
快手基于 Flink 构建实时数仓场景化实践
一、快手实时计算场景
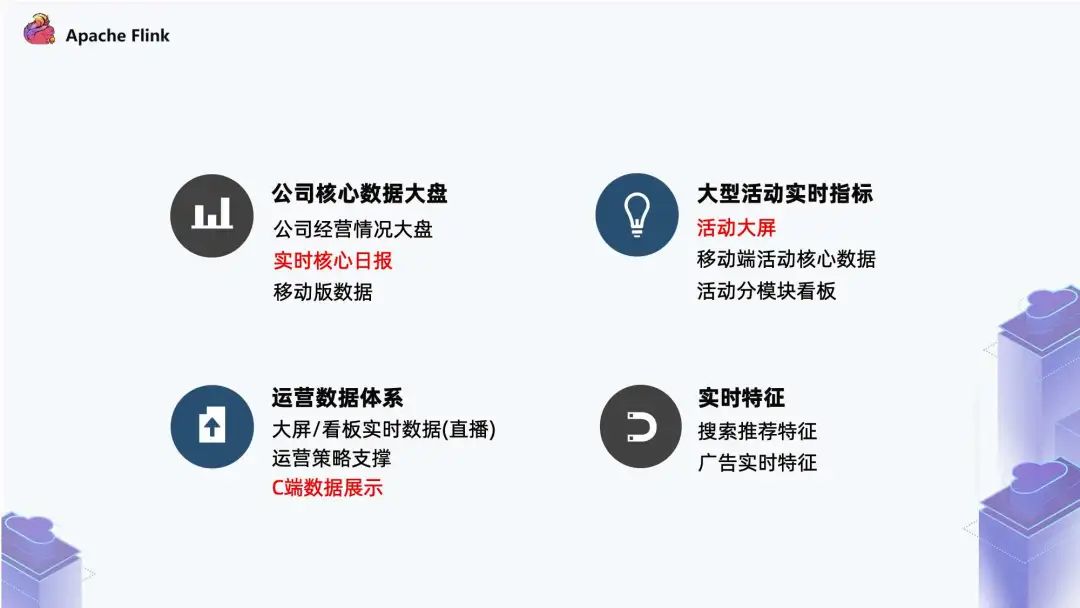
公司级别的核心数据:包括公司经营大盘,实时核心日报,以及移动版数据。相当于团队会有公司的大盘指标,以及各个业务线,比如视频相关、直播相关,都会有一个核心的实时看板;
大型活动实时指标:其中最核心的内容是实时大屏。例如快手的春晚活动,我们会有一个总体的大屏去看总体活动现状。一个大型的活动会分为 N 个不同的模块,我们对每一个模块不同的玩法会有不同的实时数据看板;
运营部分的数据:运营数据主要包括两方面,一个是创作者,另一个是内容。对于创作者和内容,在运营侧,比如上线一个大 V 的活动,我们想看到一些信息如直播间的实时现状,以及直播间对于大盘的牵引情况。基于这个场景,我们会做各种实时大屏的多维数据,以及大盘的一些数据。
此外,这块还包括运营策略的支撑,比如我们可能会实时发掘一些热点内容和热点创作者,以及目前的一些热点情况。我们基于这些热点情况输出策略,这个也是我们需要提供的一些支撑能力;
最后还包括 C 端数据展示,比如现在快手里有创作者中心和主播中心,这里会有一些如主播关播的关播页,关播页的实时数据有一部分也是我们做的。
实时特征:包含搜索推荐特征和广告实时特征。
二、快手实时数仓架构及保障措施
1. 目标及难点
■ 1.1 目标
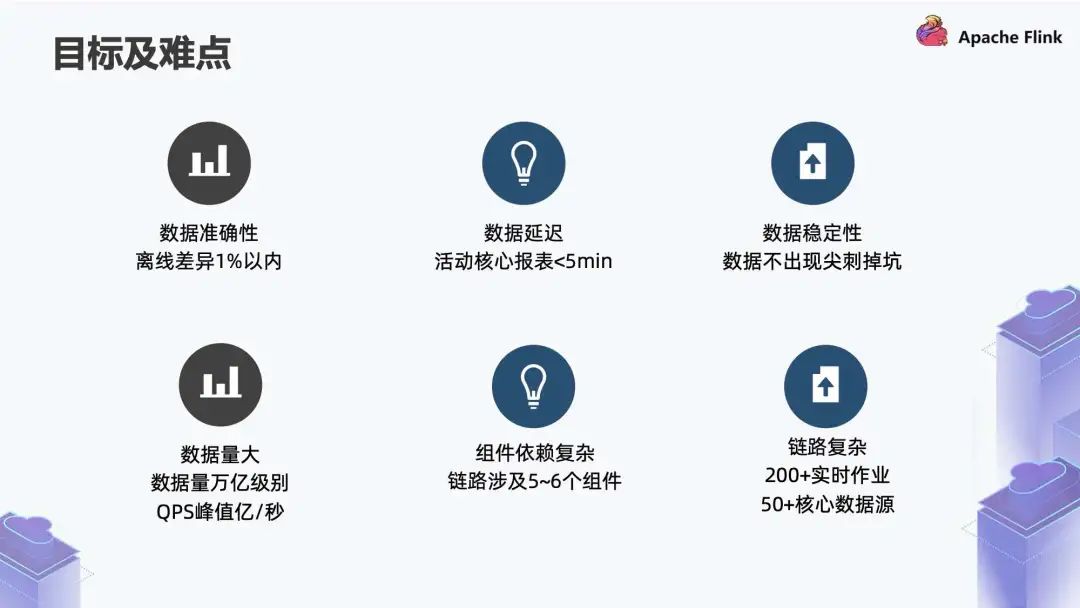
首先由于我们是做数仓的,因此希望所有的实时指标都有离线指标去对应,要求实时指标和离线指标整体的数据差异在 1% 以内,这是最低标准。
