
基于 Flink 的 OLAP 分析及实时数仓实践
业务背景 落地实践 & 特色改进 应用场景 未来规划
一、业务背景
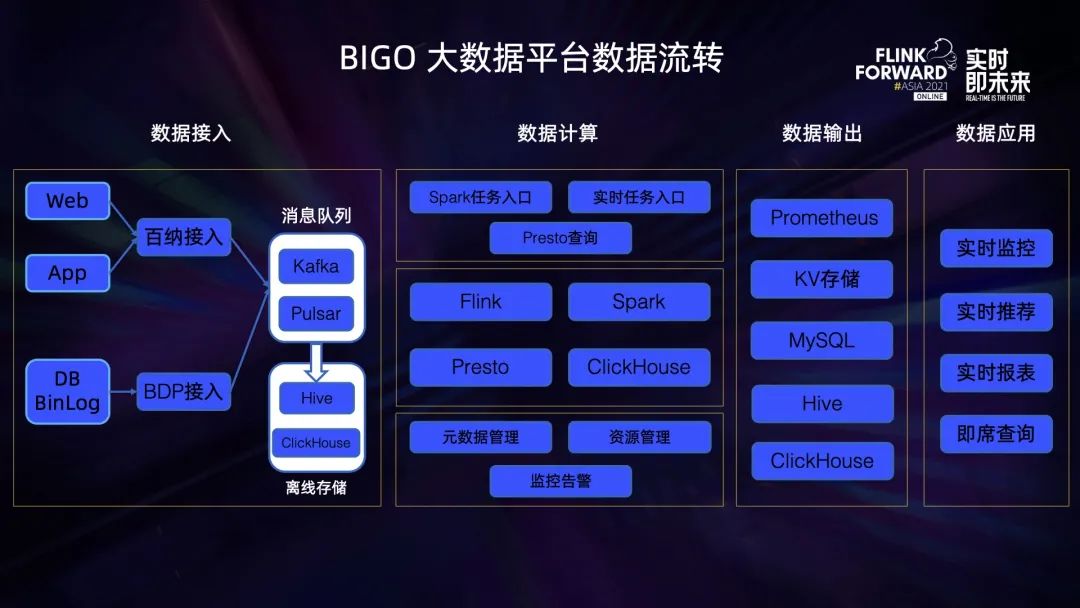
用户在 APP,Web 页面上的行为日志数据,以及关系数据库的 Binlog 数据会被同步到 BIGO 大数据平台消息队列,以及离线存储系统中,然后通过实时的,离线的数据分析手段进行计算,以应用于实时推荐、监控、即席查询等使用场景。然而存在以下几个问题:
OLAP 分析平台入口不统一:Presto/Spark 分析任务入口并存,用户不清楚自己的 SQL 查询适合哪个引擎执行,盲目选择,体验不好;另外,用户会在两个入口同时提交相同查询,以更快的获取查询结果,导致资源浪费; 离线任务计算时延高,结果产出太慢:典型的如 ABTest 业务,经常计算到下午才计算出结果; 各个业务方基于自己的业务场景独立开发应用,实时任务烟囱式的开发,缺少数据分层,数据血缘。
通过 OneSQL OLAP 分析平台,统一 OLAP 查询入口,减少用户盲目选择,提升平台的资源利用率; 通过 Flink 构建实时数仓任务,通过 Kafka/Pulsar 进行数据分层; 将部分离线计算慢的任务迁移到 Flink 流式计算任务上,加速计算结果的产出;
