
[读论文]语言视觉多模态预训练模型 ViLBERT
论文地址:https://arxiv.org/abs/1908.02265
代码实现:https://github.com/facebookresearch/vilbert-multi-task
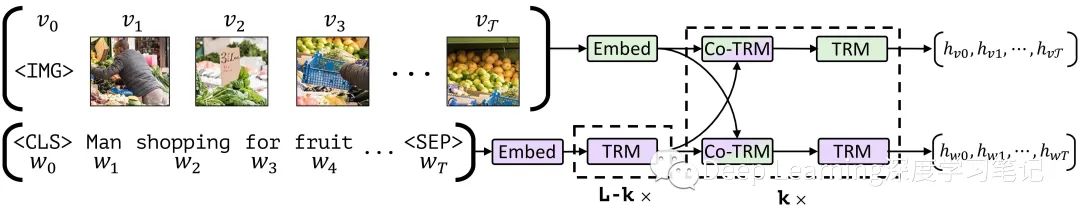 图1.ViLBERT 模型由视觉(绿色)和语言(紫色) 组成,它们通过 co-attentional transformer layer 进行互动。这种结构允许每种模式有不同的深度,并通过共同注意力实现稀疏的互动。带有乘数下标的虚线框表示重复的块。
图1.ViLBERT 模型由视觉(绿色)和语言(紫色) 组成,它们通过 co-attentional transformer layer 进行互动。这种结构允许每种模式有不同的深度,并通过共同注意力实现稀疏的互动。带有乘数下标的虚线框表示重复的块。
1. Introduction
针对视觉和语言任务的预训练 + 迁移学习( pretrain-then-transfer )方法被广泛用于计算机视觉和自然语言处理,因为在大规模数据源上训练的大型、公开可用的模型的易用性和强大表现能力,它们已成为事实上的标准。在这些领域,预训练的模型可以为目标任务提供有用的信息。为此,作者开发一个通用的视觉基础模型,该模型可以学习这些联系并在广泛的视觉和语言任务中运用(即寻求对视觉基础的预训练模型)。
为了学习这些联合视觉语言表示,作者希望在自监督学习取得成功,这些成功通过训练模型执行“代理”任务,从大型未标记的数据源中捕获了丰富的语义和结构信息。这些代理任务利用结构在数据中自动生成监督任务(例如着色图像或重建文本中的掩码词 )。虽然计算机视觉社区内的工作展现出越来越大的前景,但迄今为止,自监督学习的最大影响是通过 ELMo 、BERT 和 GPT 等语言模型,这些模型已经在许多 NLP 任务上创造了新的上限。要通过类似的方法学习视觉基础,必须确定一个合适的数据源,其中视觉和语言之间可以保持一致。在这项工作中,作者选用了最近发布的 Conceptual Captions 数据集,该数据集由约 330 万幅图像组成,为网络上支持 alt-text 的图片和其弱关联描述性标题。
作者提出了一个联合模型,用于从成对的视觉语言数据中学习与任务无关的视觉基础,作者称为 Vision & Language BERT(简称 ViLBERT )。该方法扩展了最近开发的 BERT 语言模型,以联合推理文本和图像。关键技术创新是为视觉和语言处理引入单独的流,通过共同注意的 Transformer 层(co-attentional transformer layers)进行通信。这种结构可以适应每种模态的不同处理需求,并提供不同表示深度的模态之间的交互。在实验中证明了这种结构优于单流统一模型。
类似于 BERT 中的训练任务,训练的两个代理任务上:在给定未屏蔽输入的情况下预测屏蔽词和图像区域的语义,以及预测图像和文本段是否对应。作者将预训练模型作为四个既定的视觉和语言基础任务( visual question answering , visualcommonsense reasoning, referring expressions, caption-based image retrieval)四项任务均达到 SOTA 。与使用单独的预训练视觉和语言模型的任务特定基线相比这些任务提高了 2 到 10 个百分点。此外,该结构很容易针对这些任务进行修改——作为跨多个视觉和语言任务的视觉基础的共同基础。
2. Approach
在这一节中,首先简要地总结了BERT语言模型,然后描述了作者如何扩展它以联合表示视觉和语言数据