其次是数据延迟,其 SLA 标准是活动期间所有核心报表场景的数据延迟不能超过 5 分钟,这 5 分钟包括作业挂掉之后和恢复时间,如果超过则意味着 SLA 不达标。
最后是稳定性,针对一些场景,比如作业重启后,我们的曲线是正常的,不会因为作业重启导致指标产出一些明显的异常。
■ 1.2 难点
第一个难点是数据量大。每天整体的入口流量数据量级大概在万亿级。在活动如春晚的场景,QPS 峰值能达到亿 / 秒。
第二个难点是组件依赖比较复杂。可能这条链路里有的依赖于 Kafka,有的依赖 Flink,还有一些依赖 KV 存储、RPC 接口、OLAP 引擎等,我们需要思考在这条链路里如何分布,才能让这些组件都能正常工作。
第三个难点是链路复杂。目前我们有 200+ 核心业务作业,50+ 核心数据源,整体作业超过 1000。
2. 实时数仓 - 分层模型
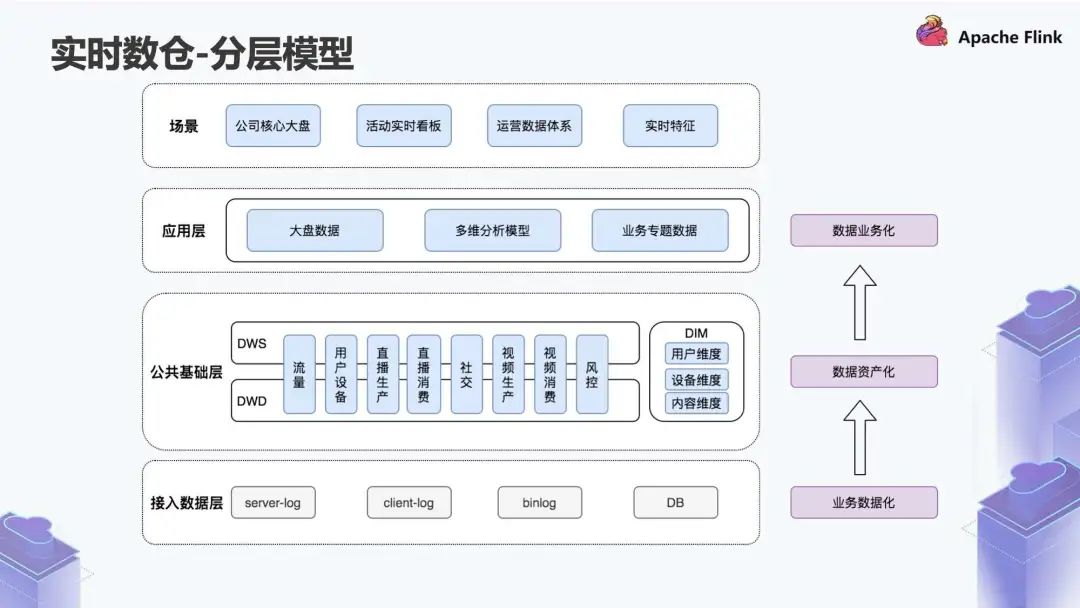
最下层有三个不同的数据源,分别是客户端日志、服务端日志以及 Binlog 日志;
在公共基础层分为两个不同的层次,一个是 DWD 层,做明细数据,另一个是 DWS 层,做公共聚合数据,DIM 是我们常说的维度。我们有一个基于离线数仓的主题预分层,这个主题预分层可能包括流量、用户、设备、视频的生产消费、风控、社交等。
DWD 层的核心工作是标准化的清洗;
DWS 层是把维度的数据和 DWD 层进行关联,关联之后生成一些通用粒度的聚合层次。
再往上是应用层,包括一些大盘的数据,多维分析的模型以及业务专题数据;
最上面是场景。
第一步是做业务数据化,相当于把业务的数据接进来;
第二步是数据资产化,意思是对数据做很多的清洗,然后形成一些规则有序的数据;
