
Flink新增特性 | CDC(Change Data Capture) 原理和实践应用
点击上方蓝色字体,选择“设为星标”




使用flink sql进行数据同步,可以将数据从一个数据同步到其他的地方,比如mysql、elasticsearch等。
可以在源数据库上实时的物化一个聚合视图
因为只是增量同步,所以可以实时的低延迟的同步数据
使用EventTime join 一个temporal表以便可以获取准确的结果
数据库之间的增量数据同步
审计日志
数据库之上的实时物化视图
基于CDC的维表join
…
Flink CDC使用方式
目前Flink支持两种内置的connector,PostgreSQL和mysql,接下来我们以mysql为例。
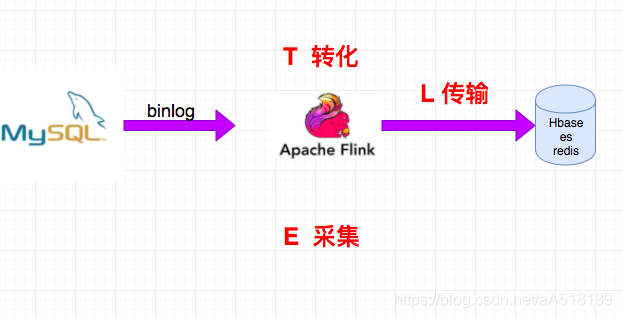
使用这种架构是好处有:
减少canal和kafka的维护成本,链路更短,延迟更低
flink提供了exactly once语义
可以从指定position读取
去掉了kafka,减少了消息的存储成本
<dependency><groupId>com.alibaba.ververicagroupId><artifactId>flink-connector-mysql-cdcartifactId><version>1.1.0version>dependency>
如果是sql客户端使用,需要下载 flink-sql-connector-mysql-cdc-1.1.0.jar 并且放到
连接mysql数据库的示例sql如下:
-- creates a mysql cdc table sourceCREATE TABLE mysql_binlog (id INT NOT NULL,name STRING,description STRING,weight DECIMAL(10,3)) WITH ('connector' = 'mysql-cdc','hostname' = 'localhost','port' = '3306','username' = 'flinkuser','password' = 'flinkpw','database-name' = 'inventory','table-name' = 'products');
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.functions.source.SourceFunction;import com.alibaba.ververica.cdc.debezium.StringDebeziumDeserializationSchema;import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;public class MySqlBinlogSourceExample {public static void main(String[] args) throws Exception {SourceFunction<String> sourceFunction = MySQLSource.<String>builder().hostname("localhost").port(3306).databaseList("inventory") // monitor all tables under inventory database.username("flinkuser").password("flinkpw").deserializer(new StringDebeziumDeserializationSchema()) // converts SourceRecord to String.build();StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.addSource(sourceFunction).print().setParallelism(1); // use parallelism 1 for sink to keep message orderingenv.execute();}}
<dependency><groupId>org.apache.flinkgroupId><artifactId>flink-connector-kafka_2.11artifactId><version>1.11.0version>dependency>
CREATE TABLE topic_products (id BIGINT,name STRING,description STRING,weight DECIMAL(10, 2)) WITH ('connector' = 'kafka','topic' = 'products_binlog','properties.bootstrap.servers' = 'localhost:9092','properties.group.id' = 'testGroup','format' = 'canal-json' -- using canal-json as the format)
<dependency><groupId>com.alibaba.ververicagroupId><artifactId>flink-format-changelog-jsonartifactId><version>1.0.0version>dependency>
-- assuming we have a user_behavior logsCREATE TABLE user_behavior (user_id BIGINT,item_id BIGINT,category_id BIGINT,behavior STRING,ts TIMESTAMP(3)) WITH ('connector' = 'kafka', -- using kafka connector'topic' = 'user_behavior', -- kafka topic'scan.startup.mode' = 'earliest-offset', -- reading from the beginning'properties.bootstrap.servers' = 'localhost:9092', -- kafka broker address'format' = 'json' -- the data format is json);-- we want to store the the UV aggregation result in kafka using changelog-json formatcreate table day_uv (day_str STRING,uv BIGINT) WITH ('connector' = 'kafka','topic' = 'day_uv','scan.startup.mode' = 'earliest-offset', -- reading from the beginning'properties.bootstrap.servers' = 'localhost:9092', -- kafka broker address'format' = 'changelog-json' -- the data format is json);-- write the UV results into kafka using changelog-json formatINSERT INTO day_uvSELECT DATE_FORMAT(ts, 'yyyy-MM-dd') as date_str, count(distinct user_id) as uvFROM user_behaviorGROUP BY DATE_FORMAT(ts, 'yyyy-MM-dd');-- reading the changelog back againSELECT * FROM day_uv;


版权声明:
文章不错?点个【在看】吧! ?
评论