
NLP关键词提取方法总结及实现

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
一、关键词提取概述
关键词是能够表达文档中心内容的词语,常用于计算机系统标引论文内容特征、信息检索、系统汇集以供读者检阅。关键词提取是文本挖掘领域的一个分支,是文本检索、文档比较、摘要生成、文档分类和聚类等文本挖掘研究的基础性工作。
从算法的角度来看,关键词提取算法主要有两类:无监督关键词提取方法和有监督关键词提取方法。
1、无监督关键词提取方法
不需要人工标注的语料,利用某些方法发现文本中比较重要的词作为关键词,进行关键词提取。该方法是先抽取出候选词,然后对各个候选词进行打分,然后输出topK个分值最高的候选词作为关键词。根据打分的策略不同,有不同的算法,例如TF-IDF,TextRank,LDA等算法。
无监督关键词提取方法主要有三类:基于统计特征的关键词提取(TF,TF-IDF);基于词图模型的关键词提取(PageRank,TextRank);基于主题模型的关键词提取(LDA)
基于统计特征的关键词提取算法的思想是利用文档中词语的统计信息抽取文档的关键词;
基于词图模型的关键词提取首先要构建文档的语言网络图,然后对语言进行网络图分析,在这个图上寻找具有重要作用的词或者短语,这些短语就是文档的关键词;
基于主题关键词提取算法主要利用的是主题模型中关于主题分布的性质进行关键词提取;
2、有监督关键词提取方法
将关键词抽取过程视为二分类问题,先提取出候选词,然后对于每个候选词划定标签,要么是关键词,要么不是关键词,然后训练关键词抽取分类器。当新来一篇文档时,提取出所有的候选词,然后利用训练好的关键词提取分类器,对各个候选词进行分类,最终将标签为关键词的候选词作为关键词。