第三步是数据业务化,可以理解数据在实时数据层面可以反哺业务,为业务数据价值建设提供一些赋能。
3. 实时数仓 - 保障措施
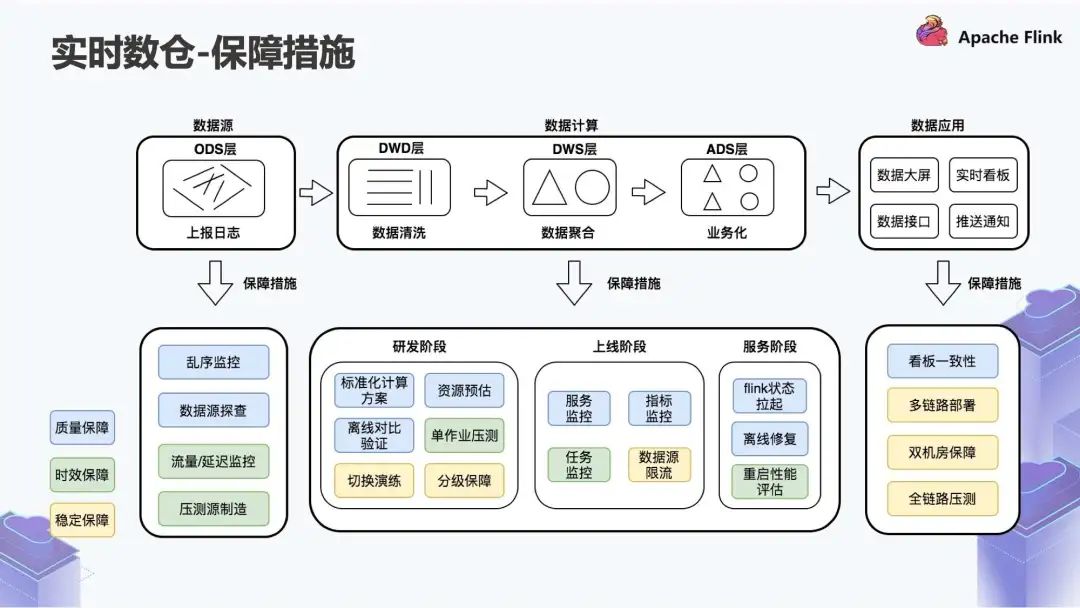
我们先看蓝色部分的质量保障。针对质量保障,可以看到在数据源阶段,做了如数据源的乱序监控,这是我们基于自己的 SDK 的采集做的,以及数据源和离线的一致性校准。研发阶段的计算过程有三个阶段,分别是研发阶段、上线阶段和服务阶段。
研发阶段可能会提供一个标准化的模型,基于这个模型会有一些 Benchmark,并且做离线的比对验证,保证质量是一致的;
上线阶段更多的是服务监控和指标监控;
在服务阶段,如果出现一些异常情况,先做 Flink 状态拉起,如果出现了一些不符合预期的场景,我们会做离线的整体数据修复。
第二个是时效性保障。针对数据源,我们把数据源的延迟情况也纳入监控。在研发阶段其实还有两个事情:
首先是压测,常规的任务会拿最近 7 天或者最近 14 天的峰值流量去看它是否存在任务延迟的情况;
通过压测之后,会有一些任务上线和重启性能评估,相当于按照 CP 恢复之后,重启的性能是什么样子。
最后一个是稳定保障。这在大型活动中会做得比较多,比如切换演练和分级保障。我们会基于之前的压测结果做限流,目的是保障作业在超过极限的情况下,仍然是稳定的,不会出现很多的不稳定或者 CP 失败的情况。之后我们会有两种不同的标准,一种是冷备双机房,另外一种是热备双机房。
冷备双机房是:当一个单机房挂掉,我们会从另一个机房去拉起;
热备双机房:相当于同样一份逻辑在两个机房各部署一次。
三、快手场景问题及解决方案
1. PV/UV 标准化
■ 1.1 场景
