
SimMIM:一种更简单的MIM方法
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
自从何恺明的MEA:视觉无监督训练新范式出来之后,基于MIM(Masked Image Modeling)的无监督学习方法越来越受到关注。这里介绍一篇和MAE同期的工作:SimMIM: A Simple Framework for Masked Image Modeling,研究团队是微软亚研院。SimMIM和MAE有很多相似的设计和结论,而且效果也比较接近,比如基于ViT-B的模型无监督训练后再finetune可以ImageNet数据集达到83.8%的top1 accuray(MAE为83.6%)。不过相比MAE,SimMIM更加简单,而且也可以用来无监督训练金字塔结构的vision transformer模型如swin transformer等。目前SimMIM实现代码已经开源,本文将基于论文和源码对SimMIM方法进行解读。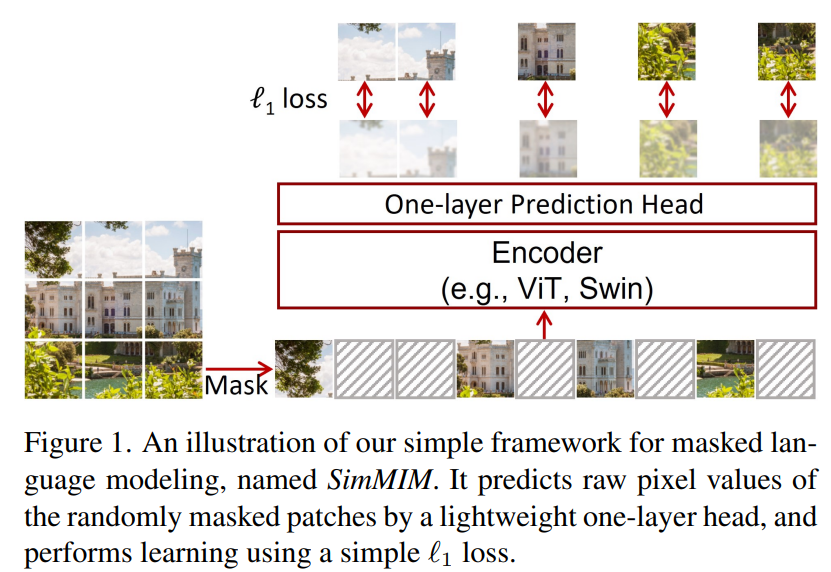
算法原理
SimMIM采用最简单的MIM方法:随机mask掉输入图像的一部分patch,然后通过encoder-decoder来预测masked patchs的原始像素值。算法原理图如上图所示,从设计方面和MAE基本一致。SimMIM的主要结论如下:
直接对图像采用简单的random mask是非常简单有效的方法; 直接回归原始的像素的RGB值不比BEiT采用的分类效果差; decoder采用轻量级的设计(直接采用一个线性层)也能得到很好的效果;
这些结论也是在MAE论文中得到了验证。那么SimMIM和MAE的区别在哪里呢?主要有以下两点:
SimMIM的encoder同时处理visible tokens和masked tokens,而MAE的encoder只处理visible tokens; SimMIM的decoder只采用一个线性层来回归像素值,而MAE的decoder采用transformer结构;
第2个差异带来的影响相对很小,因为两个论文都证明了decoder设计对性能影响较小。主要的差异点是第一个,MAE训练时只处理visible tokens一方面可以加速训练(减少了计算量),同时也可以减少pre-training和deploy之间的gap(deploy时输入是非masked的图像,无masked token),MAE实验也证明只处理visible tokens可以提升linear probing性能:73.5% vs 59.6%。而SimMIM是处理所有的tokens,从实验结果上看也符合MAE的结论,SimMIM方法得到的ViT-B模型的linear probing只有56.7%,不过这不并不会影响finetune后的性能,关于这点MAE论文也论证了。不过SimMIM这样做带来的一个好处是可以用来训练其它非“同质结构”模型,比如swin transformer,由于它各个stage间要对patch进行merge操作,所以token并不是像ViT那样一成不变的。下面我们具体介绍SimMIM的各个部分,这里默认实验都是以Swin-B为encoder,为了减少实验成本,输入图像大小为192x192(原来是224),window size设置为6(原来是7),预训练epoch为100。
Masking Strategy
SimMIM的masking策略按照一定mask ratio随机mask掉一部分patch。在MAE中,masked patch size和ViT的patch size是一致的,比如ViT-B/16模型,masked patch size就要设计为16x16,然后用一个可学习的masked token来代替。但是对于SimMIM,其设计masked patch size不一定等于模型的patch size,比如ViT模型masked patch size可以是32x32,理论上mask patch size只要是ViT模型patch size的整数倍就可以,因此此时每个mask掉的patch可以整分成和模型patch一样大小的若干个patch。