3、无监督方法和有监督方法优的缺点
无监督方法不需要人工标注训练集合的过程,因此更加快捷,但由于无法有效综合利用多种信息 对候选关键词排序,所以效果无法与有监督方法媲美;而有监督方法可以通过训练学习调节多种信息对于判断关键词的影响程度,因此效果更优,有监督的文本关键词提取算法需要高昂的人工成本,因此现有的文本关键词提取主要采用适用性较强的无监督关键词提取。
4、关键词提取常用工具包
jieba
Textrank4zh (TextRank算法工具)
SnowNLP (中文分析)简体中文文本处理
TextBlob (英文分析)
二、TF-IDF关键词提取算法及实现
TF-IDF算法的详细介绍及实现方法总结参看博客:TF-IDF算法介绍及实现
三、TextRank关键词提取算法实现
TextRank算法的详细介绍及实现方法总结参看博客:TextRank算法介绍及实现
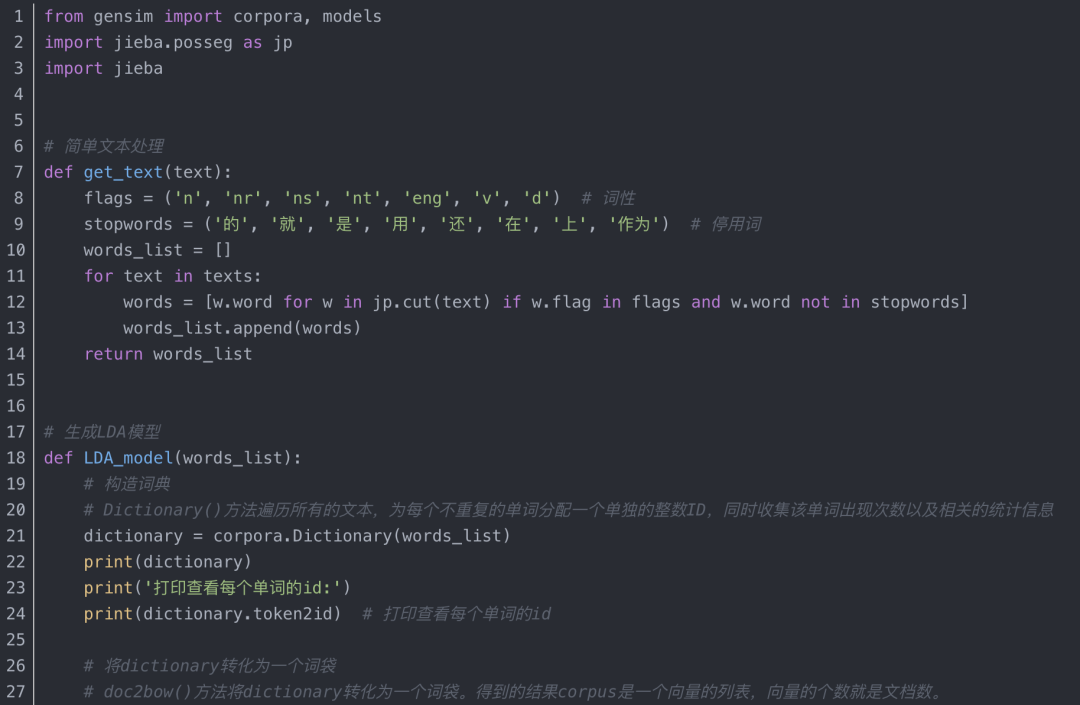
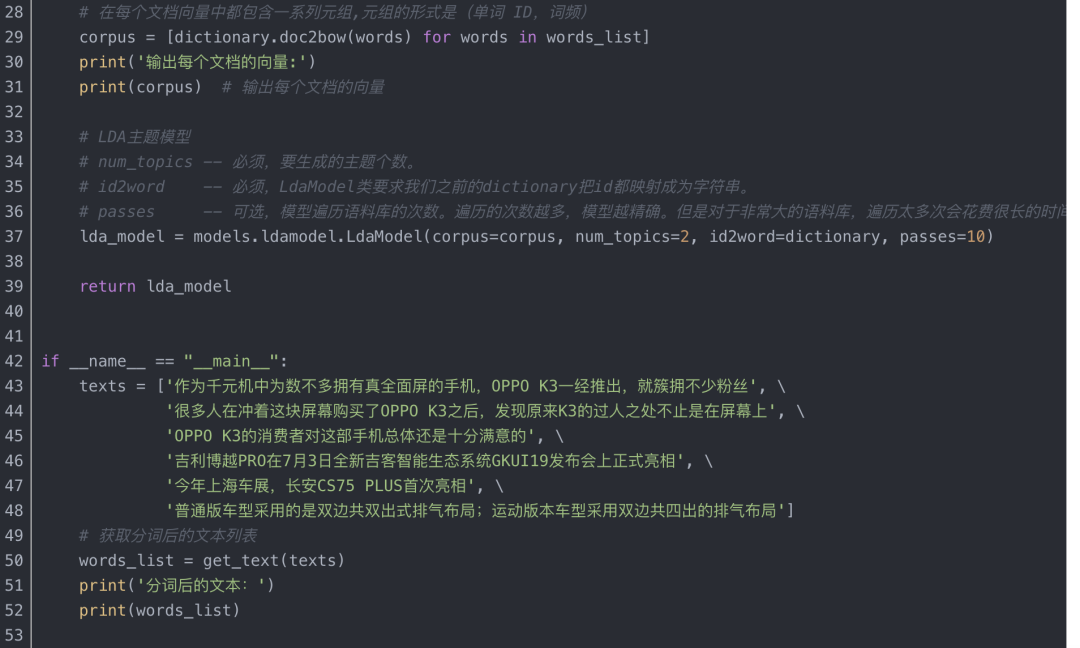
四、LDA主题模型关键词提取算法及实现
1、LDA(Latent Dirichlet Allocation)文档主题生成模型
主题模型是一种统计模型用于发现文档集合中出现的抽象“主题”。主题建模是一种常用的文本挖掘工具,用于在文本体中发现隐藏的语义结构。
LDA也称三层贝叶斯概率模型,包含词、主题和文档三层结构;利用文档中单词的共现关系来对单词按主题聚类,得到“文档-主题”和“主题-单词”2个概率分布。
