
如何评价OpenAI最新的工作CLIP:连接文本和图像,zero shot效果堪比ResNet50?
CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs. It can be instructed in natural language to predict the most relevant text snippet, given an image, without directly optimizing for the task, similarly to the zero-shot capabilities of GPT-2 and 3. We found CLIP matches the performance of the original ResNet50 on ImageNet “zero-shot” without using any of the original 1.28M labeled examples, overcoming several major challenges in computer vision.
谢凌曦(清华大学 工学博士)回答:
先说看法:多模态是趋势没错,可CLIP只是迈出了非常简单的第一步。
只要简单地扫过文章,就会发现方法简单地令人发指——熟悉深度学习编程的人,一个上午大概就能复现出所有代码。而整篇文章最大的复现难点,显然是OpenAI自行收集的400M文本图像配对的数据集。
如果要对比这个方法和传统图像分类方法,那么优缺点都是比较明显的:
相比于传统图像分类方法的优势。这是显而易见的:每张图像的标签不再是一个名词,而是一个句子,因此以往被强行分成同类的图像,就有了“无限细粒度”的标签。例如ImageNet给图片打的标签是“金毛寻回犬”,而这种配对的例子,就可以学习“金毛寻回犬”身处不同环境、在做不同事情的细微差别。
相比于传统图像分类方法的劣势。主要还是文本和图像的配对关联性不够强。这是为什么作者反复强调要收集巨大的数据集,因为他们必须通过大数据的方式来压制噪声。从这个观点出发,我们可以看出些许未来的趋势(见下面第2和第3点)。
最后再说一些扩展的观点:
千万不要被它zero-shot的能力吓到,这不是真正的zero-shot!在400M个文本图像配对的训练中,模型肯定看到了大量打着相关文本标签的图像,而且图像的domain比ImageNet要广得多——这也是为什么方法能够在一些高级场景(如clipart)轻松超越ImageNet预训练模型。但是要说这种方法碾压了有监督方法,就有点震惊体哗众取宠的意味了。
另一个耐人寻味的地方,是方法同时训练了图像和文本特征(感谢评论区@llll的提醒,一开始我看成只训练图像了)。我直觉地认为文本预训练特征比视觉预训练特征更可靠,但是作者却放弃了OpenAI祖传的超大的文本预训练模型,令人略感意外。尤其是,NLP的预训练模型体量远超视觉预训练模型,所以固定文本模型,也许是更实用的方法?
最让我感兴趣的问题,是图像和文本之间的交互方式。直接用文本的encoding结果做为图像的监督信号,显然噪声太大了;能否借鉴captioning等方向的做法,允许图像和文本在encoding过程中多次交互,从而提升效果?当然,这里还是涉及到语言模型太大,无法高效训练。不过,OpenAI也可以选择暴力出奇迹,直接从头训练大规模的跨模态预训练模型。只是这样做的话,400M的数据集可能就太小了。
再往深了说,NLP的预训练之所以能做得好,关键是pretext任务比较好。相比起来,CV还在苦苦寻找合适的pretext任务。当前我对跨模态的最大预期,就是能够在NLP的辅助下,定义CV的pretext任务。CLIP迈出了第一步,前面的路还长得很。