二、落地实践 & 特色改进
2.1 OneSQL OLAP 分析平台实践和优化
OneSQL OLAP 分析平台是一个集 Flink、Spark、Presto 于一体的 OLAP 查询分析引擎。用户提交的 OLAP 查询请求通过 OneSQL 后端转发到不同执行引擎的客户端,然后提交对应的查询请求到不同的集群上执行。其整体架构图如下:
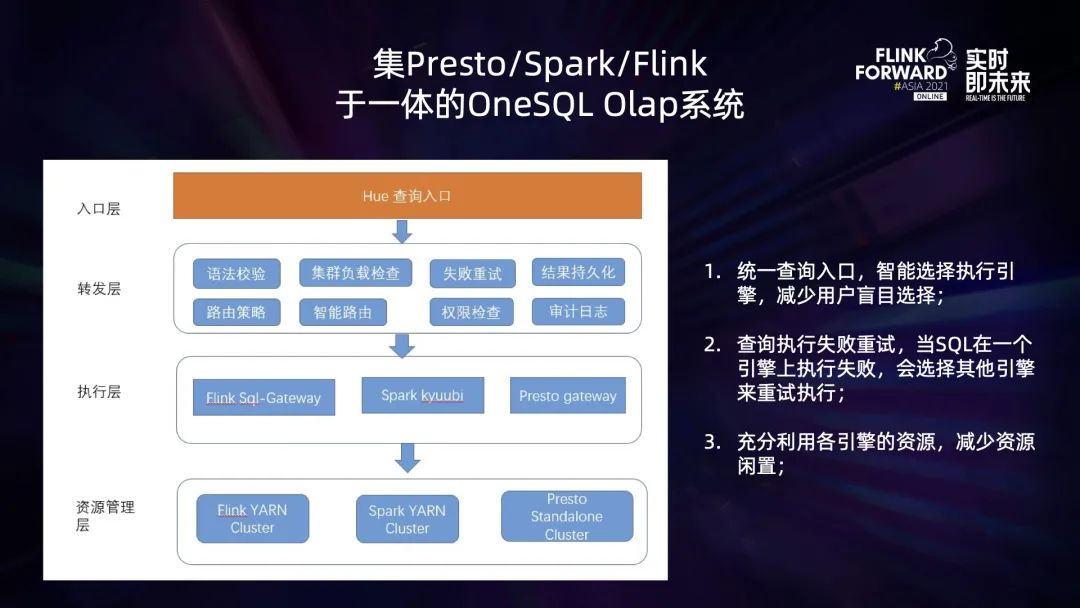
该分析平台整体结构从上到下分为入口层、转发层、执行层、资源管理层。为了优化用户体验,减少执行失败的概率,提升各集群的资源利用率,OneSQL OLAP 分析平台实现了以下功能:
统一查询入口:入口层,用户通过统一的 Hue 查询页面入口以 Hive SQL 语法为标准提交查询; 统一查询语法:集 Flink、Spark、Presto 等多种查询引擎于一体,不同查询引擎通过适配 Hive SQL 语法来执行用户的 SQL 查询任务; 智能路由:在选择执行引擎的过程中,会根据历史 SQL 