
Flink 在广告业务的实践
一、业务场景
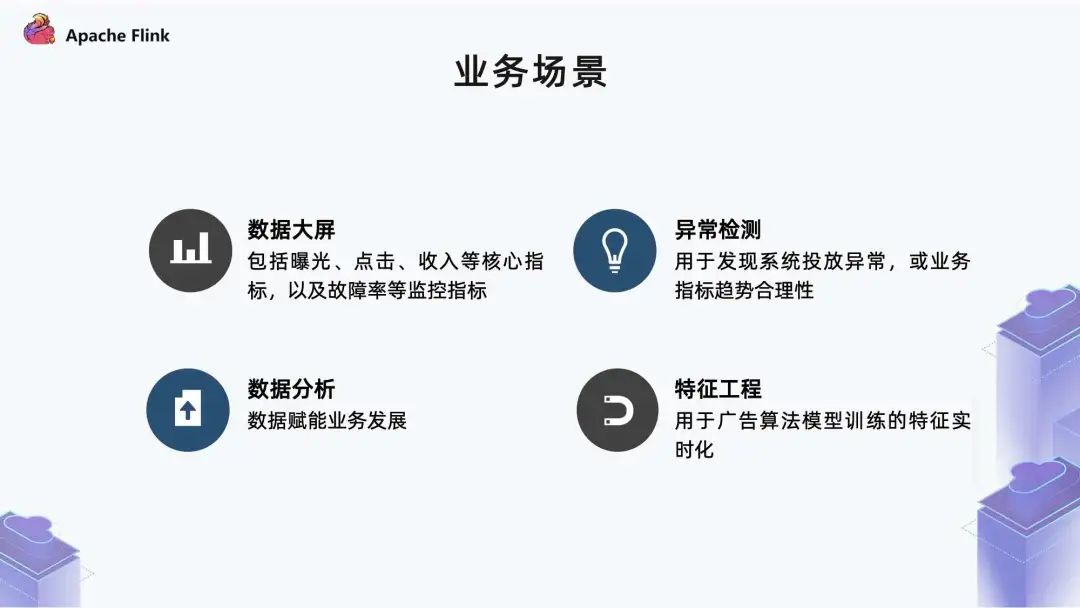
数据大屏:包括曝光、点击、收入等核心指标的展示,以及故障率等监控指标; 异常监测:因为广告投放的链路比较⻓,所以如果链路上发生任何波动的话,都会对整体的投放效果产生影响。除此之外,各个团队在上线过程中是否会对整体投放产生影响,都是通过异常监测系统能够观测到的。我们还能够观测业务指标走势是否合理,比如在库存正常的情况下,曝光是否有不同的波动情况,这可以用来实 时发现问题; 数据分析:主要用于数据赋能业务发展。我们可以实时分析广告投放过程中的一些异常问题,或者基于当前的投放效果去研究怎样优化,从而达到更好的效果; 特征工程:广告算法团队主要是做一些模型训练,用于支持线上投放。技术特征最初大部分是离线,随着实时的发展,开始把一些工程转到实时。
二、业务实践
1. 实时数仓
■ 1.1 实时数仓 - 目标

数据完整性:在广告业务里,实时数据主要是用于指导决策,比如广告主需要根据当前投放的实时数据,指导后面的出价或调整预算。另外,故障率的监控需要数据本身是稳定的。如果数据是波动的,指导意义就非常差,甚至没有什么指导意义。因此完整性本身是对时效性和完整性之间做了一个权衡; 服务稳定性:生产链包括数据接入、计算(多层)、数据写入、进度服务和查询服务。