深度学习前人精度很高了,该怎么创新?
共
3558字,需浏览
8分钟
·
2021-04-23 03:28
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
深度学习领域新技术层出不穷,顶尖的研究人员也愈来越多,当研究领域的前人精度已经很高了,我们该怎么创新,从哪些角度去创新呢?
https://www.zhihu.com/question/451438634
作者:仿佛若有光
公众号:CV技术指南
来源链接:
https://www.zhihu.com/question/451438634/answer/1813414490常见的思路我临时给它们取了几个名字:无事生非,后浪推前浪,推陈出新,出奇制胜。
1. 在原始的数据集上加一些噪声,例如随机遮挡,或者调整饱和度亮度什么的,主要是根据具体的任务来增加噪声或扰动,不可乱来。如果它的精度下降的厉害,那你的思路就来了,如何在有遮挡或有噪声或其他什么情况下,保证模型的精度。(无事生非)2. 用它的模型去尝试一个新场景的数据集,因为它原来的模型很可能是过拟合的。如果在新场景下精度下降的厉害,思路又有了,如何提升模型的泛化能力,实现在新场景下的高精度。(无事生非)3. 思考一下它存在的问题,例如模型太大,推理速度太慢,训练时间太长,收敛速度慢等。一般来说这存在一个问题,其他问题也是连带着的。如果存在以上的问题,你就可以思考如何去提高推理速度,或者在尽可能不降低精度的情况下,大幅度减少参数量或者计算量,或者加快收敛速度。(后浪推前浪)4. 考虑一下模型是否太复杂,例如:人工设计的地方太多,后处理太多,需要调参的地方太多。基于这些情况,你可以考虑如何设计一个end-to-end模型,在设计过程中,肯定会出现训练效果不好的情况,这时候需要自己去设计一些新的处理方法,这个方法就是你的创新。(后浪推前浪)5. 替换一些新的结构,引入一些其它方向的技术,例如transformer,特征金字塔技术等。这方面主要是要多关注一些相关技术,前沿技术,各个方向的内容建议多关注一些。(推陈出新)6.尝试去做一些特定的检测或者识别。通用的模型往往为了保证泛化能力,检测识别多个类,而导致每个类的识别精度都不会很高。因此你可以考虑只去检测或识别某一个特定的类。以行为识别为例,一些通用的模型可以识别几十个动作,但你可以专门只做跌倒检测。在这种情况下你可以加很多先验知识在模型中,换句话说,你的模型就是专门针对跌倒设计的,因此往往精度可以更高。(出奇制胜)注:这种特定类的检测最好是有些应用前途,让人觉得现实中可以有。