
广告行业中那些趣事系列8:详解BERT中分类器源码

摘要:BERT是近几年NLP领域中具有里程碑意义的存在。因为效果好和应用范围广所以被广泛应用于科学研究和工程项目中。广告系列中前几篇文章有从理论的方面讲过BERT的原理,也有从实战的方面讲过使用BERT构建分类模型。本篇从源码的角度从整体到局部分析BERT模型中分类器部分的源码。
目录
01 整体模块划分
02 数据处理模块
03 特征处理模块
04 模型构建模块
05 模型运行模块
06 其他模块
总结

整体模块划分
对于机器学习工程师来说,会调包跑程序应该是万里长征的第一步。这一步主要是帮助我们迅速将模型应用到实际业务中,并且提升自信心,但这还远远不够。要想根据不同的业务场景更好的使用模型,我们需要深层次的理解模型,读点源码才能走的更远。
本篇解读的是BERT开源项目中分类器部分的源码,从最开始的数据输入到模型运行整个流程主要可以分成数据处理模块、特征处理模块、模型构建模块和模型运行模块。具体如下图所示:
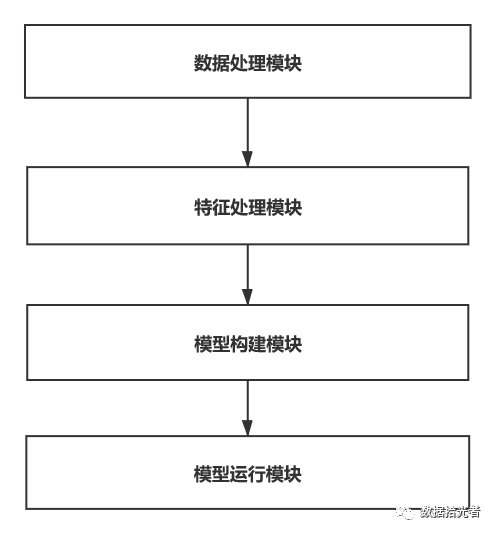
图1 BERT分类器整体模块划分
因为原生态BERT预训练模型动辄几百兆甚至上千兆的大小,模型训练速度非常慢,对于BERT模型线上化非常不友好,所以使用目前比较火的BERT最新派生产品ALBERT来完成BERT线上化服务。ALBERT使用参数减少技术来降低内存消耗从而最终达到提高BERT的训练速度,并且在主要基准测试中均名列前茅,可谓跑的快,还跑的好。本篇解读的BERT源码也是基于ALBERT开源项目。
项目开源的github工程:https://github.com/wilsonlsm006/albert_zh
主要解读分类器部分的源码,代码及注释在run_classifier.py文件,欢迎小伙伴们fork。
数据处理模块
数据处理模块主要负责数据读入和预处理功能。
数据处理主要由数据处理器DataProcessor来完成。根据不同的任务会有不同的数据处理器子类,这里的不同表现在数据读入方式和数据预处理方面。
1. 数据读入方式
实际项目中数据读入的方式多种多样,比如csv、tsv、txt等。比如有的项目是需要读取csv文件,而有的则需要tsv或者txt格式。我们可以构建自定义的数据处理器来完成不同的项目需求。
2. 数据预处理
数据预处理是根据不同的NLP任务来完成不同的操作,比如单句分类任务我们需要的是text_a和label格式。而句子相似关系判断任务需要的是text_a,text_b,label格式。其他任务也是类似的,根据不同的NLP任务来完成数据预处理操作。
通过一个类图来讲解源码中的数据处理器:
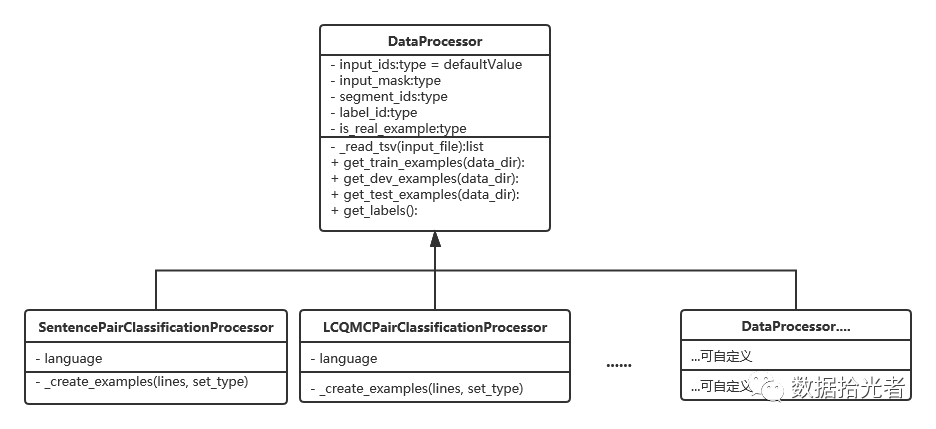
图2 数据处理器类图
对应到项目源码中,我们有一个DataProcessor父类。父类中有五个方法,分别是读取tsv文件、获得训练集、获得验证集、获得测试集和获得标签。这里可根据业务需求增删改获取文件类型的函数,比如读取csv可以添加get_csv(input_file)等等。
class DataProcessor(object):"""Base class for data converters for sequence classification data sets."""def get_train_examples(self, data_dir):"""Gets a collection of `InputExample`s for the train set."""raise NotImplementedError()def get_dev_examples(self, data_dir):"""Gets a collection