干货!图神经网络及其自监督学习

本文约3400字,建议阅读5分钟
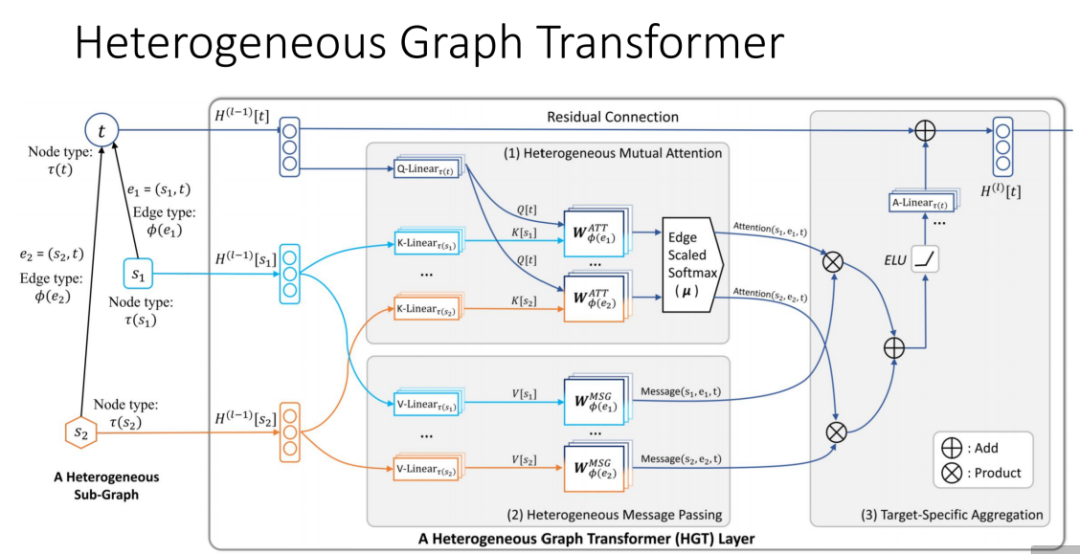
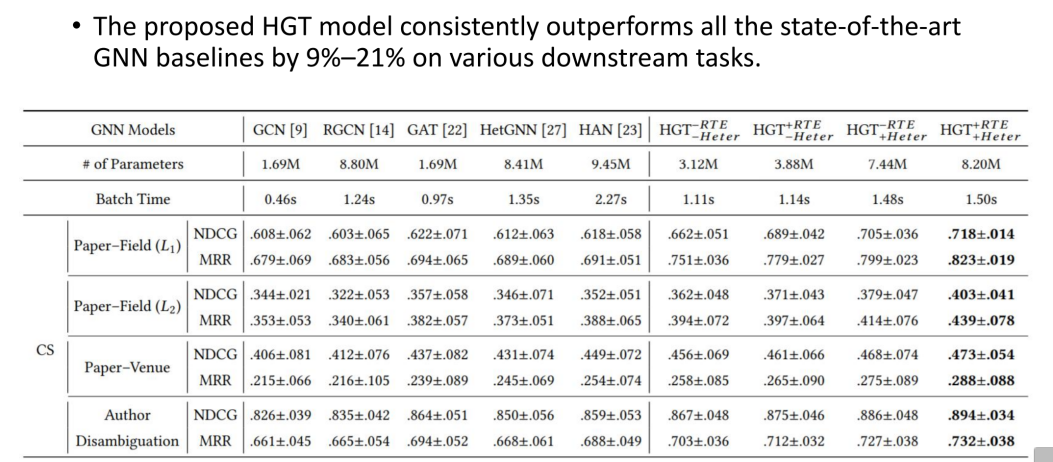
本文提出了用于建模工业级规模异构图的异构图转换架构(HGT),针对三方面问题进行解决。
代码链接:
https://github.com/acbull/pyHGT