以上都是一些针对性的思路,最原始的做法应该是看完方向上比较重要的论文后自己写一个综述,写的过程中往往会发现一些问题,不一定就是要去跟sota模型比精度,而是解决这个方向上还存在的问题。例如前面提到的实现轻量化,提高推理速度,实现实时检测,设计end to end模型,都属于解决这个方向上存在的问题,此外还包括一些其他的问题,这个得根据具体任务才能分析。如果说写完综述后还是没思路,一来是建议尝试以上思路,二来建议找一些跟你方向相关的经典论文看一看,边看边想,这四个字最重要。
作者:DLing
来源链接:
https://www.zhihu.com/question/451438634/answer/1815201106大家在写论文做研究的时候,需要找创新点,但是别人指标已经很高了,这还怎么创新呢?其实创新也不一定非要提精度啊。
你模型指标不是很高么?那也是你现有的分布下指标高,我给你加点料你还能高么?大家可能要想,这不没事找事么,这人真讨厌。但实际上,目前深度学习被人诟病的就有这点,为什么一个人身上加点图案你就检测不出来了啊,那深度学习还能可信么?这样关于深度学习的攻击对抗方向就有了很重要的研究价值。
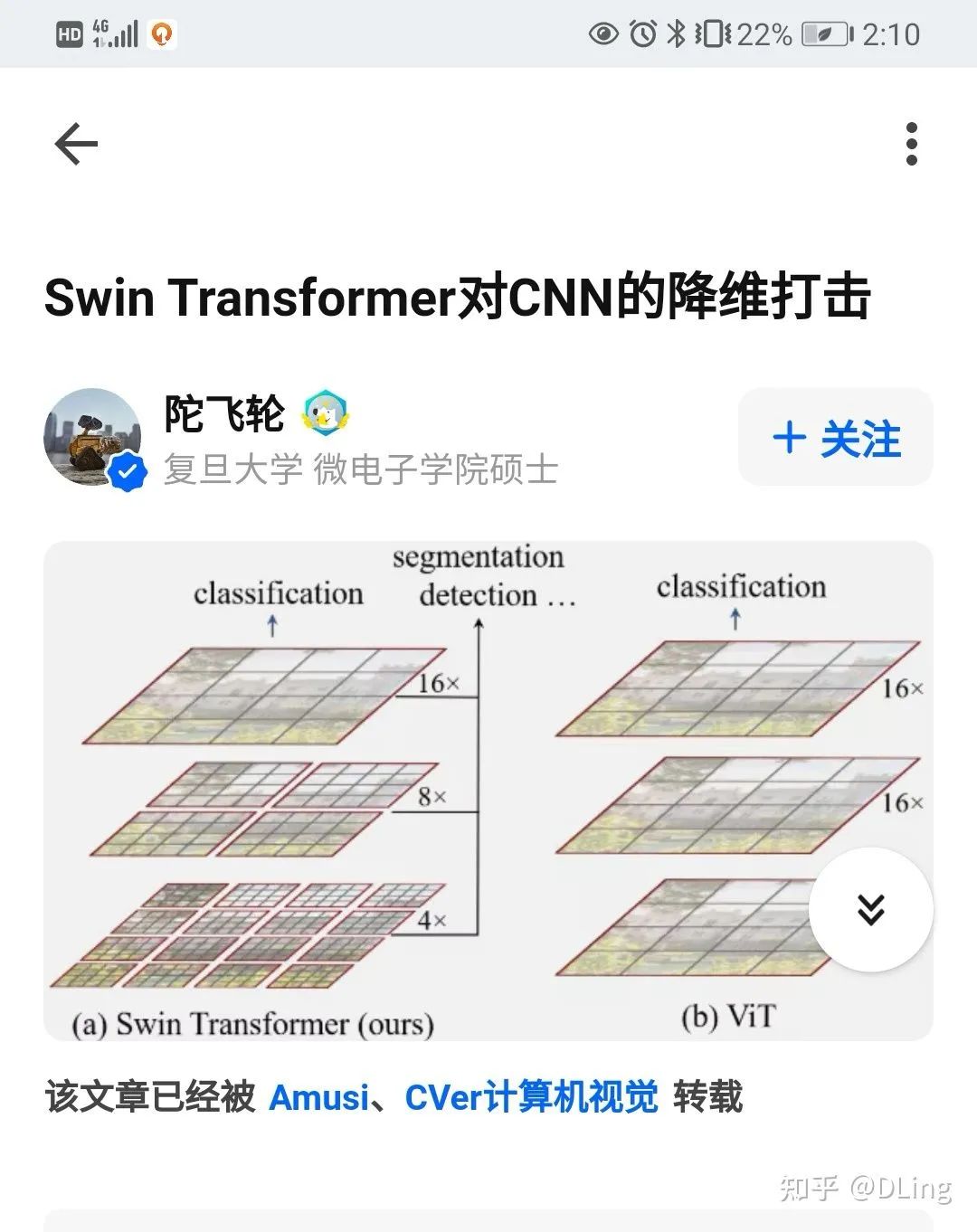
大家都知道transformer在nlp上效果很好,而最近大家cnn,cnn加传统attention已经玩腻了,指标也很高了,那就跨个界呗,让transformer也来cv界玩一玩,这样基本以前所有的论文都可以加transformer再来一次了。目前是transformer在cv上效果不错,大家趋之若鹜。即使,效果没这么好,那这种新的方向的引入也是很有价值的,效果好,皆大欢喜,效果没想象的那么好,那这个研究也至少为后人踩坑了嘛。当然,除了这些,也可以在目前比较新的论文的结论和展望里看看作者有没有给出未来的研究目标与方向,如果有,那省的自己想了,沿着思路干就完了。工作中,经常有组内小伙伴说,这个模型已经99.5%了呀,还用优化么?怎么优化啊?我当时就会说,当然得优化了啊。我们常常在业务中听说一个模型指标已经很高了,那肯定是现有场景,现有测试集的,但是客户需求一直在增加,场景在增加,老模型在新场景上的指标肯定会打折的,所以,持续更新测试集和训练集就很重要。在更新数据集的同时,是不是可以想着优化优化推理速度呀,模型复杂度呀什么的。毕竟工程中也不是唯精度论嘛,有时候精度没那么重要,你要跟你leader说,你把推理时间从50ms优化到5ms,大概率会比准确率从98%优化到99%更让他高兴。所以,真正工作业务中关注精度的同时,得关注具体业务,看业务需要什么?那我们就在哪个点做优化,做创新。精度啊,计算复杂度啊,部署友好啊,数据管理友好啊,训练时间友好啊,等等等等,多了去了。最后,不管学术还是工程,做个有心人,一定会发现很多创新点的。
