
CVPR 2021 | KeepAugment:一种简单的信息保存数据扩增方法, 助力分类/分割/检测涨点!

极市导读
KeepAugment 提出了一种简单但高效的方法,称为"保持增强",以提高增强图像的保真度。实验证明 KeepAugment 可以提升绝大多数数据扩增方法的有效性,实现了在分类/分割/检测等多个领域涨点。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
数据增强(DA)是实现深度学习网络有效涨点的技巧,如CutMix、AutoAugmemt等,在图像分类、目标检测等方向实现了简单粗暴涨点,但数据扩增可能会引入noisy 增强样本,从而在推理过程中损害未增强数据的性能,为缓解此问题,KeepAugment 提出了一种简单但高效的方法,称为"保持增强",以提高增强图像的保真度。这个想法是首先使用显著图来检测原始图像上的重要区域,然后在增广过程中保留这些信息区域。这种信息保存策略使我们能够生成更多保真的训练样本。实验证明 KeepAugment 可以提升绝大多数数据扩增方法的有效性,实现了在分类/分割/检测等多个领域涨点。

论文:KeepAugment: A Simple Information-Preserving Data Augmentation Approach
链接:https://arxiv.org/abs/2011.11778
01 Data Augmentation
数据增强被证明是解决各种挑战性深度学习任务的关键技术,在多个领域如图像分类,图像分割,目标检测和半监督学习。尽管数据增强会增加有效数据的大小并增加训练数据的多样性,但这不可避免地会在训练过程中引入具有噪声和歧义的扩增样本。 图 1
图 1
1.1 Data Augmentation
KeepAugment 的工作主要关注标签不变的数据扩增方法,当前数据扩增的方法大致可以分为区域级别增强方法,例如Cutout(图1 a2和b2)和CutMix,它们可以掩盖或修改图像的随机选择的矩形区域,以及图像级增强方法,例如AutoAugment 和 RandAugment(图1 a3和b3)),它们利用增强学习来找到用于选择和组合不同的标签不变变换(例如,旋转,颜色反转,翻转)的最佳策略。
