
最优Mask比例高达90%!恺明团队新作:MAE"入局"视频表达学习

极市导读
今天,恺明团队对MAE进行了扩展,将其用于视频表达学习,再一次表达MAE的优异性:最优Mask比例高达90%,在可以学习到强表达能力的同时在空时方面具有almost no inductive bias特性。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
前段时间,何恺明团队提出MAE在CV届引起极大轰动,自上传到arxiv之后,各种"YYDS", "Best Paper预定"等,关于MAE的介绍可参考以下两个介绍:
CVPR 2022 Oral|何恺明一作:简单实用的自监督学习方案MAE,ImageNet-1K 87.8%!
就在今天,恺明团队对MAE进行了扩展,将其用于视频表达学习,再一次表达MAE的优异性:最优Mask比例高达90%,在可以学习到强表达能力的同时在空时方面具有almost no inductive bias特性。总而言之,Masked AtuoEncoding(如BERT、MAE等)是一种统一的具有最小领域知识表达学习方法。

论文链接:https://arxiv.org/abs/2205.09113
恺明的paper最精彩的有两点:(1) idea足够简单;(2) 实验足够充分。所以本文仅为抛转引玉之述,更精彩的实验部分请移步原文,原文更精彩。
本文方案为MAE的一个简单的扩展,即将图像领域的MAE向视频领域扩展。其目的在于:在尽可能少的领域知识下,研发一种广义且统一的框架。
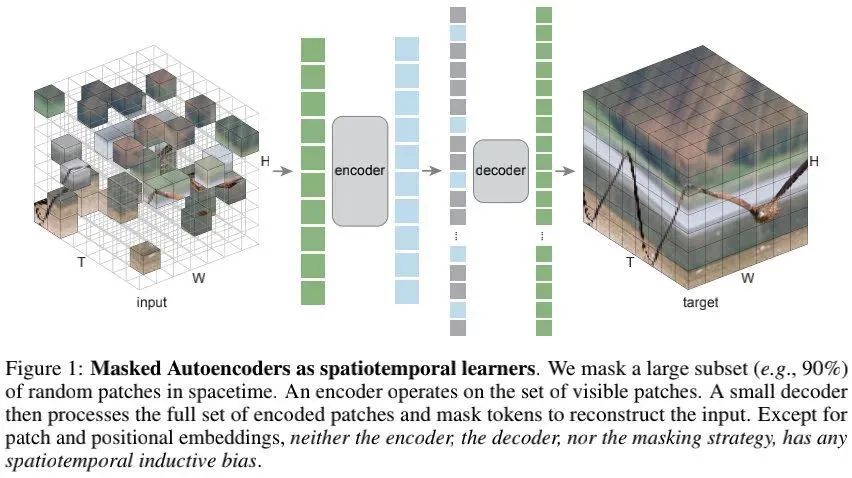
上图给出了本文所提出方案的整体架构示意图,它主要包含以下几点技术点:
Patch Embedding : 类似ViT,给定视频片段,我们将其沿空时维度拆分为无重叠的规则的网格块(grid),然后将这些网格块进行flatten并经由线性投影层进行处理。此外,对每个网格快还添加了位置嵌入信息。注:这里的块与位置嵌入过程只仅有的空时感知处理。 Masking : 我们对前述所得块嵌入信息进行随机采样,这里的随机采样类似于BERT和MAE。注1:这里的随机采样具有空时不可感知性。

MAE一文的研究表明:最优Mask比例与数据的信息冗余相关。加持上非结构化随机Mask,BERT的15%与MAE的75%表明:相比语言,图像具有更强的信息冗余。本文的研究(高达90%的Mask比例)进一步支撑了该假设,上图给出了90%与95%Mask比例的MAE在未知验证集上重建结果。
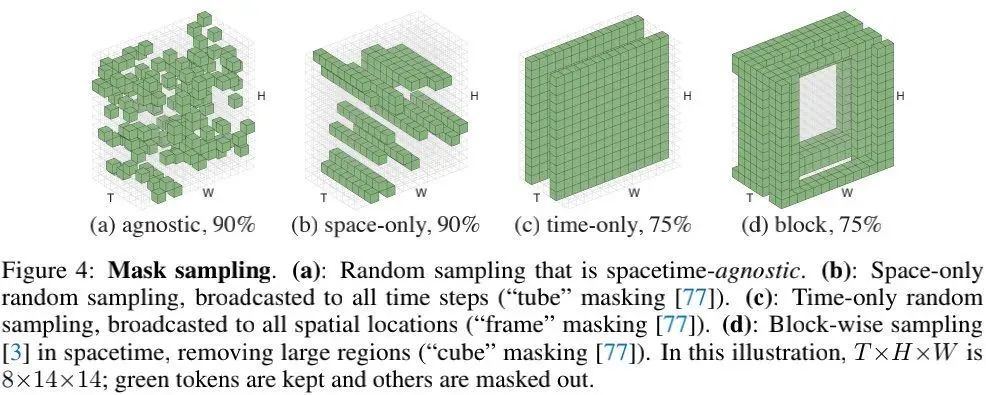
相比结构感知采样策略(如上图b-d),本文的空时不可知采样策略(见上图a)更加高效。由于近邻块在空时维度上的相关性,结构感知采样策略的最优Mask比例往往比较低。相反,空时不可知采样策略可以更好的利用有限数量的可见块(visible patches),进而达成更高的Mask比例。