除此之外还有数据质量,包括数据的准确性以及数据趋势是否符合预期; 查询能力:在广告业务有多种使用场景,在不同场景里可能使用了不同的 OLAP 引擎,所以查询方式和性能的要求不一致。另外,在做数据分析的时候,除了最新最稳定的实时数据之外,同时也会实时 + 离线做分析查询,此外还包括数据跨源和查询性能等要求。
■ 1.2 实时数仓 - 挑战

数据进度服务:需要在时效性和完整性之间做一个权衡; 数据稳定性:由于生产链路比较长,中间可能会用到多种功能组件,所以端到端的服务稳定性对整体数据准确性的影响是比较关键的; 查询性能:主要包括 OLAP 分析能力。在实际场景中,数据表包含了离线和实时,单表规模达上百列,行数也是非常大的。
■ 1.3 广告数据平台架构
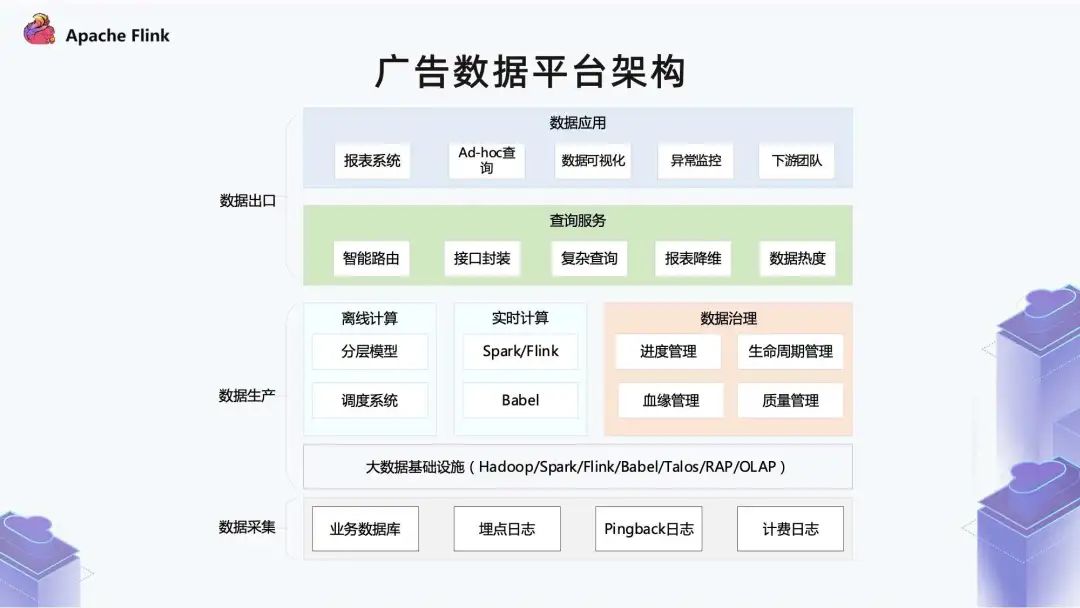
底部是数据采集层,这里与大部分公司基本一致。业务数据库主要包含了广告主的下单数据以及投放的策略;埋点日志和计费日志是广告投放链路过程中产生的日志; 中间是数据生产的部分,数据生产的底层是大数据的基础设施,这部分由公司的一个云平台团队提供,其中包含 Spark / Flink 计算引擎,Babel 统一的管理平台。