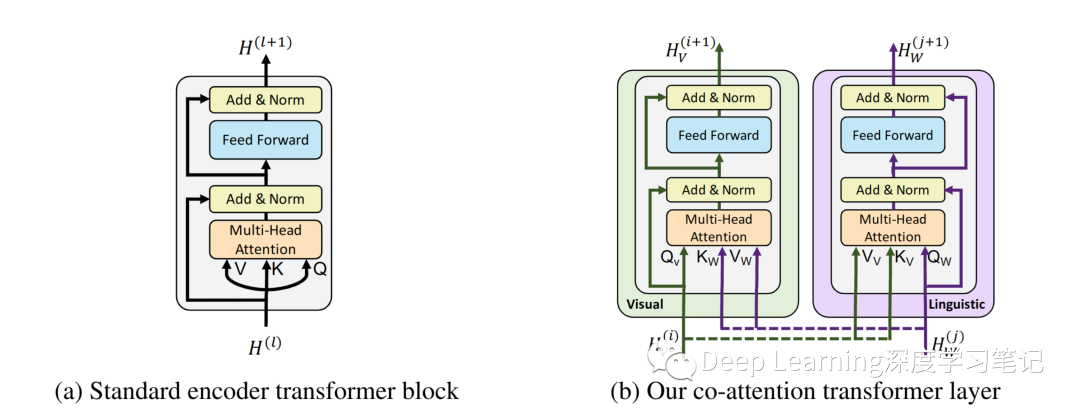 图2.基于 transformer 架构的 co-attention 机制。通过在多头注意力中交换键值对,这种结构使视觉参与的语言特征能够被纳入视觉表示中(反之亦然)
图2.基于 transformer 架构的 co-attention 机制。通过在多头注意力中交换键值对,这种结构使视觉参与的语言特征能够被纳入视觉表示中(反之亦然)
2.1 Preliminaries: Bidirectional Encoder Representations from Transformers (BERT)
BERT 模型是一个基于注意力的双向语言模型。当在大型语言语料库上进行训练时,BERT 已被证明对多种自然语言处理任务的迁移学习非常有效。
BERT 模型对 Word Token 序列 进行操作,这些 Token 被映射到学习的编码上并通过 “encoder-style” transformer blocks 以产生最终表示: 。设 是一个矩阵,其中第 行 对应于第 层之后的中间表示。提取论文( Attention is all you need ) 中发现的一些内部细节,图 2a 中 single encoder-style transformer block 的计算,该块由一个 multi-headed attention block 和一个小的全连接网络组成,两者都包裹在残差中。该中间层的表示 用于计算三个度量—— Q、K 和 V(对应于 multi-headed attention bloc 的 queries, keys, values )。具体来说,queries 和 keys 之间的点积相似度(dot-product similarity )决定了 values 向量上的注意力分布(attentional distributions over value vectors)。得到的权重平均值向量构成了注意力块的输出。作者修改了这个以 query 为条件的键值注意机制,为 ViLBERT 开发了一个多模态协同注意转换器模块( multi-modal co-attentional transformer module )
Text Representation:BERT 对由词汇词和一小组特殊标记(SEP、CLS 和 MASK)组成的离散标记序列进行操作。对于给定的 Token ,输入表示a sum of a token-specific learned embedding 以及 encodings for position(句子中符号的索引) 和 segment(如果存在多个,就标记符号句子的索引,the index of the token's sentence)。 Training Tasks and Objectives:BERT 模型在大型语言语料库上进行端到端的训练,有两个任务:masked language modelling 以及 next sentence prediction。 masked language modelling 任务:随机将输入标记分成不相交的集合,对应于 Mask Token: 和 Observed Token: (大约 15% 的 Token 被 Mask)。对于 Mask Token :80% 的情况下会被特殊的 MASK 标记替换,10% 是随机单词,10% 是未更改的。然后训练 BERT 模型以在给定 Observed Token 的情况下预测这些 Mask Token 。具体而言,线性层将每个索引(例如:)的最终表示映射到词汇表的分布上,模型在交叉熵损失下训练。 next sentence prediction 任务:BERT 模型按照格式 传递两个文本段 A 和 B。并被训练来预测原文本中的 B 是否跟随 A。具体来说,在 CLS token(即 )的最终表示的线性层上训练,以最小化此标签上的二元交叉熵损失