of `InputExample`s for the dev set."""raise NotImplementedError()def get_test_examples(self, data_dir):"""Gets a collection of `InputExample`s for prediction."""raise NotImplementedError()def get_labels(self):"""Gets the list of labels for this data set."""raise NotImplementedError()def _read_tsv(cls, input_file, quotechar=None):"""Reads a tab separated value file."""with tf.gfile.Open(input_file, "r") as f:reader = csv.reader(f, delimiter="\t", quotechar=quotechar)lines = []for line in reader:lines.append(line)return lines
下面两个子类,分别是处理句子关系判断任务的SentencePairClassificationProcessor数据处理器和LCQMCPairClassificationProcessor分类的数据处理器。前面文章有讲过如果需要做单句分类的任务我们可以在这里添加一个SentenceClassifierProcess进行定制化开发。
对应到项目源码中,因为我们是句子关系判断任务,其实就是判断两句话是不是有关系,这里我们得到的最终数据格式是列表类型,具体数据格式如下:
[(guid,text_a,text_b,label),(guid,text_a,text_b,label),....]
其中guid作为唯一识别text_a和text_b句子对的标志,可以理解为该条样例的唯一id;
text_a和text_b是需要判断的两个句子;
label字段就是标签,如果两句话相似则置为1,否则为0。
上面四个字段guid和text_a是必须的。text_b是可选的,如果为空则变成单句分类任务,不为空则是句子关系判断任务。label在训练集和验证集是必须的,在测试集中可以不提供。
具体代码在SentencePairClassificationProcessor子类的_create_examples函数:
def _create_examples(self, lines, set_type):"""Creates examples for the training and dev sets."""examples = []print("length of lines:", len(lines))for (i, line) in enumerate(lines):# print('#i:',i,line)if i == 0:continueguid = "%s-%s" % (set_type, i)try:label = tokenization.convert_to_unicode(line[2])text_a = tokenization.convert_to_unicode(line[0])text_b = tokenization.convert_to_unicode(line[1])examples.append(InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))except Exception:print('###error.i:', i, line)return examples
