
CVPR 2021| 重新思考文本分割:新的数据集及一种针对文本特征的改进分割方法
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
CVPR 2021 相关论文、代码 、解读和demo整理,同时为了方便下载论文,已把部分论文上传到上面了,欢迎小伙伴们 star 支持一波!
https://github.com/DWCTOD/CVPR2021-Papers-with-Code-Demo

本文简要介绍CVPR 2021录用论文“Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach”的主要工作。本文贡献了一个带有比较全面的标注的大型文本分割数据集TextSeg,具有多种类型的标注:单词级别和字符级别的文本框和mask,以及OCR标注。另外,本文介绍了一种文字分割方法TexRNet,针对文本进行网络设计,包括关键特征提取和基于注意力的相似特征查找,可适应于文本的独特属性,例如非凸边界、纹理多样化等。本文还介绍了trimap损失函数和判别器损失函数,能够显著提高文本分割的性能。实验证明,TexRNet与其他SOTA方法相比能够提升2%左右。数据集和代码将开源:https://github.com/SHI-Labs/Rethinking-TextSegmentation。
一、研究背景
文本分割是许多与文本相关的计算机视觉任务的基础,并且在许多应用中发挥着重要作用。例如,文字风格迁移、场景文本擦除和交互式文本图像编辑之类的智能应用都需要先使用有效的文本分割方法,才能准确地解析复杂场景中的文本。然而,现有公开的文字分割数据集缺乏大规模和精细的注释,导致文字分割在当前研究上很大程度被忽略。因此,本文贡献了一个新的文本分割数据集:TextSeg,它从更广泛的来源中收集图像,包括场景文本和设计文本,相比现有数据集具有更加丰富和全面的标注。另外本文针对文本的独特属性,提出了文字分割方法TexRNet,并在所提出的TextSeg数据集以及其他四个公开数据集上均达到了SOTA效果。
二、TextSeg 数据集介绍
本文贡献的数据集TextSeg包含4024张图像,分别是从海报,贺卡,封面,徽标,路标,广告牌,数字设计,手写等中收集的。如图1所示,这些图像可以大致分为两种文本类型:1)场景文本,例如道路 标志和广告牌;2)设计文字,例如海报设计上的艺术文字。本文的数据集TextSeg主要是英文的(即大小写的字母,数字和标点符号)。与现有数据集相比,TextSeg提供了更全面的标注。如图2所示,TextSeg为每个单词和字符都标注了最小的四边形框,像素级Mask以及OCR标注,还有诸如阴影,3D,光晕等文本效果Mask。

图1 TextSeg数据集的部分样本展示

图2 TextSeg数据集的标注情况
表1和图3列出了TextSeg和现有四个文字分割数据集ICDAR13 FST[1],MLT_S[3],COCO_TS[2]和Total-Text[4]之间的统计比较和可视化比较。其中,TextSeg具有更多不同的文本类型和更加全面完善的标注。
表1 TextSeg与其他文字分割数据集之间的统计比较
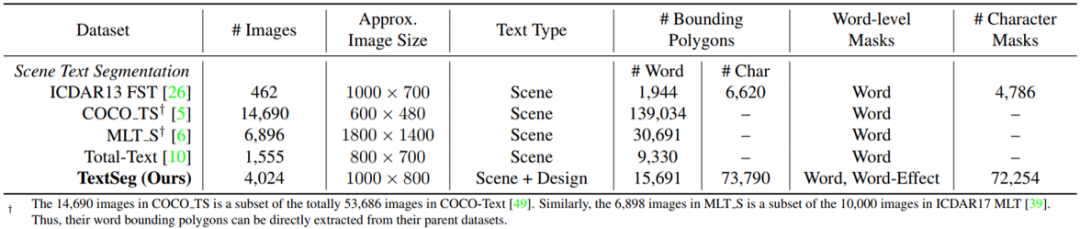