1.2 Data Augmentation and its Trade-offs
尽管数据增强能够增加数据的有效大小,但如果增强幅度控制不当,可能会导致信息丢失并引入噪声和歧义。作者在CIFAR-10数据集上使用Cutout和RandAugment两种方法进行实验,分析数据增强方式的强度与准确性Acc的关系,其中cutout的强度由Cutout length控制,RandAugment的强度由Distortion magnitude控制,实验结果如下图所示:
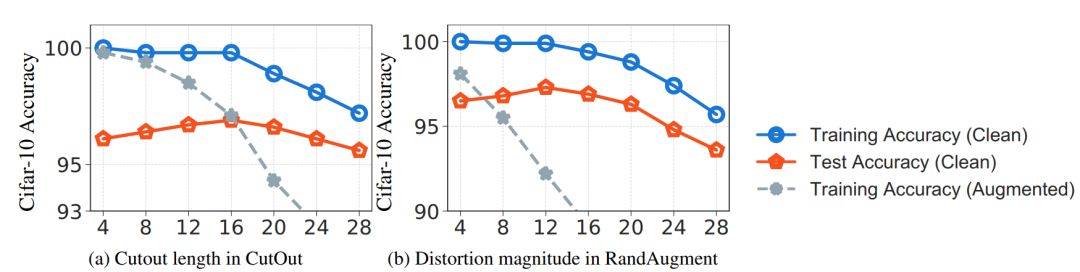
从上图可以看出,正如通常所期望的,在两种情况下,泛化(原始数据的训练和测试准确性之间的差距)都会随着变换幅度的增加而提高。但是,当变换的幅度太大时(对于Cutout≥16,对于RandAugment≥12),训练精度(蓝线)和测试精度(红线)开始退化,表明增强的数据没有在这种情况下,较长的时间持续地表示干净的训练数据,以使增强数据上的训练损失不能再替代干净数据上的训练损失。
02 KeepAugment
KeepAugment的思路是通过saliency map(如图1 a4和b4)测量图像中矩形区域的重要性,并确保在数据增强后保留重要性得分最高的矩形区域。 对于Cutout,作者通过避免剪切重要区域来实现这一点(请参见图1 a5和b5);对于图像级转换,例如RandAugment,作者通过将重要区域粘贴到转换图像的顶部来实现此目的(请参见图1 a6和b6)。
2.1 KeepAugment
从上面的思路中不难分析出KeepAugment主要可以分为(1)计算saliency map(2)保留重要的矩形区域这两个步骤。其中第二步又可以根据数据增强方式分为Selective-Cut,Selective-Paste。
Saliency map
