
何恺明团队最新力作SimSiam:消除表征学习“崩溃解”,探寻对比表达学习成功之根源
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
作者|Happy
编辑丨极市平台
导读
本文是FAIR的陈鑫磊&何恺明大神在无监督学习领域又一力作,提出了一种非常简单的表达学习机制用于避免表达学习中的“崩溃”问题,从理论与实验角度证实了所提方法的有效性;与此同时,还侧面证实了对比学习方法成功的关键性因素:孪生网络。

paper: https://arxiv.org/abs/2011.10566
Abstract
孪生网络已成为无监督表达学习领域的通用架构,现有方法通过最大化同一图像的两者增广的相似性使其避免“崩溃解(collapsing solutions)”问题。在这篇研究中,作者提出一种惊人的实证结果:Simple Siamese(SimSiam)网络甚至可以在无((1) negative sample pairs;(2)large batch;(3)momentum encoders)的情形下学习有意义的特征表达。
作者通过实验表明:对于损失与结构而言,“崩溃解”确实存在,但是“stop-gradient”操作对于避免“崩溃解”有非常重要的作用。作者提出了一种新颖的“stop-gradient”思想并通过实验对其进行了验证,该文所提SimSiam在ImageNet及下游任务上均取得了有竞争力的结果。作者期望:这个简单的基准方案可以驱动更多研员重新思考无监督表达学习中的孪生结构。
Method
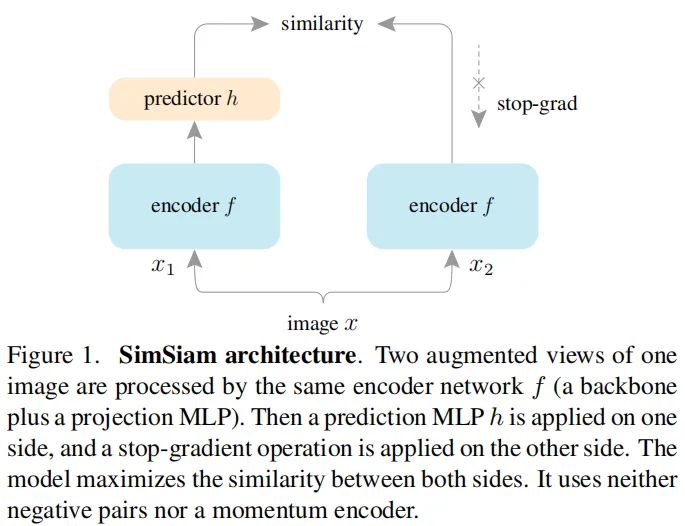
上图给出了该文所提SimSiam的示意图,它以图像
的两个随机变换
作为输入,通过相同的编码网络
(它包含一个骨干网络和一个投影MLP头模块,表示为h)提取特征并变换到高维空间。此外作者还定义了一个预测MLP头模块h,对其中一个分支的结果进行变换并与另一个分支的结果进行匹配,该过程可以描述为
,SimSiam对上述特征进行负cosine相似性最小化:
注:上述公式等价于
规范化向量的MSE损失。与此同时,作者还定义了一个对称损失:
上述两个损失作用于每一张图像,总损失是所有图像损失的平均,故最小的可能损失为-1.
需要的是:该文一个非常重要的概念是Stop-gradient操作(即上图的右分支部分)。可以通过对上述公式进行简单的修改得到本文的损失函数:
也就是说:在损失
的第一项,
不会从
接收梯度信息;在其第二项,则会从
接收梯度信息。
SimSiam的实现伪代码如下,有没有一种“就这么简单”的感觉???
