
Flink 实践 | 37 手游基于 Flink CDC + Hudi 湖仓一体方案实践
Flink CDC 基本知识介绍 Hudi 基本知识介绍 37 手游的业务痛点和技术方案选型 37 手游湖仓一体介绍 Flink CDC + Hudi 实践 总结
 GitHub 地址
GitHub 地址 一、Flink-CDC 2.0
Flink CDC Connectors 是 Apache Flink 的一个 source 端的连接器,目前 2.0 版本支持从 MySQL 以及 Postgres 两种数据源中获取数据,2.1 版本社区确定会支持 Oracle,MongoDB 数据源。
Fink CDC 2.0 的核心 feature,主要表现为实现了以下三个非常重要的功能:
全程无锁,不会对数据库产生需要加锁所带来的风险;
多并行度,全量数据的读取阶段支持水平扩展,使亿级别的大表可以通过加大并行度来加快读取速度; 断点续传,全量阶段支持 checkpoint,即使任务因某种原因退出了,也可通过保存的 checkpoint 对任务进行恢复实现数据的断点续传。
Flink CDC Connectors: https://ververica.github.io/flink-cdc-connectors/master/index.html
二、Hudi
Apache Hudi 目前被业内描述为围绕数据库内核构建的流式数据湖平台 (Streaming Data Lake Platform)。
由于 Hudi 拥有良好的 Upsert 能力,并且 0.10 Master 对 Flink 版本支持至 1.13.x,因此我们选择通过 Flink + Hudi 的方式为 37 手游的业务场景提供分钟级 Upsert 数据的分析查询能力。
Apache Hudi: https://hudi.apache.org/docs/overview/
三、37 手游的业务痛点和技术方案选型
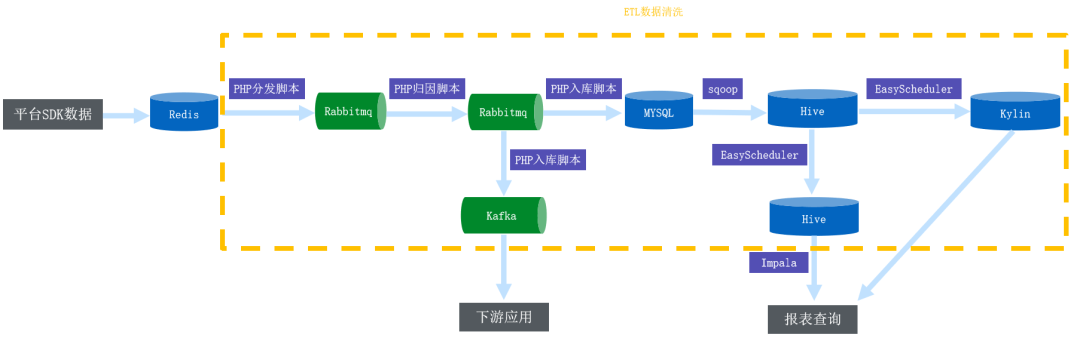
1. 旧架构与业务痛点
■ 1.1 数据实时性不够
日志类数据通过 sqoop 每 30min 同步前 60min 数据到 Hive;
数据库类数据通过 sqoop 每 60min 同步当天全量数据到 Hive;
数据库类数据通过 sqoop 每天同步前 60 天数据到 Hive。
■ 1.2 业务代码逻辑复杂且难维护
目前 37 手游还有很多的业务开发沿用 MySQL + PHP 的开发模式,代码逻辑复杂且很难维护; 相同的代码逻辑,往往流处理需要开发一份代码,批处理则需要另开发一份代码,不能复用。
■ 1.3 频繁重刷历史数据
频繁地重刷历史数据来保证数据一致。
■ 1.4 Schema 变更频繁
由于业务需求,经常需要添加表字段。
■ 1.5 Hive 版本低
目前 Hive 使用版本为 1.x 版本,并且升级版本比较困难; 不支持 Upsert; 不支持行级别的 delete。
2. 技术选型
四、新架构与湖仓一体
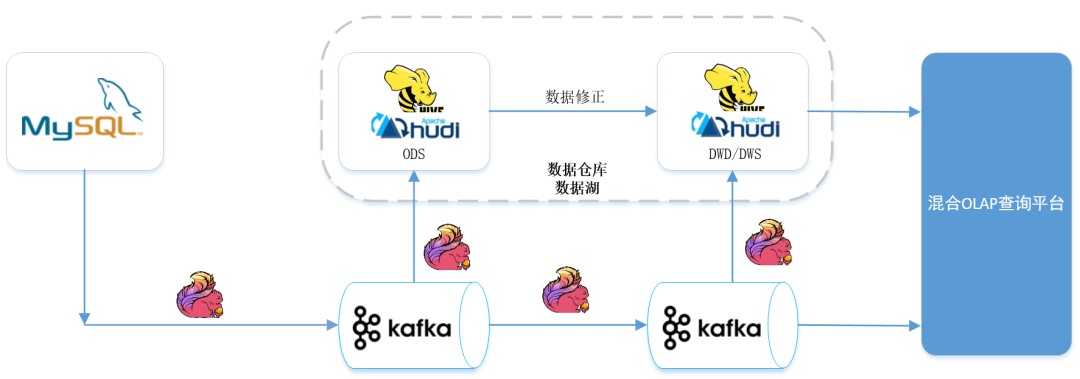
五、Flink CDC 2.0 + Kafka + Hudi 0.10
实践