Talos 是实时数仓服务,RAP 和 OLAP 对应不同的实时分析以及 OLAP 存储和查询服务。 数据生产的中间层是广告团队包含的一些服务,例如在生产里比较典型的离线计算和实时计算。 离线是比较常见的一个分层模型,调度系统是对生产出的离线任务做有效的管理和调度。 实时计算这边使用的引擎也比较多,我们的实时化是从 2016 年开始,当时选的是 Spark Streaming,后面随着大数据技术发展以及公司业务需求产生了不同场景,又引入了计算引擎 Flink。 实时计算底层调度依赖于云计算的 Babel 系统,除了计算之外还会伴随数据治理,包括进度管理,就是指实时计算里一个数据报表当前已经稳定的进度到哪个时间点。离线里其实就对应一个表,有哪些分区。 血缘管理包括两方面,离线包括表级别的血缘以及字段血缘。实时主要还是在任务层面的血缘。 至于生命周期管理,在离线的一个数仓里,它的计算是持续迭代的。但是数据保留时间非常长的话,数据量对于底层的存储压力就会比较大。 数据生命周期管理主要是根据业务需求和存储成本之间做一个权衡。 质量管理主要包括两方面,一部分在数据接入层,判断数据本身是否合理;另外一部分在数据出口,就是结果指标这一层。因为我们的数据会供给其他很多团队使用,因此在数据出口这一层要保证数据计算没有问题。 再上层是统一查询服务,我们会封装很多接口进行查询。