# Algorithm1 SimSiam Pseudocode, Pytorch-like# f: backbone + projection mlp# h: prediction mlpfor x in loader: # load a minibatch x with n samplesx1, x2 = aug(x), aug(x) # random augmentationz1, z2 = f(x1), f(x2) # projections, n-by-dp1, p2 = h(z1), h(z2) # predictions, n-by-dL = D(p1, z2)/2 + D(p2, z1)/2 # lossL.backward() # back-propagateupdate(f, h) # SGD updatedef D(p, z): # negative cosine similarityz = z.detach() # stop gradientp = normalize(p, dim=1) # l2-normalizez = normalize(z, dim=1) # l2-normalizereturn -(p*z).sum(dim=1).mean()
我们再来看一下SimSiam的基础配置:
Optimizer: SGD用于预训练,学习率为
, 基础学习率为
,学习率采用consine衰减机制,weight decay=0.0001,momentum=0.9。BatchSize默认512,采用了SynBatchNorm。
Projection MLP:编码网络中投影MLP部分的每个全连接层后接BN层,其输出层
后无ReLU,隐含层的
的维度为2048,MLP包含三个全连接层。
Prediction MLP:预测MLP中同样适用了BN层,但其输出层
后无BN与ReLU。MLP有2个全连接层,第一个全连接层的输入与输出维度为2048,第二个的输出维度为512.
Backbone:作者选用了ResNet50作为骨干网络。
作者在ImageNet上线进行无监督预训练,然后采用监督方式冻结骨干网络训练分类头,最后在验证集上验证其性能。
Empirical Study
在该部分内容中,我们将实证研究SimSiam的表现,主要聚焦于哪些行为有助于避免“崩溃解”。
Stop-gradient
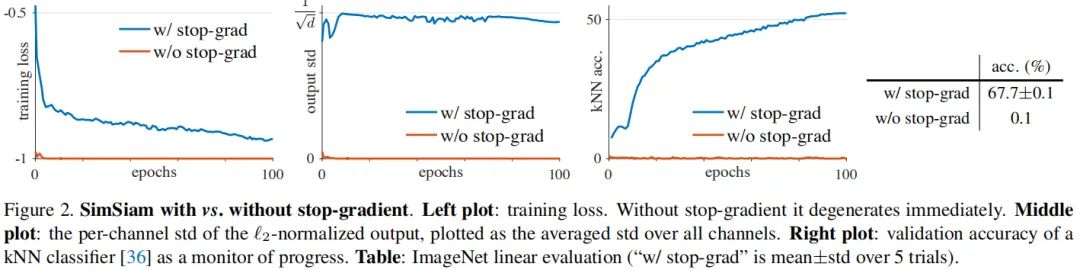
上图给出了Stop-gradient添加与否的性能对比,注网络架构与超参保持不变,区别仅在于是否添加Stop-gradient。
上图left表示训练损失,可以看到:在无Stop-gradient时,优化器迅速找了了一个退化解并达到了最小可能损失-1。为证实上述退化解是“崩溃”导致的,作者研究了输出的
规范化结果的标准差。如果输出“崩溃”到了常数向量,那么其每个通道的标准差应当是0,见上图middle。
作为对比,如果输出具有零均值各项同性高斯分布,可以看到其标准差为
。上图middle中的蓝色曲线(即添加了Stop-gradient)接近
,这也就意味着输出并没有“崩溃”。
上图right给出了KNN分类器的验证精度,KNN分类器可用于训练过程的监控。在无Stop-gradient时,其分类进度仅有0.1%,而添加Stop-gradient后最终分类精度可达67.7%。
上述实验表明:“崩溃”确实存在。但“崩溃”的存在不足以说明所提方法可以避免“崩溃”,尽管上述对比中仅有“stop-gradient”的区别。
Predictor

