
【MM-LLM系列】Chinese LLaVA 开源中英文双语视觉-语言多模态模型
作者:黄文灏
原文地址:https://zhuanlan.zhihu.com/p/647777504
类型: 技术分享
本文为 @黄文灏 原创转载!如有侵权,麻烦告知删除!
新开的【MM-LLM系列】是对多模态大模型相关工作的一些思考和总结。LLM就目前国内追赶的GPT3.5的目标来看已经是比较确定性的路径了(别说GPT4,国内先把10000张卡连起来训练做好了再说)。多模态大模型方向还是比较多样化的,也是决定未来模型高度的关键因素,探索起来也更有意思一些。
介绍一个用LLaMA2中文微调模型作为中文语言模型底座,加上图片理解能力的工作Chinese LLaVA。该工作follow LLaVA的结构使用中文数据做了两阶段训练。第一阶段pretrain from feature alignment,第二阶段end-to-end finetuning。
LinkSoul-AI/Chinese-LLaVA
https://github.com/LinkSoul-AI/Chinese-LLaVA
LinkSoul/Chinese-LLaVa
https://huggingface.co/spaces/LinkSoul/Chinese-LLaVa
LLaVA简介
论文地址:https://https://arxiv.org/pdf/2304.08485.pdf5.pdf
论文名称:Visual Instruction Tuning
数据集准备
LLaVA针对不同的任务,提出了构建instruction-following data的方法。为了让语言模型理解图片,首先,通过对图片进行caption,并识别出图片中的所有box,将两部分信息通过不同的prompt通过GPT生成Conversation、Detailed description、Complex reasoning任务类型的instruction-following data。数据如下图所示:

作者一共收集了158K instruction-following文本图像对数据, 包含58K in conversations, 23K in detailed description, 77k in complex reasoning。
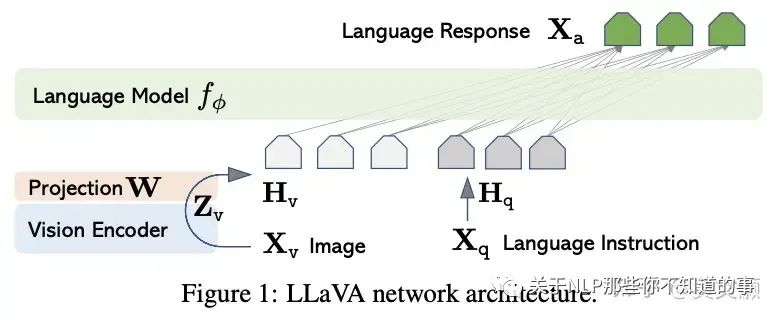
模型结构如下图所示,对于输入图像 X_v,本文使用预训练的 CLIP 视觉编码器 ViT-L/14 进行处理,得到视觉特征 Z_v=g (X_v)。实验中使用的是最后一个 Transformer 层之前和之后的网络特征。作者使用一个简单的线性层来将图像特征连接到单词嵌入空间中。具体而言,应用可训练投影矩阵 W 将 Z_v 转换为语言嵌入标记 H_v,H_v 具有与语言模型中的单词嵌入空间相同的维度:
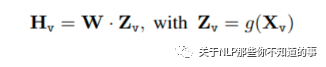
之后,得到一系列视觉标记 H_v。这种简单投影方案具有轻量级、成本低等特点,能够快速迭代以数据为中心的实验。也可以考虑连接图像和语言特征的更复杂(但昂贵)的方案,例如 Flamingo 中的门控交叉注意力机制和 BLIP-2 中的 Q-former,或者提供对象级特征的其他视觉编码器,如 SAM。
具体训练分为两个阶段
pretrain from feature alignment
从CC3M中选取595K image-text pairs,并用上述数据构造方法生成instruction-following data,把 image-text pair 看作是单轮的对话形式,Xq 从设计的问题形式中随机选取。
具体的:freeze 视觉编码器和 LLM 的权重,训练变换矩阵(linear layer) W
end-to-end finetuning
freeze视觉编码器,fine-tuning预训练的变换矩阵 W 和LLM
Chinese LLaVA
这个工作基于之前的Chinese-Llama-2-7b的工作,给语言模型加入了视觉理解的能力。模型开源且可商用,可以用来做一些中文的视觉-语言任务。
LinkSoul-AI/Chinese-Llama-2-7b
https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
作者在模型结构没有对LLaVA做任何改变,主要是将数据从英文转成了中文。根据huggingface上的信息,数据集还在整理中。
LinkSoul/Chinese-LLaVA-Vision-Instructions
https://huggingface.co/datasets/LinkSoul/Chinese-LLaVA-Vision-Instructions
实际案例
可以直接在huggingface space试玩
LinkSoul/Chinese-LLaVa
https://huggingface.co/spaces/LinkSoul/Chinese-LLaVa
下面是一些尝试的case
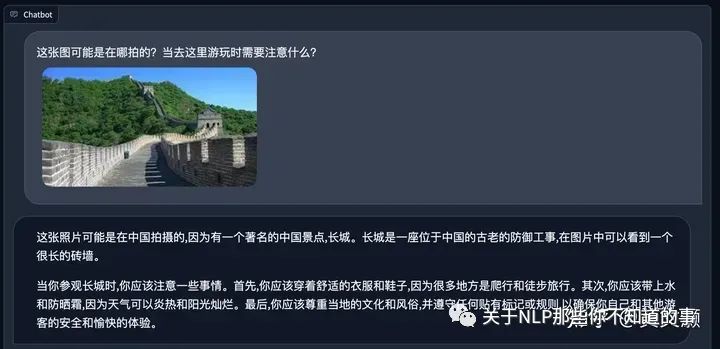
说的条理还挺清晰的
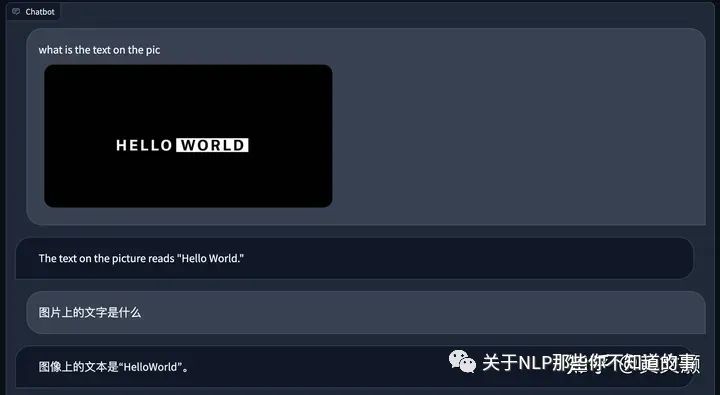
OCR能力也可以,而且可以中英双语
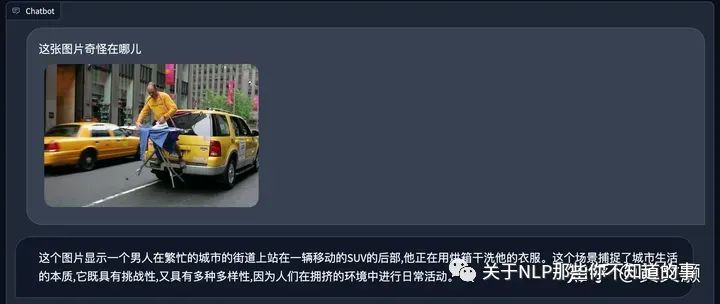
经典的GPT4测试,感觉说的还是差点意思

指令跟随能力不错
整体来说,这个多模态视觉语言模型给大家展示了用开源语言模型,快速增加中文能力和视觉理解能力的的方法,模型在简单场景下表现不错。在商用场景上,模型允许完全免费商用,这对于国内个人开发者和初创公司会有很大价值。