对于金字塔结构的swin transformer,每个stage的patch size是不同的,比如第一个stage的patch size是4x4,而最后一个stage的patch size是32x32,此时设计的mask patch size只需要是第一个stage的patch size整数就好。无论是ViT还是swin transformer,masked token对应的patch size都是其patch embedding层对应的patch size,对于ViT就是16x16,而对于swin transformer就是4x4,而mask patch size只需要是masked token的patch size的整数倍即可。所以SimMIM采用更灵活的mask patch size,不同mask patch size的可视化效果如下图所示。对于ViT和swin transformer,SimMIM都默认采用:mask ratio=0.6,mask patch size=32x32。 不同的mask type,mask patch size和mask ratio对模型效果(finetune)的影响如下表所示,可以看到不同的设置均可以取得类似的效果,其中random+masked patch size=32x32+mask ratio=0.5可取得最优的效果83.0%。
不同的mask type,mask patch size和mask ratio对模型效果(finetune)的影响如下表所示,可以看到不同的设置均可以取得类似的效果,其中random+masked patch size=32x32+mask ratio=0.5可取得最优的效果83.0%。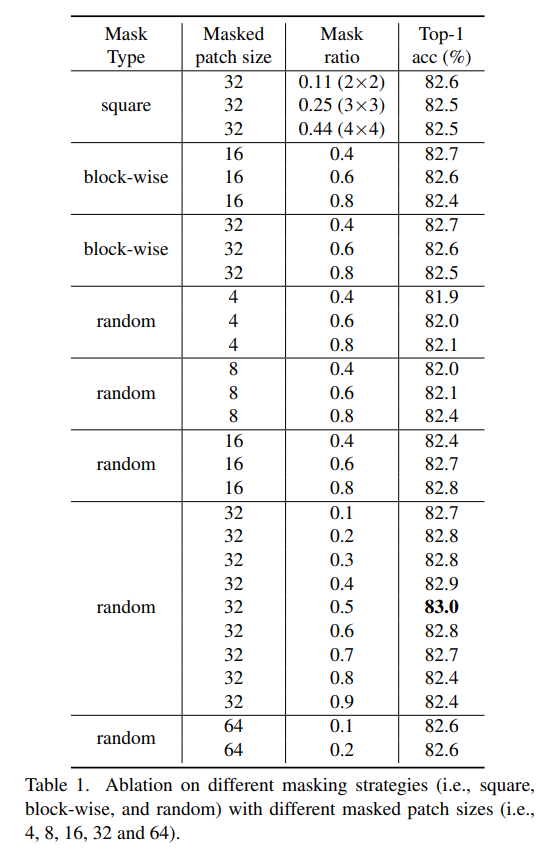 从表中可以看出,采用较小的masked patch size(4x4,8x8,16x16),模型效果随着mask ratio的增加而提升,而对于更大的masked patch size(64x64),需要采用较小的mask ratio才能得到较好的结果。masked patch size和mask ratio影响的是MIM任务的难度,两者越大,MIM任务越难,要想取得较好的模型训练效果,MIM任务的难度要适当大一些。论文也提出了AvgDist指标来进一步分析masked patch size和mask ratio对模型finetune效果的影响,这里AvgDist指标计算的是所有masked pixels到最近的visible pixels的平均欧式距离,它综合了masked patch size和mask ratio对MIM任务的影响。从下图可以看出,AvgDist随着mask ratio的增加而增加,对于较小的masked patch size,其AvgDist在较大的mask ratio下依然较小,而较大的masked patch size,其AvgDist在较小的mask ratio下就比较大。从右图可以看出,AvgDist在[10, 20]区间内都可以取得较好的finetune效果,这个可以用来指导选择不同masked patch size和mask ratio组合。
从表中可以看出,采用较小的masked patch size(4x4,8x8,16x16),模型效果随着mask ratio的增加而提升,而对于更大的masked patch size(64x64),需要采用较小的mask ratio才能得到较好的结果。masked patch size和mask ratio影响的是MIM任务的难度,两者越大,MIM任务越难,要想取得较好的模型训练效果,MIM任务的难度要适当大一些。论文也提出了AvgDist指标来进一步分析masked patch size和mask ratio对模型finetune效果的影响,这里AvgDist指标计算的是所有masked pixels到最近的visible pixels的平均欧式距离,它综合了masked patch size和mask ratio对MIM任务的影响。