这个页面来了多少人,或者有多少人点击进入这个页面;
活动一共来了多少人;
页面里的某一个挂件,获得了多少点击、产生了多少曝光。
■ 1.2 方案
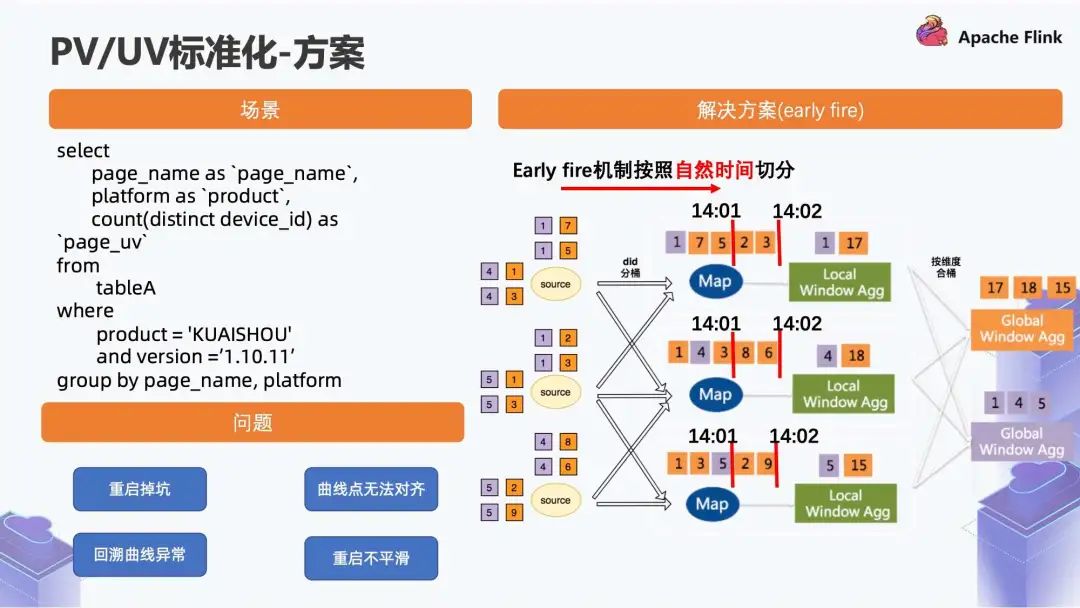
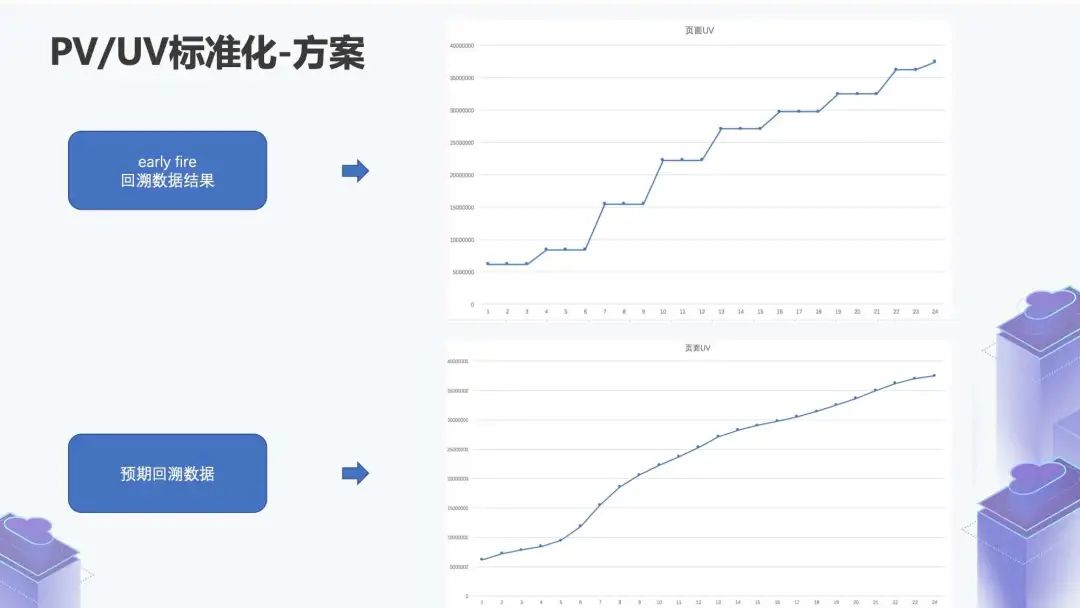
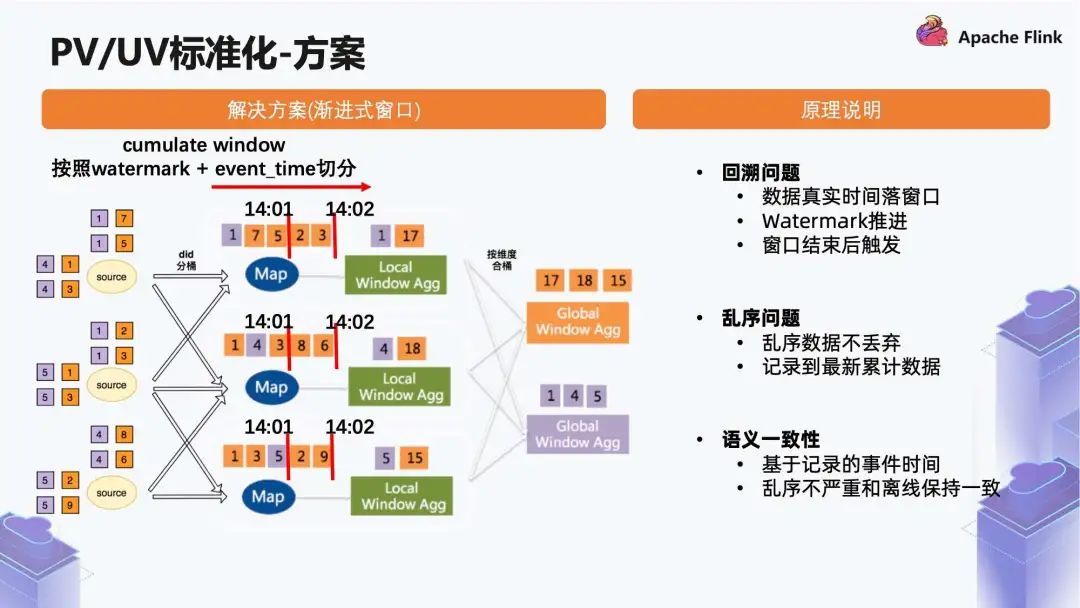
Watermark 推进过了窗口的 event_time,它会进行一次下发的触发,通过这种方式可以解决回溯的问题,数据本身落在真实的窗口, Watermark 推进,在窗口结束后触发。
此外,这种方式在一定程度上能够解决乱序的问题。比如它的乱序数据本身是一个不丢弃的状态,会记录到最新的累计数据。
最后是语义一致性,它会基于事件时间,在乱序不严重的情况下,和离线计算出来的结果一致性是相当高的。
2. DAU 计算
■ 2.1 背景介绍
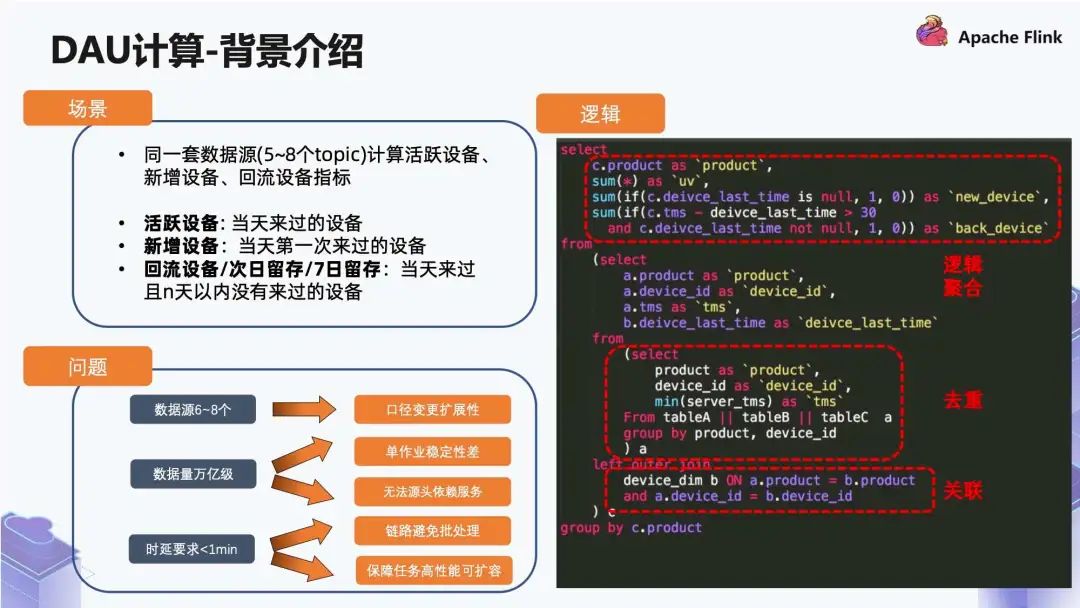
活跃设备指的是当天来过的设备;
新增设备指的是当天来过且历史没有来过的设备;
回流设备指的是当天来过且 N 天内没有来过的设备。
第一个问题是:数据源是 6~8 个,而且我们大盘的口径经常会做微调,如果是单作业的话,每次微调的过程之中都要改,单作业的稳定性会非常差;
第二个问题是:数据量是万亿级,这会导致两个情况,首先是这个量级的单作业稳定性非常差,其次是实时关联维表的时候用的 KV 存储,任何一个这样的 RPC 服务接口,都不可能在万亿级数据量的场景下保证服务稳定性;