通俗理解LDA主题模型原理
https://blog.csdn.net/v_JULY_v/article/details/41209515
2、基于LDA主题模型的关键词提取算法实现
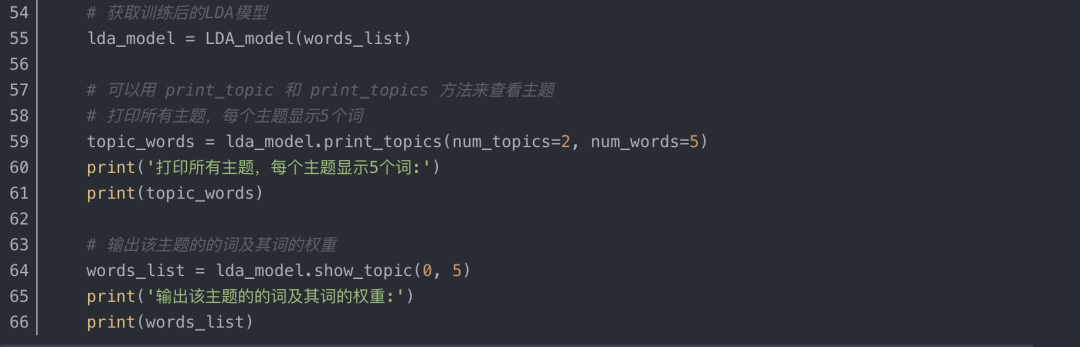
运行结果:

五、Word2Vec词聚类的关键词提取算法及实现
1、Word2Vec词向量表示
利用浅层神经网络模型自动学习词语在语料库中的出现情况,把词语嵌入到一个高维的空间中,通常在100-500维,在高维空间中词语被表示为词向量的形式。
特征词向量的抽取是基于已经训练好的词向量模型。
2、K-means聚类算法
聚类算法旨在数据中发现数据对象之间的关系,将数据进行分组,使得组内的相似性尽可能的大,组间的相似性尽可能的小。
算法思想是:首先随机选择K个点作为初始质心,K为用户指定的所期望的簇的个数,通过计算每个点到各个质心的距离,将每个点指派到最近的质心形成K个簇,然后根据指派到簇的点重新计算每个簇的质心,重复指派和更新质心的操作,直到簇不发生变化或达到最大的迭代次数则停止。
3、基于Word2Vec词聚类关键词提取方法的实现过程
主要思路是对于用词向量表示的词语,通过K-Means算法对文章中的词进行聚类,选择聚类中心作为文本的一个主要关键词,计算其他词与聚类中心的距离即相似度,选择topK个距离聚类中心最近的词作为关键词,而这个词间相似度可用Word2Vec生成的向量计算得到。
具体步骤如下:
对语料进行Word2Vec模型训练,得到词向量文件;
对文本进行预处理获得N个候选关键词;
遍历候选关键词,从词向量文件中提取候选关键词的词向量表示;