KeepAugment 通过 vanilla gradient 方法获取saliency map,具体来说,给定图像x及其对应标签logit value ly(x),KeepAugment 将gij(x, y)设为vanilla gradients的绝对值| ∇x ly(x)|。对于RBG图像,采用通道最大值,以获取每个像素(i,j)的单个显着性值。重要性得分定义的公式如下所示:
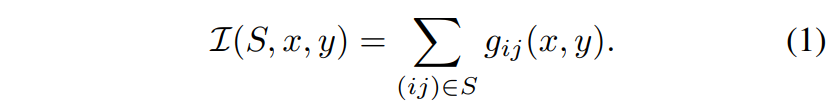
Selective-Cut
KeepAugment对于区域级的数据增强方法(如:cutout), 我们通过确保被切割的区域不会具有较大的重要性得分来控制数据增强的保真度。这实际上是通过**Algorithm 1(a)**实现的,在算法1中,我们随机采样要切割的区域S,直到其重要性得分I(S,x,y)小于给定的阈值τ。相应的数据增强定义如下: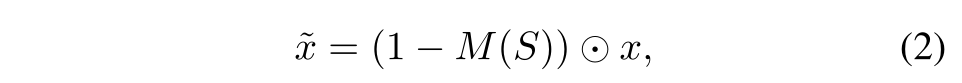 其中
其中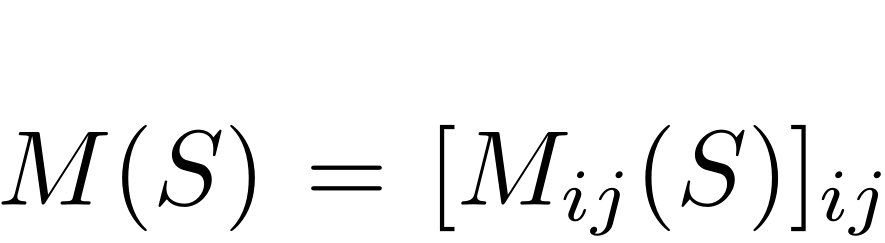 是切割的区域S的binary mask,
是切割的区域S的binary mask,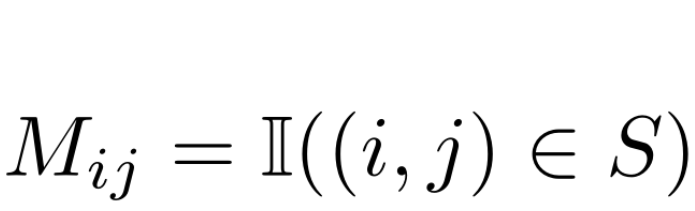
Selective-Paste
因为图像级变换共同修改了整个图像,所以我们通过粘贴具有较高重要性的随机区域来确保变换的保真度,Algorithm 1(b) 显示了如何在实践中实现此目标的方法,其中绘制图像级别的增强数据x0 = A(x),对满足阈值τ的I(S, x, y)>τ的区域S进行均匀采样,然后将原始图像x的regionS粘贴到x',从而得出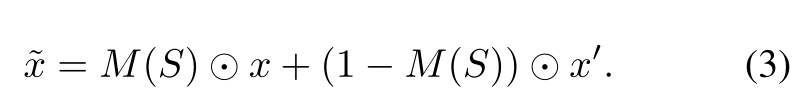

2.2 Efficient Implementation of KeepAugment
KeepAugment要求在每个训练步骤中通过反向传播来计算 saliency map。直接计算的话会导致计算成本增加两倍。在这一部分中,作者提出了两种有效的策略来计算saliency map。
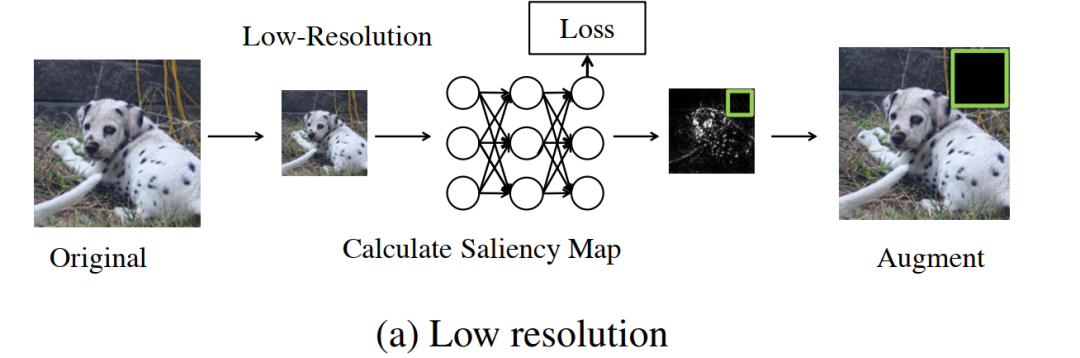