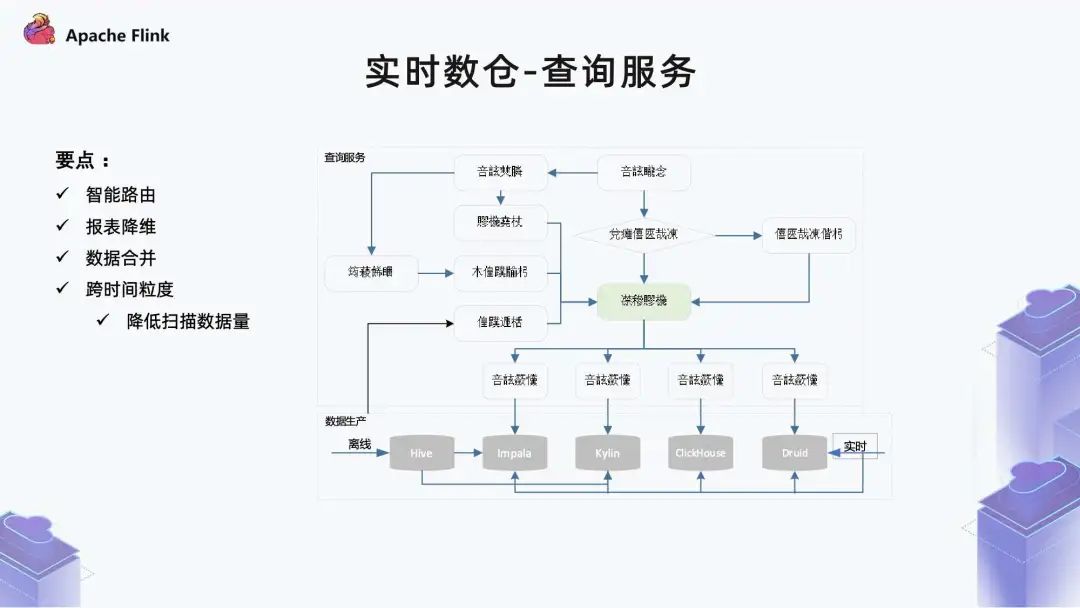
因为数据化包括离线和实时,另外还有跨集群,所以在智能路由这里会进行一些选集群、选表以及复杂查询、拆分等核心功能。 查询服务会对历史查询进行热度的统一管理。这样一方面可以更应进一步服务生命周期管理,另一方面可以去看哪些数据对于业务的意义非常大。 除了生命周期管理之外,它还可以指导我们的调度系统,比如哪些报表比较关键,在资源紧张的时候就可以优先调度这些任务。 再往上是数据应用,包括报表系统、Add - hoc 查询、数据可视化、异常监控和下游团队。
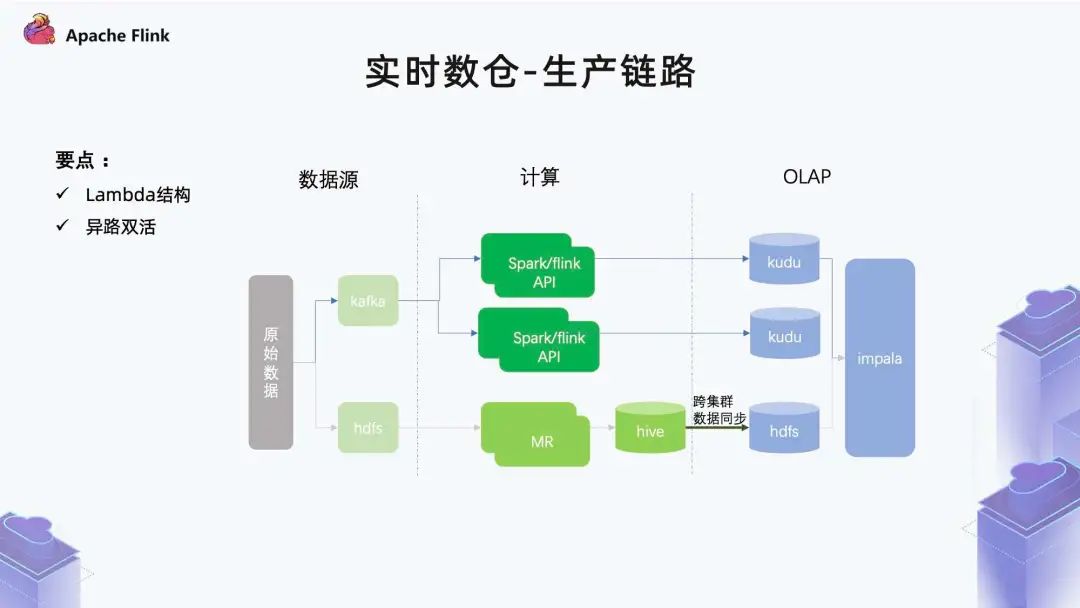
■ 1.4 实时数仓 - 生产链路
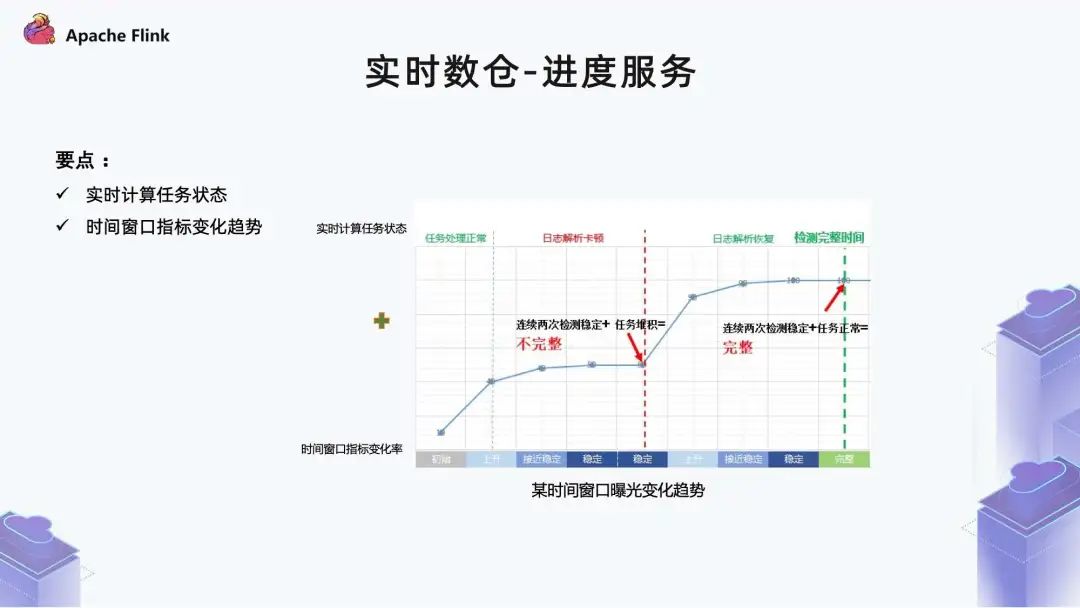
■ 1.5 实时数仓 - 进度服务
■ 1.6 实时数仓 - 查询服务
■ 1.7 数据生产 - 规划
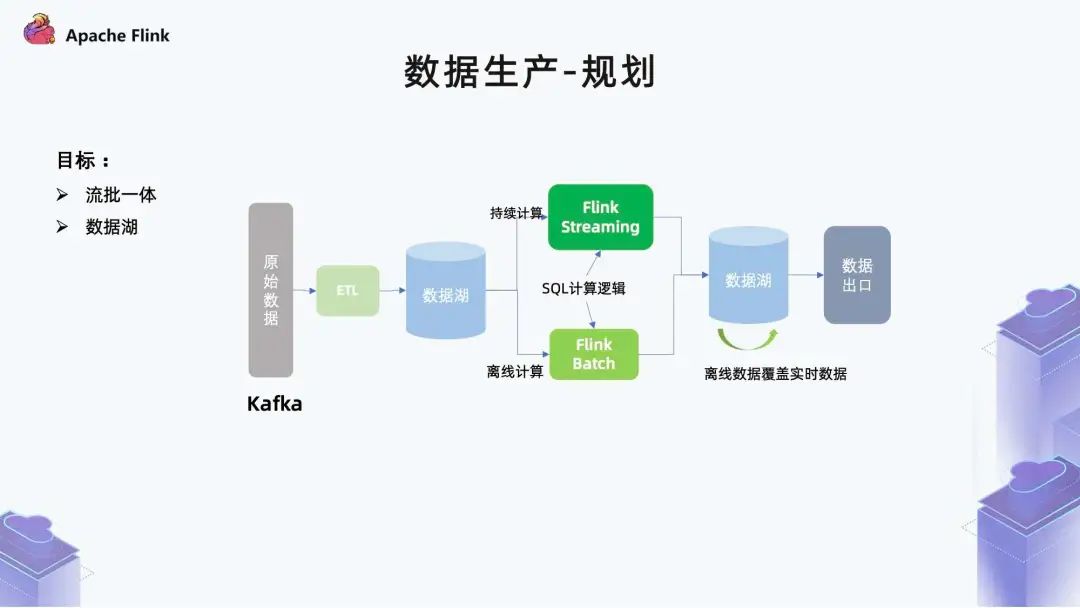
一方面是他们的逻辑可能会发生差异,最终导致结果表不一致;
另一方面是人力成本,同时需要两个团队进行开发。
■ 1.8 数据生产 - SQL 化
