
ollama:极简本地化部署LLM
主要是更方便简捷的方式运行大模型,无需GPU资源。mac、linux和win的版本都有。我是基于win去玩,在官网下载exe安装包。安装好后,默认就给你启起来,command也很简约
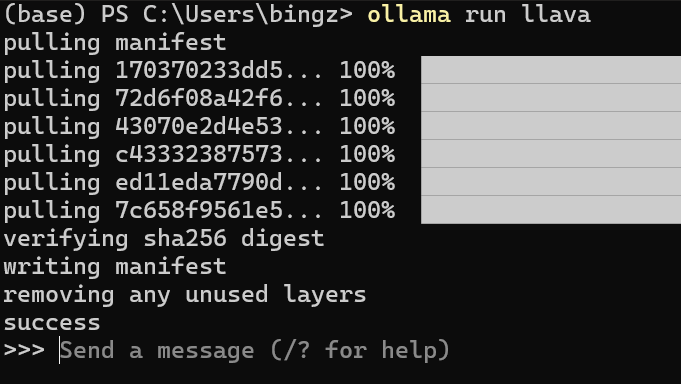
 直接run的时候,如果没有本地模型,就去pull一个,比如pull一个llava
直接run的时候,如果没有本地模型,就去pull一个,比如pull一个llava
ollama run llava
 可是没有界面,还是少点意思,不打紧,我们用open-webui。通过docker安装open-webui