从下图可以看出,AvgDist随着mask ratio的增加而增加,对于较小的masked patch size,其AvgDist在较大的mask ratio下依然较小,而较大的masked patch size,其AvgDist在较小的mask ratio下就比较大。从右图可以看出,AvgDist在[10, 20]区间内都可以取得较好的finetune效果,这个可以用来指导选择不同masked patch size和mask ratio组合。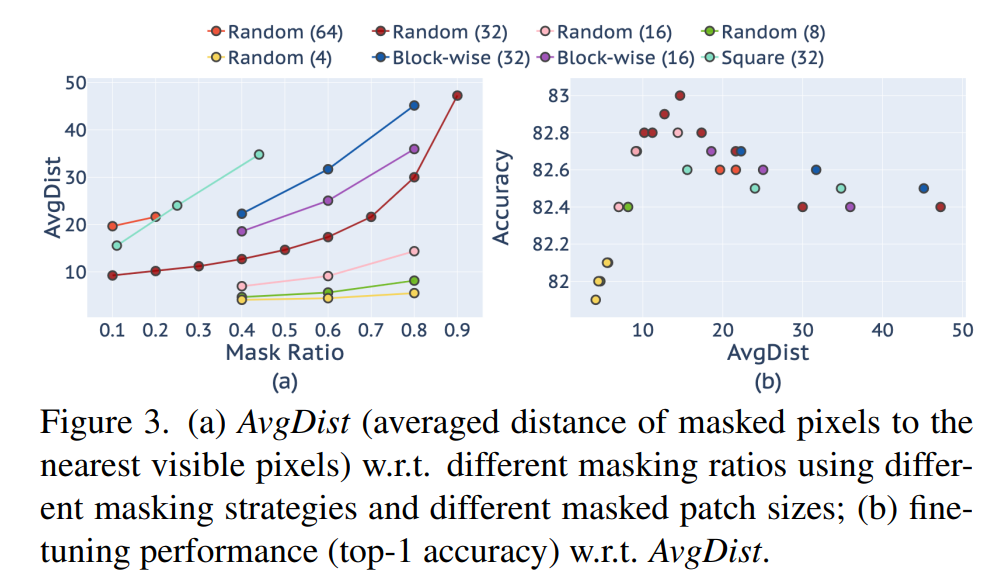
采用不同的masked patch size,其预测的图像效果如下所示,可以看到masked patch size越小,图像还原度越高,这也比较合理。但是MIM本身并不是为了更好地恢复图像,而是希望encoder学习到好的特征以迁移到下游任务。
随机mask策略的实现比较简单,在对每个图像进行数据增强后,同时随机生成一个mask;在模型forward时,将masked patch用mask token来替换,注意由于masked patch size和model_patch_size不一定相等,所以要将随机生成mask转换成和model_patch_size一致的mask。具体实现代码如下所示:
class MaskGenerator:
def __init__(self, input_size=192, mask_patch_size=32, model_patch_size=4, mask_ratio=0.6):
self.input_size = input_size # 输入图像大小
self.mask_patch_size = mask_patch_size # masked patch大小
self.model_patch_size = model_patch_size # 模型patch embed层的patch大小
self.mask_ratio = mask_ratio
assert self.input_size % self.mask_patch_size == 0
assert self.mask_patch_size % self.model_patch_size == 0
self.rand_size = self.input_size // self.mask_patch_size
self.scale = self.mask_patch_size // self.model_patch_size
self.token_count = self.rand_size ** 2
self.mask_count = int(np.ceil(self.token_count * self.mask_ratio))
def __call__(self):
mask_idx = np.random.permutation(self.token_count)[:self.mask_count]
mask = np.zeros(self.token_count, dtype=int)
mask[mask_idx] = 1
# 要转换成和model_patch size一致的mask
mask = mask.reshape((self.rand_size, self.rand_size))
mask = mask.repeat(self.scale, axis=0).repeat(self.scale, axis=1)
return mask
class SimMIMTransform:
def __init__(self, config):
self.transform_img = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.RandomResizedCrop(config.DATA.IMG_SIZE, scale=(0.67, 1.), ratio=(3. / 4., 4. / 3.)),