2.2 ViLBERT: Extending BERT to Jointly Represent Images and Text
受 BERT 在语言建模方面的成功启发,作者希望开发类似的模型和训练任务,从成对的数据中学习语言和视觉内容的联合表示。
一种直接的方法是对 BERT 做最小的改动--从预先训练的 BERT 模型开始,通过聚类简单地将视觉输入的空间离散化,将这些视觉 "Token"与文本输入完全一样。但这种结构有一些缺点。首先,**初始聚类可能会导致离散化错误,并失去重要的视觉细节。**其次,它对来自两种模式的输入进行了相同的处理,忽略了它们可能需要不同语义层次的处理,这是因为它们固有的复杂性或其输入表示的初始抽象层次。例如,图像区域可能比句子中的单词有更弱的关系,而视觉特征本身往往已经是一个非常深入的网络的输出。最后,强迫预训练的权重去适应大量的额外的视觉 "Token" 可能会损害的 BERT 语言模型。相反,作者开发了一个双流架构,分别对每种模式进行建模,并通过一小套基于注意力的互动来融合它们。这种方法允许每个模态的网络深度不同,并使不同深度的跨模态连接成为可能。
ViLBERT 的模型如图 1 所示,由两个并行的 BERT 式模型组成,这些模型在图像区域和文本段上运行。每个流都是一系列 transformer blocks (TRM) 和作者新提出的 co-attentional transformer layers (Co-TRM),引入它们以实现模式之间的信息交换。给定一个图像 ,表示为一组区域特征 和一个文本输入 , 模型输出最终表示为 和 。但两个流之间的交换仅限于特定的层并且在与视觉特征互动之前,文本流有更多的处理,这与直觉相吻合,即视觉特征已经十分具体,即与句子中的单词相比,需要有限的上下文汇总。
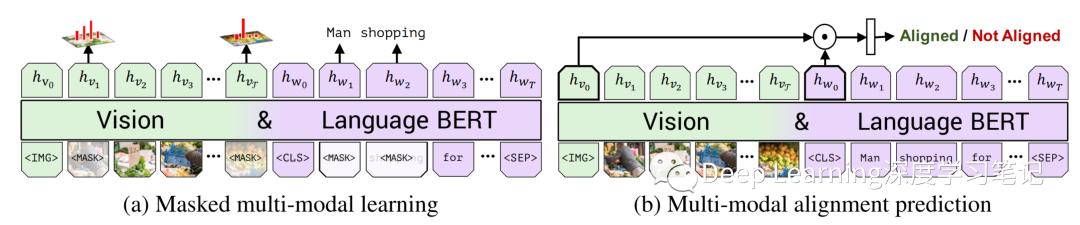 图 3. 在两个训练任务下,在 Conceptual Captions 数据集上训练 ViLBERT 以学习视觉基础。在 masked multi-modal learning 中,模型必须根据观察到的输入为 Mask 输入重建图像区域类别或单词。在 multi-modal alignment prediction 中,该模型必须预测标题是否描述了图像内容。
图 3. 在两个训练任务下,在 Conceptual Captions 数据集上训练 ViLBERT 以学习视觉基础。在 masked multi-modal learning 中,模型必须根据观察到的输入为 Mask 输入重建图像区域类别或单词。在 multi-modal alignment prediction 中,该模型必须预测标题是否描述了图像内容。
Co-Attentional Transformer Layers
给定中间视觉和语言表示 和 ,该模块像在标准转换器块中一样计算query, key, 和 value 矩阵。然而,来自每个模态的 keys 和 values 作为输入传递到另一个模态的 multi-headed attention block 。因此,attention block 为以另一个为条件的每个模态产生 attention-pooled features——实际上在视觉流中执行图像条件语言 attention,在语言流中执行语言条件图像 attention。后者模仿在视觉和语言模型中发现的常见注意力机制。Transformer 块的其余部分与之前一样进行,包括与初始表示的残差产生多模态特征。一般来说,视觉和语言的共同注意不是一个新想法并且类似的工作已经证明了类似的 co-attentional transformer 结构在视觉问答(VQA)任务中的有效性。