可是没有界面,还是少点意思,不打紧,我们用open-webui。通过docker安装open-webui
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
 起容器后,直接打开网址 http://localhost:3000/
起容器后,直接打开网址 http://localhost:3000/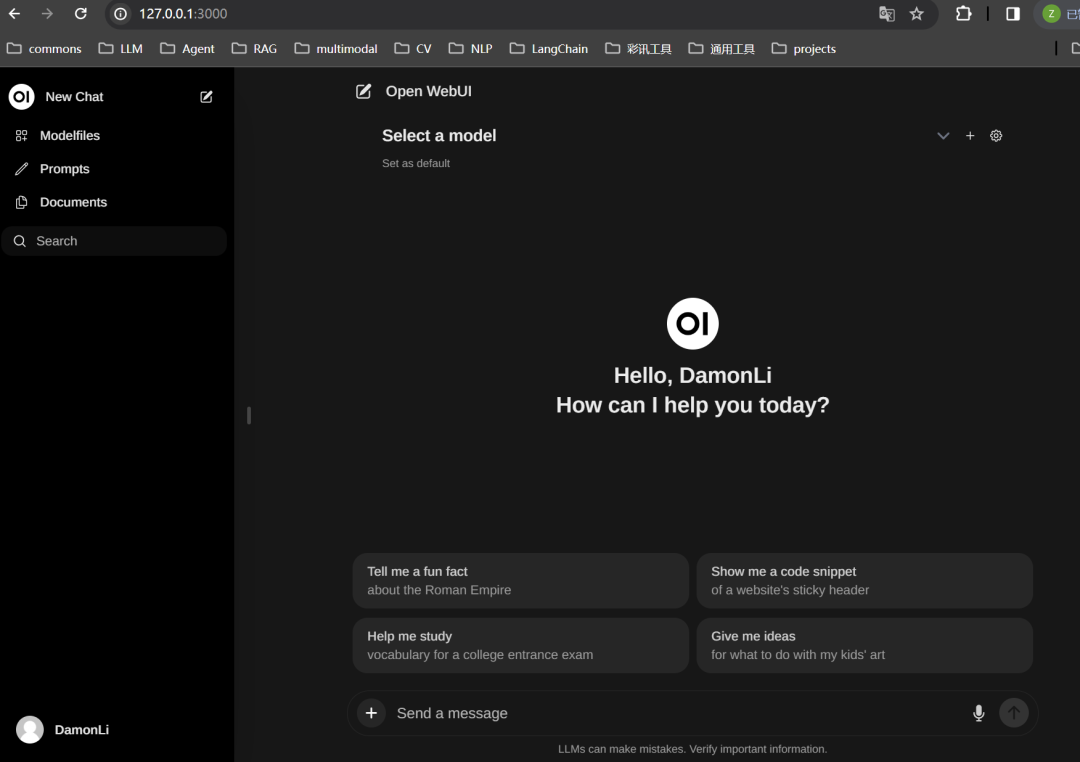 默认下载的模型都是int4量化后的模型,比如qwen1.5-1.8B-int4才1G多,qwen1.5-7B-int4才4.2G,响应速度很快。
