
超全干货!机器学习基础知识大总结
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
哈喽,小伙伴们,周末好!今天我们一起学习机器学习的知识!
机器学习(Machine Learning)本质上就是让计算机自己在数据中学习规律,并根据所得到的规律对未来数据进行预测。
机器学习包括如聚类、分类、决策树、贝叶斯、神经网络、深度学习(Deep Learning)等算法。
机器学习的基本思路是模仿人类学习行为的过程,如我们在现实中的新问题一般是通过经验归纳,总结规律,从而预测未来的过程。机器学习的基本过程如下:
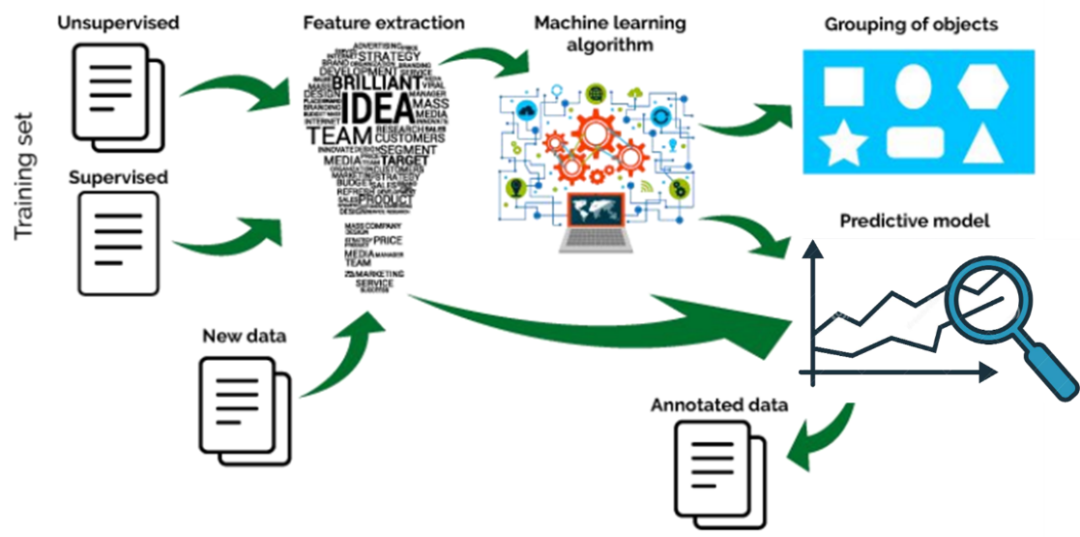
机器学习基本过程

从机器学习发展的过程上来说,其发展的时间轴如下所示:
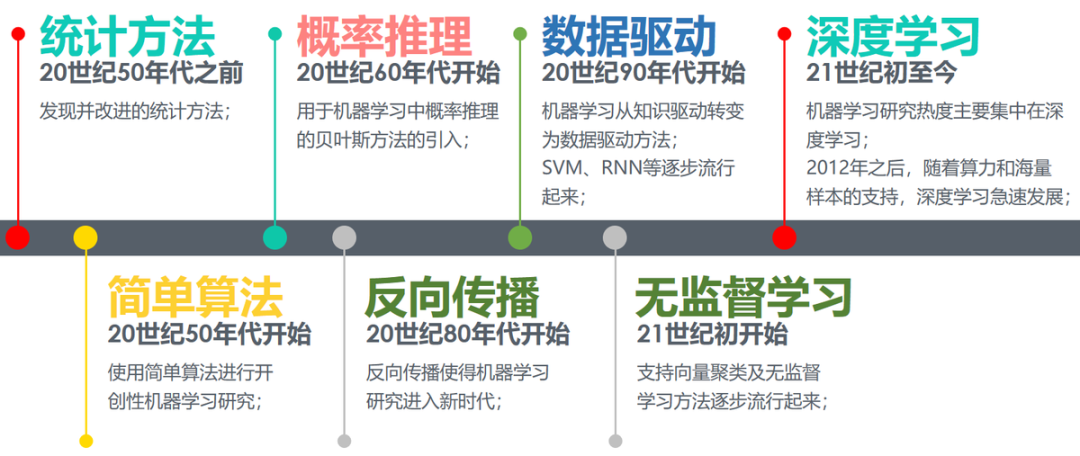
机器学习发展历程
从上世纪50年代的图灵测试提出、塞缪尔开发的西洋跳棋程序,标志着机器学习正式进入发展期。
60年代中到70年代末的发展几乎停滞。
80年代使用神经网络反向传播(BP)算法训练的多参数线性规划(MLP)理念的提出将机器学习带入复兴时期。
90年代提出的“决策树”(ID3算法),再到后来的支持向量机(SVM)算法,将机器学习从知识驱动转变为数据驱动的思路。
21世纪初Hinton提出深度学习(Deep Learning),使得机器学习研究又从低迷进入蓬勃发展期。
从2012年开始,随着算力提升和海量训练样本的支持,深度学习(Deep Learning)成为机器学习研究热点,并带动了产业界的广泛应用。
机器学习经过几十年的发展,衍生出了很多种分类方法,这里按学习模式的不同,可分为监督学习、半监督学习、无监督学习和强化学习。
