
【Python】详解pandas缺失值处理
本篇详解pandas中缺失值(Missing data handling)处理常用操作。缺失值处理常用于数据分析数据清洗阶段;Pandas中将如下类型定义为缺失值:NaN: ‘’, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’,‘-NaN’, ‘-nan’, ‘1.#IND’, ‘1.#QNAN’, ‘<NA>’, ‘N/A’, ‘NA’,‘NULL’, ‘NaN’, ‘n/a’, ‘nan’, ‘null’,None
1、pandas中缺失值注意事项
pandas和numpy中任意两个缺失值不相等(np.nan != np.nan)
下图中两个NaN不相等: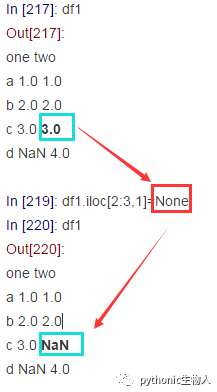
In [224]: df1.iloc[3:,0].values#取出'one'列中的NaN
Out[224]: array([nan])
In [225]: df1.iloc[2:3,1].values#取出'two'列中的NaN
Out[225]: array([nan])
In [226]: df1.iloc[3:,0].values == df1.iloc[2:3,1].values#两个NaN值不相等
Out[226]: array([False])
pandas读取文件时那些值被视为缺失值
NaN: ‘’, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’,‘-NaN’, ‘-nan’, ‘1.#IND’, ‘1.#QNAN’, ‘<NA>’, ‘N/A’, ‘NA’,‘NULL’, ‘NaN’, ‘n/a’, ‘nan’, ‘null’,None
2、pandas缺失值操作
pandas.DataFrame中判断那些值是缺失值:isna方法
#定义一个实验DataFrame
In [47]: d = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
In [48]: df = pd.DataFrame(d)
In [49]: df
Out[49]:
one two
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
d NaN 4.0
In [120]: df.isna()#返回形状一样的bool值填充DataFrame
Out[120]:
one two
a False False
b False False
c False False
d True False
pandas.DataFrame中删除包含缺失值的行:dropna(axis=0)
In [67]: df
Out[67]:
one two
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
d NaN 4.0
In [68]: df.dropna()#默认axis=0
Out[68]:
one two
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
pandas.DataFrame中删除包含缺失值的列:dropna(axis=1)
In [72]: df.dropna(axis=1)
Out[72]:
two
a 1.0
b 2.0
c 3.0
d 4.0
pandas.DataFrame中删除包含缺失值的列和行:dropna(how='any')
In [97]: df['three']=np.nan#新增一列全为NaN
In [98]: df
Out[98]:
one two three
a 1.0 1.0 NaN
b 2.0 2.0 NaN
c 3.0 3.0 NaN
d NaN 4.0 NaN
In [99]: df.dropna(how='any')
Out[99]:
Empty DataFrame#全删除了
Columns: [one, two, three]
Index: []
pandas.DataFrame中删除全是缺失值的行:dropna(axis=0,how='all')
In [101]: df.dropna(axis=0,how='all')
Out[101]:
one two three
a 1.0 1.0 NaN
b 2.0 2.0 NaN
c 3.0 3.0 NaN
d NaN 4.0 NaN
pandas.DataFrame中删除全是缺失值的列:dropna(axis=1,how='all')
In [102]: df.dropna(axis=1,how='all')
Out[102]:
one two
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
d NaN 4.0
pandas.DataFrame中使用某个值填充缺失值:fillna(某个值)
In [103]: df.fillna(666)#使用666填充
Out[103]:
one two three
a 1.0 1.0 666.0
b 2.0 2.0 666.0
c 3.0 3.0 666.0
d 666.0 4.0 666.0
pandas.DataFrame中使用前一列的值填充缺失值:fillna(axis=1,method='ffill')
#后一列填充为fillna(axis=1,method=bfill')
In [109]: df.fillna(axis=1,method='ffill')
Out[109]:
one two three
a 1.0 1.0 1.0
b 2.0 2.0 2.0
c 3.0 3.0 3.0
d NaN 4.0 4.0
pandas.DataFrame中使用前一行的值填充缺失值:fillna(axis=0,method='ffill')
#后一行填充为fillna(axis=1,method=bfill')
In [110]: df.fillna(method='ffill')
Out[110]:
one two three
a 1.0 1.0 NaN
b 2.0 2.0 NaN
c 3.0 3.0 NaN
d 3.0 4.0 NaN
pandas.DataFrame中使用字典传值填充指定列的缺失值
In [112]: df.fillna({'one':666})#填充one列的NaN值
Out[112]:
one two three
a 1.0 1.0 NaN
b 2.0 2.0 NaN
c 3.0 3.0 NaN
d 666.0 4.0 NaN
In [113]: df.fillna({'three':666})
Out[113]:
one two three
a 1.0 1.0 666.0
b 2.0 2.0 666.0
c 3.0 3.0 666.0
d NaN 4.0 666.0
3、参考资料
https://pandas.pydata.org/pandas-docs/stable/reference/frame.html?highlight=missing
-END-
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码
评论