对候选关键词进行K-Means聚类,得到各个类别的聚类中心(需要人为给定聚类的个数);
计算各类别下,组内词语与聚类中心的距离(欧几里得距离或曼哈顿距离),按聚类大小进行降序排序;
对候选关键词计算结果得到排名前TopK个词语作为文本关键词。
注:第三方工具包Scikit-learn提供了K-Means聚类算法的相关函数,本文用到了sklearn.cluster.KMeans()函数执行K-Means算法,sklearn.decomposition.PCA()函数用于数据降维以便绘制图形。
六、信息增益关键词提取算法及实现
信息增益算法的详细介绍及实现方法总结参看博客:信息增益算法介绍及实现
七、互信息关键词提取算法及实现
1、互信息(Mutual Information,MI)
在概率论和信息论中,两个随机变量的互信息或转移信息(transinformation)是变量间相互依赖性的量度。不同于相关系数,互信息并不局限于实值随机变量,它更加一般且决定着联合分布 p(X,Y) 和分解的边缘分布的乘积 p(X)p(Y) 的相似程度。互信息是度量两个事件集合之间的相关性(mutual dependence)。
互信息被广泛用于度量一些语言现象的相关性。在信息论中,互信息常被用来衡量两个词的相关度,也用来计算词与类别之间的相关性。
2、互信息计算公式

3、互信息算法实现
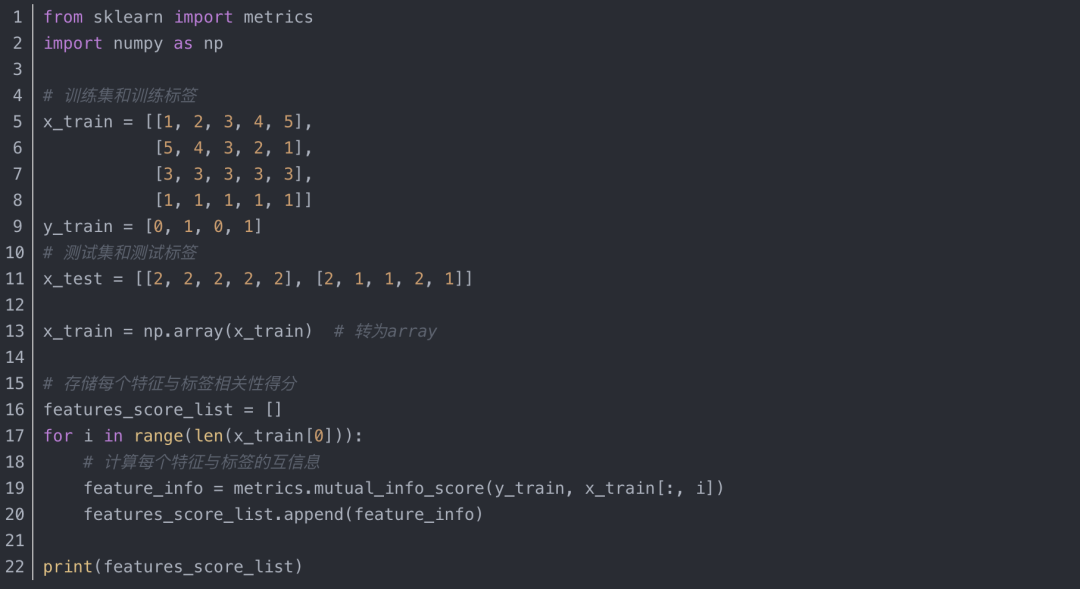
运行结果:
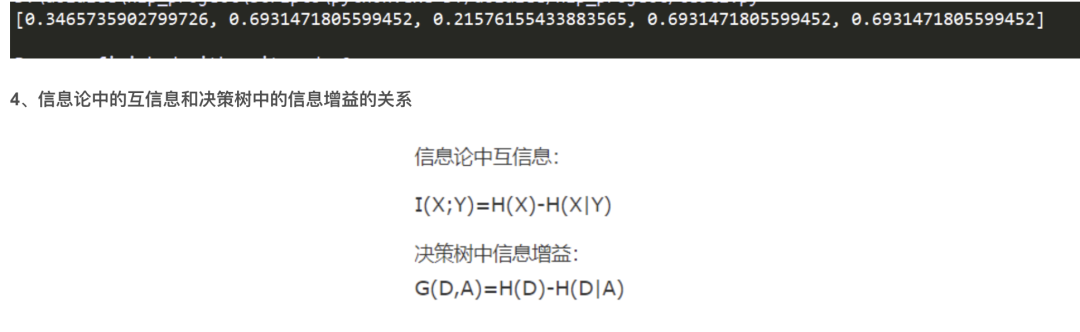
两者表达意思是一样的,都是表示得知特征 X 的信息而使得类 Y 的信息的不确定性减少的程度。
