
使用OneFlow完成基于U型网络的ISBI细胞分割任务
文章目录
1. Introduction
2. 网路架构
3. 数据和程序准备
4. 使用步骤
5. 单机单卡训练方式
6. 单机多卡训练方式(DDP)
7. 可视化实验结果
8. Conclusion and discussion
1. Introduction
本文基于OneFlow和U-Net实现ISBI挑战赛的细胞分割,代码包括单机单卡和单机多卡两种训练方式,OneFlow 提供了 oneflow.nn.parallel.DistributedDataParallel 模块及 launcher,可以几乎不用对单机单卡脚本做修改,就能地进行数据并行训练。除此之外,因为我目前在OneFlow做一名算法实习生,本文更多以一个初次接触OneFlow框架的用户角度进行分析,包括API、分布式训练能力、高性能和我的一些实习感受(不重要👀)。
ISBI细胞分割任务:给一张细胞结构图,对边缘轮廓进行二分类,如下动图所示。
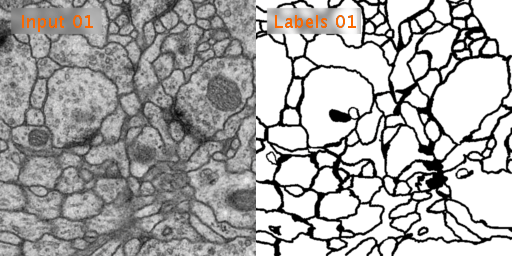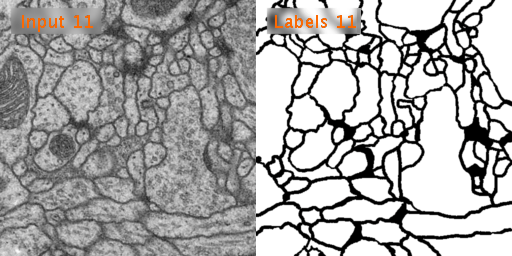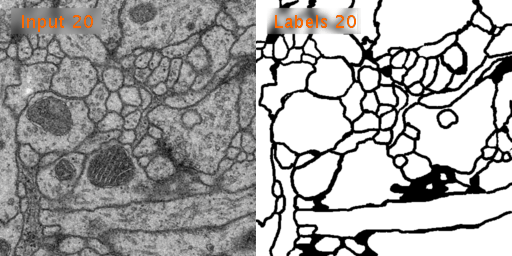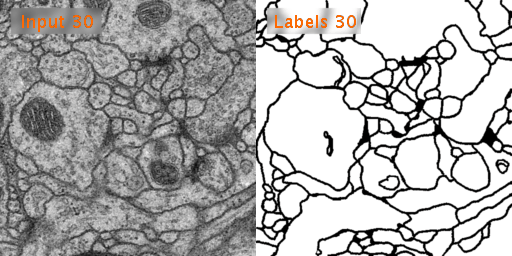
训练数据有30张,分辨率为512x512,这些图片是果蝇的电镜细胞图。
2. 网路架构
U-Net网络架构如下图所示。它由一个收缩路径和一个扩展路径组成。收缩路径遵循卷积网络的典型架构。它包括重复使用两个 3x3 卷积,每个卷积后跟一个线性修正单元(ReLU)和一个2x2最大池化操作,步长为2的下采样。在每个下采样步骤中,我们将特征通道的数量加倍。扩展路径中的每一步都包括特征映射的上采样,然后进行 2x2 向上卷积,将特征通道数量减半,与来自收缩路径的相应裁剪特征映射串联。然后是两个3x3卷积,每个卷积后面接ReLU。由于每一次卷积都会丢失边界像素,因此裁剪是必要的。在最后一层,使用1x1卷积将每个分量特征向量映射到所需数量的类别(2类)上。网络总共有23个卷积层。
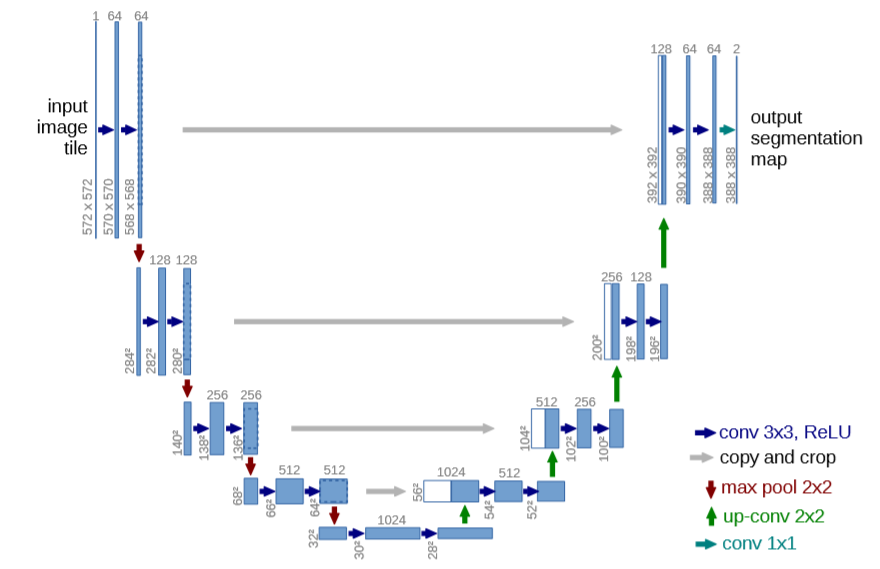
根据上面的网络结构,使用OneFlow实现U型网络结构代码如下:
"""
Creates a U-Net Model as defined in:
U-Net: Convolutional Networks for Biomedical Image Segmentation
https://arxiv.org/abs/1505.04597
Modified from https://github.com/milesial/Pytorch-UNet
"""
import oneflow as flow
import oneflow.nn as nn
import oneflow.nn.functional as F
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2), DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
