
小白学CV:目标检测任务和模型介绍
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
目标检测介绍
目标检测是计算机视觉领域中最基础且最具挑战性的任务之一,其包含物体分类和定位。它为实例分割、图像捕获、视频跟踪等任务提供了强有力的特 征分类基础。
传统的目标检测方法包括预处理、区域提案、特征提取、特征选择、特征分类和后处理六个阶段,大多数检测模型关注于物体特征的提取和区域分类算法的选择。
Deformable Part⁃based Model(DPM)算法三次在PASCAL VOC目标检测竞赛上获得冠军,是传统目标检测方法的巅峰之作. 然而在2008年至2012年期间,目标检测模型在PASCAL VOC数据集上的检测准确率逐渐达到瓶颈. 传统方法的弊端也展现出来,主要包括:
算法在区域提案生成阶段产生大量冗余的候选框且正负样本失衡; 特征提取器如 HOG、SIFT等未能充分捕捉图像的高级语义特征和上下文内容;传统检测算法分阶段进行,整体缺乏一种全局优化策略 目标检测数据集
目前主流的通用目标检测数据集有
PASCAL VOC、ImageNet、MS COCO、Open Images和Objects365。目标检测评价指标
当前用于评估检测模型的性能指标主要有
帧率每秒(Frames Per Second,FPS)、准确率(accuracy)、精确率(precision)、召回率(recall)、平均精度(Average Precision,AP)、平均 精度均值(mean Average Precision,mAP)等。
FPS即每秒识别图像的数量,用于评估目标检测模型的检测速度;accuracy是正确预测类别的样本数占样本总数的比例;precision是预测正确的正样本数占所有预测为正样本个数的比例;recall是预测正确的正样本数占所有真实值为正样本个数的比例;PR曲线是对应precision和recall构成的曲线;AP是对不同召回率点上的精确率进行平均,在PR曲线图上表现为 PR 曲线下的面积;mAP是所有类别AP的平均;目标检测模型
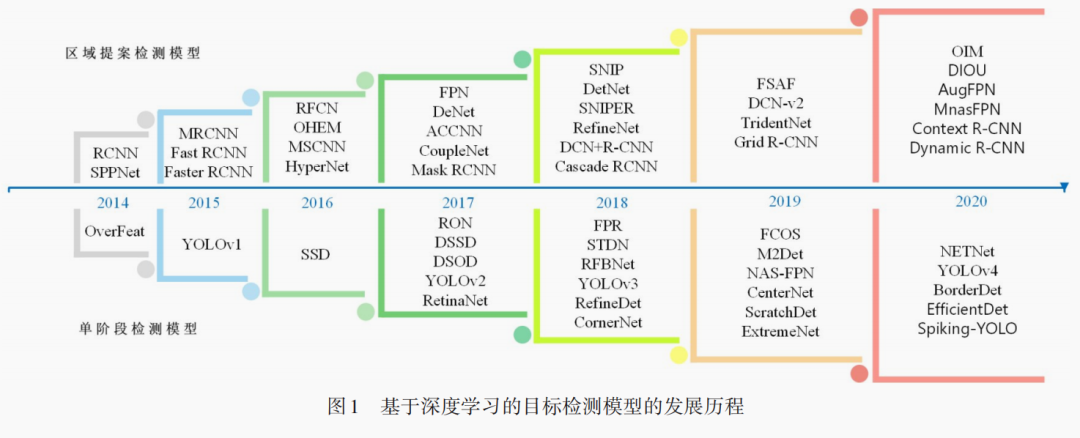
基于深度学习的目标检测方法根据有无区域提案阶段划分为双阶段模型和单阶段检测模型。
双阶段模型
区域检测模型将目标检测任务分为区域提案生成、特征提取和分类预测三个阶段。在区域提案生成阶段,检测模型利用搜索算法如选择性搜索(SelectiveSearch,SS)、EdgeBoxes、区 域 提 案 网 络(Region Proposal Network,RPN) 等在图像中搜寻可能包含物体的区域。在特征提取阶段,模型利用深度卷积网络提取区域提案中的目标特征。在分类预测阶段,模型从预定义的类别标签对区域提案进行分类和边框信息预测。
单阶段模型
单阶段检测模型联合区域提案和分类预测,输入整张图像到卷积神经网络中提取特征,最后直接输出目标类别和边框位置信息。这类代表性的方法有:
YOLO、SSD和CenterNet等。目标检测研究方向
目标检测方法可分为检测部件、数据增强、优化方法和学习策略四个方面 。其中检测部件包含基准模型和基准网络;数据增强包含几何变换、光学变换等;优化方法包含特征图、上下文模型、边框优化、区域提案方法、类别不平衡和训练策略六个方面,学习策略涵盖监督学习、弱监督学习和无监督学习。
特征图融合
特征图是图像经过卷积池化层输出的结果,大多数基准检测模型只在顶层特征图做预测,这在很大程度上限制了模型的性能。
多层特征图单层预测模型 分层预测模型 结合多层特征图多层预测模型 上下文信息融合
在物体遮挡、背景信息杂乱或图像质量不佳的情况下,根据图像的上下文信息能更有效更精确地检测。
全局上下文信息 局部上下文信息 边框优化
当前检测模型在小目标检测表现不佳的主要原因是定位错误偏多,包含定位偏差大和重复预测。
优化边框定位 NMS优化 类别不均衡优化
类别不平衡的主要矛盾是负样本数远多于正样本数,导致训练的深度模型效率低。
Online Hard Example Mining,OHEM Focal Loss损失函数

本文仅做学术分享,如有侵权,请联系删文。