查询执行的情况 (在各引擎上是否执行成功,以及执行耗时),各集群的繁忙情况,以及各引擎对该 SQL 语法的是否兼容,来选择合适的引擎提交查询; 失败重试:OneSQL 后台会监控 SQL 任务的执行情况,如果 SQL 任务在执行过程中失败,将选择其他的引擎执行重试提交任务;
■ 2.1.1 Flink OLAP 分析系统建设
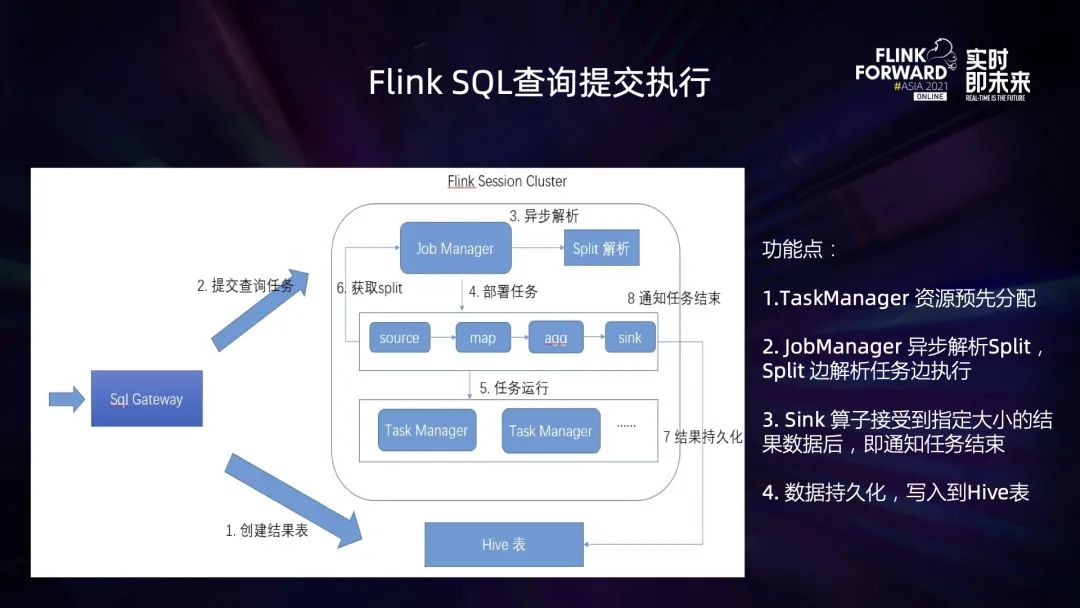
为了保证整个 Flink OLAP 系统的稳定性,以及高效的执行 SQL 查询,在这个系统中,进行了以下功能增强:
稳定性: 基于 zookeeper HA 来保证 Flink Session 集群的可靠性,SQL Gateway 监听 Zookeeper 节点,感知 Session 集群; 控制查询扫描 Hive 表的数据量,分区个数,以及返回结果数据量,防止 Session 集群的 JobManager,TaskManager 因此出现 OOM 情况; 性能: Flink Session 集群预分配资源,减少作业提交后申请资源所需的时间; Flink JobManager 异步解析 Split,Split 