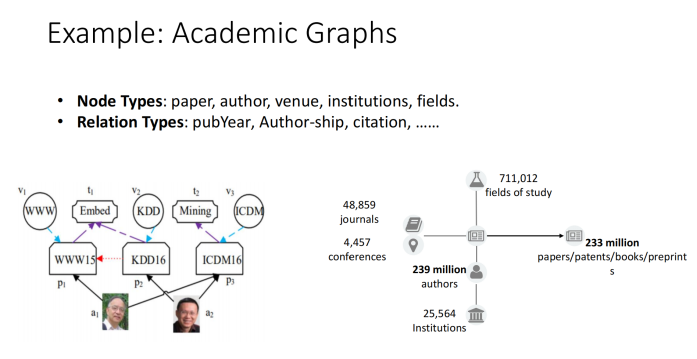
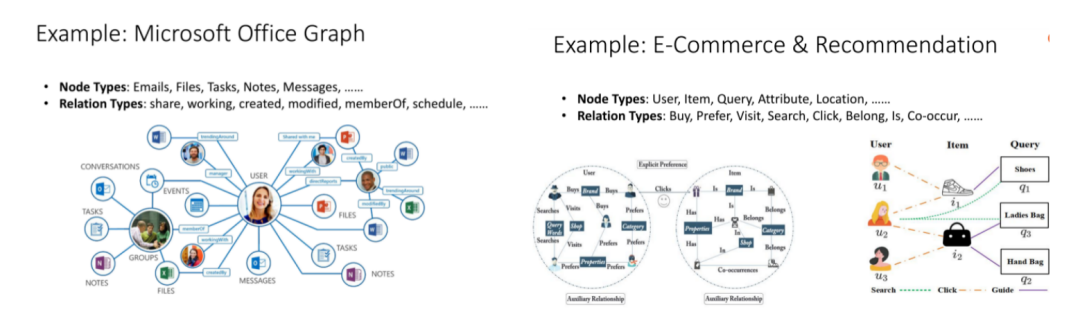
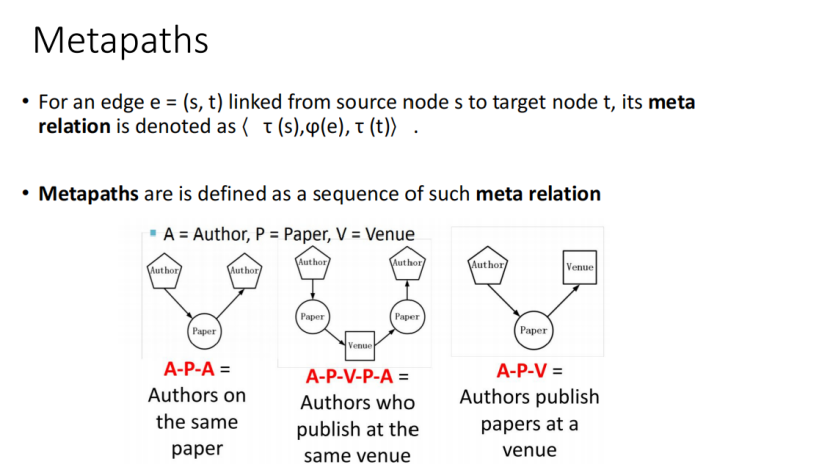
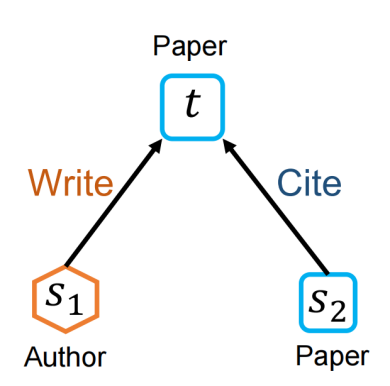
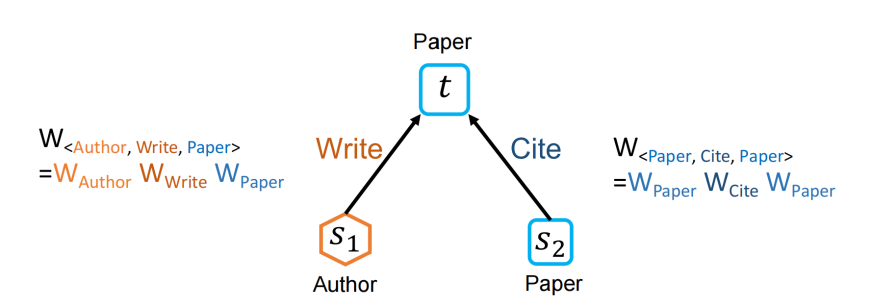