AutoEncoding : 延续MAE方案,本文的编码器ViT仅作用于可见块嵌入。这种设计有助于减少内存占用与推理耗时,达成更实用的方案。高达90%的Mask比例可以将编码器的计算复杂减少到 10%以下。类似MAE,解码器同样采用了ViT架构,且比编码小还要小。尽管解码器作用于全部的token,但其复杂度比编码器小。在默认配置下,自编码器的整体复杂度比标准自编码器方案(即输入端不进行Mask)小7.7x。
Experiments
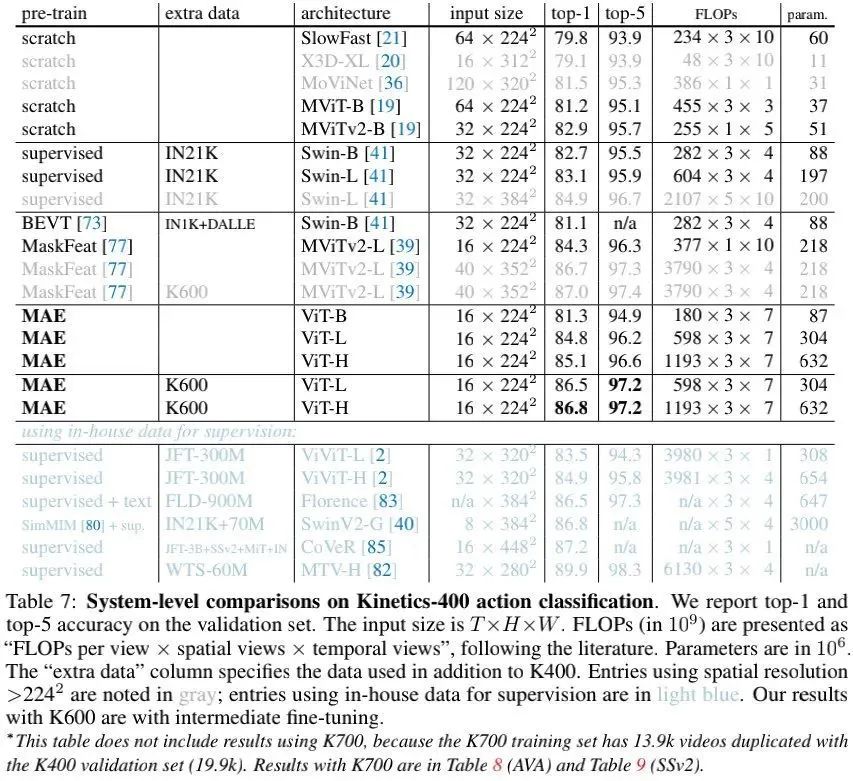
上表给出了Kinetics-400(K400)数据集上的性能对比,可以看到:相比SOTA方案,本文方案极具竞争力。本文方案是仅有的vanilla ViT方案,其他方案均为分层架构或转为视频而设计的架构。
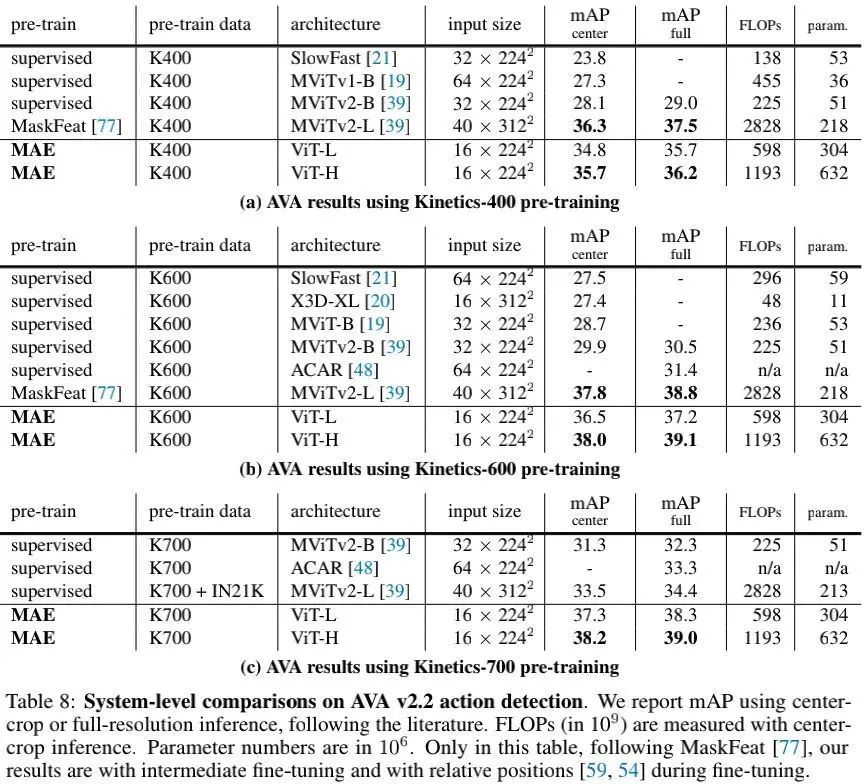
上表给出了AVA数据集上的性能对比, 可以看到: 仅需 , 所提方案取得了与MaskFeat(其输 入分辨率更高 )相当的性能。更重要的是, 该方案采用了PlainViT架构, 无需在检测任务上 表现更好的分层特征。
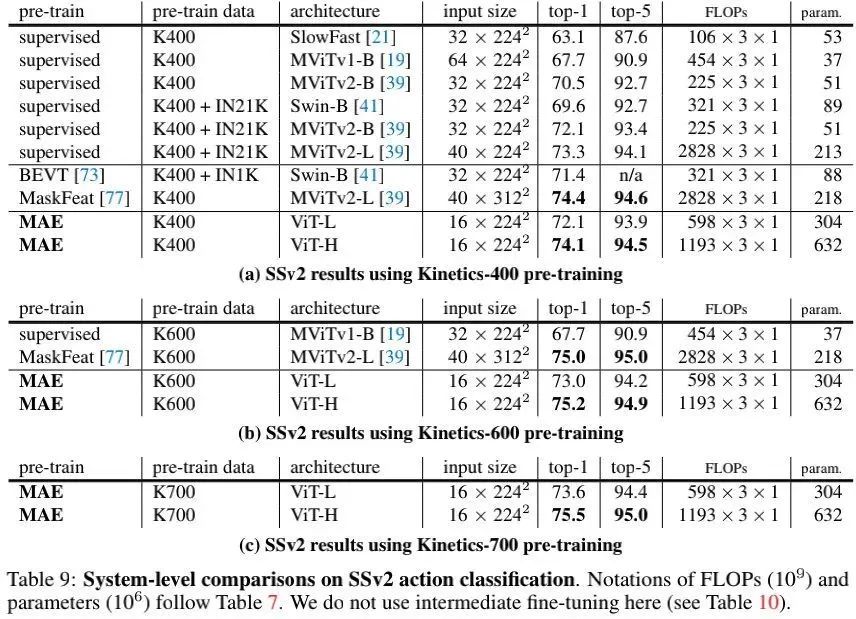
上表给出了SSv2数据集上的性能对比, 可以看到:仅需 输入的VanillaViT方案具有与 输入的MaskFeat方案相当的性能。
公众号后台回复“目标检测竞赛”获取竞赛经验分享~