边解析任务边执行,减少由于解析 Split 阻塞任务执行的时间; 控制作业提交过程中扫描分区,以及 Split 最大的个数,减少设置任务并行所需要的时间; Hive SQL 兼容: 针对 Flink 对于 Hive SQL 语法的兼容性进行改进,目前针对 Hive SQL 的兼容性大致为 80%; 监控告警: 监控 Flink Session 集群的 JobManager,TaskManager,以及 SQL Gateway 的内存,CPU 使用情况,以及任务的提交情况,一旦出现问题,及时告警和处理;
■ 2.1.2 OneSQL OLAP 分析平台取得的成果
基于以上实现的 OneSQL OLAP 分析平台,取得了以下几个收益:
统一查询入口,减少用户的盲目选择,用户执行出错率下降 85.7%,SQL 执行的成功率提升 3%; SQL 执行时间缩短 10%,充分利用了各个集群的资源,减少任务排队等待的时间; Flink 作为 OLAP 分析引擎的一部分,实时计算集群的资源利用率提升了 15%;
2.2 实时数仓建设和优化
■ 2.2.1 建设方案
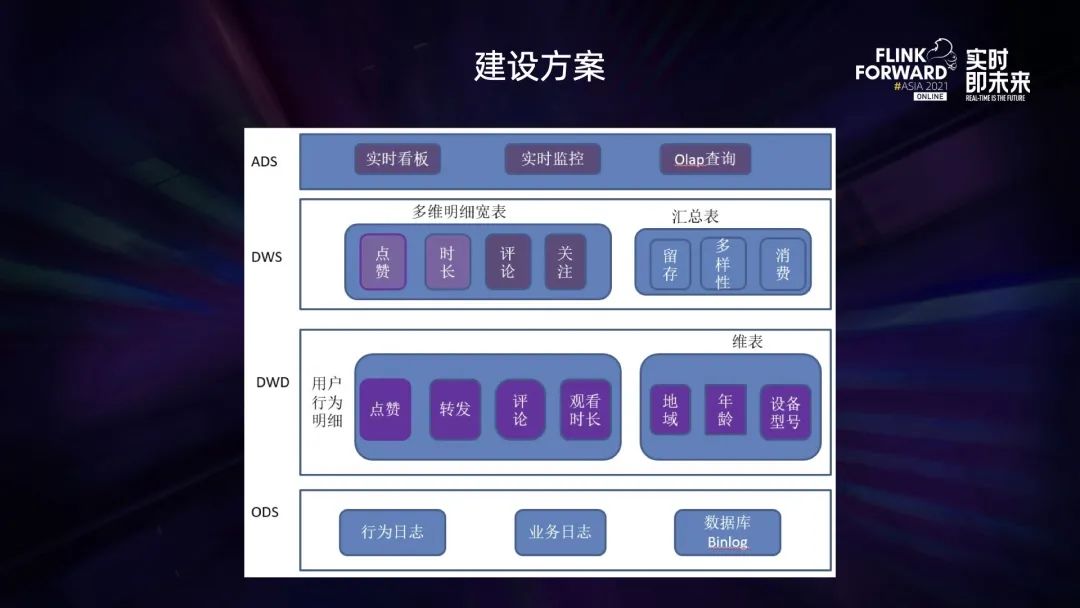