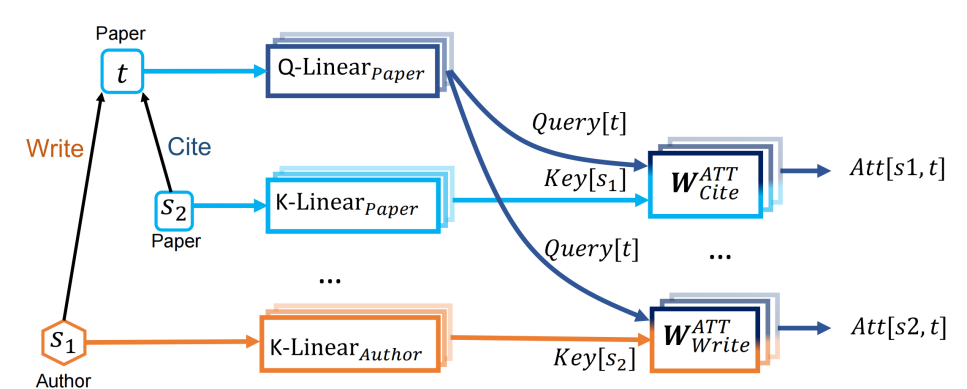
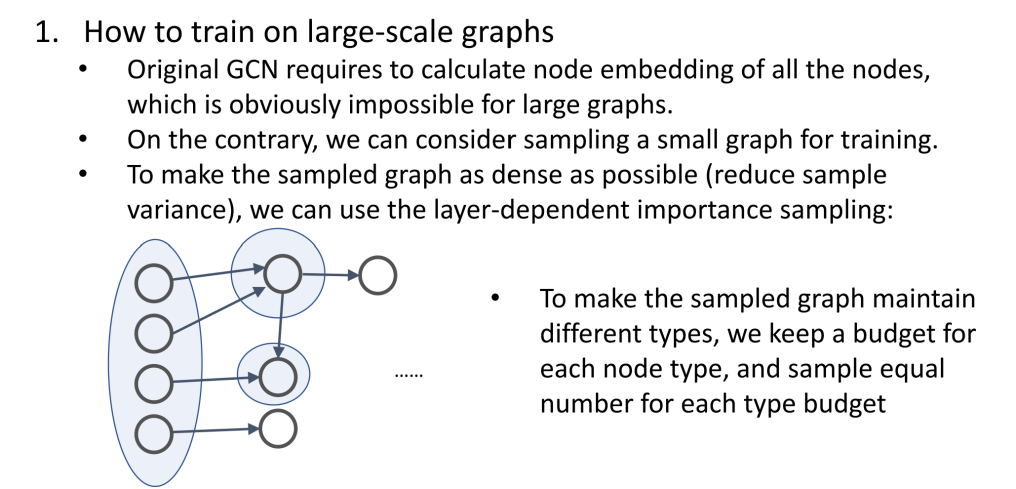
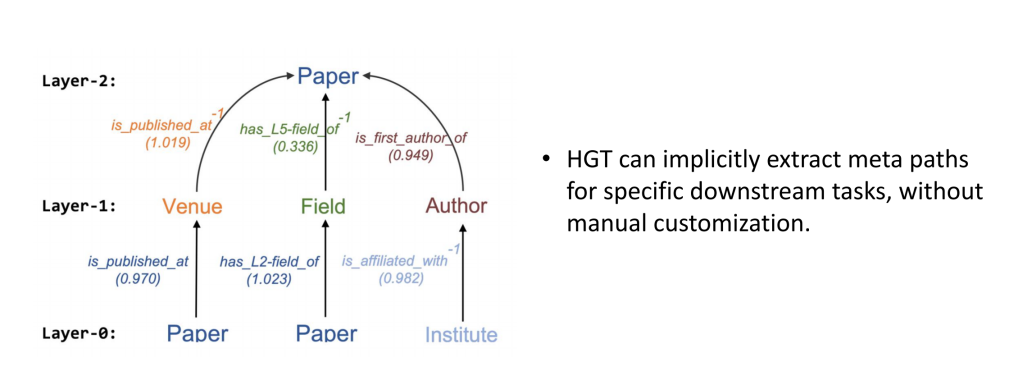
(一)异构交互注意力和消息传递
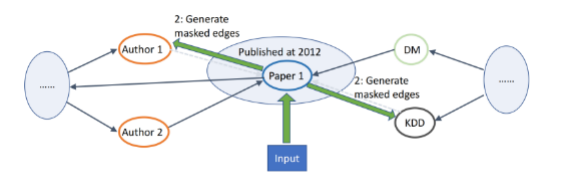
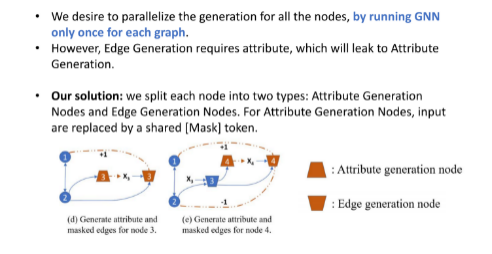