T.RandomHorizontalFlip(),
T.ToTensor(),
T.Normalize(mean=torch.tensor(IMAGENET_DEFAULT_MEAN),std=torch.tensor(IMAGENET_DEFAULT_STD)),
])
if config.MODEL.TYPE == 'swin':
model_patch_size=config.MODEL.SWIN.PATCH_SIZE
elif config.MODEL.TYPE == 'vit':
model_patch_size=config.MODEL.VIT.PATCH_SIZE
else:
raise NotImplementedError
self.mask_generator = MaskGenerator(
input_size=config.DATA.IMG_SIZE,
mask_patch_size=config.DATA.MASK_PATCH_SIZE,
model_patch_size=model_patch_size,
mask_ratio=config.DATA.MASK_RATIO,
)
def __call__(self, img):
img = self.transform_img(img) # 图像数据增强
mask = self.mask_generator() # 生成mask
return img, mask
class SwinTransformerForSimMIM(SwinTransformer):
def __init__(self, **kwargs):
super().__init__(**kwargs)
assert self.num_classes == 0
self.mask_token = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
trunc_normal_(self.mask_token, mean=0., std=.02)
def forward(self, x, mask):
x = self.patch_embed(x)
assert mask is not None
B, L, _ = x.shape
mask_tokens = self.mask_token.expand(B, L, -1)
w = mask.flatten(1).unsqueeze(-1).type_as(mask_tokens)
x = x * (1. - w) + mask_tokens * w
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x)
x = x.transpose(1, 2)
B, C, L = x.shape
H = W = int(L ** 0.5)
x = x.reshape(B, C, H, W)
return x
# 基于swinT的SimMIM
class SwinTransformerForSimMIM(SwinTransformer):
def __init__(self, **kwargs):
super().__init__(**kwargs)
assert self.num_classes == 0
# 定义可学习的masked token
self.mask_token = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
trunc_normal_(self.mask_token, mean=0., std=.02)
def forward(self, x, mask):
x = self.patch_embed(x)
assert mask is not None
B, L, _ = x.shape
mask_tokens = self.mask_token.expand(B, L, -1)
w = mask.flatten(1).unsqueeze(-1).type_as(mask_tokens)