特征处理模块
特征处理模块主要的功能是将数据处理模块得到的数据转化成特征并持久化到TFRecord文件中,由file_based_convert_examples_to_features函数完成。
"""将数据处理模块得到的数据转化成TFRecord文件input:examples:数据格式为[(guid,text_a,text_b,label),(guid,text_a,text_b,label),....]label_list:标签列表max_seq_length:允许的句子最大长度tokenizer:分词器output_file:TFRecord文件存储路径output:持久化到TFRecord格式文件"""def file_based_convert_examples_to_features(examples,label_list,max_seq_length,tokenizer, output_file):
1. 预处理数据转化成特征
数据转化成特征的操作主要由函数convert_single_example完成。传统的机器学习需要从数据中抽取特征,NLP任务是对文本进行分词等操作获取特征。BERT模型中默认每个字字就是一个词。
"""将预处理数据加工成模型需要的特征input:ex_index:数据条数索引example:数据格式为[(guid,text_a,text_b,label),(guid,text_a,text_b,label),....]label_list:标签列表max_seq_length:允许的句子最大长度,这里如果输入句子长度不足则补0tokenizer:分词器output: feature = InputFeatures(input_ids=input_ids:token embedding:表示词向量,第一个词是CLS,分隔词有SEP,是单词本身input_mask=input_mask:position embedding:为了令transformer感知词与词之间的位置关系segment_ids=segment_ids:segment embedding:text_a与text_b的句子关系label_id=label_id:标签is_real_example=True)"""def convert_single_example(ex_index, example,label_list, max_seq_length,tokenizer):....feature = InputFeatures(input_ids=input_ids,input_mask=input_mask,segment_ids=segment_ids,label_id=label_id,is_real_example=True)return feature
论文中BERT模型的输入转化成特征如下图所示:
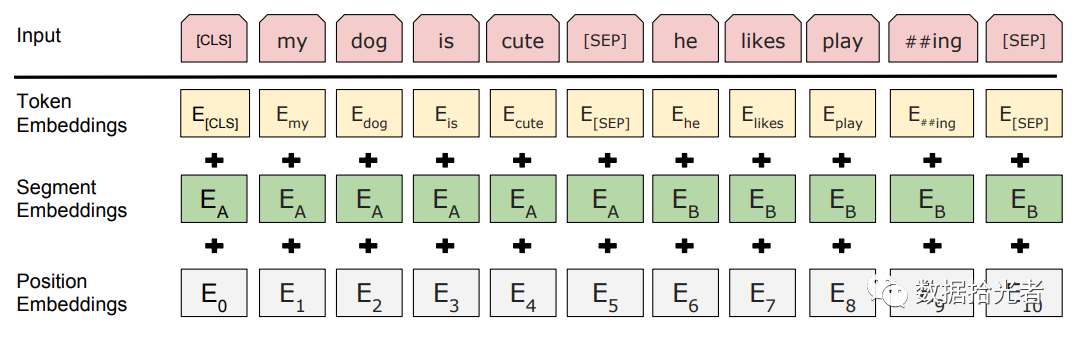
图3 句子输入转化成三层Embedding
这里需要注意下对text_a和text_b的预处理操作。首先会进行标记化将text_a和text_b转化成tokens_a和tokens_b。如果tokens_b存在,那么tokens_a和tokens_b的长度就不能超过max_seq_length-3,因为需要加入cls,sep,seq三个符号;如果tokens_b不存在,那么tokens_a的长度不能超过 max_seq_length -2 ,因为需要加入 cls 和 sep符号。
这里通过一条具体的数据转化成特征说明上述流程。现在我们的example中有一条数据,分别有三个字段:
text_a: 这种图片是用什么软件制作的?
text_b: 这种图片制作是用什么软件呢?