注:
标准化互信息(Normalized Mutual Information,NMI)可以用来衡量两种聚类结果的相似度。
标准化互信息Sklearn实现:metrics.normalized_mutual_info_score(y_train, x_train[:, i])。
点互信息(Pointwise Mutual Information,PMI)这个指标来衡量两个事物之间的相关性(比如两个词)。
八、卡方检验关键词提取算法及实现
1、卡方检验
卡方是数理统计中用于检验两个变量独立性的方法,是一种确定两个分类变量之间是否存在相关性的统计方法,经典的卡方检验是检验定性自变量对定性因变量的相关性。
2、基本思路
原假设:两个变量是独立的
计算实际观察值和理论值之间的偏离程度
如果偏差足够小,小于设定阈值,就接受原假设;否则就否定原假设,认为两变量是相关的。
3、计算公式
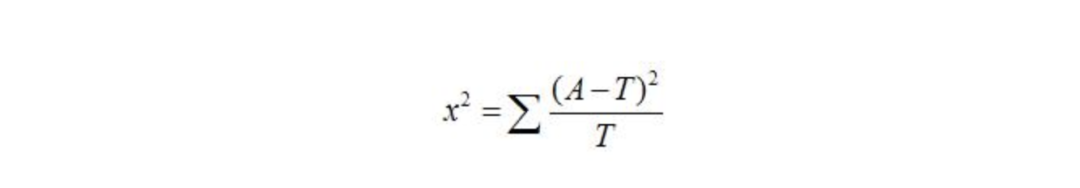
其中,A为实际值,T为理论值。卡方检验可用于文本分类问题中的特征选择,此时不需要设定阈值,只关心找到最为相关的topK个特征。基本思想:比较理论频数和实际频数的吻合程度或者拟合优度问题。
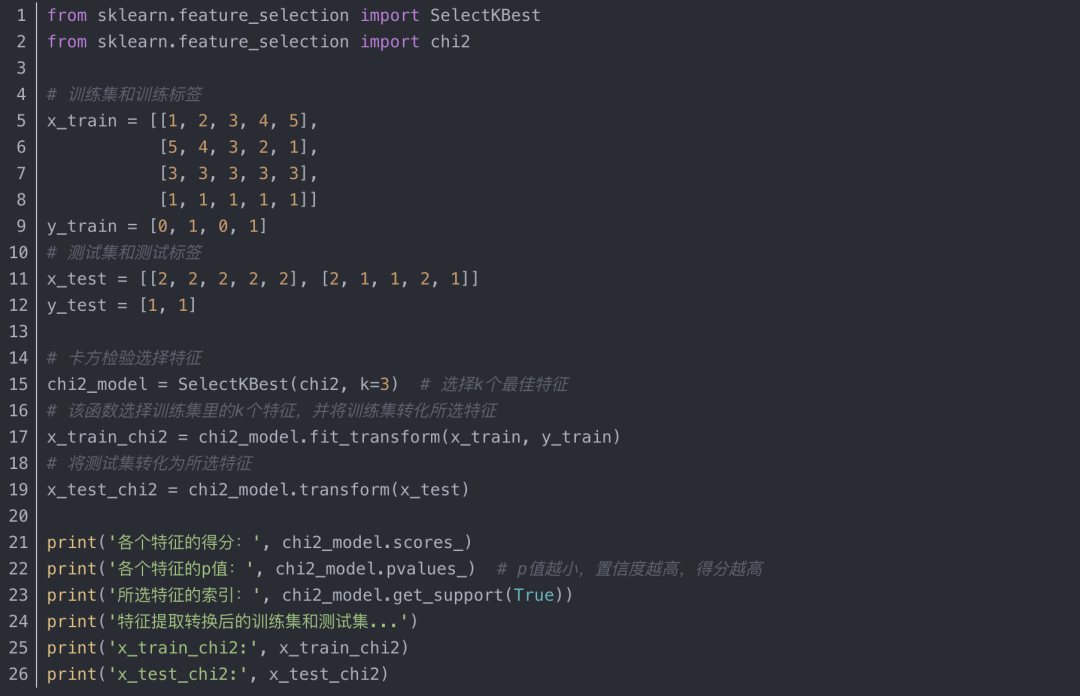
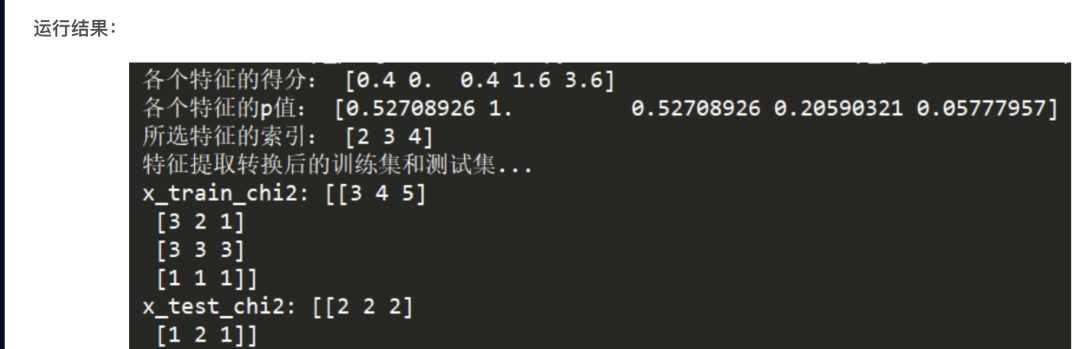
4、基于sklearn的卡方检验实现
九、基于树模型的关键词提取算法及实现
1、树模型