图3 TextSeg与其他文字分割数据集之间的可视化比较
三、TexRNet原理简述
语义分割中,树木,天空这些常见类别,在不同场景之间一般是有相似纹理的。然而在文本分割中,不同单词之间的文本纹理可能差异很大。为了适应纹理多样性,TexRNet根据低置信度区域与高置信度区域的全局相似性来动态激活低置信度区域,而不是使模型“记住”那些多样化的纹理。文本分割的另一个挑战是任意尺寸的文本,语义分割中普遍采用的卷积限制了模型的感受野,降低了模型对各种尺寸和宽高比的适应性。为了使模型适应不同尺寸的文本,作者借鉴Non-local的思想,使用点积和Softmax在整个图像上对相似纹理进行关注。
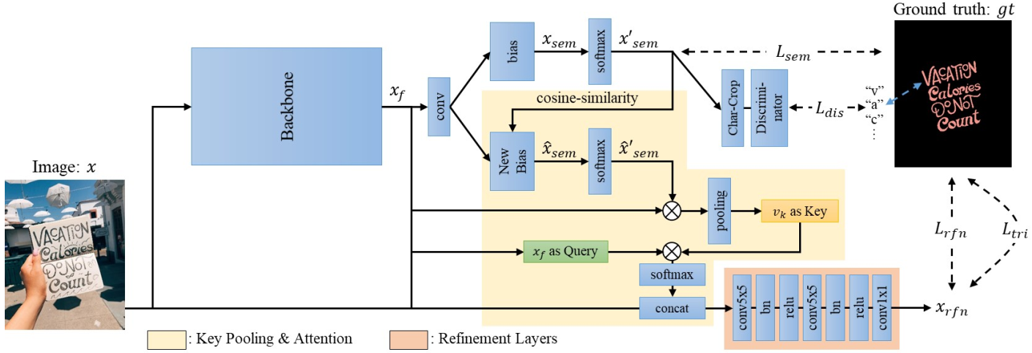
图4 TexRNet的整体网络结构
图4是TexRNet的网络结构,由两部分组成:1) 主干网,例如DeeplabV3+[5]或HRNet[6],2) 关键特征提取和Attention模块。首先输入一张图片x,经过主干网提取特征xf,与传统分割模型一样,特征xf通过带偏置的1×1卷积映射到语义图,再通过Softmax激活函数得到预测的分割图,然后直接与GT计算交叉熵损失,如公式(1)所示。
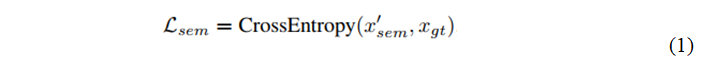
由于文本没有统一的纹理,在训练过程中没有可以学习的标准纹理,因此网络需要在推理过程中确定该文本纹理。具体而言,如果低置信度区域与同一类别的高自信度区域共享相似的纹理,则应该修改低置信度区域。为此,需要从高置信度区域提取每个类的关键特征,用来作为该类的全局视觉特征。更具体地说,我们对上面预测的分割图进行余弦相似度计算,如公式(2)所示,并将其作为新的偏置,对特征xf进行带有新的偏置的1x1卷积然后经过Softmax得到新的分割图,目的是为了降低Softmax之后每个类别的得分图。降低每个类别的得分之后,那些依然保持高亮的区域,作者认为这些区域足够好,就对这些区域提取关键特征vk,作为每个类别的全局特征。提取特征是在得分图和特征图xf之间的归一化加权和,如公式(3)所示。
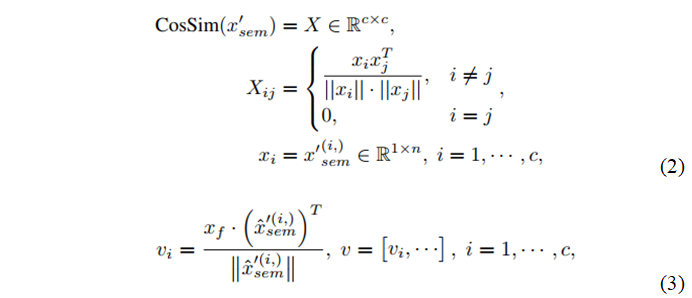
得到关键特征之后,作者用Attention的结构,将关键特征vk作为Key,将特征xf作为Quary,高亮出与关键特征vk相似的区域,得到一张Attention Map,再与原图进行卷积操作,预测出最终的分割图,同样也是跟GT做交叉熵损失。经过这个操作,可以实现动态激活与高置信度区域具有全局相似性的低置信度区域。另外还有两个损失函数,一个是判别器Loss,也就是一个预先训练好的字符分类器,另一个是跟边界有关的Loss,如公式(4)所示,作者认为文字的边界对分割的效果非常重要,因此这里用文字边界来做一个加权的交叉熵损失。最终的Loss是这几项的加权和。
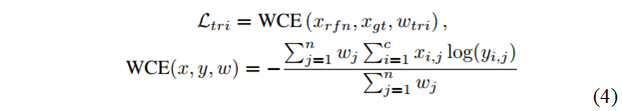
四、主要实验结果及可视化效果
作者在四个公开的文字分割数据集和本文公开的数据集上与现有的SOTA方法:DeeplabV3+[5]和HRNet-W48[6]相比较。其中图形判别器是在训练集上预训练好的ResNet50分类器。使用的评价指标是前景IoU(fgIoU)和前景F-score。如表2所示,在DeeplabV3+和HRNetV2-W48主干网上,本文的方法在各个数据集上都优于现有的方法。另外作者对文中的Attention模块,Trimap损失函数和字形判别器进行了消融实验,如表3所示,加上Attention模块和文中提出的两个损失函数都能使模型的性能得到提升。
表2 TexRNet和其他方法在五个数据集上的性能比较
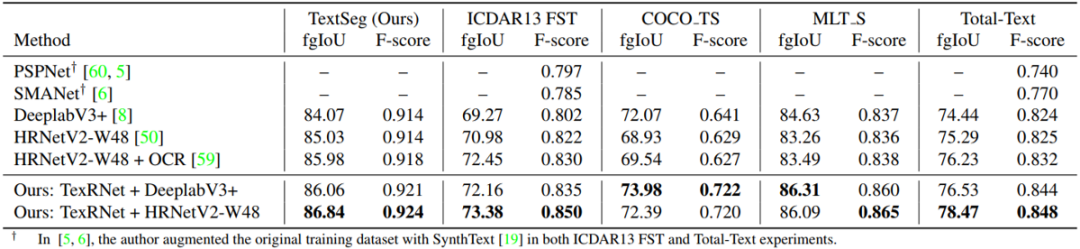
表3 Attention模块和损失函数的消融实验