监督学习
监督学习(Supervised Learning)是从有标签的训练数据中学习模型,然后对某个给定的新数据利用模型预测它的标签。如果分类标签精确度越高,则学习模型准确度越高,预测结果越精确。
监督学习主要用于回归和分类。

常见的监督学习的回归算法有线性回归、回归树、K邻近、Adaboost、神经网络等。
常见的监督学习的分类算法有朴素贝叶斯、决策树、SVM、逻辑回归、K邻近、Adaboost、神经网络等。
半监督学习
半监督学习(Semi-Supervised Learning)是利用少量标注数据和大量无标注数据进行学习的模式。
半监督学习侧重于在有监督的分类算法中加入无标记样本来实现半监督分类。
常见的半监督学习算法有Pseudo-Label、Π-Model、Temporal Ensembling、Mean Teacher、VAT、UDA、MixMatch、ReMixMatch、FixMatch等。
无监督学习
无监督学习(Unsupervised Learning)是从未标注数据中寻找隐含结构的过程。
无监督学习主要用于关联分析、聚类和降维。
常见的无监督学习算法有稀疏自编码(Sparse Auto-Encoder)、主成分分析(Principal Component Analysis, PCA)、K-Means算法(K均值算法)、DBSCAN算法(Density-Based Spatial Clustering of Applications with Noise)、最大期望算法(Expectation-Maximization algorithm, EM)等。
强化学习
强化学习(Reinforcement Learning)类似于监督学习,但未使用样本数据进行训练,是是通过不断试错进行学习的模式。