上表给出了Predictor MLP的影响性分析,可以看到:
当移除预测MLP头模块h(即h为恒等映射)后,该模型不再有效(work);
如果预测MLP头模块h固定为随机初始化,该模型同样不再有效;
当预测MLP头模块采用常数学习率时,该模型甚至可以取得比基准更好的结果(多个实验中均有类似发现).
Batch Size
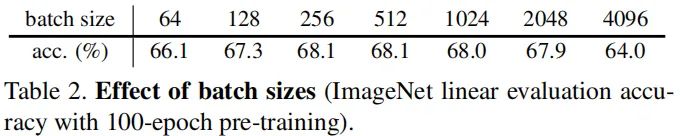
上表给出了Batch Size从64变换到4096过程中的精度变化,可以看到:该方法在非常大范围的batch size下表现均非常好。
Batch Normalization

上表比较了投影与预测MLP中不同BN的配置对比,可以看到:
移除所有BN层后,尽管精度只有34.6%,但不会造成“崩溃”;这种低精度更像是优化难问题,对隐含层添加BN后精度则提升到了67.4%;
在投影MLP的输出后添加BN,精度可以进一步提升到68.1%;
在预测MLP的输出添加BN后反而导致训练变的不稳定。
总而言之,BN有助于训练优化,这与监督学习中BN的作用类似;但并未看到BN有助于避免“崩溃”的证据。
Similarity Function
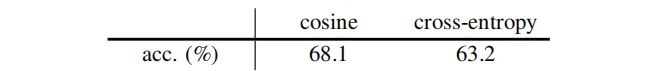
所提方法除了与cosine相似性组合表现好外,其与交叉熵相似组合表现同样良好,见上表。此时的交叉熵相似定义如下:
可以看到:交叉熵相似性同样可以收敛到一个合理的解并不会导致“崩溃”,这也就是意味着“崩溃”避免行为与cosine相似性无关。
Symmetrization

尽管前述描述中用到了对称损失,但上表的结果表明:SimSiam的行为不依赖于对称损失:非对称损失同样取得了合理的结果,而对称损失有助于提升精度,这与“崩溃”避免无关。
Summary
通过上面的一些列消融实验对比分析,可以看到:SimSiam可以得到有意义的结果而不会导致“崩溃”。优化器、BN、相似性函数、对称损失可能会影响精度,但与“崩溃”避免无关;对于“崩溃”避免起关键作用的是stop-gradient操作。
Hypothesis
接下来,我们将讨论:SimSiam到底在隐式的优化什么?并通过实验对其进行验证。主要从定义、证明以及讨论三个方面进行介绍。
Formulation
作者假设:SimSiam是类期望最大化算法的一种实现。它隐含的包含两组变量,并解决两个潜在子问题,而stop-gradient操作是引入额外变换的结果。我们考虑如下形式的损失:
其中
分别表示特征提取网络与数据增广方法,x表示图像。在这里,作者引入了另外一个变量
,其大小正比于图像数量,直观上来讲,
是x的特征表达。
基于上述表述,我们考虑如下优化问题:
这种描述形式类似于k-means聚类问题,变量
与聚类中心类似,是一个可学习参数;变量
与样本x的对应向量(类似k-means的one-hot向量)类似:即它是x的特征表达。类似于k-means,上述问题可以通过交替方案(固定一个,求解另一个)进行求解:
对于
的求解,可以采用SGD进行子问题求解,此时stop-gradient是一个很自然的结果,因为梯度先不要反向传播到
,在该子问题中,它是一个常数;对于
的七届,上述问题将转换为:
结合前述介绍,SimSiam可以视作上述求解方案的一次性交替近似。
此外需要注意:(1)上述分析并不包含预测器h;(2) 上述分析并不包含对称损失,对称损失并非该方法的必选项,但有助于提升精度。
Proof of concept
作者假设:SimSiam是一种类似交错优化的方案,其SGD更新间隔为1。基于该假设,所提方案在多步SGD更新下同样有效。为此,作者设计了一组实验验证上述假设,结果见下表。

在这里,
等价与SimSiam。可以看到:multi-step variants work well。更多步的SGD更新甚至可以取得比SimSiam更优的结果。这就意味着:交错优化是一种可行的方案,而SimSiam是其特例。
Comparison
前述内容已经说明了所提方法的有效性,接下来将从ImageNet以及迁移学习的角度对比一下所提方法与其他SOTA方法。