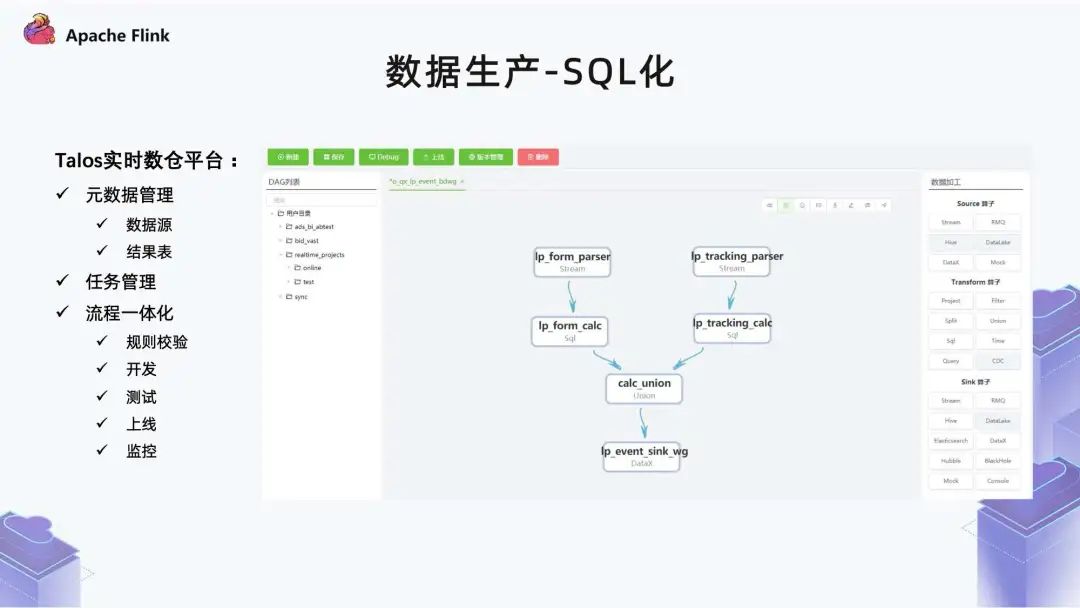
有一些业务团队本身对于计算引擎算子非常熟,那么他们便可以做一些代码开发; 但是很多业务团队可能对引擎并不是那么了解,或者没有强烈的意愿去了解,他们就可以通过这种可视化的方式,拼接出一个作业。
2. 特征工程

第一个需求是实时化,因为数据价值随着时间的递增会越来越低。比如某用户表现出来的观影行为是喜欢看儿童内容,平台就会推荐儿童相关的广告。另外,用户在看广告过程中,会有一些正/负反馈的行为,如果把这些数据实时迭代到特征里,就可以有效提升后续的转化效果。
特征工程的第二个需求是服务稳定性。
首先是作业容错,比如作业在异常的时候能否正常恢复; 另外是数据质量,在实时数据里追求端到端精确一次。
■ 2.1 点击率预估
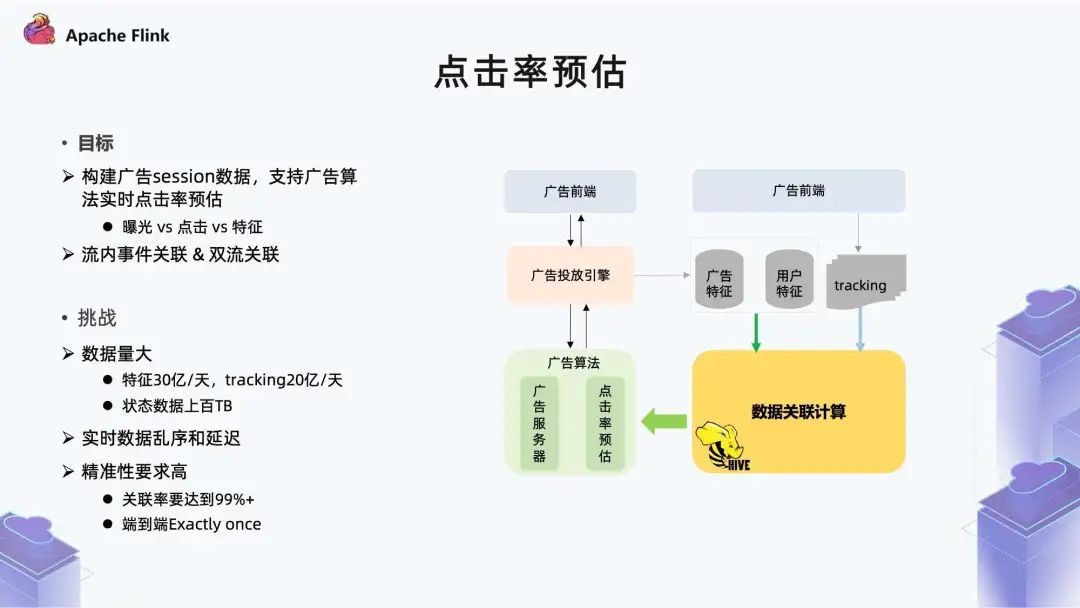
一方面是 Tracking 流里曝光、点击事件的关联; 另一方面是特征流跟用户行为的关联。
第一个挑战是数据量; 第二个挑战是实时数据乱序和延迟; 第三个挑战是精确性要求高。
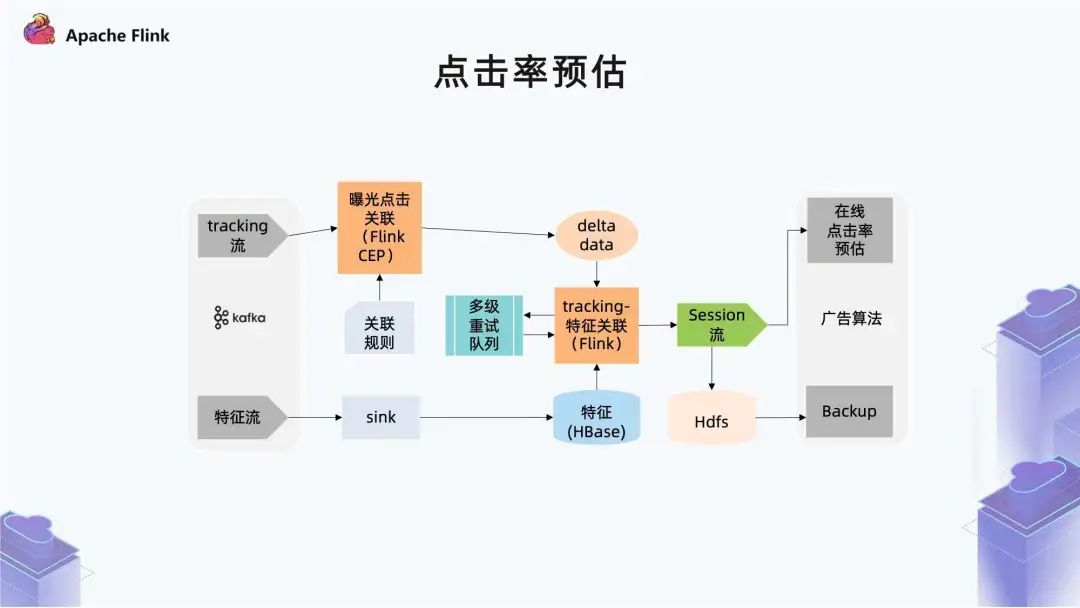
第一个部分是用户行为流里曝光跟点击事件的关联,这里通过 CEP 实现。