默认下载的模型都是int4量化后的模型,比如qwen1.5-1.8B-int4才1G多,qwen1.5-7B-int4才4.2G,响应速度很快。
-
支持任意对话节点切换模型:比如和1.8B聊着不爽了,就切换到7B去聊
-
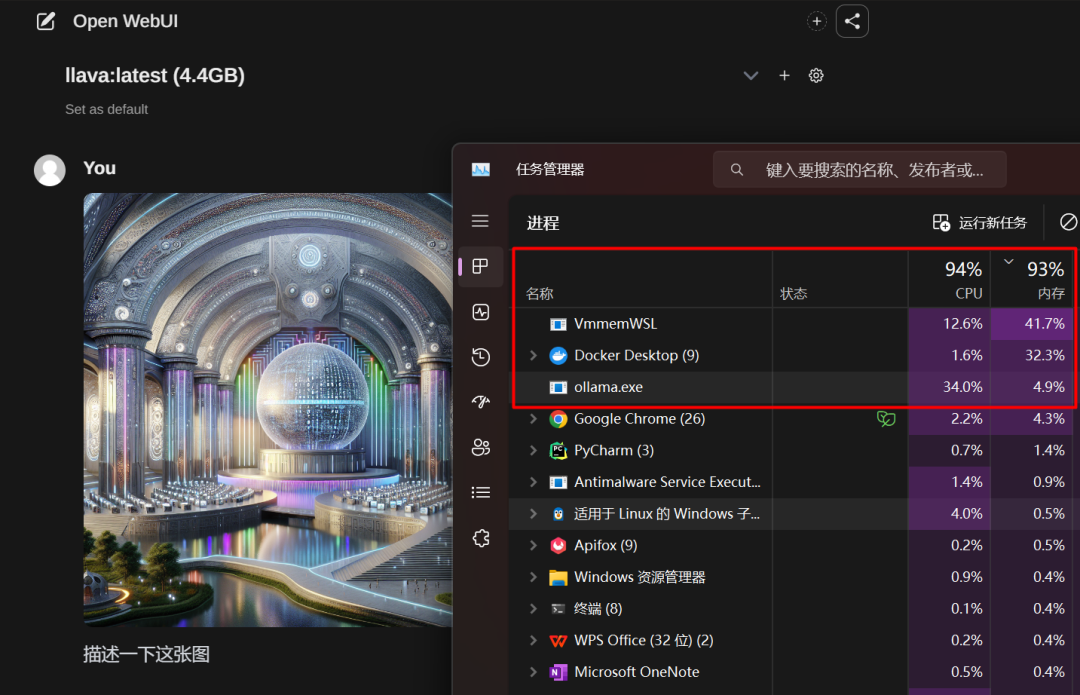
支持多模态对话,比如llava,就是没有gpu资源,推理相对慢点
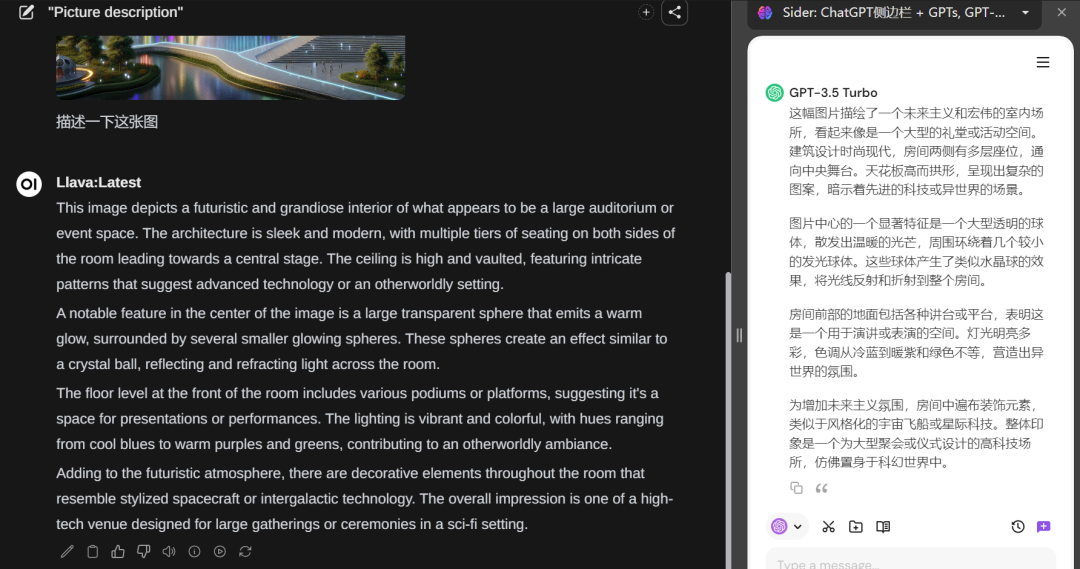
-
构建提示词模板,当然下面的提示有点粗糙 : )