else:
self.up = nn.ConvTranspose2d(
in_channels, out_channels, kernel_size=2, stride=2
)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, (diffX // 2, diffX - diffX // 2, diffY // 2, diffY - diffY // 2))
x = flow.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
self.down4 = Down(512, 1024)
self.up1 = Up(1024, 512, bilinear)
self.up2 = Up(512, 256, bilinear)
self.up3 = Up(256, 128, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
3. 数据和程序准备
原始数据:首先准备数据,参考数据来自于 ISBI 挑战的数据集。数据可以在本仓库(https://github.com/Oneflow-Inc/models/tree/main/Vision/segmentation/U-Net)下载到,含30张训练图、30张对应的标签。30张测试图片。
增强后的数据 :谷歌云盘(https://drive.google.com/drive/folders/0BzWLLyI3R0pLclMzMzRxUm1qZmc)
以上数据二选一。
代码链接: https://github.com/Oneflow-Inc/models/tree/main/Vision/segmentation/U-Net
该程序目录如下:
dataloader.py//加载数据
plot.py//绘制loss曲线
TrainUnetDataSet.py//训练文件
unet.py//网路结构
predict_unet_test.py//测试文件
tran.sh//训练脚本
test.sh//测试脚本
4. 使用步骤
训练:
bash train.sh
测试:
bash test.sh
5. 单机单卡训练方式
在TrainUnetDataSet.py中,为了与单机多卡训练方式对比,这里给出训练U-Net的完整脚本,如下:
def Train_Unet(net, device, data_path, batch_size=3, epochs=40, lr=0.0001):
train_dataset = SelfDataSet(data_path)
train_loader = utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True
)
opt = optim.Adam((net.parameters()))
loss_fun = nn.BCEWithLogitsLoss()
bes_los = float("inf")
for epoch in range(epochs):
net.train()