第二个部分是两个流的关联,前面介绍特征需要保留 7 天,它的状态较大,已经是上百 TB。这个量级在内存里做管理,对数据稳定性有比较大的影响,所以我们把特征数据放在一个外部存储 (Hbase) 里,然后和 HBase 特征做一个实时数据查询,就可以达到这样一个效果。
■ 2.2 点击率预估 - 流内事件关联
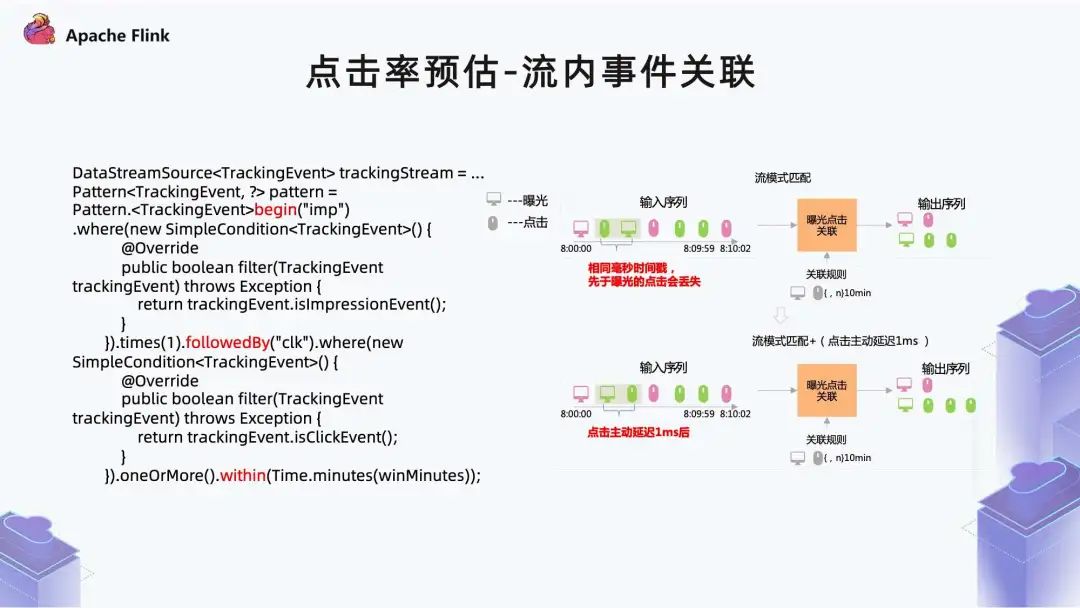
如果事件序列本身都在同一个窗口之内,数据没有问题; 但是当事件序列跨窗口的时候,是达不到正常关联效果的。
■ 2.3 点击率预估-双流关联
首先支持比较高的读写并发能力; 另外它的时效性需要非常低; 同时因为数据要保留 7 天,所以它最好具备生命周期管理能力。
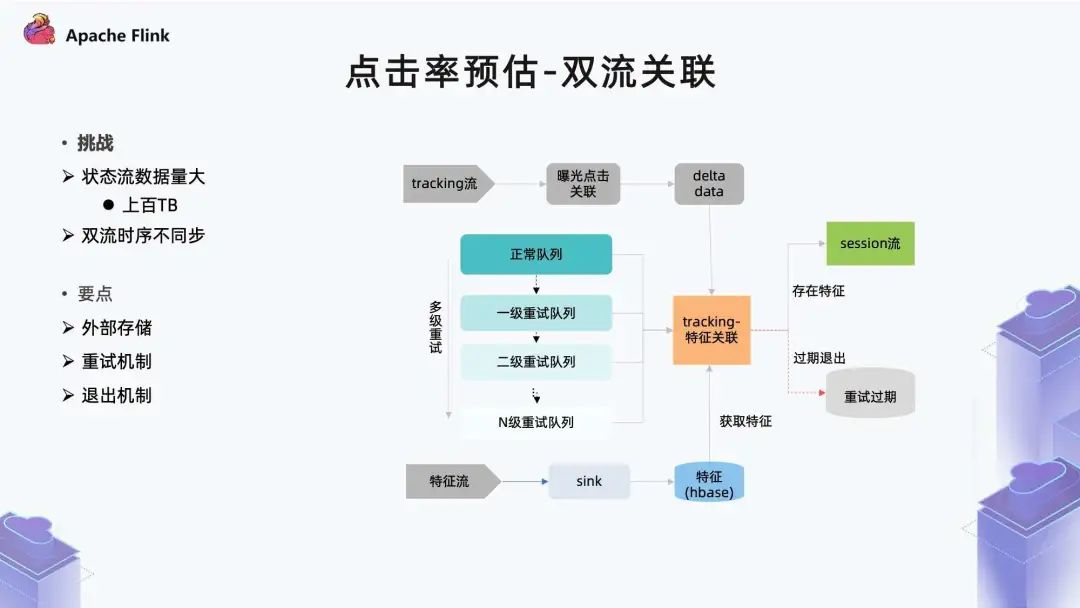
第一点是特征数据保留了 7 天,如果对应特征是在 7 天之前,那么它本身是关联不到的。
另外在广告业务里,存在一些外部的刷量行为,比如刷曝光或刷点击,但它本身并没有真实存在的广告请求,所以这种场景也拿不到对应特征。
■ 2.4 有效点击
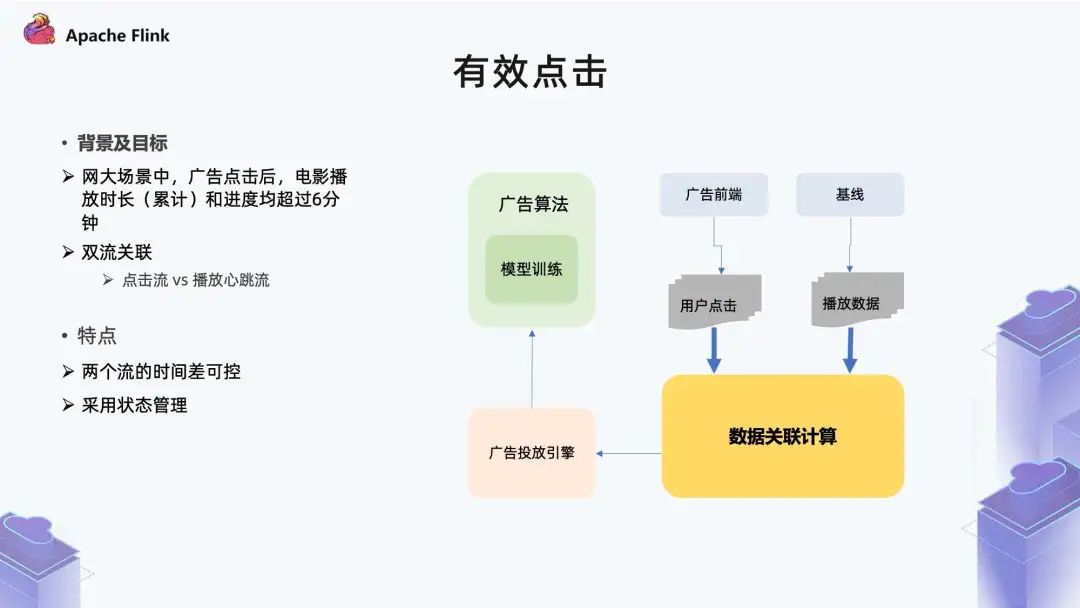
点击流比较好理解,包括用户的曝光和点击等行为,从里面筛选点击事件即可。