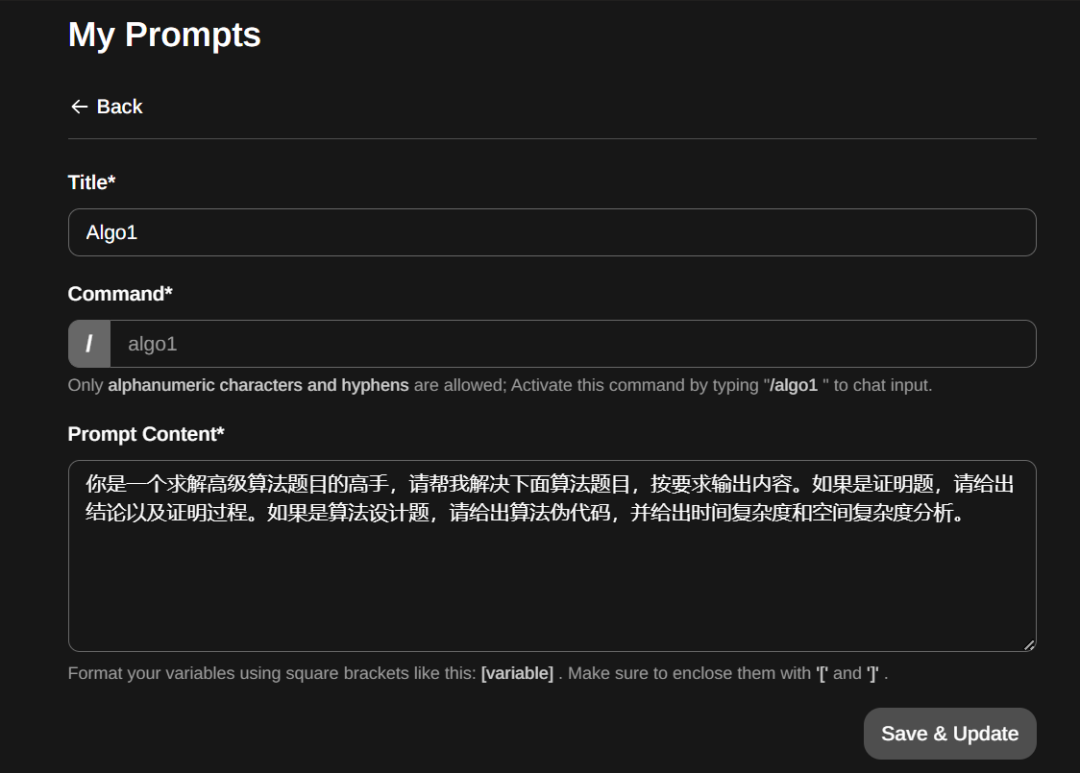 构建好后,通过“/”符号来唤醒
构建好后,通过“/”符号来唤醒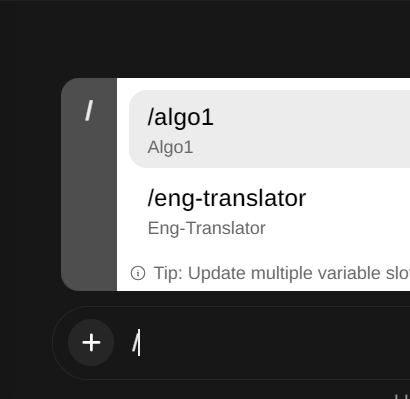 唤醒后会直接把提示词模版插入文本框
唤醒后会直接把提示词模版插入文本框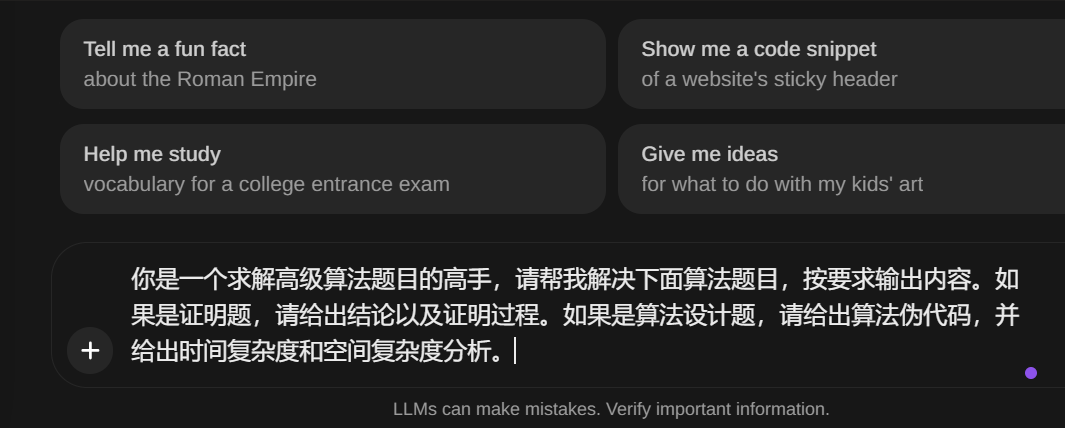 再在模板相应位置插入关键信息进行生成
再在模板相应位置插入关键信息进行生成
-
基于文档问答:先是插入文档和文档解析,默认用文本分块大小是1500,分块之间的overlap是100字符
