息。一般情况下,会介于两者之间效果为最好,若强行填补缺失值之后引入了自相关,这会给后续分析造成障碍。
利用模型预测缺失变量的方法有很多,这里仅简单介绍几种。
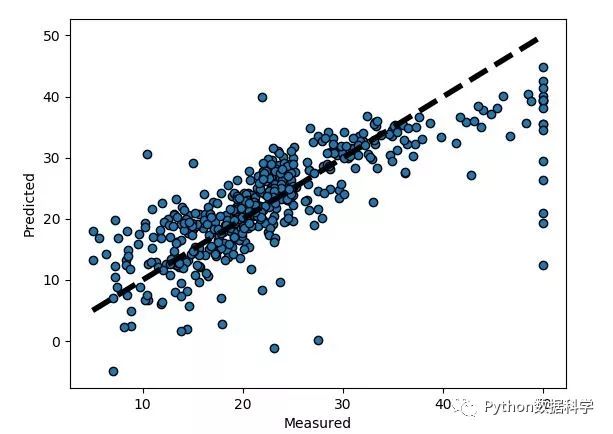
回归预测:
缺失值是连续的,即定量的类型,才可以使用回归来预测。
极大似然估计(Maximum likelyhood):
多重插补(Mutiple imputation):
为每个缺失值产生一套可能的插补值,这些值反映了无响应模型的不确定性;
每个插补数据集合都用针对完整数据集的统计方法进行统计分析;
对来自各个插补数据集的结果,根据评分函数进行选择,产生最终的插补值;
根据数据缺失机制、模式以及变量类型,可分别采用回归、预测均数匹配( predictive mean matching, PMM )、趋势得分( propensity score, PS )、Logistic回归、判别分析以及马尔可夫链蒙特卡罗( Markov Chain Monte Carlo, MCMC) 等不同的方法进行填补。
假设一组数据,包括三个变量Y1,Y2,Y3,它们的联合分布为正态分布,将这组数据处理成三组,A组保持原始数据,B组仅缺失Y3,C组缺失Y1和Y2。在多值插补时,对A组将不进行任何处理,对B组产生Y3的一组估计值(作Y3关于Y1,Y2的回归),对C组作产生Y1和Y2的一组成对估计值(作Y1,Y2关于Y3的回归)。
当用多值插补时,对A组将不进行处理,对B、C组将完整的样本随机抽取形成为m组(m为可选择的m组插补值),每组个案数只要能够有效估计参数就可以了。对存在缺失值的属性的分布作出估计,然后基于这m组观测值,对于这m组样本分别产生关于参数的m组估计值,给出相应的预测,这时采用的估计方法为极大似然法,在计算机中具体的实现算法为期望最大化法(EM)。对B组估计出一组Y3的值,对C将利用Y1,Y2,Y3它们的联合分布为正态分布这一前提,估计出一组(Y1,Y2)。
上例中假定了Y1,Y2,Y3的联合分布为正态分布。这个假设是人为的,但是已经通过验证(Graham和Schafer于1999),非正态联合分布的变量,在这个假定下仍然可以估计到很接近真实值的结果。
注:使用多重插补要求数据缺失值为随机性缺失,一般重复次数20-50次精准度很高,但是计算也很复杂,需要大量计算。
随机森林:
def set_missing_ages(df):
# 把已有的数值型特征取出来丢进Random Forest Regressor中
age_df = df[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
# 乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
# y即目标年龄
y = known_age[:, 0]
# X即特征属性值
X = known_age[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1:])
# print predictedAges
# 用得到的预测结果填补原缺失数据
df.loc[ (df.Age.isnull()), 'Age' ] = predictedAges
return df, rfr虚拟变量
data_train['CabinCat'] = data_train['Cabin'].copy()
data_train.loc[ (data_train.CabinCat.notnull()), 'CabinCat' ] = "No"
data_train.loc[ (data_train.CabinCat.isnull()), 'CabinCat' ] = "Yes"
fig, ax = plt.subplots(figsize=(10,5))
sns.countplot(x='CabinCat', hue='Survived',data=data_train)
plt.show()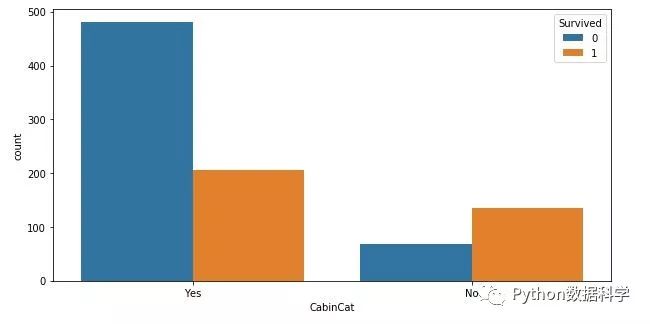
下面可以通过一行代码清楚看到衍生的虚拟变量。
data_train[['Cabin','CabinCat']].head(10)
3. 不处理
4 总结
总而言之,大部分数据挖掘的预处理都会使用比较方便的方法来处理缺失值,比如均值法,但是效果上并一定好,因此还是需要根据不同的需要选择合适的方法,并没有一个解决所有问题的万能方法。具体的方法采用还需要考虑多个方面的:
数据缺失的原因;
数据缺失值类型;
样本的数据量;
数据缺失值随机性等;
关于数据缺失值得思维导图:
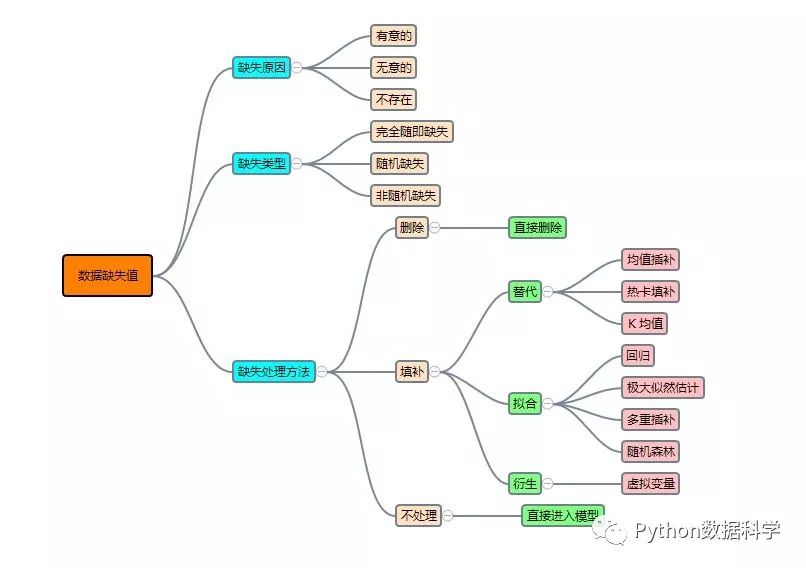
如果大家有任何好的其他方法,欢迎补充。
参考:
http://www.restore.ac.uk/PEAS/imputation.php
https://blog.csdn.net/lujiandong1/article/details/52654703
http://blog.sina.com.cn/s/blog_4b0f1da60101d8yb.html
https://www.cnblogs.com/Acceptyly/p/3985687.html
推荐阅读:
【1】【Kaggle入门级竞赛top5%排名经验分享】— 分析篇
【6】转行数据分析的亲身经历