x = x * (1. - w) + mask_tokens * w # 用masked token替换masked patch对应的patch embedding
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x)
x = x.transpose(1, 2)
B, C, L = x.shape
H = W = int(L ** 0.5)
x = x.reshape(B, C, H, W)
return x
Prediction Head
这里的prediction head指的就是decoder,用来预测masked patch的原始像素值。论文发现采用一个非常轻量级的decoder(只用1个linear层)就非常有效。采用更复杂的head,效果没有提升,反而会增加训练成本。MAE也指出decoder的设计对finetune性能影响较小,但是却会影响linear probing效果,如果采用较轻的decoder,那么encoder的后面部分层就要承担一部分像素预测任务(无监督训练代理任务),但这个却不是图像分类任务所需要的,所以会带来linear probing的下降,所以如果要想得到比较好的linear probing效果,就需要设计一个适当的decoder以将预测任务集中在decoder上。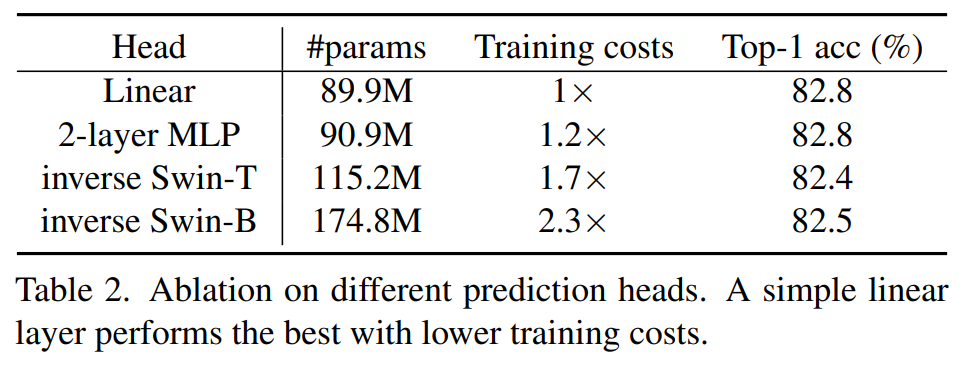 SimMIM默认采用单个linear层来预测像素值,在实现上采用一个1x1卷积层。对于swin transformer,其得到的特征图(恢复成hxw)是原来图像的1/32大小,那么卷积层输出channels等于3072=32x32x3,每个特征点预测32x32个pixels的RGB值。
SimMIM默认采用单个linear层来预测像素值,在实现上采用一个1x1卷积层。对于swin transformer,其得到的特征图(恢复成hxw)是原来图像的1/32大小,那么卷积层输出channels等于3072=32x32x3,每个特征点预测32x32个pixels的RGB值。
Prediction Tragets
SimMIM是直接回归masked patch的原始像素值,所以target就是原始图像的RGB值,而回归损失采用L1 loss,注意这里和MAE一样,只计算masked pixels的损失,论文也发现如果对所有pixels计算loss,效果会下降(82.8% -> 81.7%),prediction而不是reconstruction能更好地让encoder学习到更强的特征。另外一个参数是prediction resolution,SimMIM默认的prediction resolution是原始图像大小,但也可以对原始图像进行下采样,从而降低prediction resolution,从实验结果来看,采用不同的prediction resolution均能得到较好的结果,除了1/32表现相对差一些(图像损失比较严重):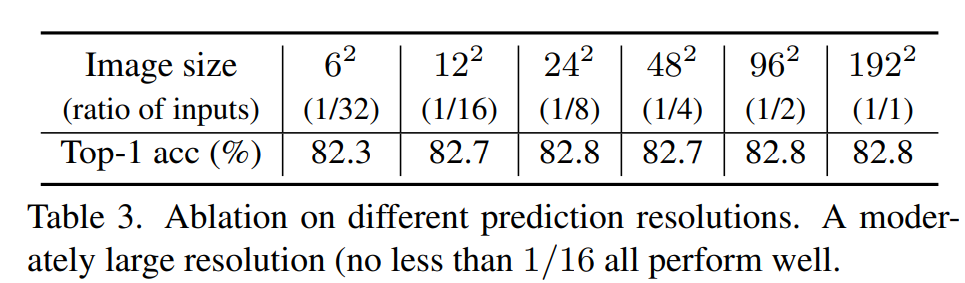
论文也对比了其它类型的targets,比如像BEiT那样用dVAE将回归变成分类任务,或者像IGPT那样采用color clustering。从下表的对比结果可以看到直接回归像素值并不比这些更复杂的设计差。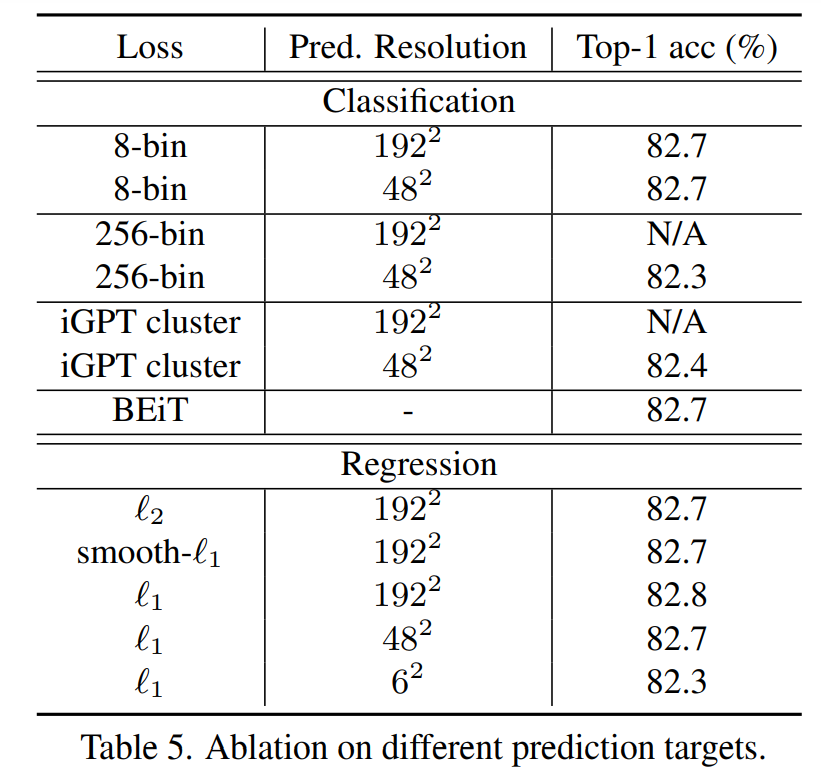 loss计算部分的实现也比较简单,具体的代码如下所示(注意这里回归的像素值是归一化后的像素值):
loss计算部分的实现也比较简单,具体的代码如下所示(注意这里回归的像素值是归一化后的像素值):
class SimMIM(nn.Module):
def __init__(self, encoder, encoder_stride):
super().__init__()
self.encoder = encoder
self.encoder_stride = encoder_stride
# 定义encoder
self.decoder = nn.Sequential(
