
数据分析必知必会,缺失值处理技巧大全!(附Python代码)
点击上方“数据管道”,选择“置顶星标”公众号
干货福利,第一时间送达

1、缺失查看
import pandas as pd# 统计缺失值数量missing=data.isnull().sum().reset_index().rename(columns={0:'missNum'})# 计算缺失比例missing['missRate']=missing['missNum']/data.shape[0]# 按照缺失率排序显示miss_analy=missing[missing.missRate>0].sort_values(by='missRate',ascending=False)# miss_analy 存储的是每个变量缺失情况的数据框
import matplotlib.pyplot as pltimport pylab as plfig = plt.figure(figsize=(18,6))plt.bar(np.arange(miss_analy.shape[0]), list(miss_analy.missRate.values), align = 'center',color=['red','green','yellow','steelblue'])plt.title('Histogram of missing value of variables')plt.xlabel('variables names')plt.ylabel('missing rate')# 添加x轴标签,并旋转90度plt.xticks(np.arange(miss_analy.shape[0]),list(miss_analy['index']))pl.xticks(rotation=90)# 添加数值显示for x,y in enumerate(list(miss_analy.missRate.values)):plt.text(x,y+0.12,'{:.2%}'.format(y),ha='center',rotation=90)plt.ylim([0,1.2])plt.show()
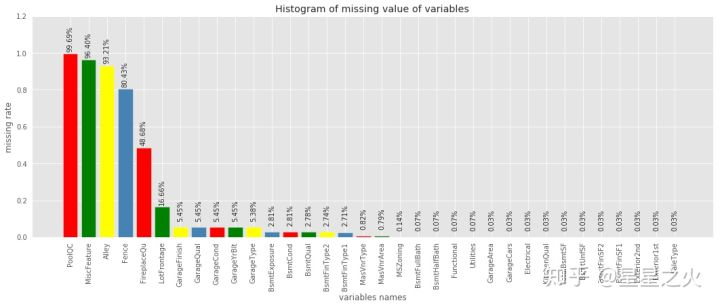
2、缺失处理
方式1:删除
func: df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)# 1、删除‘age’列df.drop('age', axis=1, inplace=True)# 2、删除数据表中含有空值的行df.dropna()# 3、丢弃某几列有缺失值的行df.dropna(axis=0, subset=['a','b'], inplace=True)
# 去掉缺失比例大于80%以上的变量data=data.dropna(thresh=len(data)*0.2, axis=1)
方式2:常量填充
# 均值填充data['col'] = data['col'].fillna(data['col'].means())# 中位数填充data['col'] = data['col'].fillna(data['col'].median())# 众数填充data['col'] = data['col'].fillna(stats.mode(data['col'])[0][0])
from sklearn.preprocessing import Imputerimr = Imputer(missing_values='NaN', strategy='mean', axis=0)imputed_data =pd.DataFrame(imr.fit_transform(df.values),columns=df.columns)imputed_data
方式3:插值填充
# interpolate()插值法,缺失值前后数值的均值,但是若缺失值前后也存在缺失,则不进行计算插补。df['a'] = df['a'].interpolate()# 用前面的值替换, 当第一行有缺失值时,该行利用向前替换无值可取,仍缺失df.fillna(method='pad')# 用后面的值替换,当最后一行有缺失值时,该行利用向后替换无值可取,仍缺失df.fillna(method='backfill')#用后面的值替换
方式4:KNN填充
from fancyimpute import KNNfill_knn = KNN(k=3).fit_transform(data)data = pd.DataFrame(fill_knn)
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressordef knn_filled_func(x_train, y_train, test, k = 3, dispersed = True):# params: x_train 为目标列不含缺失值的数据(不包括目标列)# params: y_train 为不含缺失值的目标列# params: test 为目标列为缺失值的数据(不包括目标列)if dispersed:knn= KNeighborsClassifier(n_neighbors = k, weights = "distance")else:knn= KNeighborsRegressor(n_neighbors = k, weights = "distance")knn.fit(x_train, y_train)return test.index, knn.predict(test)
方式5:随机森林填充
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifierdef knn_filled_func(x_train, y_train, test, k = 3, dispersed = True):# params: x_train 为目标列不含缺失值的数据(不包括目标列)# params: y_train 为不含缺失值的目标列# params: test 为目标列为缺失值的数据(不包括目标列)if dispersed:rf= RandomForestRegressor()else:rf= RandomForestClassifier()rf.fit(x_train, y_train)return test.index, rf.predict(test)
3、缺失衍生
4、总结
评论