总之,CLIP这个工作,技术突破不大,效果还算惊艳。作为占坑之作,将来应该会成为跨模态的一个重要baseline。

mileistone(上海交大 计算机视觉)回答:
1、动机
a、当前的CV数据集标注劳动密集,成本高昂;
b、当前的模型只能胜任一个任务,迁移到新任务上非常困难;
c、当前模型泛化能力较差。
2、CLIP解决方案概述
a、互联网上较容易搜集到大量成对的文本和图像,对于任何一个图像文本对而言,文本其实可以认为是图像的标签。也就是说,互联网上天然就存在已经标注好的CV数据集,这解决了“动机”中的问题a。
b、而互联网上存在的这些已经标注好的CV数据集数量不仅大而且差异也大,当我们在这样的数据集上训练一个表达能力足够强的模型时,这个模型就能具备较强的泛化能力,较容易迁移到其他新任务上,这缓解了“动机”中的问题b和问题c。
上述两段话是CLIP解决方案的粗线条概括。
3、CLIP细节
“CLIP的解决方案概述”中的a比较容易解决:确定一系列query,然后通过搜索引擎(通用搜索引擎如Google等,或者垂直领域搜索引擎Twitter等)搜索图片。
最后通过50万条query,搜索得到4亿个图像文本对,这样一个大规模的数据量,对应了“CLIP的解决方案概述”中的b。
既然我们有了图像文本对,那么最直接训练方法就是metric learning,CLIP的确也是这么干的。
4、一些思考
NLP supervision如何理解。
NLP supervision其实可以理解为多维度的标签,常见的分类任务只有一维,比如ImageNet-1K是一维,这一维的shape为1000,而NLP supervision可以认为是多维,比如三维,shape为(A, B, C),每一维描述一个concept。
经典图像分类的一维标签只包含一种数据集创建者自己设定的较粗的单种concept,比如ImageNet-1K里的“图像包含egyptian cat、Persian cat、tiger cat、alley cat等1000种类别中的哪一种”。
而这个单种concept可以由多种concept组合而来,一方面可以减小歧义,一方面方便迁移,比如颜色、大小等等,NLP supervision就可以达到类似的一种效果,比如“a photo of guacamole, a type of food”这一句话告诉我们这是一张图片,图片里包含的是食物,这个食物是酸橘汁腌鱼。
zero shot如何理解
我们通过CLIP训练出来一个模型之后,满足以下条件的新任务都可以直接zero shot进行识别:
1、我们能够用文字描述清楚这个新分类任务中每个类别;
2、这个描述对应的概念在CLIP的训练集中出现过。这在经典一维标签的图像分类中是不可实现的。
CLIP这种方法把分类转换为了跨模态检索,模型足够强的情况下,检索会比分类扩展性强。比如人脸识别,如果我们把人脸识别建模为分类任务,当gallery里新增加人脸后,类别数就变大了,我们就需要重新训练模型、更新类别数;如果我们将人脸识别建模为检索,当gallery里新增加人脸后,我们用已有的模型提取这个人脸的特征,后续流程不用变,也不用重新训练模型。
从检索这个角度来看,CLIP的zero shot其实就是把分类问题转化为了检索问题。
总结来看,CLIP能够zero shot识别,而且效果不错的原因在于:
1、训练集够大,zero shot任务的图像分布在训练集中有类似的,zero shot任务的concept在训练集中有相近的;
2、将分类问题转换为检索问题。
concept的唬人之处