Image Representations:作者通过从预训练的目标检测网络中提取边界框及其视觉特征来生成图像区域特征。与文本中的单词不同,图像区域缺乏自然排序。作者改为编码空间位置,从区域位置(标准化的左上角和右下角坐标)和覆盖的图像区域的比例构建一个 5 维向量。然后将其投影以匹配视觉特征的维度并将它们相加。作者用代表整个图像的特殊 IMG token 标记图像区域序列的开始(即具有对应于整个图像的空间编码的平均池化视觉特征) Training Tasks and Objectives:与上一节描述的相似,作者考虑了两个预训练任务:masked language modelling 以及 next sentence prediction。 masked language modelling(如图 3a 所示):遵循标准 BERT 中的 masked language modelling ——标记 Mask 大约为 15% 的单词和图像区域输入,并在给定剩余输入的情况下对模型进行重构。对于标记 Mask 的图像区域的图像特征在 90% 的情况下被归零,10% 的情况下未改变。掩码文本输入的处理方式与 BERT 相同。该模型不是直接回归掩蔽特征值,而是预测相应图像区域的语义类分布。为了对此进行监督,作者从特征提取中使用的相同预训练检测模型中获取该区域的输出分布。作者训练模型以最小化这两个分布之间的 KL 散度。这个选择反映了这样一种观念,即语言通常只识别视觉内容的高级语义,不太可能重建准确的图像特征。此外,应用回归损失可能难以平衡由标记 Mask 的图像区域和文本输入引起的损失。 multi-modal alignment task (如图 3b 所示):模型以图像-文本对的形式呈现为 并且预测图像和文本是否对齐,即文本是否描述了图像。我们将输出 和 作为视觉和语言输入的整体表示。借用视觉和语言模型的另一种常见结构,作者将整体表示计算为 和 之间的元素乘积,并学习一个线性层来进行二值预测图像和文本是否对齐。然而,Conceptual Captions 数据集仅包含对齐的图像-字幕对。为了生成图像-字幕对的反例,作者随机用另一个图像或字幕替换。
3. Experimental Settings
3.1 Training ViLBERT
为了训练完整的 ViLBERT 模型,作者应用了第 2.2 节中介绍的训练任务。Conceptual Captions是一个由330万个图像-标题对组成的集合,自动地从支持 alt-text 的网络图像中爬取。自动收集和清理过程会留下一些噪音,“captions”有时候不符合人类正常表达或缺乏细节(例如“演员参加电影节的首映式”)。然而,它呈现了巨大的视觉内容多样性,并作为目的的数据集。由于在作者下载数据时某些链接已损坏,因此模型使用了大约 310 万个图像字幕对进行了训练。
实现细节:作者使用在 BookCorpus 和英文维基百科上预训练的 BERT 语言模型作为初始化 ViLBERT 模型的 linguistic stream。具体来说,作者使用 模型,它有 12 层 transformer blocks,每个块的隐藏状态大小为 762 和 12 个 attention heads。由于担心过度训练时间,作者选择使用 BASE 模型,但发现更强大的 模型可能会进一步提高性能。作者使用在 Visual Genomedataset 上预训练的 Faster R-CNN(使用 ResNet-101 为主干网络)提取区域特征。作者选择分类检测概率超过置信阈值的区域,并保持 10 到 36 个高阈值框。对于每个选定的区域 , 定义为来自该区域的平均池化卷积特征。视觉流中的 Transformer 和 co-attentional Transformer 块的隐藏状态大小为 1024 和 8 个 attention heads 。作者在 8 个 Titan X GPU 上训练,总批大小为 512 为 10 个时期。并使用 Adam 优化器,初始学习率为 1e-4。作者使用预热线性衰减学习率方法来训练模型。两个训练任务损失的权重相等