Flink 1.13.2 .../lib/hudi-flink-bundle_2.11-0.10.0-SNAPSHOT.jar (修改 Master 分支的 Hudi Flink 版本为 1.13.2 然后构建) .../lib/hadoop-mapreduce-client-core-2.7.3.jar (解决 Hudi ClassNotFoundException) ../lib/flink-sql-connector-mysql-cdc-2.0.0.jar ../lib/flink-format-changelog-json-2.0.0.jar ../lib/flink-sql-connector-kafka_2.11-1.13.2.jar
create table sy_payment_cdc (ID BIGINT,...PRIMARY KEY(ID) NOT ENFORCED) with('connector' = 'mysql-cdc','hostname' = '','port' = '','username' = '','password' = '','database-name' = '','table-name' = '','connect.timeout' = '60s','scan.incremental.snapshot.chunk.size' = '100000','server-id'='5401-5416');
create table sy_payment_cdc2kafka (ID BIGINT,...PRIMARY KEY(ID) NOT ENFORCED) with ('connector' = 'kafka','topic' = '','scan.startup.mode' = 'latest-offset','properties.bootstrap.servers' = '','properties.group.id' = '','key.format' = '','key.fields' = '','format' = 'changelog-json');create table sy_payment2hudi (ID BIGINT,...PRIMARY KEY(ID) NOT ENFORCED)PARTITIONED BY (YMD)WITH ('connector' = 'hudi','path' = 'hdfs:///data/hudi/m37_mpay_tj/sy_payment','table.type' = 'COPY_ON_WRITE','partition.default_name' = 'YMD','write.insert.drop.duplicates' = 'true','write.bulk_insert.shuffle_by_partition' = 'false','write.bulk_insert.sort_by_partition' = 'false','write.precombine.field' = 'MTIME','write.tasks' = '16','write.bucket_assign.tasks' = '16','write.task.max.size' = '','write.merge.max_memory' = '');
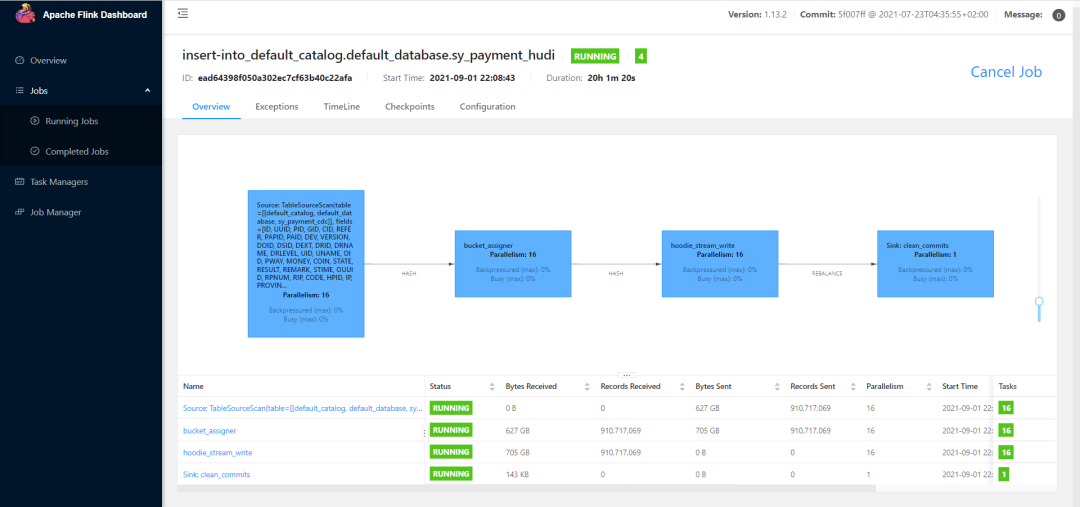
之前 Flink CDC 1.x 版本由于全量 snapshot 阶段单并行度读取的原因,当时亿级以上的表在全量 snapshot 读取阶段就需要耗费很长时间,并且 checkpoint 会失败无法保证数据的断点续传。