上图给出了所提方法与其他SOTA无监督学习方法在ImageNet的性能,可以看到:SimSiam可以取得具有竞争力的结果。在100epoch训练下,所提方法具有最高的精度;但更长的训练所得收益反而变小。
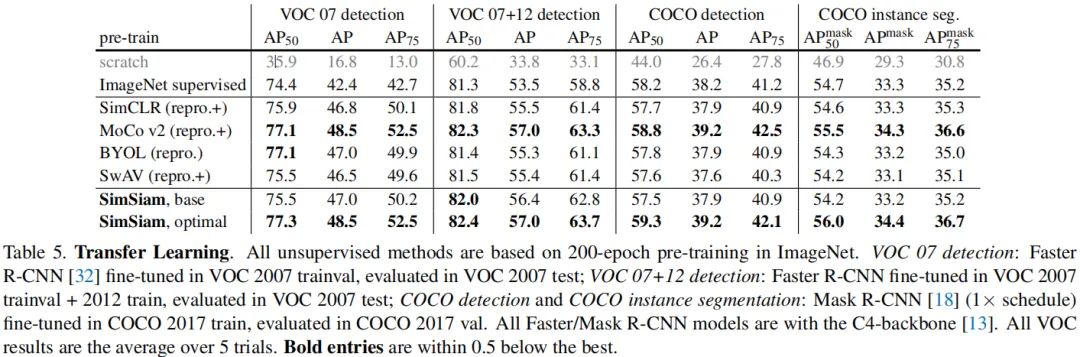
上表给出了所提方法与其他SOTA方法在迁移学习方面的性能对比。从中可以看到:SimSiam表达可以很好的迁移到ImageNet以外的任务上,迁移模型的性能极具竞争力。
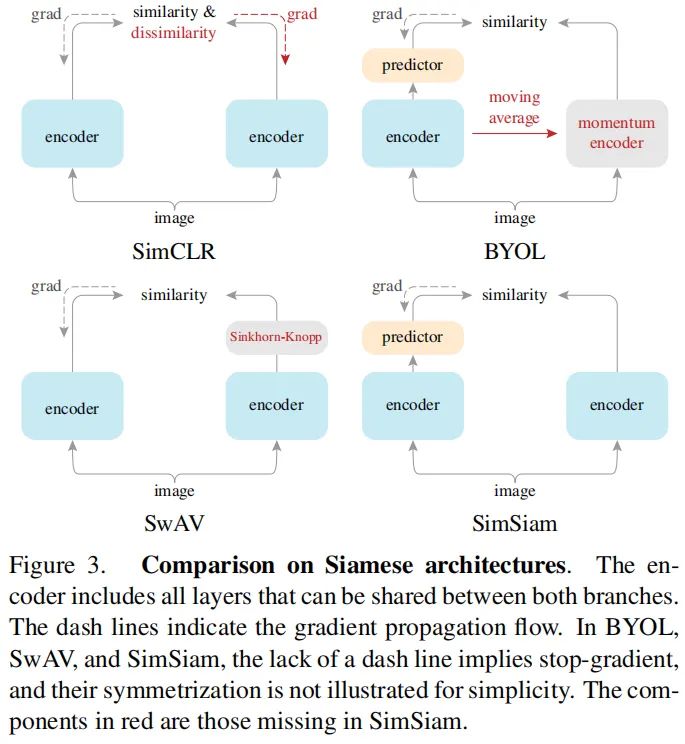
最后,作者对比了所提方法与其他SOTA方法的区别&联系所在,见上图。
Relation to SimCLR:SimCLR依赖于负采样以避免“崩溃”,SimSiam可以是作为“SimCLR without negative”。
Relation to SwAV:SimSiam可以视作“SwAV without online clustering”.
Relation to BYOL: SimSiam可以视作“BYOL without the momentum encoder”.
全文到此结束,对该文感兴趣的同学建议去查看原文的实验结果与实验分析。
Conclusion
该文采通过非常简单的设计探索了孪生网络,所提方法方法的有效性意味着:孪生形状是这些表达学习方法(SimCLR, MoCo,SwAR等)成功的关键原因所在。孪生网络天然具有建模不变性的特征,而这也是表达学习的核心所在。
相关文章
SimCLR: A simple framework for contrastive learning of visual representations
SimCLRv2: Big self-supervised models are strong semi-supervised learners.
SwAV:Unsupervised learning of visual features by contrasting cluster assignments
MoCo: Momentum contrast for unsupervised visual representation learning.
MoCov2:Improved baselines with momentum contrastive learning
BYOL: Bootstrap your own latten: A new aproach to self-supervised learning.
CPC: Data efficient image recognition with contrastive predictive coding.
PIC: Parametric instance classification for unsupervised visual feature learning.
下载1:leetcode 开源书
在「AI算法与图像处理」公众号后台回复:leetcode,即可下载。每题都 runtime beats 100% 的开源好书,你值得拥有!
下载2 CVPR2020
在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文
个人微信(如果没有备注不拉群!)
请注明:地区+学校/企业+研究方向+昵称

觉得不错就点亮在看吧