 图4:作者在实验中把 ViLBERT 转换为到视觉和语言任务
图4:作者在实验中把 ViLBERT 转换为到视觉和语言任务
3.2 Vision-and-Language Transfer Tasks
作者将预训练的 ViLBERT 模型转移到一组四个既定的视觉和语言任务(参见图 4 中的示例)和一个诊断任务。作者遵循微调策略(fine-tuning strategy),修改预训练的基础模型以执行新任务,然后端到端地训练整个模型。在所有情况下,修改都是十分微小的——通常相当于学习一个分类层。这与社区内为这些任务中的每一项都专门设计模型所做的重大努力形成鲜明对比。下面描述了每个任务的问题、数据集、模型修改和训练目标。
Visual Question Answering (VQA):VQA 任务需要回答有关图像的自然语言问题。作者对 VQA 2.0 数据集进行训练和评估,该数据集包含 110 万个关于 COCO 图像的问题,每个问题有 10 个答案。为了在 VQA 上fine-tune ViLBERT,作者在图像和文本表示的元素乘积 和 之上学习了一个两层 MLP,将此表示映射到 3,129 个可能的答案。作者将 VQA 视为多标签分类任务——根据每个答案与 10 个人类答案的相关性,为每个答案分配一个软目标分数。然后,作者在最多 20 个 epoch 内使用 256 的 batch size 对软目标分数进行二元交叉熵损失训练。作者使用初始学习率为 4e-5 的 Adam 优化器。在推理时简单地取一个 softmax 进行归一化。 Visual Commonsense Reasoning (VCR):给定一张图像,VCR 任务提出了两个问题——视觉问答()和答案证明()——两者都是多项选择题。整体设置()要求选择的答案和选择的基本原理都是正确的。VCR 数据集由 290k 多选 QA 问题由 110k 电影场景衍生。与 VQA 数据集不同,VCR 将目标标签集成到语言中,提供直接的基础监督并明确排除了指代表达。为了对这个任务进行 fine-tuning,作者将问题和每个可能的响应连接起来,形成四个不同的文本输入,并将每个输入与图像一起通过 ViLBERT。学习一个线性层来预测每一对的分数。最终预测是对这四个分数的 softmax,并交叉熵损失下训练,20 个 epoch 且批量大小为 64,初始学习率为 2e-5。 Grounding Referring Expressions:根据自然语言参考对图像区域进行定位。作者对 RefCOCO+ 数据集进行训练和评估。该任务的一种常见方法是根据给定参考的一组图像区域建议进行排序。作者使用在 COCO 数据集上预训练的 Mask R-CNN 。对于 fine-tuning,作者将每个图像区域的最终表示 传递到学习的线性层中以预测匹配分数。作者通过计算 IoU 并将阈值设置为 0.5 来标记每个预测框。使用二元交叉熵损失训练,epoch 为 20 ,批量大小为 256,初始学习率为 4e-5。在推理时,作者使用得分最高的区域作为预测值。 Caption-Based Image Retrieval:基于标题的图像检索是指从给定的描述其内容的标题中识别图像的任务。