所以当时入 Hudi 是采用先启动一个 CDC 1.x 的程序将此刻开始的增量数据写入 Kafka,之后再启动另外一个 sqoop 程序拉取当前的所有数据至 Hive 后,通过 Flink 读取 Hive 的数据写 Hudi,最后再把 Kafka 的增量数据从头消费接回 Hudi。由于 Kafka 与 Hive 的数据存在交集,因此数据不会丢失,加上 Hudi 的 upsert 能力保证了数据唯一。
但是,这种方式的链路太长操作困难,如今通过 CDC 2.0 在全量 snapshot 阶段支持多并行度以及 checkpoint 的能力,确实大大降低了架构的复杂度。
2. 数据比对
由于生产环境用的是 Hive1.x,Hudi 对于 1.x 还不支持数据同步,所以通过创建 Hive 外部表的方式进行查询,如果是 Hive2.x 以上版本,可参考 Hive 同步章节; 创建 Hive 外部表 + 预创建分区; auxlib 文件夹添加 Hudi-hadoop-mr-bundle-0.10.0-SNAPSHOT.jar。
CREATE EXTERNAL TABLE m37_mpay_tj.`ods_sy_payment_f_d_b_ext`(`_hoodie_commit_time` string,`_hoodie_commit_seqno` string,`_hoodie_record_key` string,`_hoodie_partition_path` string,`_hoodie_file_name` string,`ID` bigint,...)PARTITIONED BY (`dt` string)ROW FORMAT SERDE'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'STORED AS INPUTFORMAT'org.apache.hudi.hadoop.HoodieParquetInputFormat'OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'LOCATION'hdfs:///data/hudi/m37_mpay_tj/sy_payment'
总数一致; 按天分组统计数量一致; 按天分组统计金额一致。
Hive 同步章节:
https://www.yuque.com/docs/share/01c98494-a980-414c-9c45-152023bf3c17?#IsoNU
六、总结
Hudi 提供了 Upsert 能力,解决频繁 Upsert/Delete 的痛点; 提供分钟级的数据,比传统数仓有更高的时效性; 基于 Flink-SQL 实现了流批一体,代码维护成本低; 数据同源、同计算引擎、同存储、同计算口径; 选用 Flink CDC 作为数据同步工具,省掉 sqoop 的维护成本。
Reference
[1] MySQL CDC 文档:
https://ververica.github.io/flink-cdc-connectors/master/content/connectors/mysql-cdc.html
[2] Hudi Flink 答疑解惑:
https://www.yuque.com/docs/share/01c98494-a980-414c-9c45-152023bf3c17?#
[3] Hudi 的一些设计:
https://www.yuque.com/docs/share/5d1c383d-c3fc-483a-ad7e-d8181d6295cd?#
 戳我,查看更多技术文章!
戳我,查看更多技术文章!