播放行为流是在用户观看的过程,会定时地把心跳信息回传,比如三秒钟回传一个心跳,表明用户在持续观看。在定义时长超过 6 分钟的时候,需要把这个状态本身做一些处理,才能满足 6 分钟的条件。
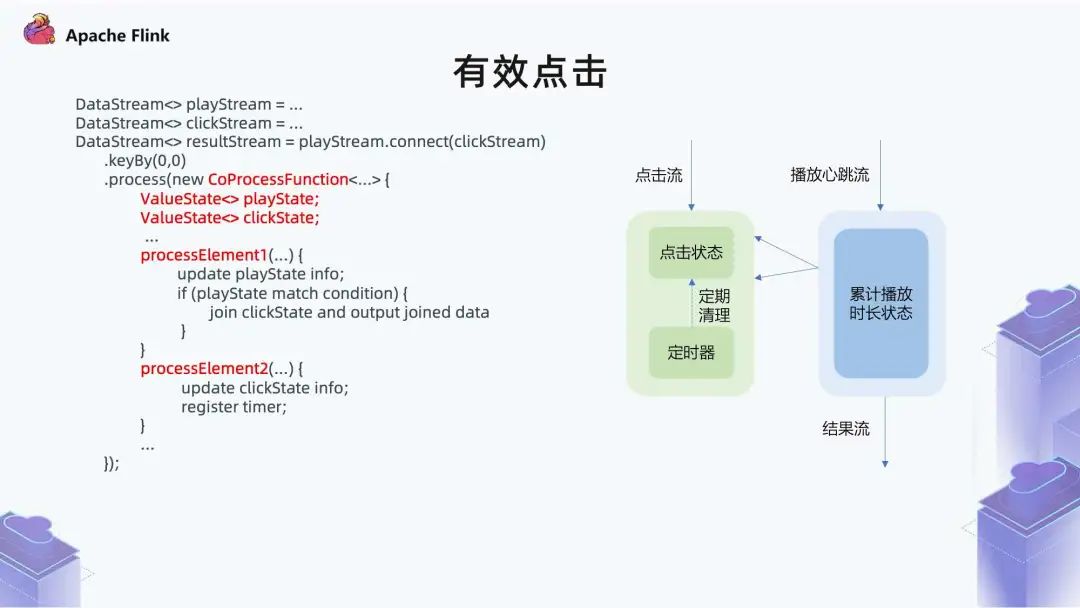
在左边的状态里面,一个点击事件进来之后,会对这个点击做一个状态记录,同时会注册一个定时器做定期清理,定时器是三个小时。因为大部分影片的时长在三小时以内,如果这个时候对应的播放事件还没有一个目标状态,点击事件基本就可以过期了。
在右边的播放心跳流里,这个状态是对时长做累计,它本身是一个心跳流,比如每三秒传一个心跳过来。我们需要在这里做一个计算,看它累计播放时长是不是达到 6 分钟了,另外也看当前记录是不是到了 6 分钟。对应 Flink 里的一个实现就是把两个流通过 Connect 算子关系在一起,然后可以制定一个 CoProcessFunction,在这里面有两个核心算子。 第一个算子是拿到状态 1 的流事件之后,需要做一些什么样的处理; 第二个算子是拿到第 2 个流事件之后,可以自定义哪些功能。
■ 2.5 特征工程 - 小结

三、Flink 使用过程中的问题及解决
1. 容错

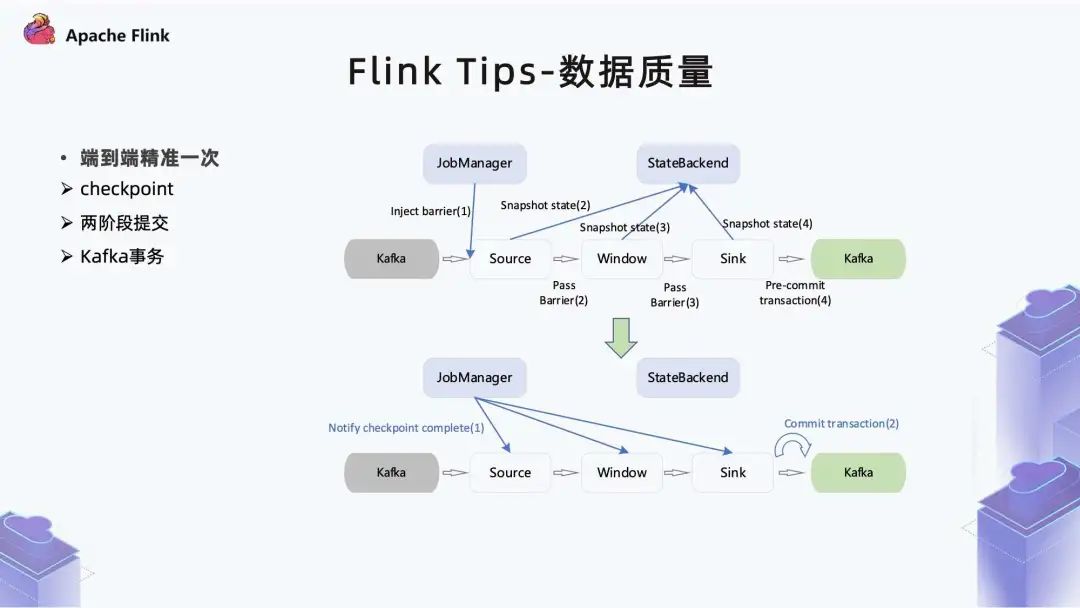
2. 数据质量