按照传统数据仓库的数据分层方法,将数据划分成 ODS、DWD、DWS、ADS 等四层数据:
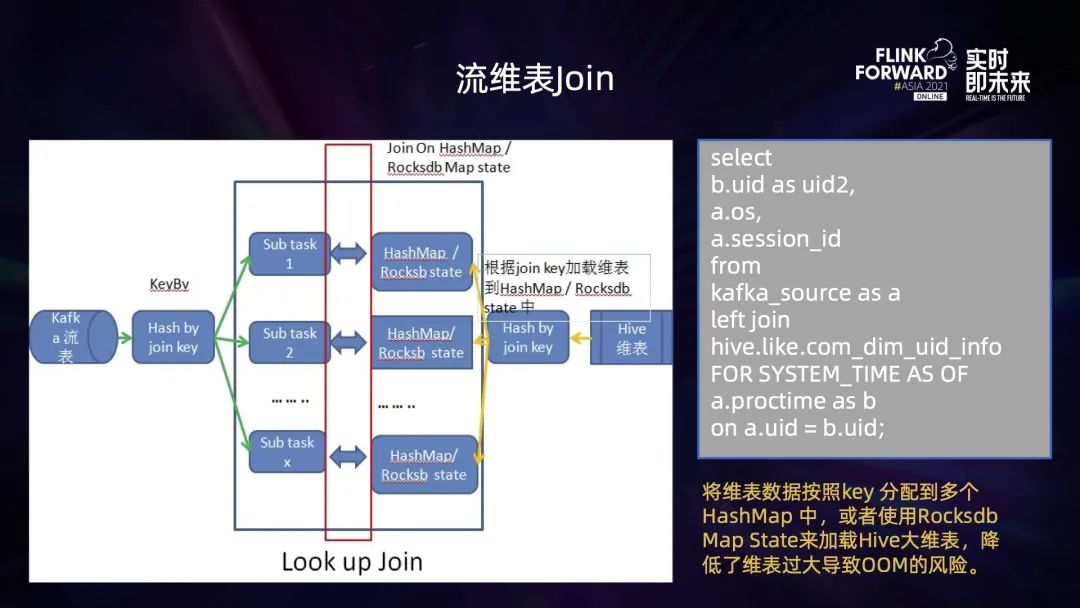
ODS 层:基于用户的行为日志,业务日志等作为原始数据,存放于 Kafka/Pulsar 等消息队列中; DWD 层:这部分数据根据用户的 UserId 经过 Flink 任务进行聚合后,形成不同用户的行为明细数据,保存到 Kafka/Pulsar 中; DWS 层:用户行为明细的 Kafka 流表与用户 Hive/MySQL 维表进行流维表 JOIN,然后将 JOIN 之后产生的多维明细数据输出到 ClickHouse 表中; ADS 层:针对 ClickHouse 中多维明细数据按照不同维度进行汇总,然后应用于不同的业务中。
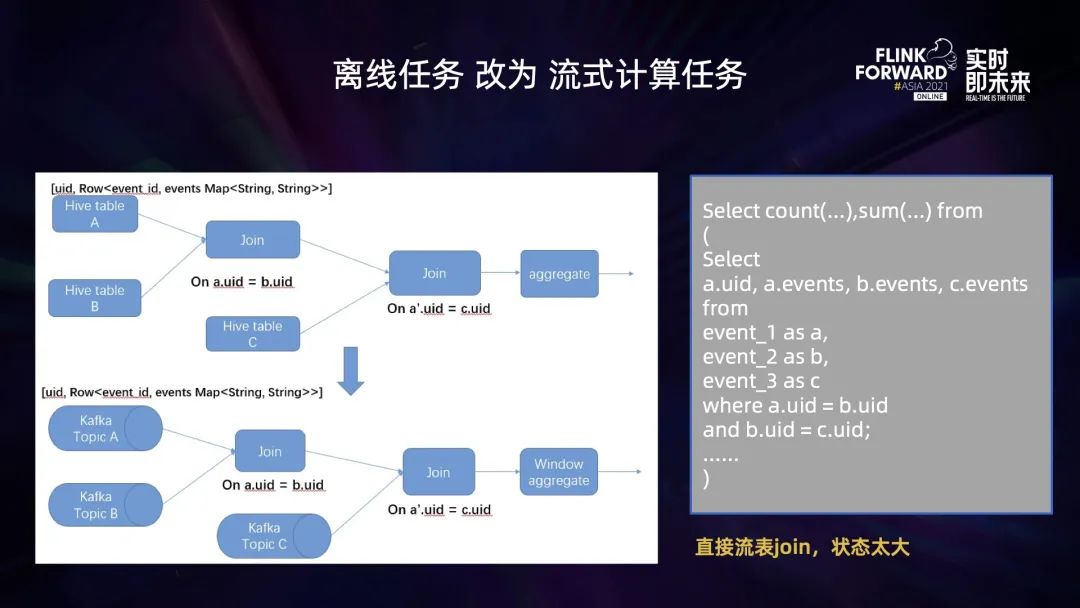
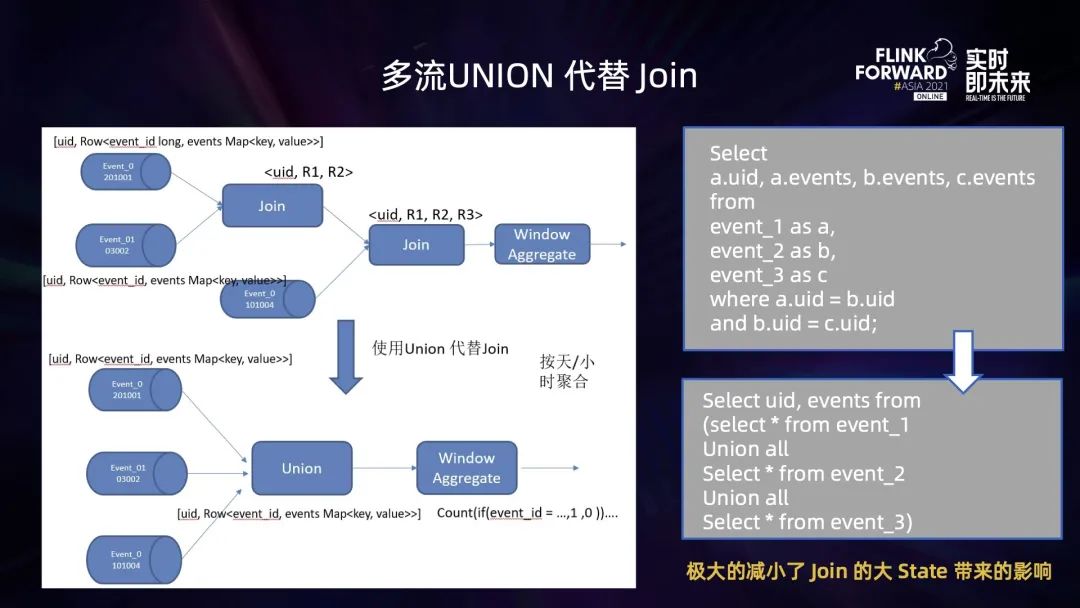
