
一个用于styleGAN图像处理的编码器
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

源码链接:https://github.com/omertov/encoder4editing
最近,通过使用预先训练过的无条件生成器来执行图像编辑的各种方法出现了激增。然而,在真实图像上应用这些方法仍然是一个挑战,因为它必然需要将图像反转到它们的潜在空间。为了成功地反转真实图像,需要找到一种潜在的代码来准确地重建输入图像,更重要的是,允许对其进行有意义的操作。本文详细研究了最先进的无条件生成器StyleGAN的潜在空间。作者识别并分析在样式潜在空间中存在的扭曲-可编辑性权衡和扭曲-感知权衡。然后,作者提出了两个设计编码器的原则,使其能够控制与StyleGAN最初训练的区域的倒置的接近性。作者提出了一个基于作者的两个原则的编码器,这是专为促进编辑真实图像,通过平衡这些权衡。通过对其在包括汽车和马在内的众多具有挑战性的领域的性能进行定性和定量评价,作者证明了作者的反演方法,以及常见的编辑技术,在只有很小的重建精度下降的情况下,获得了较高的真实图像编辑质量。
提出了定量和定性的结果证明distortion-editability distortion-perception权衡,和反相接近的好处w .作者评估作者的编码器,显示作者的方法及其适用性的泛化为各种具有挑战性的领域,与面部域不同,没有共同的结构和可能包含大量的模式。在下图中,作者展示了编码器在多个领域中获得的反转,以及使用各种编辑方法执行的几个操作。可以看到,只有轻微的失真退化,作者能够实现合理的编辑图像,同时保留原始图像的内容和质量。
总结一下,作者提出了四个主要贡献:
作者分析了柱体的复杂潜伏空间,提出了柱体结构的新观点。
作者展示了扭曲、感知和可编辑性之间固有的权衡。
作者描述了这种权衡,并设计了两种编码器来控制它们。
作者提出了e4e,一种新的编码器,是专门设计的,允许随后编辑倒转的真实图像。
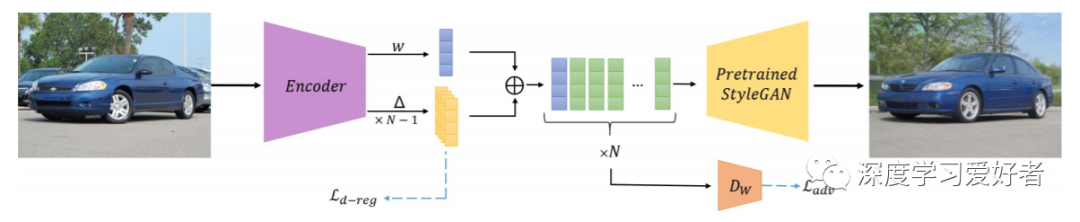
作者的e4e网络架构。编码器接收一个输入图像,并输出一个样式代码w和一组偏移量1..N 1,其中N为StyleGAN s风格调制层数。作者通过复制w向量N次并将每个i加到对应的元素来获得最终的潜在表示法。在训练期间,Ld-reg正则化鼓励最终表示的不同条目之间存在较小的差异,从而保持接近W。Ladv将每个潜在代码引导到StyleGAN映射网络的范围内,从而使最终的表示更接近于Wk。由于应用了这两个正则化项,编码器的最终学习表示接近于W。

作者展示了源图像的三联体,它的反演,以及对多个域的反演图像应用的编辑。在奇数行,作者的基线编码器(A)获得反演。在偶数行,作者使用配置D,对接近w的图像进行编码,观察反演图像的失真和感知质量之间的权衡。例如,在白马的图像中,使用构型A观察倒像的低失真(例如马鞍被保留)。但是,感知质量比D得到的要低(如马头不真实)。关于可编辑性,请注意,在女性的左上角图像中,姿态编辑并没有忠实地改变a中的头发。相反,D以失真的细微退化为代价,获得了一个真实且视觉愉悦的编辑结果。从上到下,从左到右的编辑是:头部姿势,性别,日光,观点(x3),马姿势,骑马者,猫姿势。

扭曲感知和扭曲编辑的权衡。放大细节。左边的图像是源图像。在顶部一行,作者展示了一系列图像,其中最左边的图像是通过pSp得到的重建图像,最右边的图像是通过e4e得到的重建图像。当作者向右移动时,反转越接近W,失真越严重,感知质量越好。然后,作者使用StyleFlow对每个倒置和插值图像执行性别编辑。注意,当用于编辑的潜在代码接近W时,感知质量变得明显更好。例如,观察最左边编辑过的图像中不真实的头发。
作者的主要贡献有两方面:
作者提出了鼓励将真实图像的编码映射到表现良好的Wk区域的方法;
作者设计了一个编码器,并根据失真和可编辑性之间的权衡,演示了其性能。
作者也讨论了评估重构和可编辑性的困难,并提出了建立在常用措施上的评估协议。从某种意义上说,作者提出的方法是对图像处理方法的一种补充,可以提高真实图像的编辑质量。
一般来说,作者的编码器鼓励映射接近W,这工作得很好,因为W周围的空间仍然是令人惊讶的高度表达。此外,该原理还可用于图像反演以外的问题。例如,它可以应用于地图潜在的向量代表多个图像,或者说两个的组合,如身份和姿态的解离表示,或混合的两个图片,一个合适的潜在目标图像的代码可能存在于邻近w。作者计划去探索这个研究方向。
作者的反演方案是通用的,作者已经在五个具有挑战性和多样化的领域展示了它的性能。然而,请注意,有些领域比其他领域更难。人脸结构良好,简化了编码器的训练。例如,马的领域就复杂得多,因为它是非结构化的,并且有许多模式。因此,训练这样一个领域的编码器是非常具有挑战性的。在未来,作者将考虑像Sendik等人那样的多模态生成器,并将编码器开发成多模态潜在空间。
最后,在这里作者考虑到一个给定的潜在空间的反转。在未来,考虑对生成器进行微调,并训练编码器和解码器,使其针对特定的下游任务实现共同目标,将是一件有趣且具有挑战性的事情。
论文链接:https://arxiv.org/pdf/2102.02766.pdf
每日坚持论文分享不易,如果喜欢我们的内容,希望可以推荐或者转发给周围的同学。
- END -
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~