基于低分辨率的近似方法, 作者进行如下操作:a)对于给定的图像x,首先生成一个低分辨率副本,然后计算其saliency map;b)将低分辨率saliency map映射到其相应的原始分辨率。这样能够显着加快saliency map的计算速度,例如在ImageNet上,通过将分辨率从224降低到112,实现了3倍的计算成本降低。
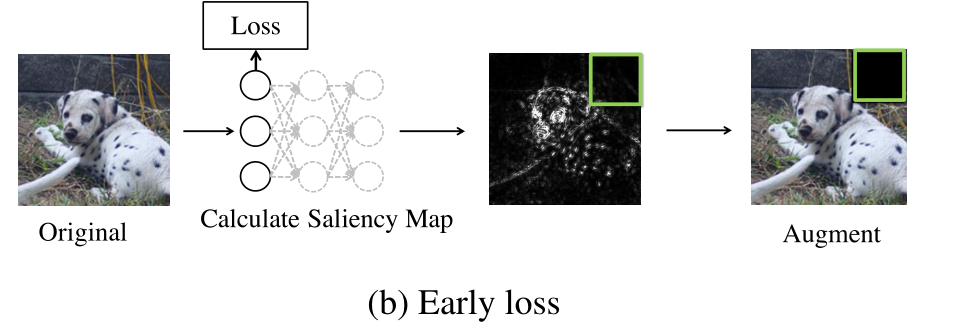
基于Eary loss的近似方法,第二个想法是在网络前面层添加loss,然后用此loss来saliency map。实际上,在评估了网络的第一块之后添加了一个附加的平均池化层和一个线性头。我们的训练目标与Inception Network相同。用标准损失和辅助损失训练神经网络。在计算saliency map时,实现了3倍的计算成本降低。
在实验中,作者表明两种近似策略均不会导致任何性能下降。
03 实验结果
作者经过实验表明KeepAugment在各种挑战性深度学习任务(包括图像分类,半监督图像分类,多视图多摄像机跟踪,和目标检测)中都实现了准确率的提升。
分类任务:
(1)CIFAR-10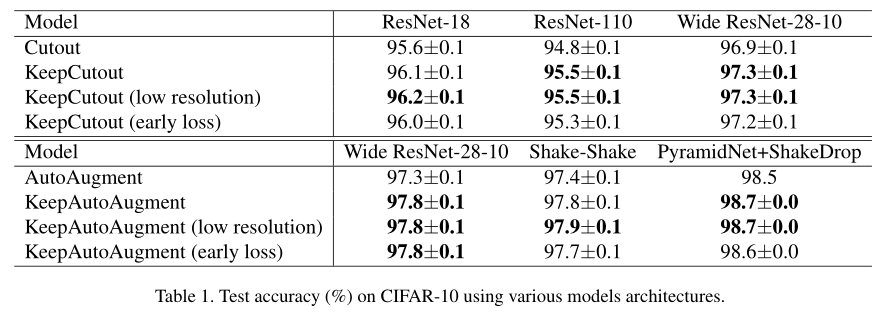 (2)ImageNet
(2)ImageNet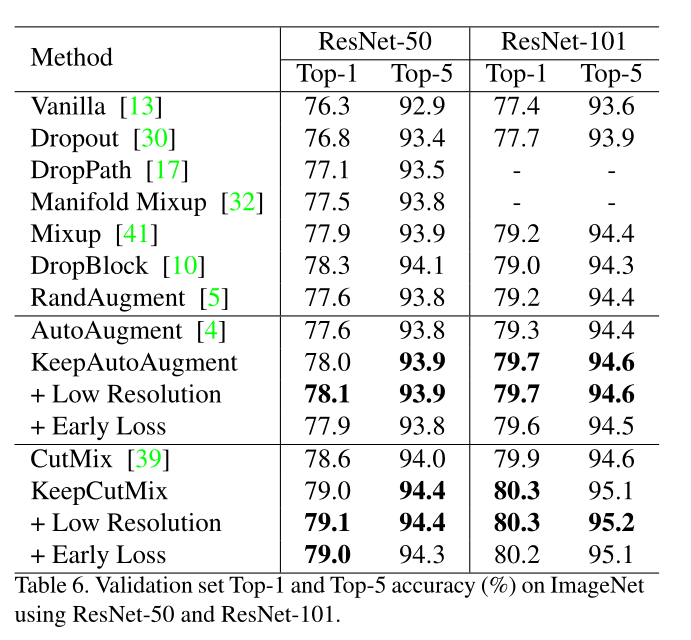
目标检测任务:
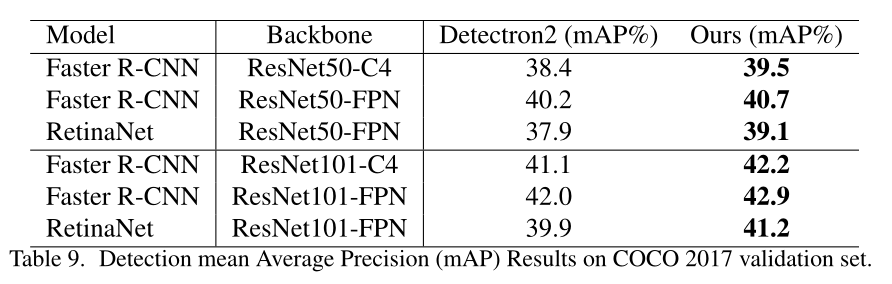
半监督学习:
04 实验结果
这篇文章分析表明现有的数据增强方案可能会引入noisy 增强样本,从而限制了它们提高整体性能的能力。因此,作者使用saliency map来衡量每个区域的重要性,并提出避免区域级数据增强方法(例如Cutout)切割重要区域;或从原始数据中粘贴关键区域以进行图像级数据增强。总而言之,KeepAugment 是一项能够提高数据增强有效性的通用方法
推荐阅读
2021-03-13
2021-03-12

2021-03-11


# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
