yolov5使用冻结层进行迁移学习
模型而无需重新训练整个网络的有用方法。相反,部分初始权重被冻结,其余权重用于计算损失并由优化器更新。这需要比正常训练更少的资源并允许更快的训练时间,但它也可能导致最终训练准确度的降低。
在你开始前
克隆这个 repo 并安装requirements.txt依赖项,包括Python>=3.8和PyTorch>=1.7。
$ git clone https://github.com/ultralytics/yolov5 # clone repo
$ cd yolov5
$ pip install wandb -qr requirements.txt # install requirements.txt
冻结主干
freeze在训练开始之前,所有与train.py中的列表匹配的层将通过将其梯度设置为零来冻结。https://github.com/ultralytics/yolov5/blob/58f8ba771e3712b525ca93a1ee66bc2b2df2092f/train.py#L83-L90
要查看模块名称列表:
for k, v in model.named_parameters():
print(k)
# Output
model.0.conv.conv.weight
model.0.conv.bn.weight
model.0.conv.bn.bias
model.1.conv.weight
model.1.bn.weight
model.1.bn.bias
model.2.cv1.conv.weight
model.2.cv1.bn.weight
...
model.23.m.0.cv2.bn.weight
model.23.m.0.cv2.bn.bias
model.24.m.0.weight
model.24.m.0.bias
model.24.m.1.weight
model.24.m.1.bias
model.24.m.2.weight
model.24.m.2.bias
查看模型架构我们可以看到模型主干是第 0-9 层:https://github.com/ultralytics/yolov5/blob/58f8ba771e3712b525ca93a1ee66bc2b2df2092f/models/yolov5s.yaml#L12-L48