将离线任务转为实时计算任务后,计算逻辑较为复杂 (多流 JOIN,去重),导致作业状态太大,作业出现 OOM (内存溢出) 异常或者作业算子背压太大; 维表 Join 过程中,明细流表与大维表 Join,维表数据过多,加载到内存后 OOM,作业失败无法运行; Flink 将流维表 Join 产生的多维明细数据写入到 ClickHouse,无法保证 Exactly-once,一旦作业出现 Failover,就会导致数据重复写入。
■ 2.2.2 问题解决 & 优化
优化作业执行逻辑,减小状态
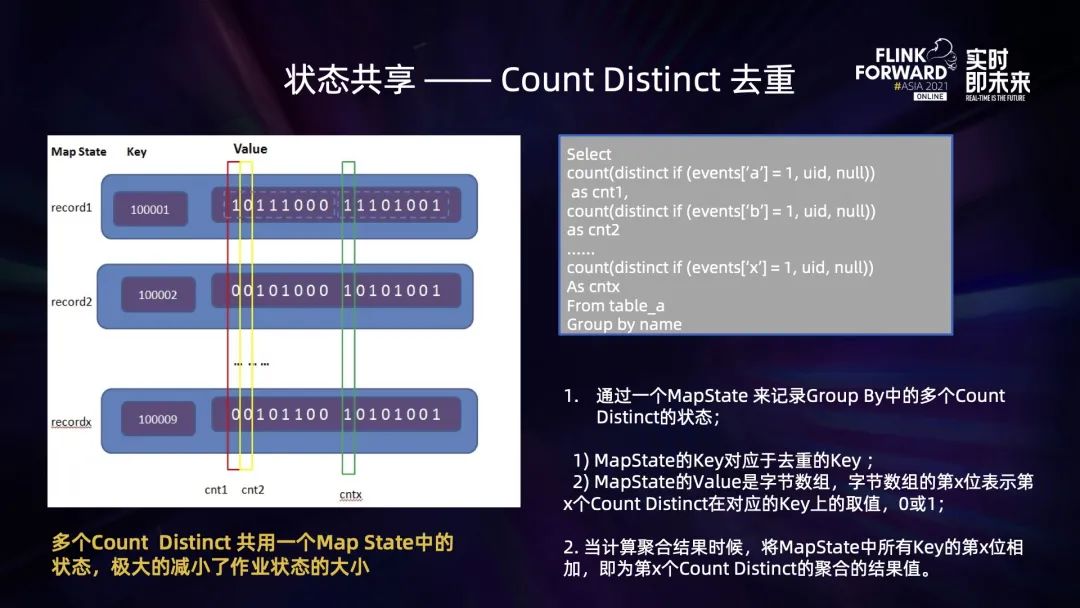
selectcount(distinct if(events['a'] = 1, postid, null))as cnt1,count(distinct if(events['b'] = 1, postid, null))as cnt2……count(distinct if(events['x'] = 1, postid, null))As cntxFrom table_aGroup by uid
流维表 JOIN 优化
ClickHouse Sink 的 Exactly-Once 语义支持
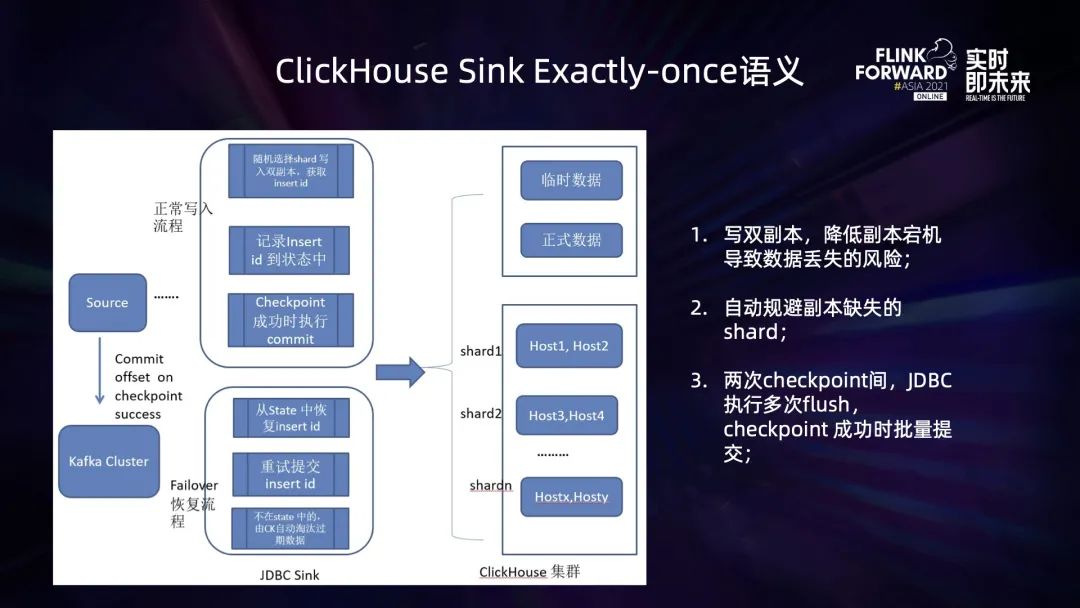