label: 1
经过分词之后,我们会得到:
tokens: [CLS] 这 种 图 片 是 用 什 么 软 件 制 作 的 ? [SEP] 这 种 图 片 制 作 是 用 什 么 软 件 呢 ? [SEP]
其中[CLS]是模型额外增加的开始标志,说明这是句首位置。[SEP]代表分隔符,我们会将两句话拼接成一句话,通过分隔符来识别。第二句话拼接完成后也会加上一个分隔符。这里需要注意的是BERT对于中文分词是以每个字进行切分,并不是我们通常理解的按照中文实际的词进行切分。
经过特征提取之后变成了:
input_ids:101 6821 4905 1745 4275 3221 4500 784 720 6763 816 1169 868 46388043 102 6821 4905 1745 4275 1169 868 3221 4500 784 720 6763 816 1450 8043 1020 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
input_mask:1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 0
segment_ids:0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 0
label_id:1
这里详细说下我们真正给模型输入的特征是什么。
input_ids代表词向量编码。NLP任务中我们会将文本转化成词向量的表征形式提供给模型。通过BERT源码中的tokenizer将句子拆分成字,并且将字映射成id。比如上面例子中第一句话有14个字,第二句话也有14个字,再加上一个开始标志和两个分隔符,一种有31个字。而上面例子中的input_ids列表中前31个位置都有每个字映射的id,并且相同字的映射的id也是一样的。其他则通过添加0进行填充;
input_mask代表位置编码。为了transformer感知词与词之间的位置关系,源码中会将当前位置有字的设置为1,其他用0进行填充;
segment_ids代表句子关系编码。如果是句子关系判断任务则会将text_b位置对应的句子关系编码置为1。这里需要注意,只要是句子关系判断任务,不管两句话到底有没有关系,即标签是否为1都会将text_b位置对应的句子关系编码置为1;
label_id就代表两句话是不是有关系。如果有关系则标签置为1,否则为0。
2. 特征存储在TFRecord格式文件
当我们进行模型训练的时候,会将全部训练数据加载到内存中。对于小规模数据集来说没有问题,但是遇到大规模数据集时我们的内存并不能加载全部的数据,所以涉及到分批加载数据。Tensorflow给开发者提供了TFRecord格式文件。TFRecord内部采用二进制编码,加载快,对大型数据转换友好。
小结下,特征处理模块主要将预处理得到的数据转化成特征并存储到TFRecord格式文件。BERT会将句子输入转化成三层Embedding编码,第一层是词编码,主要表示词本身;第二层编码是位置编码,主要为了transformer感知词与词之间的位置关系;第三层编码则表示句与句之间关系。通过这三层编码我们就得到了模型的特征输入。为了方便大数据集下模型训练加载数据,我们将特征持久化到TFRecord格式文件。
模型构建模块
模型构建模块主要分成模型构建和模型标准输入。
1. 模型构建
通过函数model_fn_builder来构建自定义模型估计器。
"""自定义模型估计器(model_fn_builder)input:bert_config:bert相关的配置num_labels:标签的数量init_checkpoint:预训练模型learning_rate:学习率num_train_steps:模型训练轮数 = (训练集总数/batch_size)*epochsnum_warmup_steps:线性地增加学习率,num_warmup_steps = num_train_steps * warmup_proportionuse_tpu:是否使用TPUoutput:构建好的模型"""def model_fn_builder(bert_config, num_labels, init_checkpoint, learning_rate,num_train_steps, num_warmup_steps, use_tpu,use_one_hot_embeddings):"""Returns `model_fn` closure for TPUEstimator."""......return model_fn
这里模型构建主要有create_model函数完成,主要完成两件事:第一是调用modeling.py中的BertModel类创建模型;第二是计算交叉熵损失loss。交叉熵的值越小,两个概率分布就越接近。
"""创建模型,主要完成两件事:第一件事是调用modeling.py中国的BertModel类创建模型;第二件事事计算交叉熵损失loss。交叉熵的值越小,两个概率分布就越接近。"""def create_model(bert_config, is_training, input_ids, input_mask, segment_ids,labels, num_labels, use_one_hot_embeddings):"""Creates a classification model."""# 建立一个BERT分类模型(create_model)model = modeling.BertModel(config=bert_config,is_training=is_training,input_ids=input_ids,input_mask=input_mask,token_type_ids=segment_ids,use_one_hot_embeddings=use_one_hot_embeddings)......return (loss, per_example_loss, logits, probabilities)
2. 模型标准输入
因为源项目是基于Tensorflow框架开发,所以需要将前面得到的特征转化成标准的Tensorflow模型输入格式。这块主要由函数file_based_input_fn_builder来完成。通过输入文件的不同可以完成训练集、验证集和测试集的输入。