作者在 Flickr30k 数据集上进行训练和评估,该数据集由来自 Flickr 的 31,000 张图片组成,每张图片有五个标题。作者使用 1,000 张图片进行验证和测试,其余的进行训练。这些标题在视觉内容上有很好的基础和描述性,与自动收集的 Conceptual Caption 数据集有质的区别。作者通过对每个图像-标题对随机抽取三个干扰因素来训练,即从目标图像邻近的 100 个对象中随机抽取一个标题、一个随机图像或一个 hard negative(难分样本)。计算每个的对齐分数(如对齐预测的预训练),并应用一个 softmax 。在交叉熵损失下训练这个模型,以选择真正的图像-标题对,训练 20 个 epoch ,批次大小为64,初始学习率为2-5。在推理过程中,对测试集中的每个标题-图像对进行评分,然后进行排序。为了提高效率,作者在第一个 Co-TRM 层之前缓存了语言流表示--在融合之前有效地冻结了语言表示。 ‘Zero-shot’ Caption-Based Image Retrieval:前面的任务都是包括特定 fine-tuning 的转移任务。在这个 "Zero-shot "任务中,作者直接将预先训练好的多模态对齐预测机制应用于 Flickr30k 中基于标题的图像检索,而没有进行 fine-tuning(因此被描述为 "Zero-shot")。这个任务的目的是证明预训练已经发展出了文本定位的能力,而且这可以推广到视觉和语言的变化,而不需要任何特定的任务 fine-tuning。作者直接使用在第 3.1 节中描述的 Conceptual Captions 数据集上训练的 ViLBERT 模型。使用对齐预测目标作为评分函数,并在与上述 Caption-Based Image Retrieval 相同的分割上进行测试
4. Results and Analysis
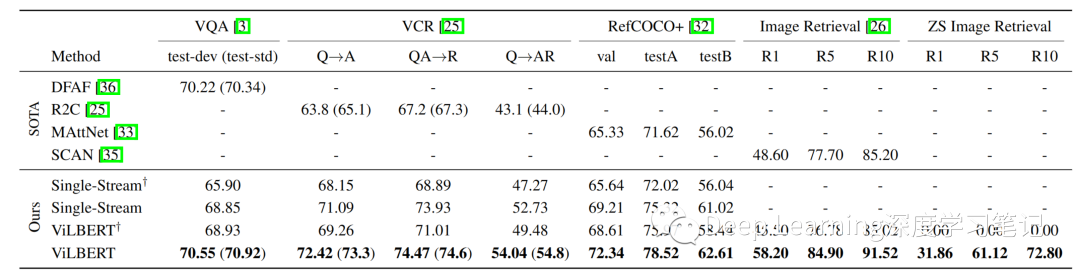 表 1:ViLBERT 模型的传输任务结果与现有最优且合理的架构消融相比。† 表示没有对 Conceptual Captions 进行预训练的模型。对于具有私有测试集的 VCR 和 VQA,作者仅报告完整模型的测试结果(在括号中)。完整的 ViLBERT 模型在所有任务中都优于特定任务的最新模型
表 1:ViLBERT 模型的传输任务结果与现有最优且合理的架构消融相比。† 表示没有对 Conceptual Captions 进行预训练的模型。对于具有私有测试集的 VCR 和 VQA,作者仅报告完整模型的测试结果(在括号中)。完整的 ViLBERT 模型在所有任务中都优于特定任务的最新模型
 表 2:模型深度与 Co-TRMTRM 块数量的消融研究(如图 1 中的虚线框所示)。作者发现不同的任务在不同的网络深度上表现更好——这意味着它们可能需要或多或少的上下文聚合
表 2:模型深度与 Co-TRMTRM 块数量的消融研究(如图 1 中的虚线框所示)。作者发现不同的任务在不同的网络深度上表现更好——这意味着它们可能需要或多或少的上下文聚合
 表3:ViLBERT 的转移任务结果与预训练期间使用 Conceptual Captions 数据集的百分比有关。我们看到,随着预训练数据集规模的增长,收益越高。
表3:ViLBERT 的转移任务结果与预训练期间使用 Conceptual Captions 数据集的百分比有关。我们看到,随着预训练数据集规模的增长,收益越高。
 图5:经过作者的培训任务,但在特定任务 fine-tuning 之前,ViLBERT 模型图像采样描述的定性例子
图5:经过作者的培训任务,但在特定任务 fine-tuning 之前,ViLBERT 模型图像采样描述的定性例子