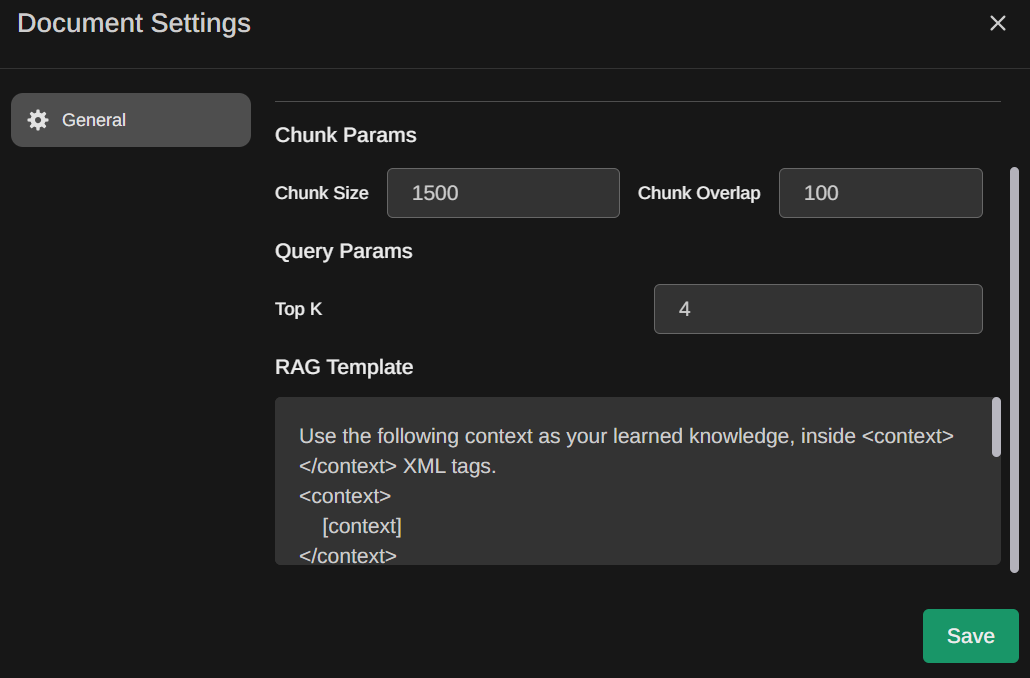 解析好的文档会显示出来
解析好的文档会显示出来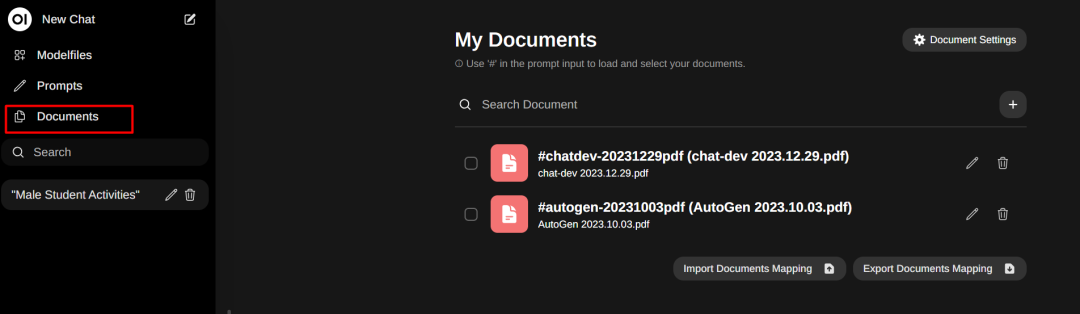 然后在对话框中通过符号‘#’来引用
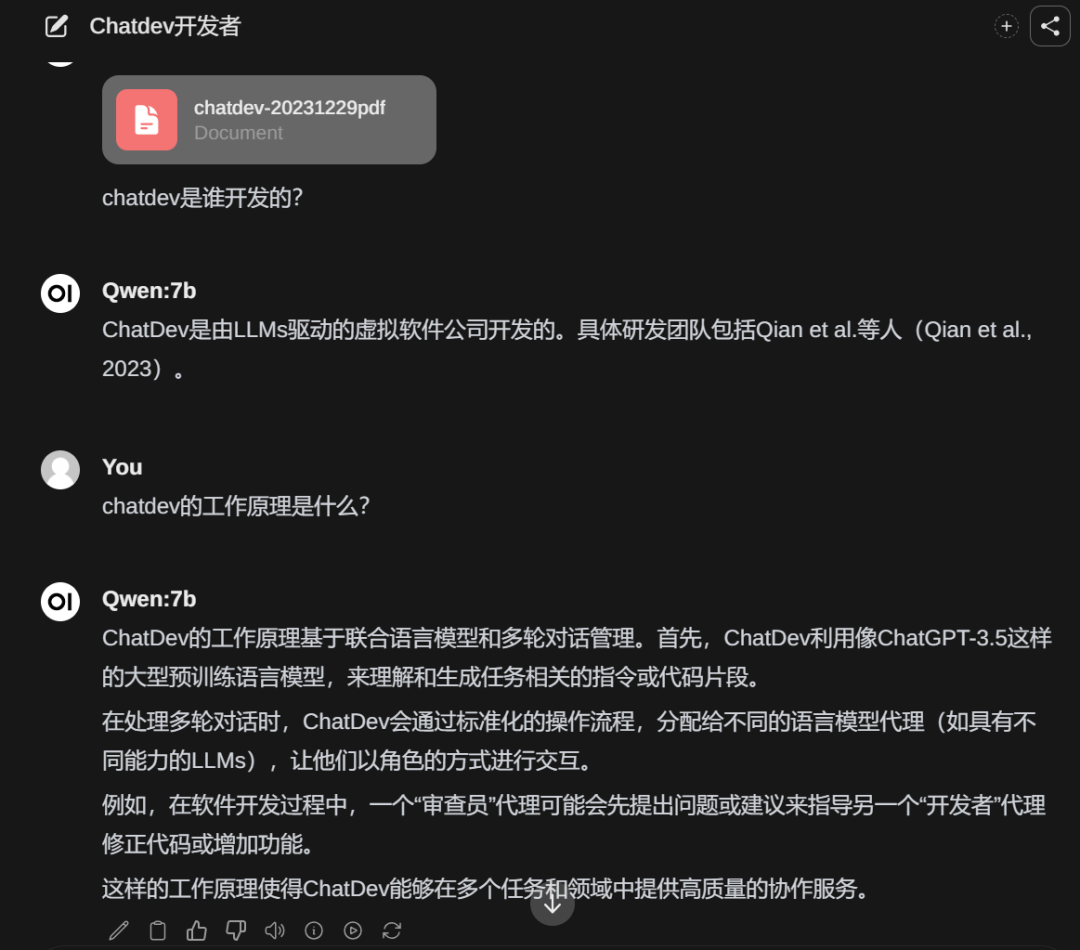
然后在对话框中通过符号‘#’来引用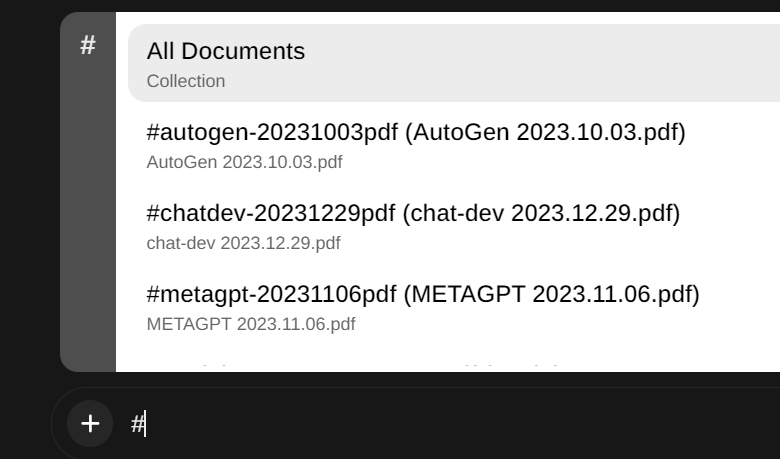 为了测试他具不具备这个能力,用qwen-14b做了验证,下面是没有加载文档的回复