running_loss = 0.0
i = 0
begin = time.perf_counter()
for image, label in train_loader:
opt.zero_grad()
image = image.to(device=device, dtype=flow.float32)
label = label.to(device=device, dtype=flow.float32)
pred = net(image)
loss = loss_fun(pred, label)
loss.backward()
i = i + 1
running_loss = running_loss + loss.item()
opt.step()
end = time.perf_counter()
loss_avg_epoch = running_loss / i
Unet_train_txt.write(str(format(loss_avg_epoch, ".4f")) + "\n")
print("epoch: %d avg loss: %f time:%d s" % (epoch, loss_avg_epoch, end - begin))
if loss_avg_epoch < bes_los:
bes_los = loss_avg_epoch
state = {"net": net.state_dict(), "opt": opt.state_dict(), "epoch": epoch}
flow.save(state, "./checkpoints")
def main(args):
DEVICE = "cuda" if flow.cuda.is_available() else "cpu"
print("Using {} device".format(DEVICE))
net = UNet(1, 1, bilinear=False)
# print(net)
net.to(device=DEVICE)
data_path = args.data_path
Train_Unet(net, DEVICE, data_path, epochs=args.epochs, batch_size=args.batch_size)
Unet_train_txt.close()
6. 单机多卡训练方式(DDP)
OneFlow 提供了 oneflow.nn.parallel.DistributedDataParallel 模块及 launcher,可以几乎不用对单机单卡脚本做修改,就能地进行DDP训练。
根据该特性,数据并行的训练代码与单机单卡脚本的不同只有2个,将第5节的训练脚本做如下修改:
使用 DistributedDataParallel处理一下 module 对象
m=net.to(device=DEVICE)
net = ddp(m)
使用 DistributedSampler在每个进程中实例化Dataloader,每个Dataloader实例加载完整数据的一部分,自动完成数据的分发。
is_distributed=True