在正常写入的情况下,Connector 随机选择 ClickHouse 的某一个 shard 写入,根据用户配置写单副本,或者双副本来执行 insert 操作,并记录写入后的 insert id;在两次 checkpoint 之间就会有多次这种 insert 操作,从而产生多个 insert id,当 checkpoint 完成时,再将这些 insert id 批量提交,将临时数据转为正式数据,即完成了两次 checkpoint 间数据的写入; 一旦作业出现 Failover,Flink 作业 Failover 重启完成后,将从最近一次完成的 checkpoint 来恢复状态,此时 ClickHouse Sink 中的 Operator State 可能会包含上一次还没有来得及提交完成的 Insert id,针对这些 insert id 进行重试提交;针对那些数据已经写入 ClickHouse 中之后,但是 insert id 并没有记录到 Opeator State 中的数据,由于是临时数据,在 ClickHouse 中并不会被查询到,一段时间后,将会由 ClickHouse 的过期清理机制,被清理掉,从而保证了状态回滚到上一次 checkpoint 之后,数据不会重复。
■ 2.2.3 平台建设
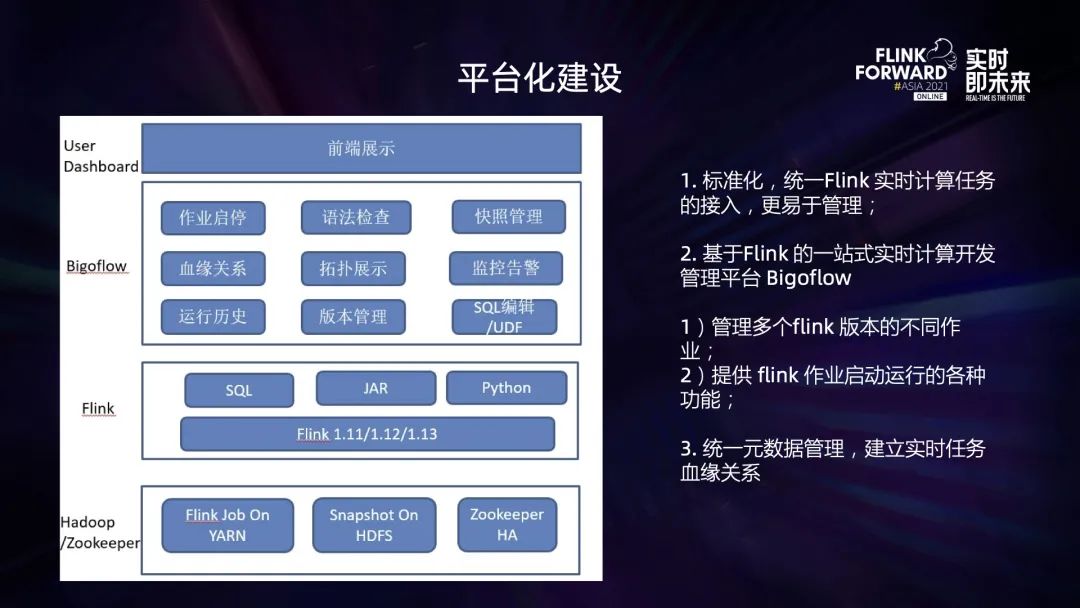
支持 Flink JAR、SQL、Python 等多种类型作业;支持不同的 Flink 版本,覆盖公司内部大部分实时计算相关业务; 一站式管理:集作业开发、提交、运行、历史展示、监控、告警于一体,便于随时查看作业的运行状态和发现问题; 血缘关系:方便查询每个作业的数据源、数据目的、数据计算的来龙去脉。
三、应用场景
3.1 Onesql OLAP 分析平台应用场景
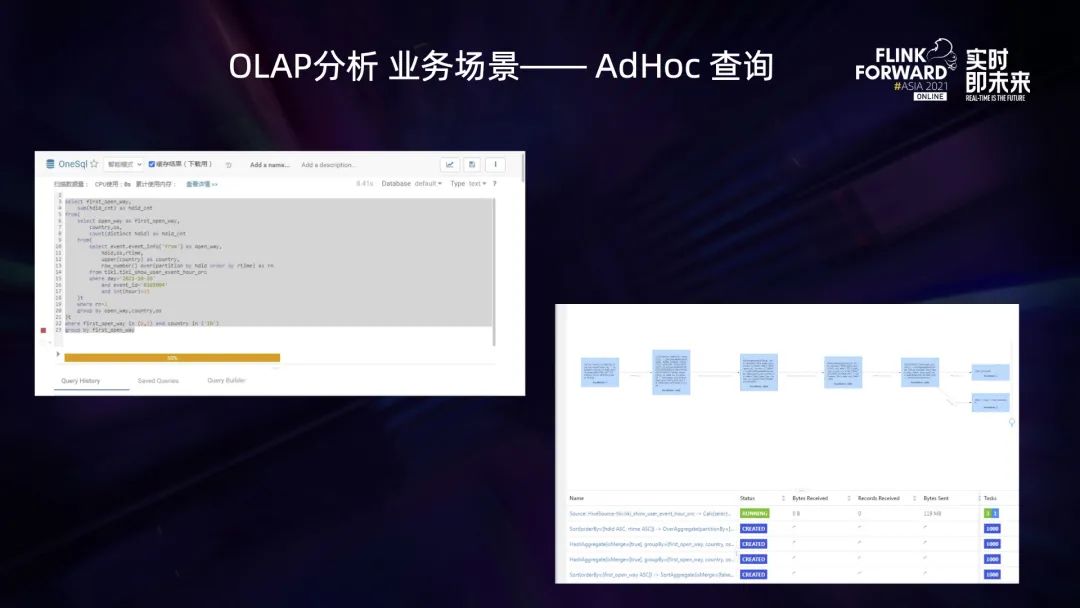
3.2 实时数据仓库应用场景

四、未来规划
为了更好的建设 OneSQL OLAP 分析平台以及 BIGO 实时数据仓库,实时计算平台的规划如下:
完善 Flink OLAP 分析平台,完善 Hive SQL 语法支持,以及解决计算过程中出现的 JOIN 数据倾斜问题; 完善实时数仓建设,引入数据湖技术,解决实时数仓中任务数据的可重跑回溯范围小的问题; 基于 Flink 打造流批一体的数据计算平台。
评论