作者:CC查理
来源链接:
https://www.zhihu.com/question/451438634/answer/1816128126自己在一直想同样的问题,也跟几个教授聊过,现在趁机整理一下。我自己能理解的最高形式的创新是创建一个新的任务。往大了说叫做开创一个新的领域,往小了说是创建一个新的设定。这种情况下不用关心之前的方法的精度如何因为设定不同了,而只需要和自己新创立的基准方法(baseline)相比较即可。大概就是这么个意思,我认为想做这种工作需要非常强的学术能力和对于某几个方向的很深刻的理解才可能成功,一般交叉学科比容容易出现。但是现在很多瞎提研究方向都挺扯淡的以次充好。我自己也是在摸索,希望未来几年能做出来一个。我认为的稍次一些但是依然非常好的创新形式是开发一个通用的方法。这种情况下不在乎也无需在一个流行的巨大的数据库上展示出很高的精度,而只是需要在一些很简单的数据库上显出其独特的优势和特性即可,精度不是重点。之前有一些很有启发性的方法就是这样提出来的,虽然很多方法后来被证明无法推广但是依然是有借鉴意义的。当然也有些很牛的通用性方法直接就在大型数据库上干翻所有人。我认为想做这种工作需要学术能力工程能力都很强才行,而且想出来的点子也很精妙。偶然见过一些被拒的文章也想走这个思路但是功力不够反而弄巧成拙。希望自己以后能做一些这种的工作。再次的话就是观察现有的公开数据库的缺点,然后自己提出并采集一个新的数据库。新的数据库一定要戳中本领域现有数据库的一个或者几个痛点,并且完美补上这个痛点,这样开放数据库之后才会有很多人去使用。想做这种工作需要对一个小领域非常了解并且有能力有钱去做数据库。我看到过一些数据库没有切中痛点即使发表也不会有很多人使用,更多的是费力做数据库之后到处被拒。我之前做过一些工作就是数据库,觉得这个方向如果摸索到方式方法并且有资金还是很容易出成果的,而且对于目前科研推动意义也很大。再再次就是提出一些模型的改进了并且一般都会在流行的大型数据库上刷一下分数,这里就有很多很多不同的方法来做,一般可以尝试用现在比较火的一些方法结构用在另外一个领域上,或者做一些各种方法的组合,或者专注于轻量化而不注重提高精度等等。只要创新性上做得够,即使精度没有提高甚至有那么一点下降也是可以接受的。这里的方法和形式就太多了,做的人最多竞争也是最激烈的。我自己的工作大都是这种类型毕竟自己还是处于初级阶段,希望自己以后能尽量减少这方面的工作。以上是我自己的总结想法,当然也会有别人不认同的地方。比如大佬说:
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报