本文公开的数据集还可以做一些下游任务的研究,比如场景文字擦除和文字风格迁移等。这里作者将场景文字擦除看做是一个Inpainting问题,并使用Deep Image Prior[7]进行实验。图5比较了三种类型的文字Mask(即文字分割Mask,字符边界框和单词边界框)的结果。显然,文字分割Mask能实现更好的文字擦除,因为它保留了更多的背景。另外文字风格迁移一般依赖于准确的文字Mask,在本实验中,作者使用ShapeMatching GAN[8]在任意文本图像上实现场景文字风格迁移。图6中展示了一些结果,可以看到有文字Mask能做到视觉上更好的文字风格迁移。

图5 不同类型文字Mask的文字擦除效果

图6 文字风格迁移示例
五、总结及讨论
本文公开了一个文字分割数据集TextSeg,该数据集由4024张场景文本和设计文本图像组成,并带有比较全面的标注,包括单词级别和字符级别的文本框和mask,以及OCR标注。此外,本文提出一种有效的文字分割方法TexRNet,并在本文的数据集和其他四个文字分割数据集上证明所提出的模型的优越性。另外,本文的数据集还能进行多个下游任务的研究,包括场景文字擦除,文字风格迁移等。
六、相关资源
论文地址:https://arxiv.org/abs/2011.14021
项目地址:https://github.com/SHI-Labs/Rethinking-TextSegmentation
参考文献
[1] Dimosthenis Karatzas, Faisal Shafait, Seiichi Uchida, Masakazu Iwamura, Lluis Gomez i Bigorda, Sergi Robles Mestre, Joan Mas, David Fernandez Mota, Jon Almazan Almazan, and Lluis Pere De Las Heras. Icdar 2013 robust reading competition. In 2013 12th International Conference on Document Analysis and Recognition, pages 1484–1493. IEEE, 2013.
[2] Simone Bonechi, Paolo Andreini, Monica Bianchini, and Franco Scarselli. Coco ts dataset: Pixel–level annotations based on weak supervision for scene text segmentation. In International Conference on Artificial Neural Networks, pages 238–250. Springer, 2019.
[3] Simone Bonechi, Monica Bianchini, Franco Scarselli, and Paolo Andreini. Weak supervision for generating pixel–level annotations in scene text segmentation. Pattern Recognition Letters, 138:1–7, 2020.
[4] Chee Kheng Ch’ng and Chee Seng Chan. Total-text: A comprehensive dataset for scene text detection and recognition. In 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), volume 1, pages 935–942. IEEE, 2017.
[5] Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In European Conference on Computer Vision, 2018.
[6] Jingdong Wang, Ke Sun, Tianheng Cheng, Borui Jiang, Chaorui Deng, Yang Zhao, Dong Liu, Yadong Mu, Mingkui Tan, Xinggang Wang, et al. Deep high-resolution representation learning for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
[7] Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky. Deep image prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9446–9454, 2018.
[8] Shuai Yang, Zhangyang Wang, Zhaowen Wang, Ning Xu, Jiaying Liu, and Zongming Guo. Controllable artistic text style transfer via shape-matching gan. In Proceedings of the IEEE International Conference on Computer Vision, pages 4442–4451, 2019.
原文作者: Xingqian Xu, Zhifei Zhang, Zhaowen Wang, Brian Price, Zhonghao Wang, Humphrey Shi
撰稿:陈邦栋
编排:高 学
审校:殷 飞
发布:金连文
免责声明:(1)本文仅代表撰稿者观点,撰稿者不一定是原文作者,其个人理解及总结不一定准确及全面,论文完整思想及论点应以原论文为准。(2)本文观点不代表本公众号立场。
个人微信(如果没有备注不拉群!)
请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021
在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看