第三个问题是:我们对于时延要求比较高,要求时延小于一分钟。整个链路要避免批处理,如果出现了一些任务性能的单点问题,我们还要保证高性能和可扩容。
■ 2.2 技术方案
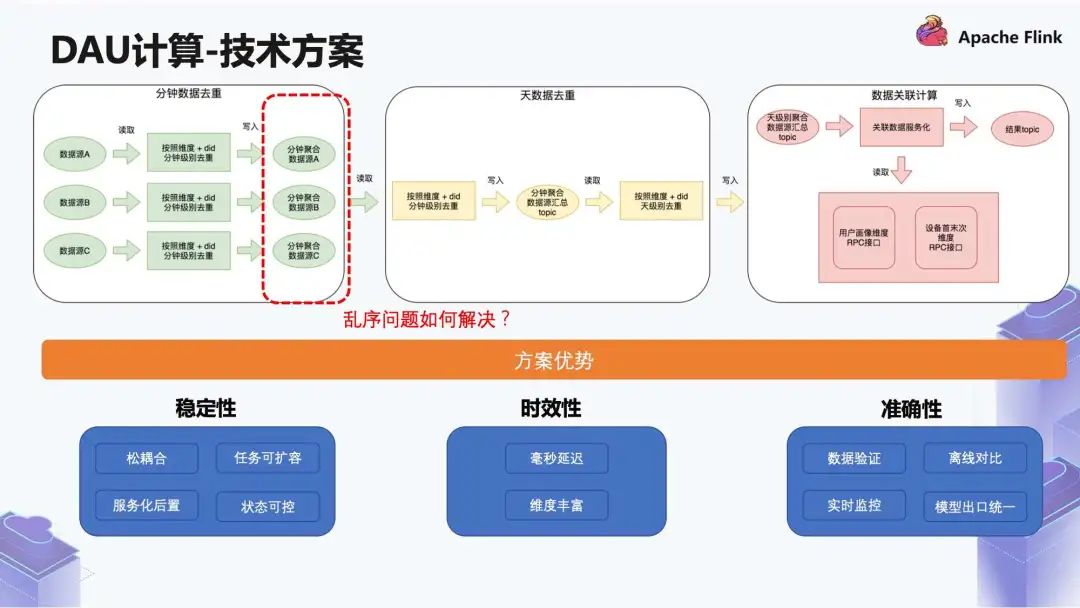
首先是稳定性。松耦合可以简单理解为当数据源 A 的逻辑和数据源 B 的逻辑需要修改时,可以单独修改。第二是任务可扩容,因为我们把所有逻辑拆分得非常细粒度,当一些地方出现了如流量问题,不会影响后面的部分,所以它扩容比较简单,除此之外还有服务化后置和状态可控。
其次是时效性,我们做到毫秒延迟,并且维度丰富,整体上有 20+ 的维度做多维聚合。
最后是准确性,我们支持数据验证、实时监控、模型出口统一等。
■ 2.3 延迟计算方案
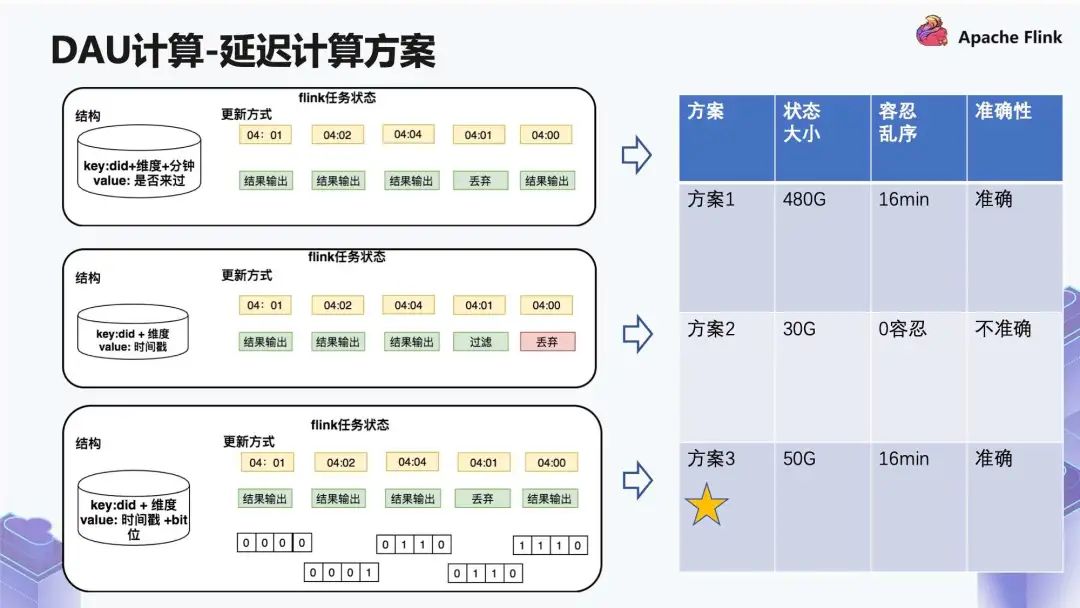
第一种解决方案是用 “did + 维度 + 分钟” 进行去重,Value 设为 “是否来过”。比如同一个 did,04:01 来了一条,它会进行结果输出。同样的,04:02 和 04:04 也会进行结果输出。但如果 04:01 再来,它就会丢弃,但如果 04:00 来,依旧会进行结果输出。
这个解决方案存在一些问题,因为我们按分钟存,存 20 分钟的状态大小是存 10 分钟的两倍,到后面这个状态大小有点不太可控,因此我们又换了解决方案 2。
第二种解决方案,我们的做法会涉及到一个假设前提,就是假设不存在数据源乱序的情况。在这种情况下,key 存的是 “did + 维度”,Value 为 “时间戳”,它的更新方式如上图所示。