nn.Conv2d(
in_channels=self.encoder.num_features,
out_channels=self.encoder_stride ** 2 * 3, kernel_size=1), # 1x1 conv等价于linear
nn.PixelShuffle(self.encoder_stride), # [B, 3*r*r, h, w] -> [B, 3, h*r, w*r]
)
self.in_chans = self.encoder.in_chans
self.patch_size = self.encoder.patch_size
def forward(self, x, mask):
z = self.encoder(x, mask) # encoder提取特征
x_rec = self.decoder(z) # decoder预测图像
# mask转变成和原始图像一样大小
mask = mask.repeat_interleave(self.patch_size, 1).repeat_interleave(self.patch_size, 2).unsqueeze(1).contiguous()
loss_recon = F.l1_loss(x, x_rec, reduction='none') # L1 loss
loss = (loss_recon * mask).sum() / (mask.sum() + 1e-5) / self.in_chans # 只计算masked pixels并取mean
return loss
实验设置及对比结果
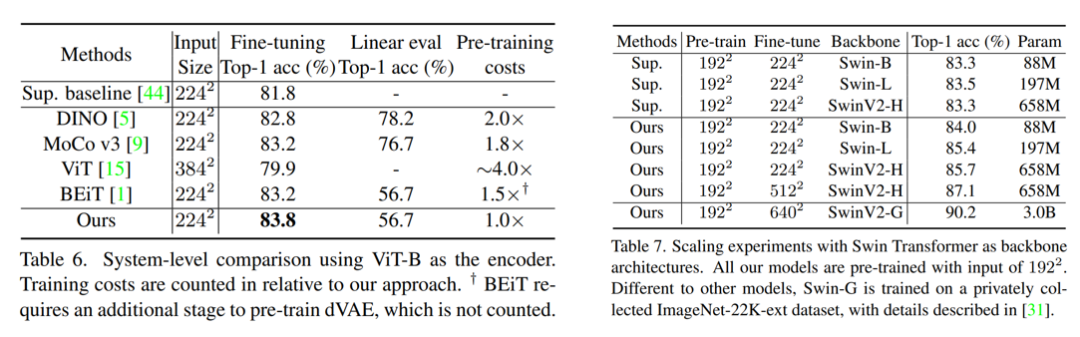
前面的实验都是以Swin-B为backbone,预训练的epoch为100,而最后的实验训练800个epoch,batch size为2048。在数据增强方面,只采用random resize croping:RandomResizedCrop(192, scale=(0.67, 1.), ratio=(3. / 4., 4. / 3.))以及水平翻转,和MAE一样属于轻量级的数据增强,这说明MIM方法确实不像对比学习那样需要较heavy的数据增强。对于ViT,预训练的图像大小是224,而SwinT采用的图像大小为192,对比结果如下表所示。可以看到:
基于SimMIM训练的ViT-B优于BEiT方法(83.8 vs 83.2),训练成本也比较低,但是linear probing效果均比较差(56.7); 基于SimMIM预训练的SwinT也优于有监督训练的模型,对于Swin-B,预训练800epoch相比100epoch有一定提升(82.8 vs 84.0),这里也包含SwinV2的实验,其中30亿参数的SwinV2-G的效果可达到90.2%。
下图是一些masked图像重建后的可视化,可以看出经过SimMIM训练后,模型能学习到一定的推理能力,比如mask掉一个物体或者人后,模型能学会补全背景。
小结
总结来看,SimMIM和MAE方法大致相同,两者的差异大概源自SimMIM是为Swin设计的,而MAE是为单纯的ViT结构设计的。一个缺憾是SimMIM方法虽然在SwinV2上做了验证,但是没有直接在下游检测和分割任务上的对比实验,而MAE方法在随后的工作Benchmarking Detection Transfer Learning with Vision Transformers中论证了其迁移到实例分割任务上的有效性。
参考
Masked Autoencoders Are Scalable Vision Learners SimMIM: A Simple Framework for Masked Image Modeling https://github.com/microsoft/SimMIM
推荐阅读
PyTorch1.10发布:ZeroRedundancyOptimizer和Join
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