在强化学习中,有两个可以进行交互的对象:智能体(Agnet)和环境(Environment),还有四个核心要素:策略(Policy)、回报函数(收益信号,Reward Function)、价值函数(Value Function)和环境模型(Environment Model),其中环境模型是可选的。
强化学习常用于机器人避障、棋牌类游戏、广告和推荐等应用场景中。
为了便于读者理解,用灰色圆点代表没有标签的数据,其他颜色的圆点代表不同的类别有标签数据。监督学习、半监督学习、无监督学习、强化学习的示意图如下所示:
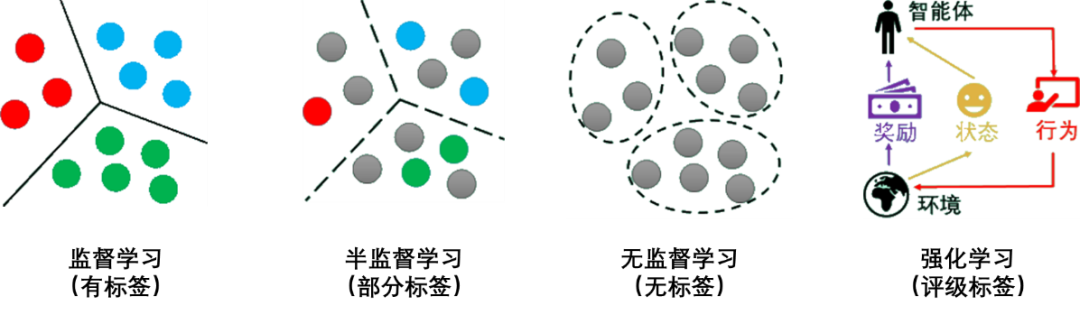
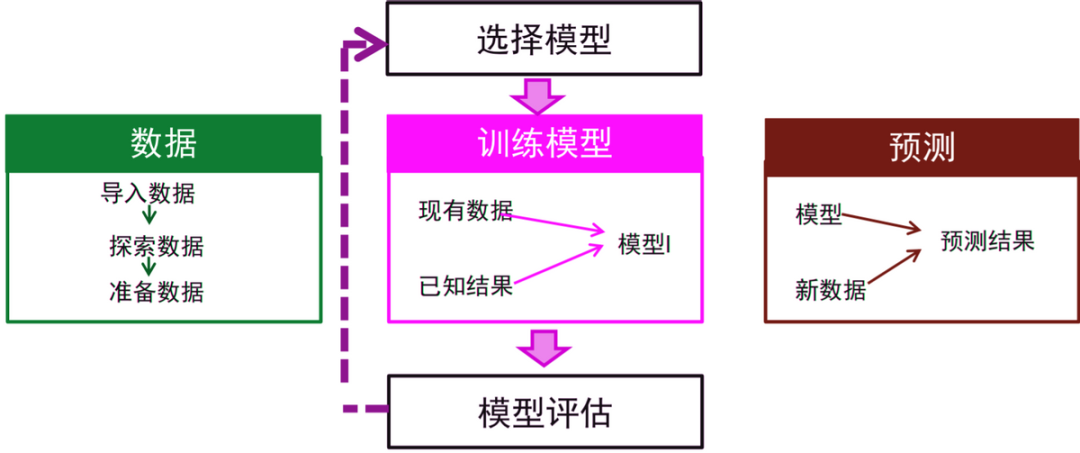
机器学习是将现实中的问题抽象为数学模型,利用历史数据对数据模型进行训练,然后基于数据模型对新数据进行求解,并将结果再转为现实问题的答案的过程。机器学习一般的应用实现步骤如下:
将现实问题抽象为数学问题;
数据准备;
选择或创建模型;
模型训练及评估;
预测结果;
这里我们以Kaggle上的一个竞赛Cats vs. Dogs(猫狗大战)为例来进行简单介绍,感兴趣的可亲自实验。
现实问题抽象为数学问题
现实问题:给定一张图片,让计算机判断是猫还是狗?
数学问题:二分类问题,1表示分类结果是狗,0表示分类结果是猫。
数据准备
数据下载地址:
https://www.kaggle.com/c/dogs-vs-cats。
下载 kaggle 猫狗数据集解压后分为 3 个文件 train.zip、 test.zip 和 sample_submission.csv。