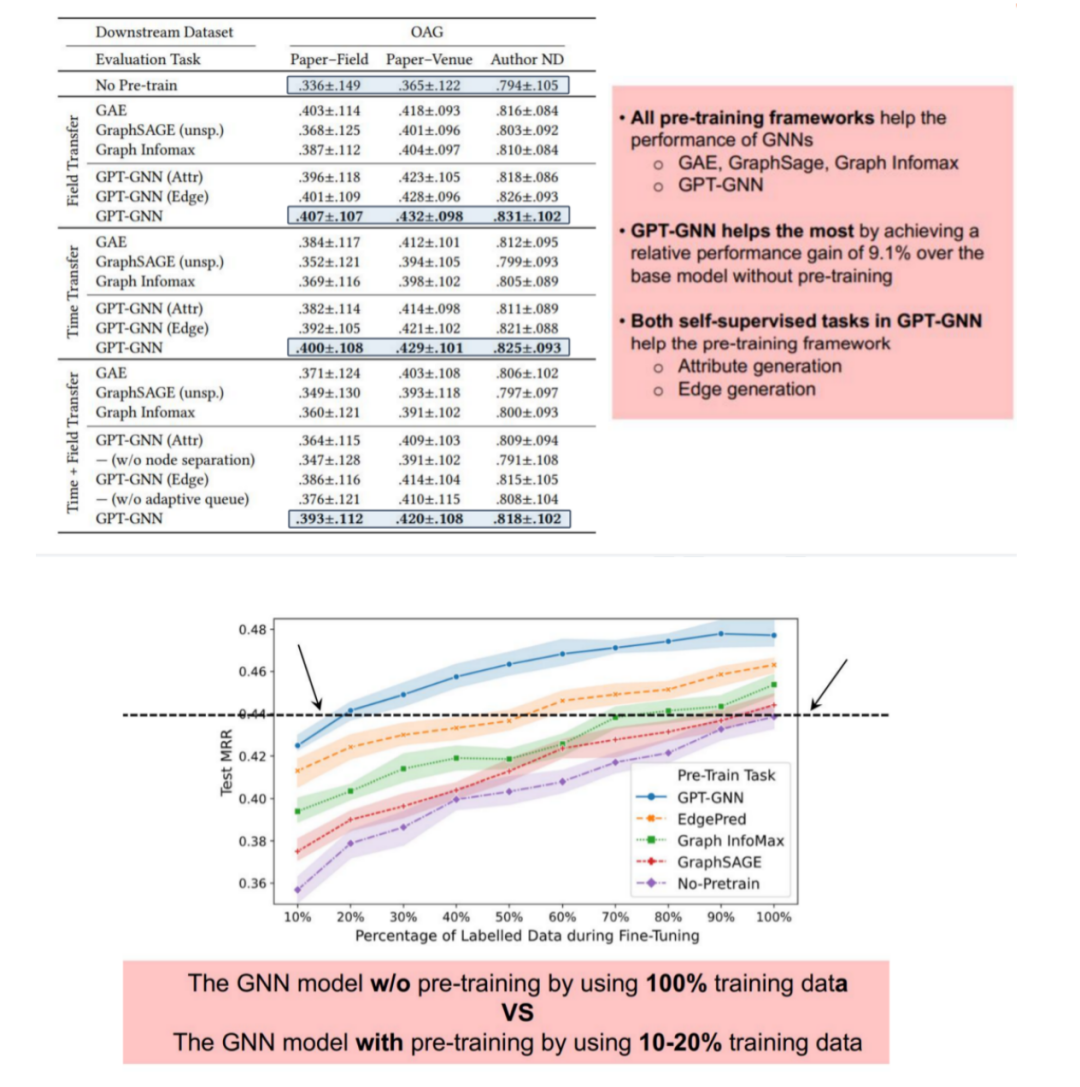
编辑:王菁
校对:林亦霖
评论
 下载APP
下载APP
本文约3400字,建议阅读5分钟
本文提出了用于建模工业级规模异构图的异构图转换架构(HGT),针对三方面问题进行解决。
代码链接:
https://github.com/acbull/pyHGT
(一)异构交互注意力和消息传递
编辑:王菁
校对:林亦霖