"""模型标准输入从TFRecord格式文件中读取特征并转化成TensorFlow标准的数据输入格式input:input_file:input_file=train_file:输入文件,可以是训练集、验证集和预测集seq_length=FLAGS.max_seq_length:句子最大长度is_training=True:是否训练标志drop_remainder=True:表示在少于batch_size元素的情况下是否应删除最后一批 ; 默认是不删除。output:TensorFlow标准的格式输入"""def file_based_input_fn_builder(input_file, seq_length, is_training,drop_remainder):name_to_features = {"input_ids": tf.FixedLenFeature([seq_length], tf.int64),"input_mask": tf.FixedLenFeature([seq_length], tf.int64),"segment_ids": tf.FixedLenFeature([seq_length], tf.int64),"label_ids": tf.FixedLenFeature([], tf.int64),"is_real_example": tf.FixedLenFeature([], tf.int64),}......return input_fn
这里需要注意的是is_training字段,对于训练数据,需要大量的并行读写和打乱顺序;而对于验证数据,我们不希望打乱数据,是否并行也不关心。
小结下,模型构建模块主要由模型构建和模型标准输入两部分。模型构建负责创建和配置BERT模型。模型标准输入则读取TFRecord格式文件并转化成标准的模型输入,根据输入文件的不同完成训练集、验证集和测试集的标准输入。
模型运行模块
上面模型构建好了之后即可运行模型。Tensorflow中模型运行需要构建一个Estimator对象。主要通过源码中tf.contrib.tpu.TPUEstimator()来构建。
"""Estimator对象包装由model_fn指定的模型input:给定输入和其他一些参数use_tpu:是否使用TPUmodel_fn:前面构建好的模型config:模型运行相关的配置train_batch_size:训练batch大小eval_batch_size:验证batch大小predict_batch_size:预测batch大小output:需要进行训练、计算,或预测的操作"""estimator = tf.contrib.tpu.TPUEstimator(use_tpu=FLAGS.use_tpu,model_fn=model_fn,config=run_config,train_batch_size=FLAGS.train_batch_size,eval_batch_size=FLAGS.eval_batch_size,predict_batch_size=FLAGS.predict_batch_size)
1. 模型训练
模型训练通过estimator.train即可完成:
if FLAGS.do_train:train_input_fn = file_based_input_fn_builder(input_file=train_file,seq_length=FLAGS.max_seq_length,is_training=True,drop_remainder=True)....estimator.train(input_fn=train_input_fn, max_steps=num_train_steps)
2. 模型验证
模型验证通过estimator.evaluate即可完成:
if FLAGS.do_eval:= file_based_input_fn_builder(input_file=eval_file,seq_length=FLAGS.max_seq_length,is_training=False,drop_remainder=eval_drop_remainder)....result = estimator.evaluate(input_fn=eval_input_fn, steps=eval_steps, checkpoint_path=filename)
3. 模型预测
模型预测通过estimator.predict即可完成:
if FLAGS.do_predict:predict_input_fn = file_based_input_fn_builder(input_file=predict_file,seq_length=FLAGS.max_seq_length,is_training=False,drop_remainder=predict_drop_remainder)....result = estimator.predict(input_fn=predict_input_fn)
其他模块
1. tf日志模块
import tensorflow as tf# 日志的显示等级tf.logging.set_verbosity(tf.logging.INFO)# 打印提示日志tf.logging.info("***** Runningtraining *****")# 打印传参日志tf.logging.info(" Num examples = %d", len(train_examples))
2. 外部传参模块
import tensorflow as tfflags = tf.flagsFLAGS = flags.FLAGSflags.DEFINE_string("data_dir", None,"The input data dir. Should contain the .tsv files (or other datafiles) ""for thetask.")# 设置哪些参数是必须要传入的flags.mark_flag_as_required("data_dir")
总结本篇主要讲解BERT中分类器部分的源码。整体来看主要分成数据处理模块、特征处理模块、模型构建模块和模型运行模块。数据处理模块主要负责数据读入和预处理工作;特征处理模块负责将预处理后的数据转化成特征并持久化到TFRecord格式文件中;模型构建模块主要负责构建BERT模型和模型标准输入数据准备;模型运行模块主要负责模型训练、验证和预测。通过整体到局部的方式我们可以对BERT中的分类器源码有深入的了解。后面可以根据实际的业务需求对分类器进行二次开发。