04:01 来了一条数据,进行结果输出。04:02 来了一条数据,如果是同一个 did,那么它会更新时间戳,然后仍然做结果输出。04:04 也是同样的逻辑,然后将时间戳更新到 04:04,如果后面来了一条 04:01 的数据,它发现时间戳已经更新到 04:04,它会丢弃这条数据。
这样的做法大幅度减少了本身所需要的一些状态,但是对乱序是零容忍,不允许发生任何乱序的情况,由于我们不好解决这个问题,因此我们又想出了解决方案 3。
方案 3 是在方案 2 时间戳的基础之上,加了一个类似于环形缓冲区,在缓冲区之内允许乱序。
比如 04:01 来了一条数据,进行结果输出;04:02 来了一条数据,它会把时间戳更新到 04:02,并且会记录同一个设备在 04:01 也来过。如果 04:04 再来了一条数据,就按照相应的时间差做一个位移,最后通过这样的逻辑去保障它能够容忍一定的乱序。
方案 1 在容忍 16 分钟乱序的情况下,单作业的状态大小在 480G 左右。这种情况虽然保证了准确性,但是作业的恢复和稳定性是完全不可控的状态,因此我们还是放弃了这个方案;
方案 2 是 30G 左右的状态大小,对于乱序 0 容忍,但是数据不准确,由于我们对准确性的要求非常高,因此也放弃了这个方案;
方案 3 的状态跟方案 1 相比,它的状态虽然变化了但是增加的不多,而且整体能达到跟方案 1 同样的效果。方案 3 容忍乱序的时间是 16 分钟,我们正常更新一个作业的话,10 分钟完全足够重启,因此最终选择了方案 3。
3. 运营场景
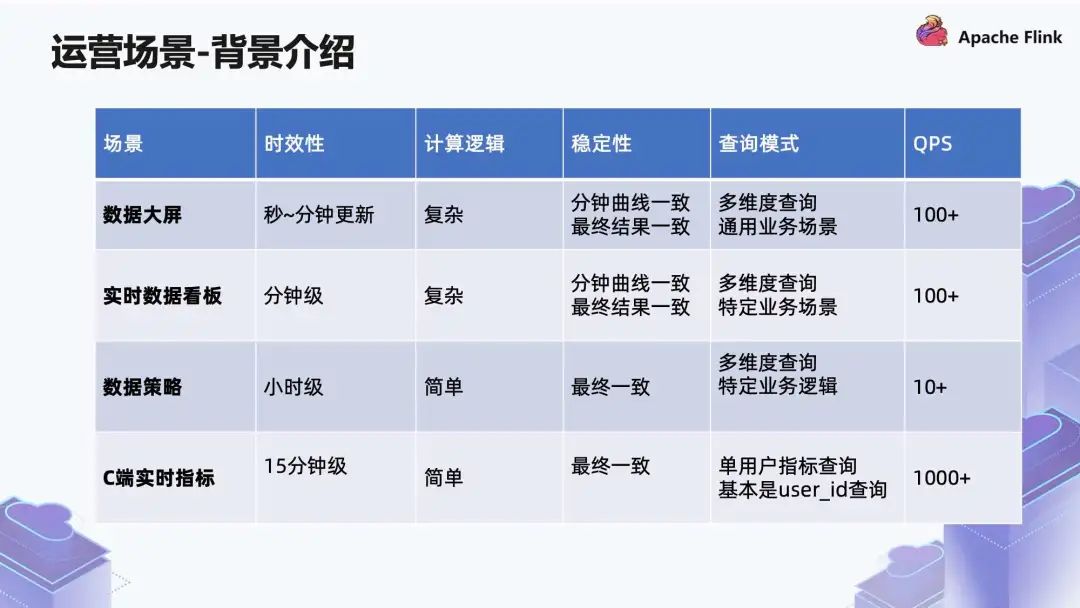
■ 3.1 背景介绍
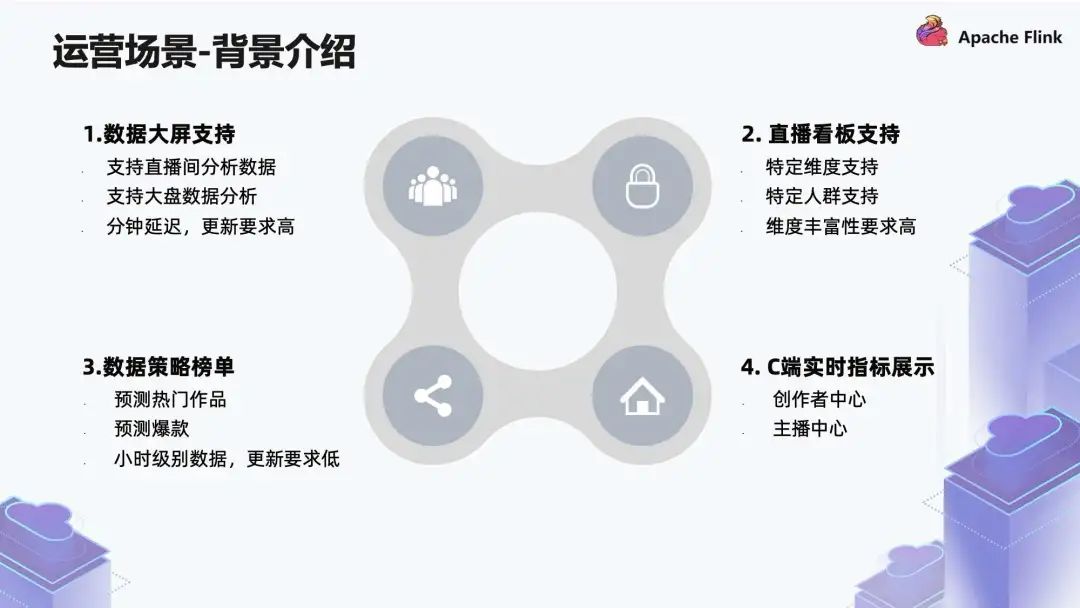
第一个是数据大屏支持,包括单直播间的分析数据和大盘的分析数据,需要做到分钟级延迟,更新要求比较高;