sampler = flow.utils.data.distributed.DistributedSampler(train_dataset) if is_distributed else None
train_loader = utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=(sampler is None), sampler=sampler
)
在分布式模式下,在创建DataLoader迭代器之前,在每个epoch开始时调用set_epoch()方法,这对于在多个epoch中正确地进行shuffle是必要的。否则,将总是使用相同的顺序。
for epoch in range(epochs):
if is_distributed:
sampler.set_epoch(epoch)
···
这样就完成了分布式训练脚本的编写,然后使用 launcher 启动脚本,把剩下的一切都交给 OneFlow,让分布式训练U-Net,像单机单卡训练U-Net一样简单。
python3 -m oneflow.distributed.launch --nproc_per_node 8 ./ddp_train.py
--nproc_per_node选项表示调用的GPU结点数量。
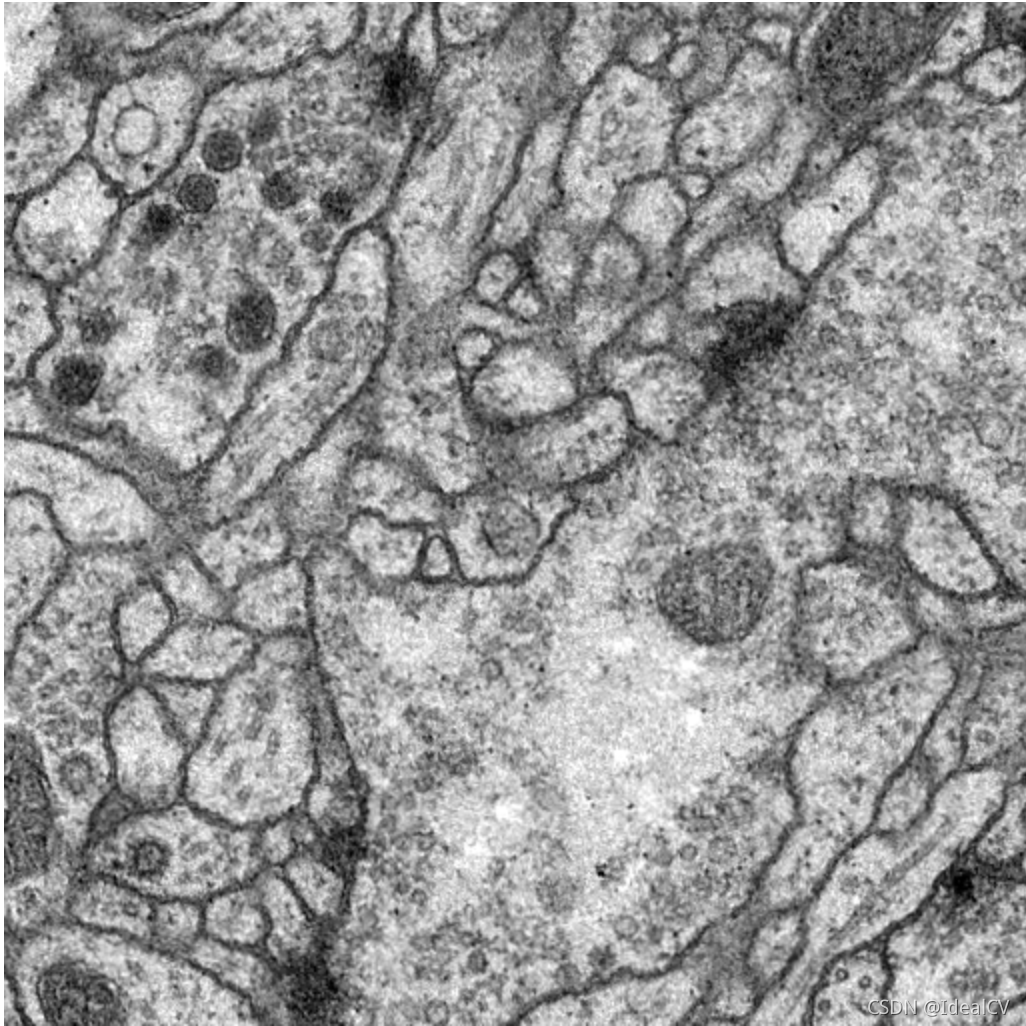
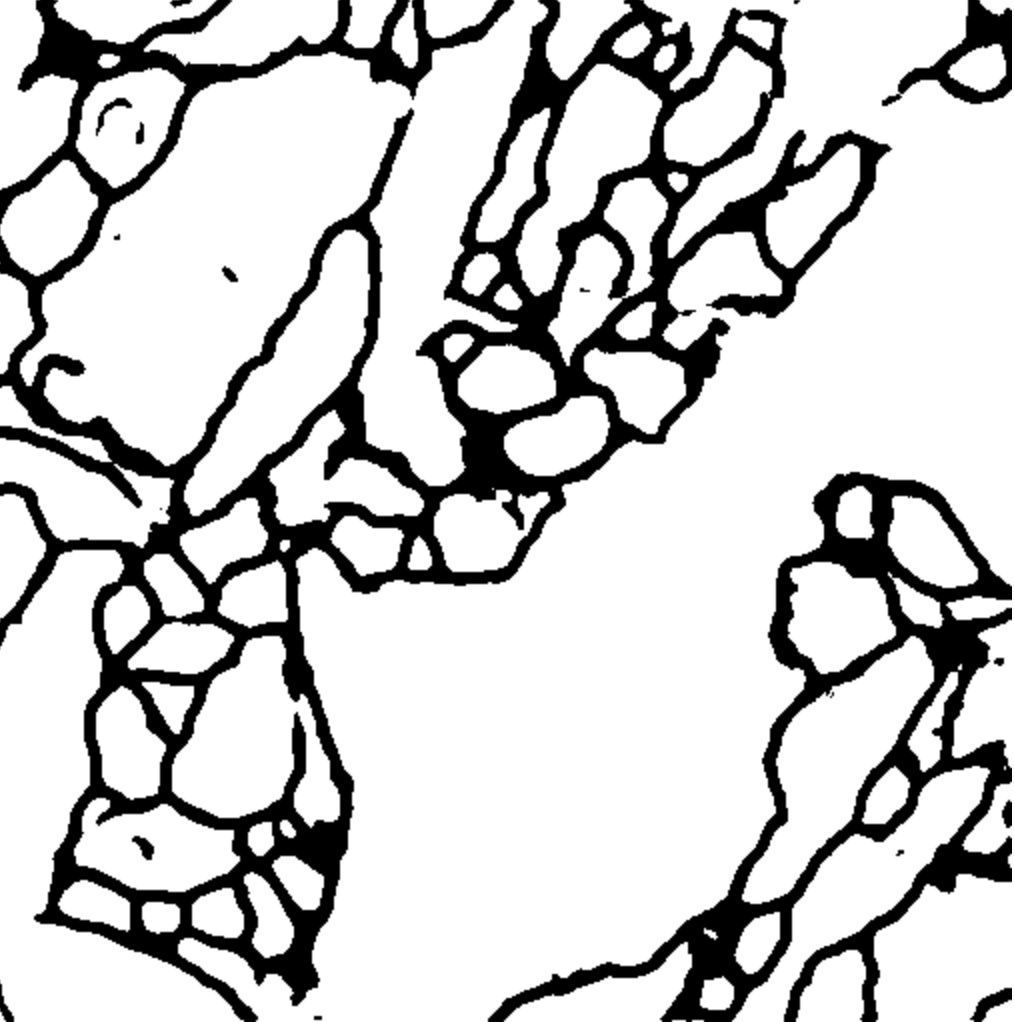
7. 可视化实验结果
该实验只训练了40个Epoch,提升Epoch数量可显著提升模型精度。
原图:
U-Net预测图:
8. Conclusion and discussion
本文更多以一个初次接触OneFlow框架的用户角度进行分析,在使用OneFlow训练U-Net网络的过程中,我真正感受到OneFlow对新用户的友好。之前的学习中,我主要使用Keras和TensorFlow,但使用OneFlow却可以很快上手。因为OneFlow的Eager模式,与 PyTorch 对齐,让熟悉PyTorch的用户可以零成本直接上手。至于Graph模式,目前我还没有进行实践,但Graph也是基于面向对象的编程风格,熟悉动态图开发的用户,只需要改很少量的代码,就可以使用高效率的静态图。
首先,OneFlow提供的API基本可以满足我的所有需求,在下一版本中也将提供更加详细的API帮助文档和更丰富、完善的算子集,对比TensorFlow复杂和大型的文档,我认为Oneflow更具有易用性。
此外,OneFlow在处理大规模模型上的性能是最重要的。计算机视觉领域的模型规模越来越大,多节点集群进行分布式训练,以提升算力的方法被OneFlow更好的解决了。而且,分布式训练的简单操作也更能满足我的需求。
最后,我想说一下我在OneFlow短暂的实习体验💁🏻,11月份15号入职,到现在为止已经过去三周了。在这三周里,我除了感受到国产深度学习框架正在异军突起之外,在BBuf晓雨哥的言传身教下,也感受到OneFlow团队的高效开发方式。三周的时间过的很快,对比我自己没有pipline式的学习,在OneFlow学习和工作确实对我的个人提升很有benefits。这里抓重点了👀,实习的我每天过的很愉快哦😊😊😊😊!