CLIP这篇文章里提到通过NLP supervision能够让模型学到concept的概念,concept这个比较唬人,实际情况可能比我们想象的要差一些。
OpenAI没放数据集,我们只知道有50万query,但是这些query是怎么样的我们不得而知,比如是很简单的描述还是较复杂的描述。如果只是简单的描述,比如“black cat”、“lecture room”之类,那NLP encoder学到的所谓concept可能比较低级,稍微比bag of words好一点,毕竟50万的量不是很大,query又简单。
我猜想情况可能近乎于如此,论据如下:
1、原文里作者说到“we found CLIP's performance to be less sensitive to the capacity of the text encoder”;
2、zero shot时,prompt engineering和prompt ensemble影响较大,原文里说到“When considered together, prompt engineering and ensembling improve ImageNet accuracy by almost 5%”。
数据问题
一个强大的方法不仅需要依赖强大的模型结构,还仰仗大规模的训练集。模型结构决定下限,数据集决定上限。CLIP这种方法的上限如何,query的数量和质量至关重要。
如果图像文本对仅仅通过搜索的方式在互联网上获取,感觉文本不太可能复杂,这个会限制CLIP的上限。如果能找到一种获取大量图像文本对,而且文本还比较复杂,那么CLIP这种方法前景会非常不错。
算法科学家/工程师的阶层固化
越来越多的前沿方向,要么需要大规模数据,要么需要大规模的GPU集群,无论哪一种,都是普通公司或者实验室承受不了的。
我想如果后续一直这么发展下去,算法科学家/工程师是不是就会形成阶层固化,资本充沛公司/实验室的科学家/工程师的经验、成果、知识、技能会越来越强,反之,越来越弱。就像现在中国和美国一样,贫富差距越来越大,单单靠天赋、努力想跨越阶层越来越难。
原文见《对Connecting Text and Images的理解》。
小小将(华中科大 工学硕士)回答:
先占个坑,我觉得这个工作非常nice,就像OpenAI所说虽然深度学习在CV领域很成功,但是:
typical vision datasets are labor intensive and costly to create while teaching only a narrow set of visual concepts(标注数据我太难了)
standard vision models are good at one task and one task only, and require significant effort to adapt to a new task; (模型在单一任务上优秀,但难迁移到新任务)
and models that perform well on benchmarks have disappointingly poor performance on stress tests, casting doubt on the entire deep learning approach to computer vision.(真o(╥﹏╥)o了,泛化性和鲁棒性堪忧)
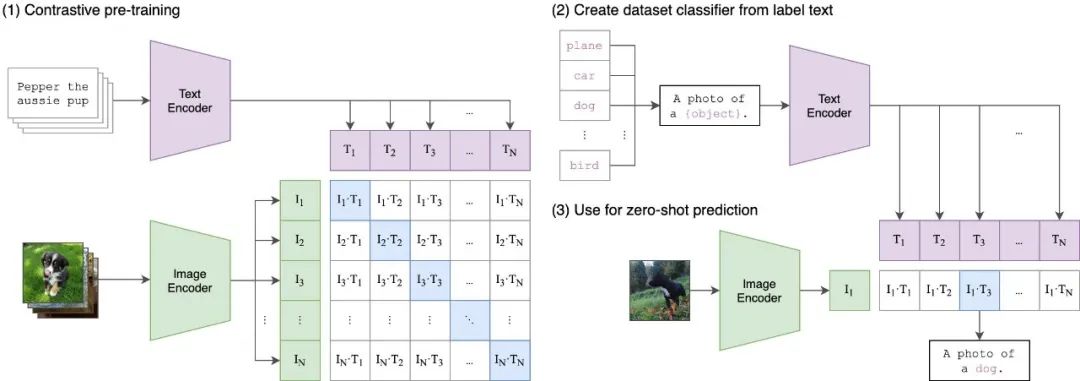
OpenAI的这项新工作CLIP可以解决上述问题,思路看起来很简单,看下图就知道了,简单来说CLIP是将Text Decoder从文本中提取的语义特征和Image Decoder从图像中提取的语义特征进行匹配训练:
CLIP pre-trainsan image encoder and a text encoder to predict which images were paired with which texts in our dataset. We then use this behavior to turn CLIP into a zero-shot classifier. We convert all of a dataset’s classes into captions such as “a photo of adog” and predict the class of the caption CLIP estimates best pairs with a given image.(这个zero-shot真是鬼才)
训练的伪代码也很simple(https://github.com/openai/CLIP):
# image_encoder - ResNet or Vision Transformer# text_encoder - CBOW or Text Transformer# I[n, h, w, c] - minibatch of aligned images# T[n, l] - minibatch of aligned texts# W_i[d_i, d_e] - learned proj of image to embed# W_t[d_t, d_e] - learned proj of text to embed# t - learned temperature parameter# extract feature representations of each modalityI_f = image_encoder(I) #[n, d_i]T_f = text_encoder(T) #[n, d_t]# joint multimodal embedding [n, d_e]I_e = l2_normalize(np.dot(I_f, W_i), axis=1)T_e = l2_normalize(np.dot(T_f, W_t), axis=1)# scaled pairwise cosine similarities [n, n]logits = np.dot(I_e, T_e.T) * np.exp(t)# symmetric loss functionlabels = np.arange(n)loss_i = cross_entropy_loss(logits, labels, axis=0)loss_t = cross_entropy_loss(logits, labels, axis=1)loss = (loss_i + loss_t)/2
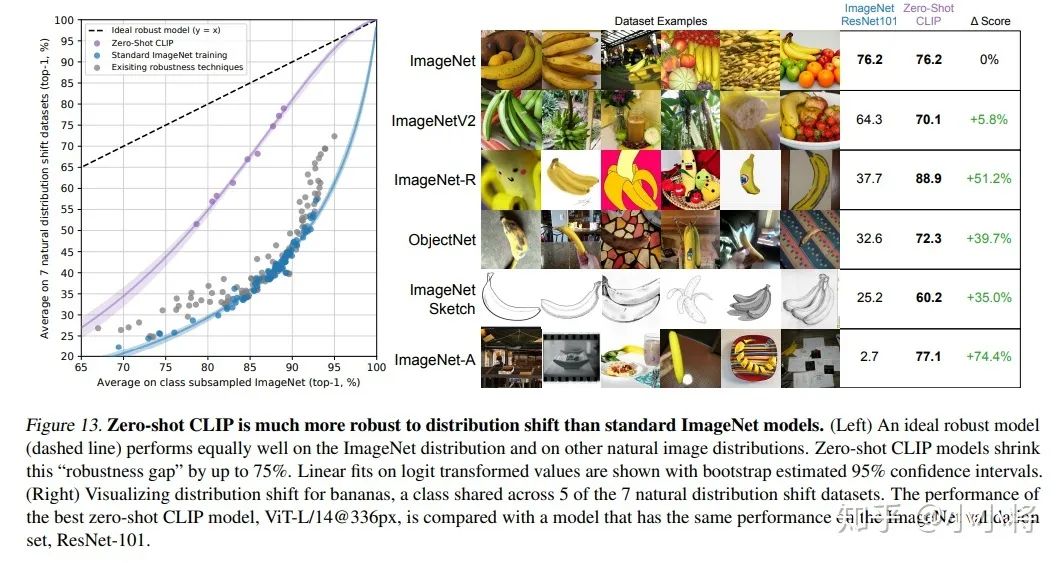
效果也是杠杠的,首先CLIP的zero-shot迁移能力非常强。如在ImageNet问题上,CLIP无需ImageNet标注数据训练,通过zero-shot分类效果就可以达到ResNet监督训练结果,并且泛化性和鲁棒性更好:
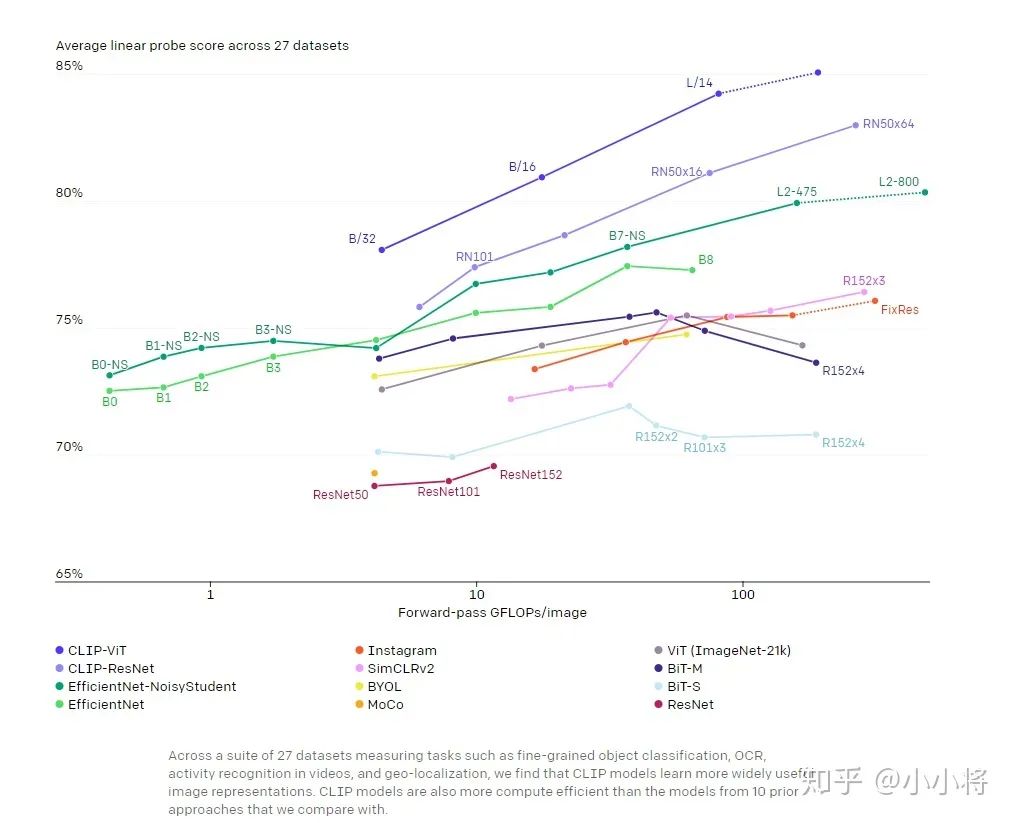
如果采用standard representation learning evaluation(后面加一个linear classifier,而不是finetuning,前者更能看出提取特征的质量),CLIP在27个数据集上的效果也要超过谷歌的Noisy Student EfficientNet-L2:
本文转载自知乎,著作权归属原作者,侵删
——The End——

推荐阅读