为了测试他具不具备这个能力,用qwen-14b做了验证,下面是没有加载文档的回复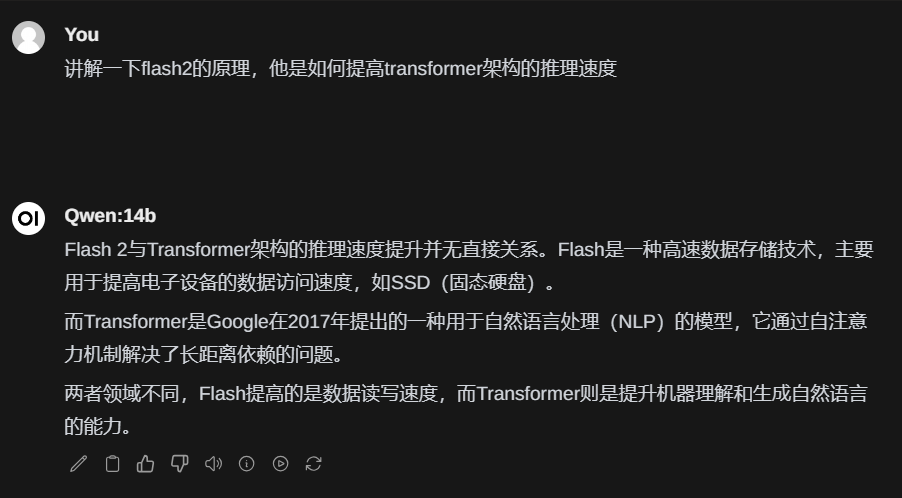 下面是加载了文档的回复
下面是加载了文档的回复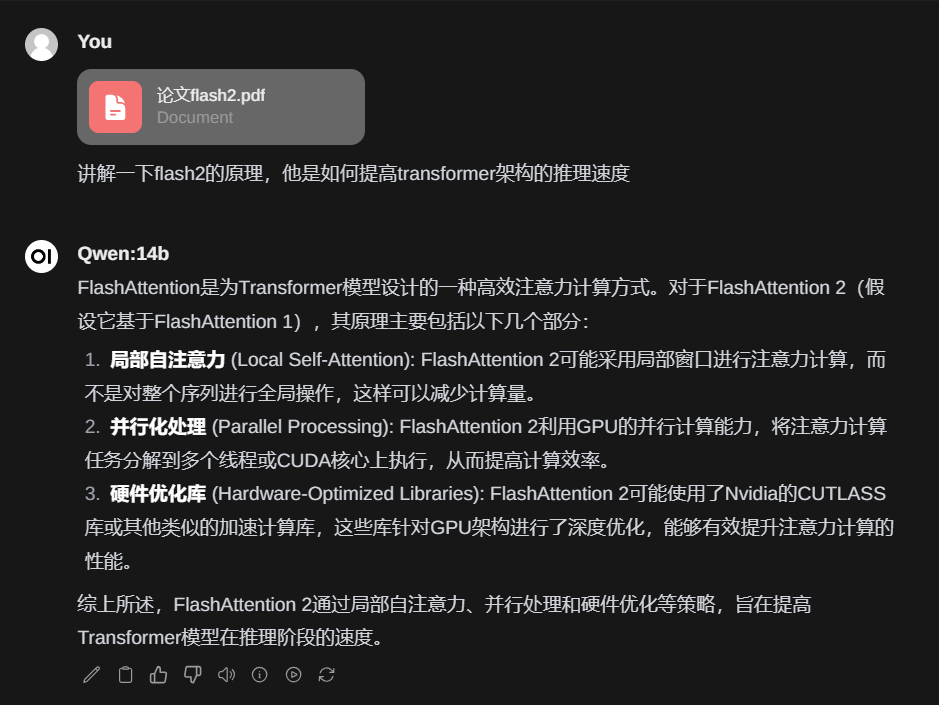
-
支持GGUF、PyTorch和Safetensors模型的导入:参考这里
-
通过ngrok反向代理服务,实现内网穿透:在这里下载ngrok安装exe文件,然后再在官网上注册一下获得auth的token,启动的时候指定3000端口即可。
ngrok http http://localhost:3000