3. Sink Kafka

第一个办法是用户自定义一个 FlinkKafkaPartitioner;
另一个办法是默认不配置,默认轮询写入各个 Partition。
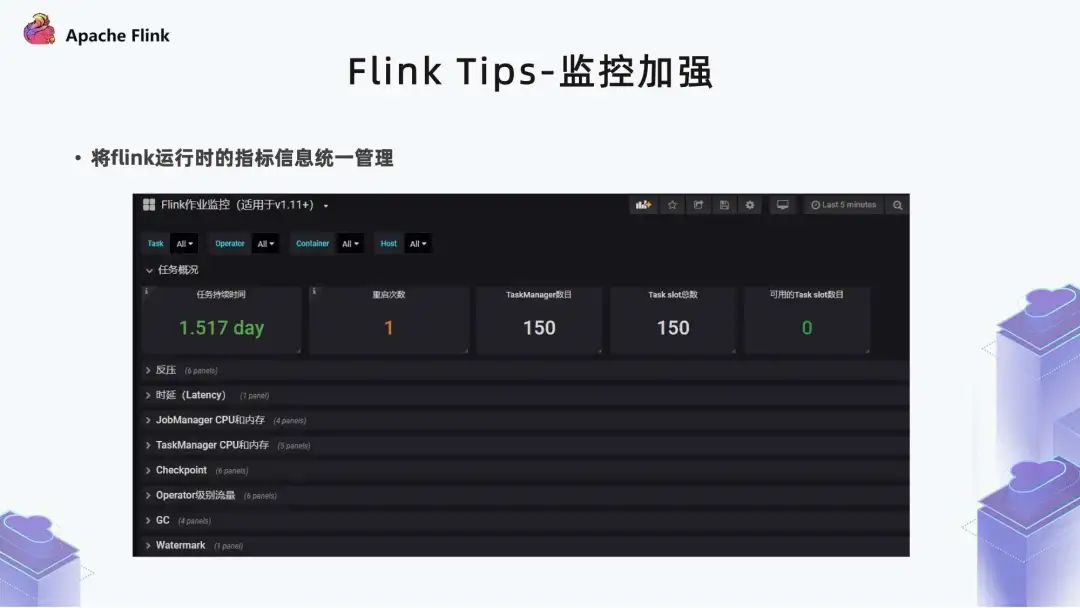
4. 监控加强
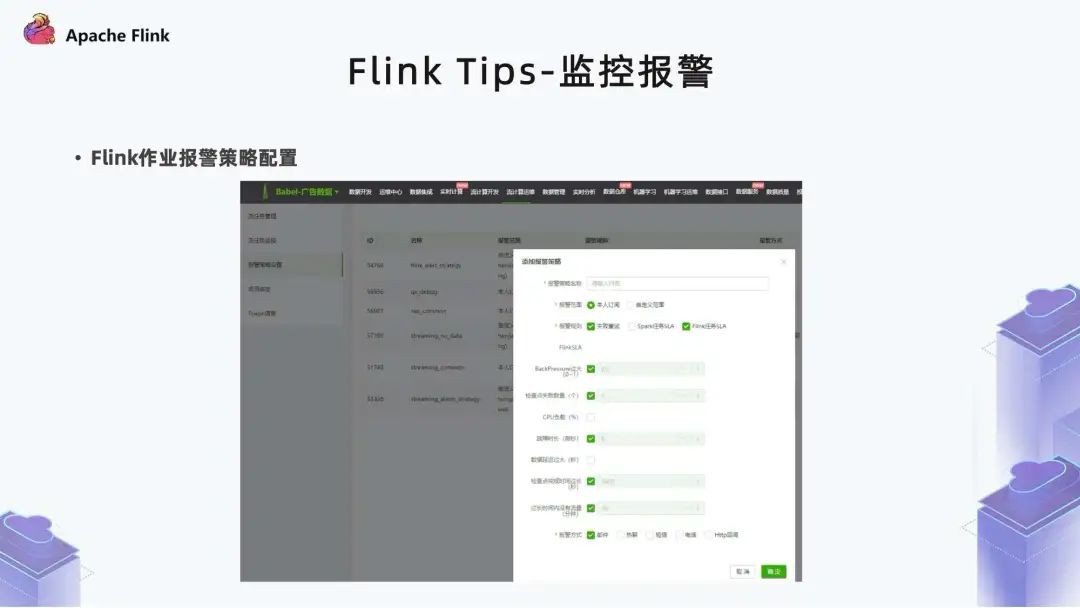
5. 监控报警
6. 实时数据生产
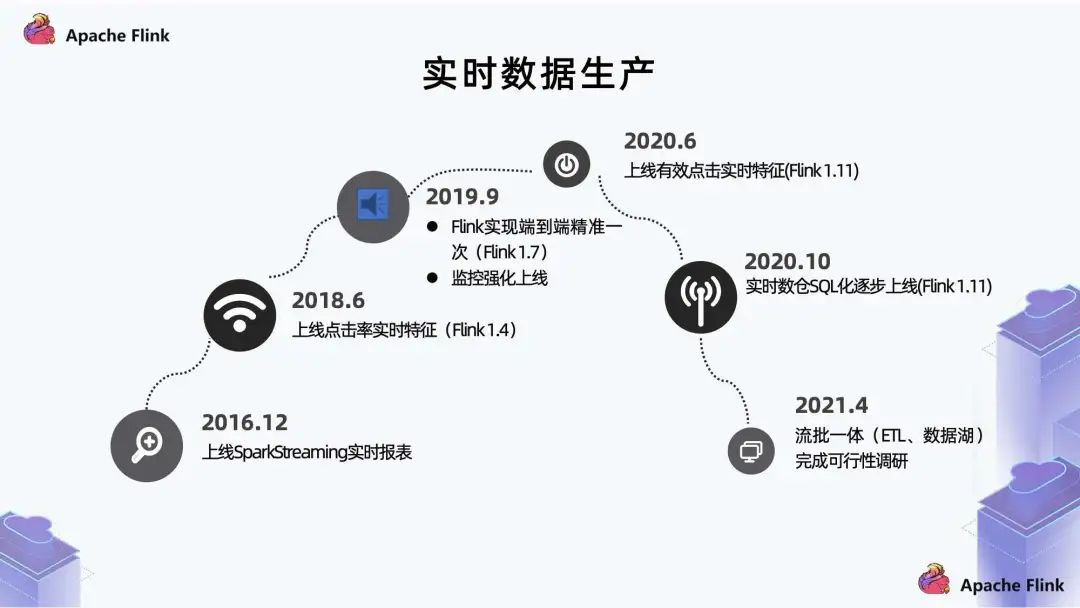
我们的实时是从 2016 年开始起步,当时主要功能点是做一些指标实时化,使用的是 SparkStreaming; 2018 年上线了点击率实时特征; 2019 年上线了 Flink 的端到端精确到一次和监控强化。 2020 年上线了有效点击实时特征; 同年10月,逐步推进实时数仓的改进,把 API 生产方式逐渐 SQL 化;
2021 年 4 月,进行流批一体的探索,目前先把流批一体放在 ETL 实现。
四、未来规划

首先是流批一体,这里包括两个方面: 第一个是 ETL 一体,目前已经是基本达到可线上的状态。 第二个是实时报表 SQL 化和数据湖的结合。 另外,现在的反作弊主要是通过离线的方式实现,后面可能会把一些线上的反 作弊模型转成实时化,把风险降到最低。
评论