第二个是直播看板支持,直播看板的数据会有特定维度的分析,特定人群支持,对维度丰富性要求比较高;
第三个是数据策略榜单,这个榜单主要是预测热门作品、爆款,要求的是小时级别的数据,更新要求比较低;
第四个是 C 端实时指标展示,查询量比较大,但是查询模式比较固定。
■ 3.2 技术方案
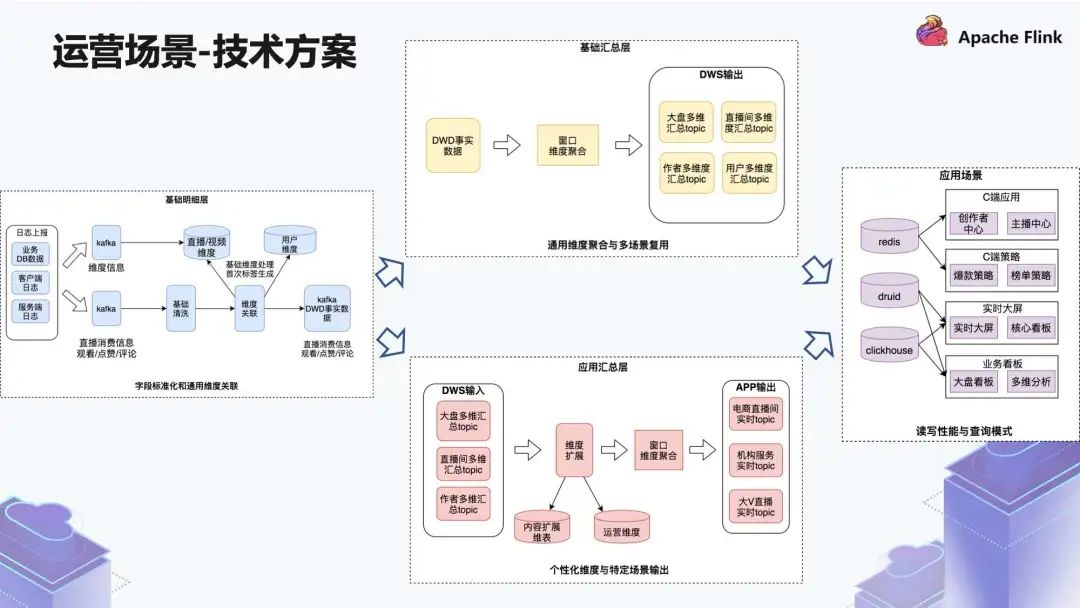
首先看一下基础明细层 (图中左方),数据源有两条链路,其中一条链路是消费的流,比如直播的消费信息,还有观看 / 点赞 / 评论。经过一轮基础清洗,然后做维度管理。上游的这些维度信息来源于 Kafka,Kafka 写入了一些内容的维度,放到了 KV 存储里边,包括一些用户的维度。
这些维度关联了之后,最终写入 Kafka 的 DWD 事实层,这里为了做性能的提升,我们做了二级缓存的操作。
如图中上方,我们读取 DWD 层的数据然后做基础汇总,核心是窗口维度聚合生成 4 种不同粒度的数据,分别是大盘多维汇总 topic、直播间多维汇总 topic、作者多维汇总 topic、用户多维汇总 topic,这些都是通用维度的数据。
如图中下方,基于这些通用维度数据,我们再去加工个性化维度的数据,也就是 ADS 层。拿到了这些数据之后会有维度扩展,包括内容扩展和运营维度的拓展,然后再去做聚合,比如会有电商实时 topic,机构服务实时 topic 和大 V 直播实时 topic。
分成这样的两个链路会有一个好处:一个地方处理的是通用维度,另一个地方处理的是个性化的维度。通用维度保障的要求会比较高一些,个性化维度则会做很多个性化的逻辑。如果这两个耦合在一起的话,会发现任务经常出问题,并且分不清楚哪个任务的职责是什么,构建不出这样的一个稳定层。