主要包括决策树和随机森林,基于树的预测模型(sklearn.tree 模块和 sklearn.ensemble 模块)能够用来计算特征的重要程度,因此能用来去除不相关的特征(结合 sklearn.feature_selection.SelectFromModel)
sklearn.ensemble模块包含了两种基于随机决策树的平均算法:RandomForest算法和Extra-Trees算法。这两种算法都采用了很流行的树设计思想:perturb-and-combine思想。这种方法会在分类器的构建时,通过引入随机化,创建一组各不一样的分类器。这种ensemble方法的预测会给出各个分类器预测的平均。
RandomForests 在随机森林(RF)中,该ensemble方法中的每棵树都基于一个通过可放回抽样(boostrap)得到的训练集构建。另外,在构建树的过程中,当split一个节点时,split的选择不再是对所有features的最佳选择。相反的,在features的子集中随机进行split反倒是最好的split方式。sklearn的随机森林(RF)实现通过对各分类结果预测求平均得到,而非让每个分类器进行投票(vote)。
Ext-Trees 在Ext-Trees中(详见ExtraTreesClassifier和 ExtraTreesRegressor),该方法中,随机性在划分时会更进一步进行计算。在随机森林中,会使用侯选feature的一个随机子集,而非查找最好的阈值,对于每个候选feature来说,阈值是抽取的,选择这种随机生成阈值的方式作为划分原则。
2、树模型的关键词提取算法实现
(1)部分代码实现1
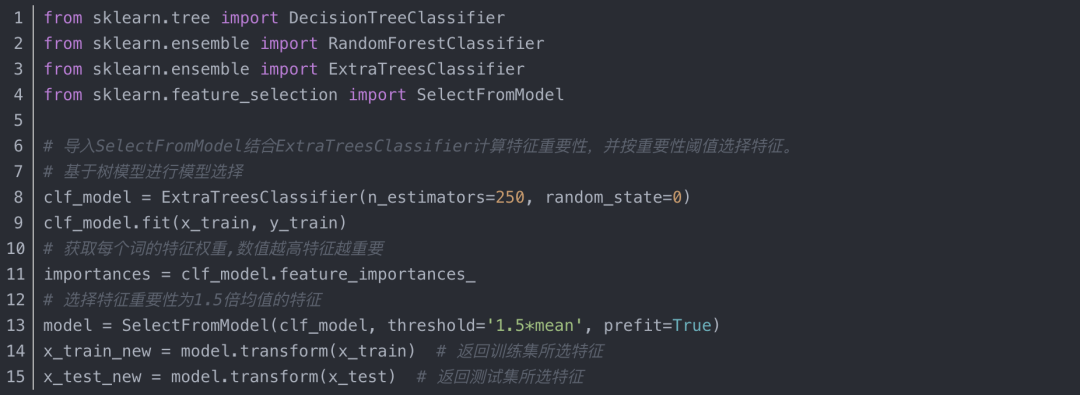
(2)部分代码实现2