train 训练集包含了 25000 张猫狗的图片,猫狗各一半,每张图片包含图片本身和图片名。命名规则根据 “type.num.jpg” 方式命名。

训练集示例
test 测试集包含了 12500 张猫狗的图片,没有标定是猫还是狗,每张图片命名规则根据“num.jpg”命名。
测试集示例
sample_submission.csv 需要将最终测试集的测试结果写入.csv 文件中。
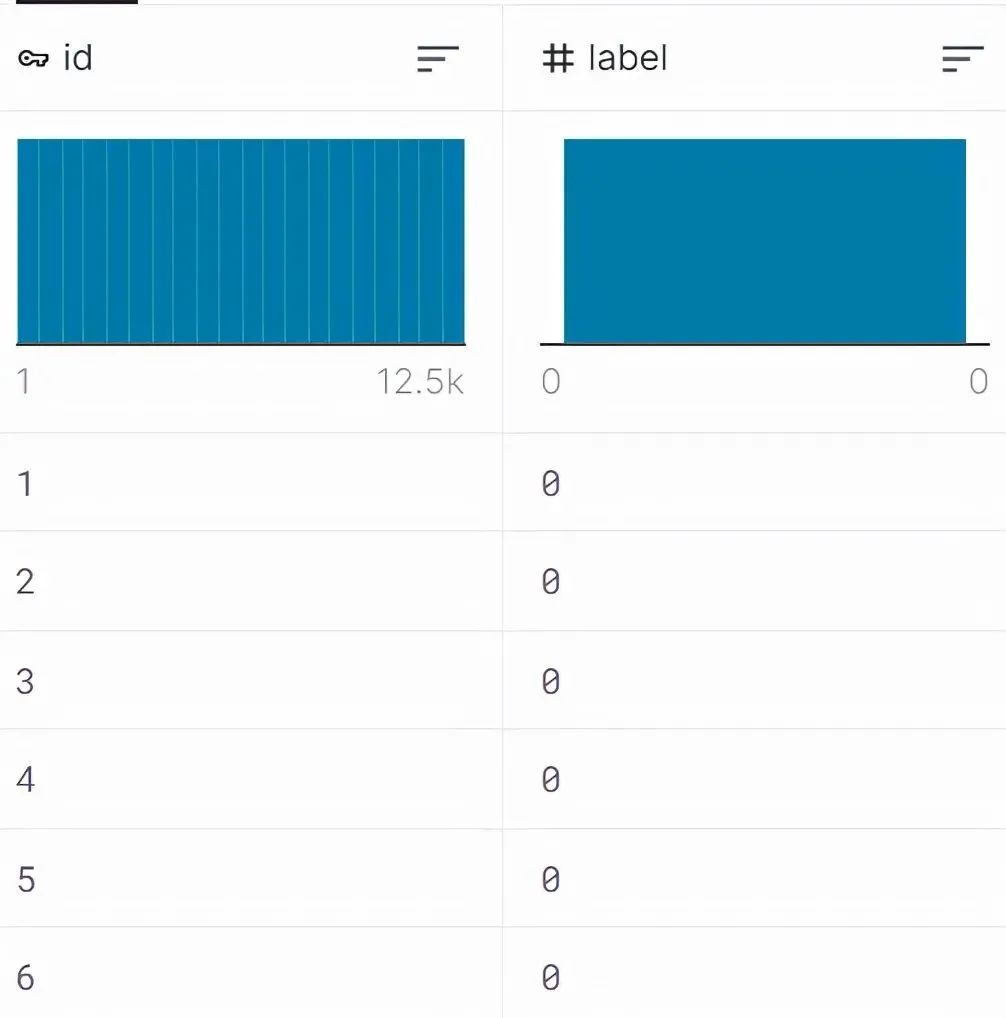
sample_submission示例
我们将数据分成3个部分:训练集(60%)、验证集(20%)、测试集(20%),用于后面的验证和评估工作。

选择模型
机器学习有很多模型,需要选择哪种模型,需要根据数据类型,样本数量,问题本身综合考虑。
如本问题主要是处理图像数据,可以考虑使用卷积神经网络(Convolutional Neural Network, CNN)模型来实现二分类,因为选择CNN的优点之一在于避免了对图像前期预处理过程(提取特征等)。猫狗识别的卷积神经网络结构如下面所示:
最下层是网络的输入层(Input Layer),用于读入图像作为网络的数据输入;最上层是网络的输出层(Output Layer),其作用是预测并输出读入图像的类别,由于只需要区分猫和狗,因此输出层只有2个神经计算单元;位于输入和输出层之间的,都称之为隐含层(Hidden Layer),也叫卷积层(Convolutional Layer),这里设置3个隐含层。
模型训练及评估
我们预先设定损失函数Loss计算得到的损失值,通过准确率Accuracy来评估训练模型。损失函数LogLoss作为模型评价指标:
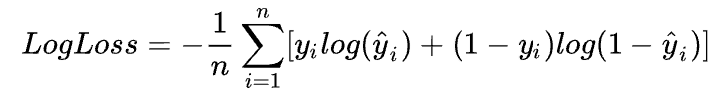

准确率(accuracy)来衡量算法预测结果的准确程度:
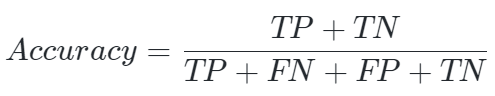
TP(True Positive)是将正类预测为正类的结果数目。
FP(False Positive)是将负类预测为正类的结果数目。
TN(True Negative)是将负类预测为负类的结果数目。
FN(False Negative)是将正类预测为负类的结果数目。
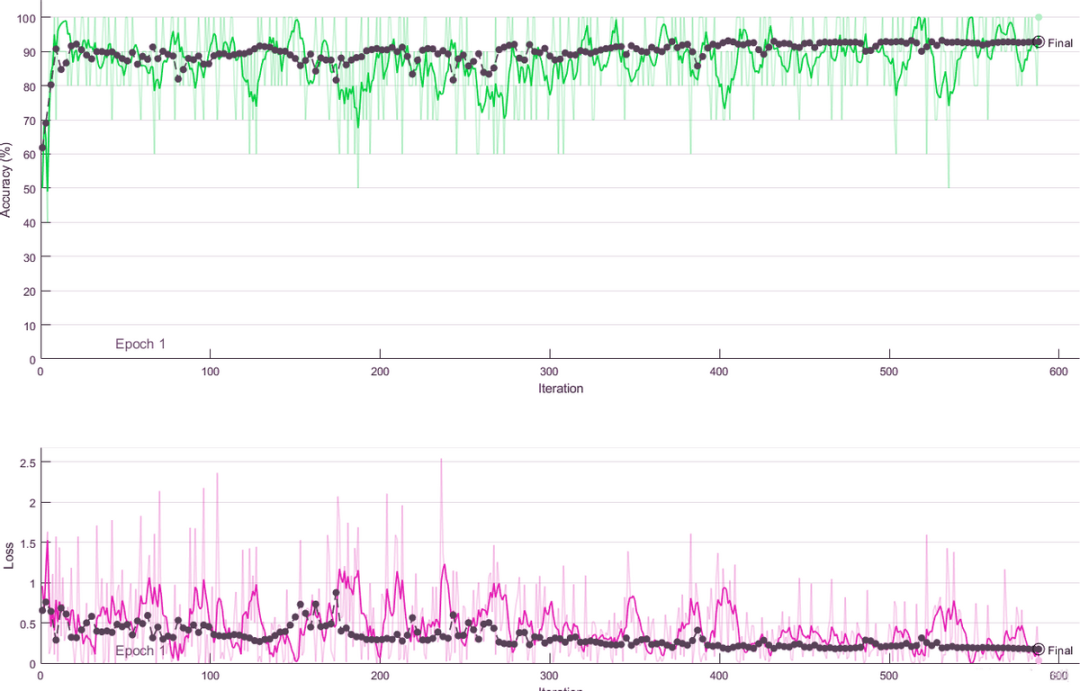
训练过中的 loss 和 accuracy
预测结果
训练好的模型,我们载入一张图片,进行识别,看看识别效果:

机器学习正真开始研究和发展应该从80年代开始,我们借助AMiner平台,将近些年机器学习论文进行统计分析所生成的发展趋势图如下所示:
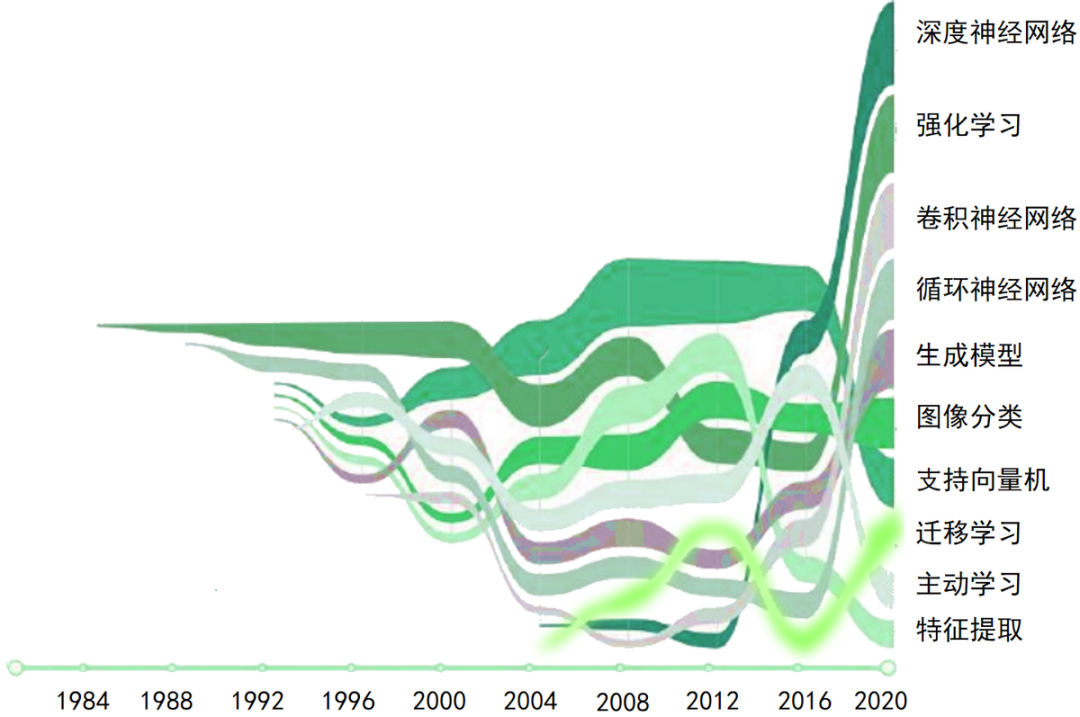
可以看出,深度神经网络(Deep Neural Network)、强化学习(Reinforcement Learning)、卷积神经网络(Convolutional Neural Network)、循环神经网络(Recurrent Neural Network)、生成模型(Generative Model)、图像分类(Image Classification)、支持向量机(Support Vector Machine)、迁移学习(Transfer Learning)、主动学习(Active Learning)、特征提取(Feature Extraction)是机器学习的热点研究。
以深度神经网络、强化学习为代表的深度学习相关的技术研究热度上升很快,近几年仍然是研究热点。
来源:爱数据LoveData
本文仅做学术分享,如有侵权,请联系删文。