如图中右方,最终我们用到了三种不同的引擎。简单来说就是 Redis 查询用到了 C 端的场景,OLAP 查询用到了大屏、业务看板的场景。
四、未来规划
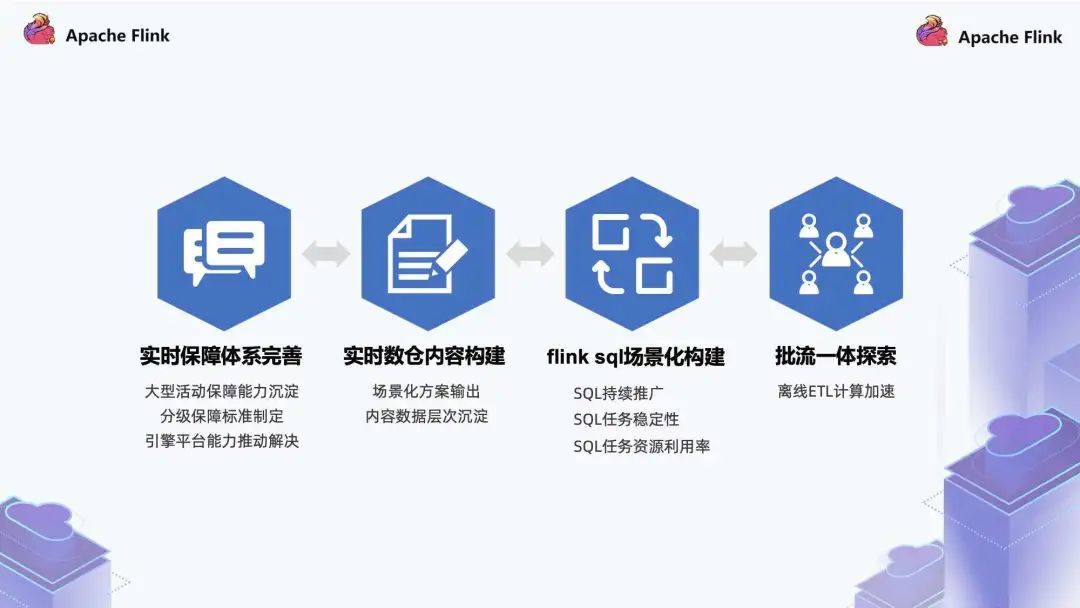
第一部分是实时保障体系完善:
一方面做一些大型的活动,包括春晚活动以及后续常态化的活动。针对这些活动如何去保障,我们有一套规范去做平台化的建设;
第二个是分级保障标准制定,哪些作业是什么样的保障级别 / 标准,会有一个标准化的说明;
第三个是引擎平台能力推动解决,包括 Flink 任务的一些引擎,在这上面我们会有一个平台,基于这个平台去做规范、标准化的推动。
第二部分是实时数仓内容构建:
一方面是场景化方案的输出,比如针对活动会有一些通用化的方案,而不是每次活动都开发一套新的解决方案;
另一方面是内容数据层次沉淀,比如现在的数据内容建设,在厚度方面有一些场景的缺失,包括内容如何更好地服务于上游的场景。
第三部分是 Flink SQL 场景化构建,包括 SQL 持续推广、SQL 任务稳定性和 SQL 任务资源利用率。我们在预估资源的过程中,会考虑比如在什么样 QPS 的场景下, SQL 用什么样的解决方案,能支撑到什么情况。Flink SQL 可以大幅减少人效,但是在这个过程中,我们想让业务操作更加简单。
第四部分是批流一体探索。实时数仓的场景其实就是做离线 ETL 计算加速,我们会有很多小时级别的任务,针对这些任务,每次批处理的时候有一些逻辑可以放到流处理去解决,这对于离线数仓 SLA 体系的提升十分巨大。