所以我们定义冻结列表以包含所有带有“model.0”的模块。- 'model.9.' 以他们的名义,然后我们开始训练。
freeze = ['model.%s.' % x for x in range(10)] # parameter names to freeze (full or partial)
冻结所有图层
为了冻结除 Detect() 中的最终输出卷积层之外的完整模型,我们将冻结列表设置为包含所有带有“model.0”的模块。- 'model.23.' 以他们的名义,然后我们开始训练。
freeze = ['model.%s.' % x for x in range(24)] # parameter names to freeze (full or partial)
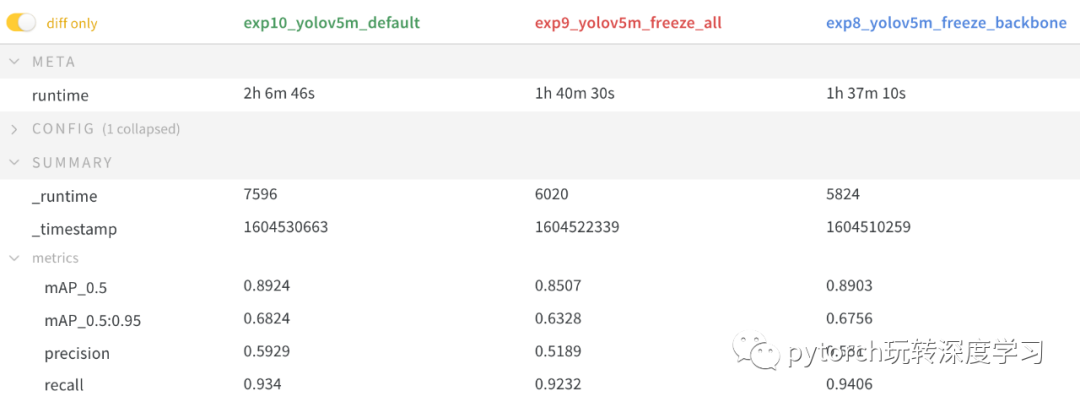
结果
我们在上述两个场景中对 VOC 进行了 YOLOv5m 训练,并使用了一个默认模型(不冻结),从官方 COCO 预训练开始--weights yolov5m.pt。所有运行的训练命令是:
$ train.py --batch 48 --weights yolov5m.pt --data voc.yaml --epochs 50 --cache --img 512 --hyp hyp.finetune.yaml
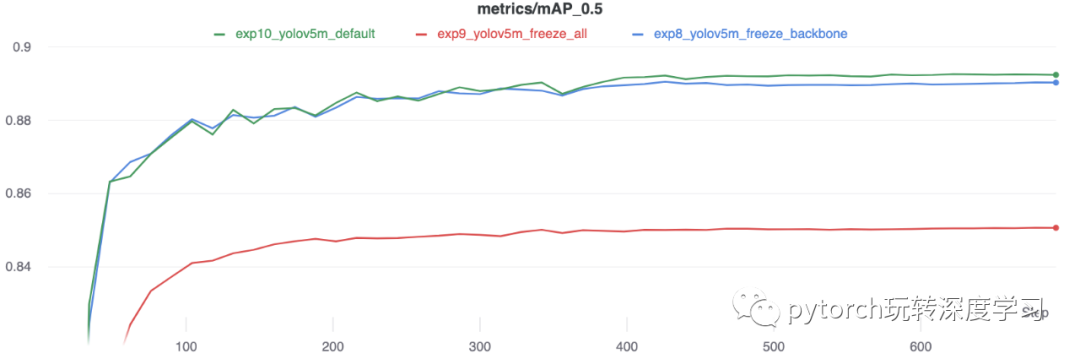
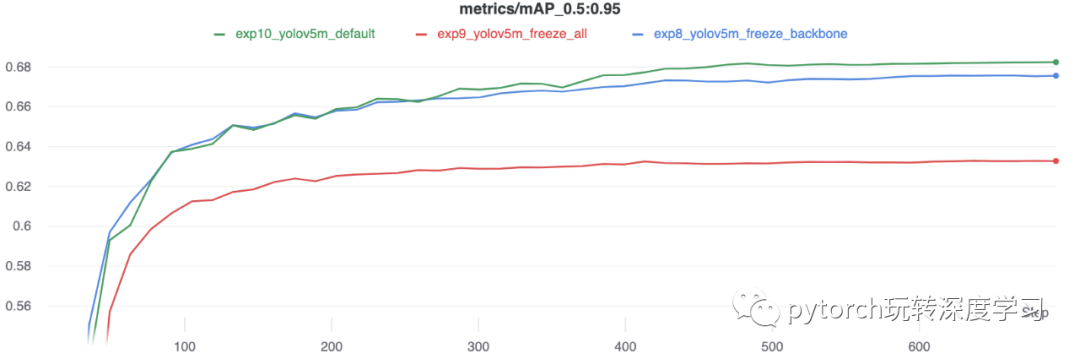
精度比较
结果表明,冻结可以加快训练速度,但会略微降低最终准确率。运行的完整 W&B 报告可在此链接中找到:https://wandb.ai/glenn-jocher/yolov5_tutorial_freeze/reports/Freezing-Layers-in-YOLOv5--VmlldzozMDk3NTg
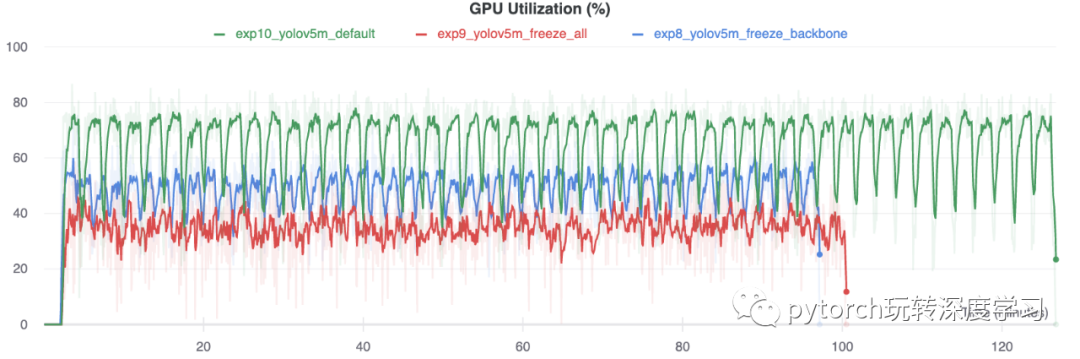
GPU利用率比较
有趣的是,冻结的模块越多,训练所需的 GPU 内存就越少,GPU 利用率也就越低。这表明较大的模型或以较大 --image-size 训练的模型可能会受益于冻结以便更快地训练。