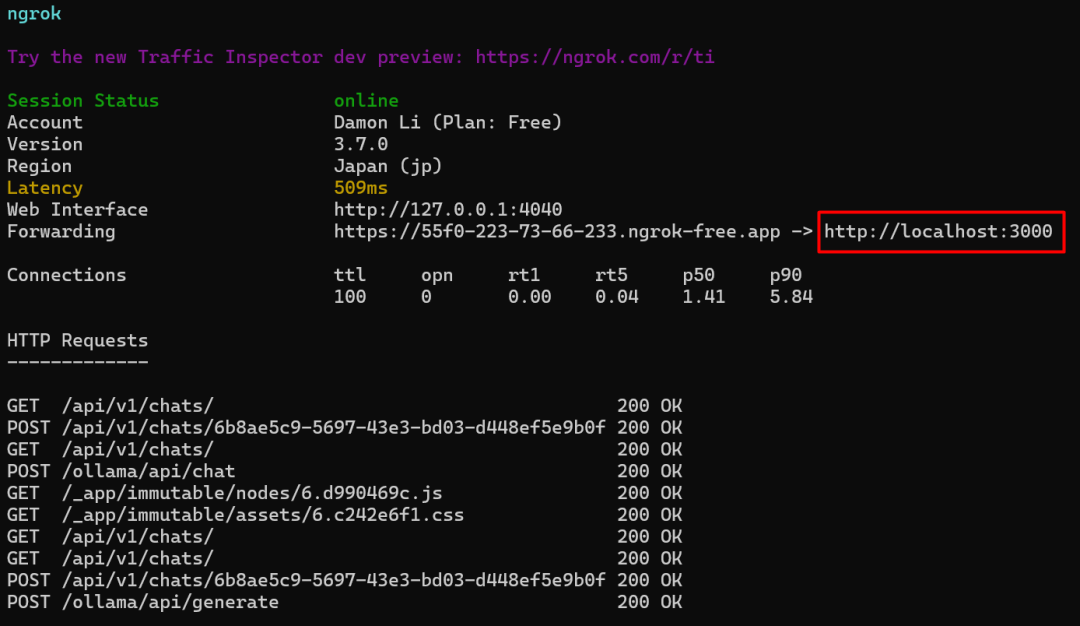 然后复制 https://6123-223-73-66-233.ngrok-free.app 给小伙伴们体验吧
然后复制 https://6123-223-73-66-233.ngrok-free.app 给小伙伴们体验吧 目前ollama也支持gemma和mistral。现在没有网络,没有gpu显卡,也能跑起llm推理生成,何乐而不为。
目前ollama也支持gemma和mistral。现在没有网络,没有gpu显卡,也能跑起llm推理生成,何乐而不为。