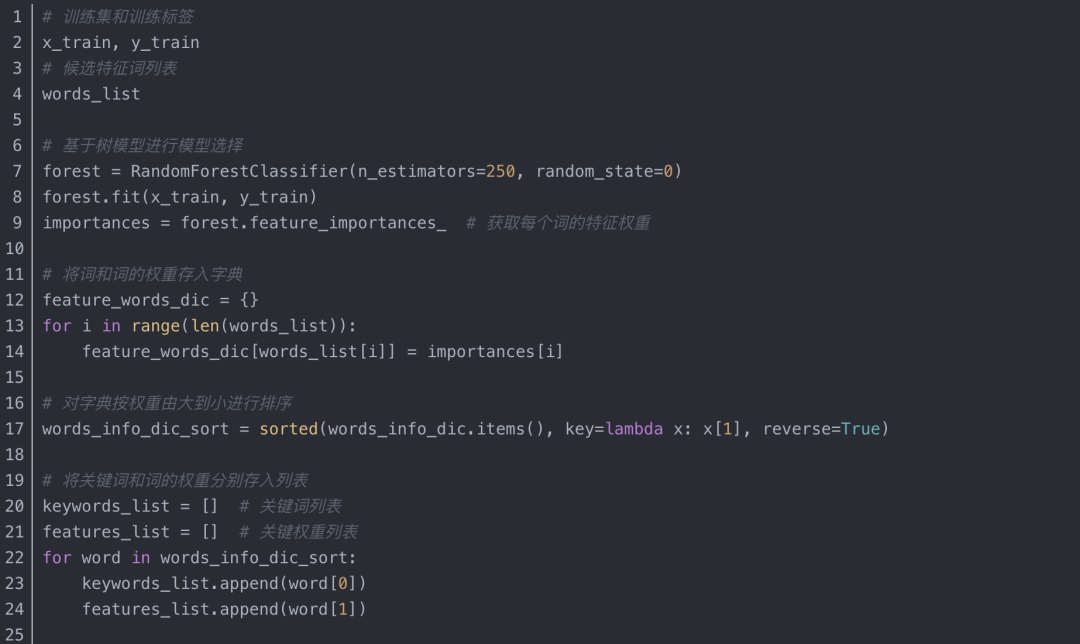

十、总结
本文总结了本人在实验过程中所用到的常用关键词抽取方法,实验数据是基于公司的内部数据,但此篇总结只是方法上的讲解和实现,没有针对某一具体数据集做相应的结果分析。从实验中可以很明显看出有监督关键词抽取方法通常会显著好于无监督方法,但是有监督方法依赖一定规模的标注数据。
参考:
1、NLP关键词抽取常见算法
https://blog.csdn.net/Sakura55/article/details/85122966
2、gensim models.ldamodel
https://radimrehurek.com/gensim/models/ldamodel.html
3、卡方检验原理及应用
https://blog.csdn.net/qq_39303465/article/details/79223843
4、特征选择 (feature_selection)
https://www.cnblogs.com/stevenlk/p/6543628.html
5、随机森林算法总结及调参
https://www.cnblogs.com/wj-1314/p/9628303.html
6、句子相似度计算
https://blog.csdn.net/reigns_/article/details/80983031
原文地址 https://asialee.blog.csdn.net/article/details/96454544
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx