
JuiceFS 源码阅读-中
JuiceFS锁的实现
JuiceFS的锁实现,目前同时实现了BSD locks(对应Flock)和POSIX locks(对应Setlk)。细节上最大区别就是BSD locks只能以FD为最小控制单位(简单理解为单文件加锁,锁定的是文件描述符fd对应的文件),而POSIX locks可以在一个文件中以文件的offset+length的方式进行加锁(按文件内容进行范围加锁)。
BSD locks
//pkg/vfs/vfs_unix.go
func Flock(ctx Context, ino Ino, fh uint64, owner uint64, typ uint32, block bool) (err syscall.Errno) {
var name string
var reqid uint32
defer func() { logit(ctx, "flock (%d,%d,%016X,%s,%t): %s", reqid, ino, owner, name, block, strerr(err)) }()
switch typ {
case syscall.F_RDLCK:
name = "LOCKSH"
case syscall.F_WRLCK:
name = "LOCKEX"
case syscall.F_UNLCK:
name = "UNLOCK"
default:
err = syscall.EINVAL
return
}
if IsSpecialNode(ino) {
err = syscall.EPERM
return
}
h := findHandle(ino, fh)
if h == nil {
err = syscall.EBADF
return
}
h.addOp(ctx)
defer h.removeOp(ctx)
err = m.Flock(ctx, ino, owner, typ, block) //核心在元数据部分的控制,具体参考下面部分代码注释
if err == 0 {
h.Lock()
if typ == syscall.F_UNLCK {
h.locks &= 2
} else {
h.locks |= 1
h.flockOwner = owner
}
h.Unlock()
}
return
}
//pkg/meta/sql_unix.go
func (m *dbMeta) Flock(ctx Context, inode Ino, owner uint64, ltype uint32, block bool) syscall.Errno {
if ltype == syscall.F_UNLCK {//如果为解锁操作,则只需要删除对应的db记录即可
return errno(m.txn(func(s *xorm.Session) error {
_, err := s.Delete(&flock{Inode: inode, Owner: owner, Sid: m.sid})
return err
}))
}
var err syscall.Errno
//循环处理加锁请求,分为阻塞(block=true)和非阻塞两种类型操作
for {
err = errno(m.txn(func(s *xorm.Session) error {
//获取inode信息,避免锁指向的对象不存在,成为空锁。
if exists, err := s.Get(&node{Inode: inode}); err != nil || !exists {
if err == nil && !exists {
err = syscall.ENOENT
}
return err
}
//查询inode关联的全部锁信息
rows, err := s.Rows(&flock{Inode: inode})
if err != nil {
return err
}
type key struct {
sid uint64
o uint64
}
var locks = make(map[key]flock)
var l flock
for rows.Next() {
if rows.Scan(&l) == nil {
//执行迭代,将查询结果临时保存到locks数据结构中
locks[key{l.Sid, l.Owner}] = l
}
}
rows.Close()
//判断需要加锁的类型是否为读锁,如果已经有写锁则加锁失败
if ltype == syscall.F_RDLCK {
for _, l := range locks {
if l.Ltype == 'W' {
return syscall.EAGAIN
}
}
//没有写锁冲突,则通过insert记录加上读锁
return mustInsert(s, flock{Inode: inode, Owner: owner, Ltype: 'R', Sid: m.sid})
}
//加写入锁逻辑:先判断是否已经有写入锁(判断locks中是否有重复键值),如果有则更新锁的记录,否则直接insert插入对应的记录
me := key{m.sid, owner}
_, ok := locks[me]
delete(locks, me)
if len(locks) > 0 {
return syscall.EAGAIN
}
if ok {
_, err = s.Cols("Ltype").Update(&flock{Ltype: 'W'}, &flock{Inode: inode, Owner: owner, Sid: m.sid})
} else {
err = mustInsert(s, flock{Inode: inode, Owner: owner, Ltype: 'W', Sid: m.sid})
}
return err
}))
//非阻塞or报错直接返回结果
if !block || err != syscall.EAGAIN {
break
}
//阻塞情况下加写锁,则等待固定时长再进行下一轮加锁操作
if ltype == syscall.F_WRLCK {
time.Sleep(time.Millisecond * 1)
} else {
time.Sleep(time.Millisecond * 10)
}
if ctx.Canceled() {
return syscall.EINTR
}
}
return err
}
POSIX locks
按pid进行范围加锁,实现起来相对比较复杂,核心算法在updateLocks中实现。
func (m *dbMeta) Setlk(ctx Context, inode Ino, owner_ uint64, block bool, ltype uint32, start, end uint64, pid uint32) syscall.Errno {
var err syscall.Errno
lock := plockRecord{ltype, pid, start, end}//以pid为粒度,所以适合单机多进/线程模型,跨节点不太合适
owner := int64(owner_)
for {
err = errno(m.txn(func(s *xorm.Session) error {
if exists, err := s.Get(&node{Inode: inode}); err != nil || !exists {
if err == nil && !exists {
err = syscall.ENOENT
}
return err
}
//unlock操作
if ltype == F_UNLCK {
//sid代表session ID,每个客户端的数据库连接都有一个独立的ID实例
var l = plock{Inode: inode, Owner: owner, Sid: m.sid}
ok, err := m.engine.Get(&l) //按inode、owner、sid三个字段组合,查询锁列表
if err != nil {
return errno(err)
}
if !ok {
return nil
}
ls := loadLocks([]byte(l.Records)) //解析锁列表信息
if len(ls) == 0 {
return nil
}
ls = updateLocks(ls, lock) //在已有所列表里面新增锁记录,有点复杂,之后详细介绍
if len(ls) == 0 {
_, err = s.Delete(&plock{Inode: inode, Owner: owner, Sid: m.sid}) //删除锁记录
} else {
_, err = s.Cols("records").Update(plock{Records: dumpLocks(ls)}, l) //更新已有所记录
}
return err
}
//以inode为关键字,查找已有的锁列表
rows, err := s.Rows(&plock{Inode: inode})
if err != nil {
return errno(err)
}
type key struct {
sid uint64
owner int64
}
var locks = make(map[key][]byte)
var l plock
//按查询结果构建锁map
for rows.Next() {
if rows.Scan(&l) == nil {
locks[key{l.Sid, l.Owner}] = dup(l.Records)
}
}
rows.Close()
//遍历map,判断是否有冲突锁
lkey := key{m.sid, owner}
for k, d := range locks {
if k == lkey {
continue
}
ls := loadLocks([]byte(d))
for _, l := range ls {
// find conflicted locks
if (ltype == F_WRLCK || l.ltype == F_WRLCK) && end > l.start && start < l.end {
return syscall.EAGAIN
}
}
}
ls := updateLocks(loadLocks([]byte(locks[lkey])), lock) //更新锁列表信息
var n int64
//保存锁列表记录到DB
if len(locks[lkey]) > 0 {
n, err = s.Cols("records").Update(plock{Records: dumpLocks(ls)},
&plock{Inode: inode, Sid: m.sid, Owner: owner})
} else {
n, err = s.InsertOne(&plock{Inode: inode, Sid: m.sid, Owner: owner, Records: dumpLocks(ls)})
}
if err == nil && n == 0 {
err = fmt.Errorf("insert/update failed")
}
return err
}))
//如果加锁失败且不进行阻塞,则直接返回结果
if !block || err != syscall.EAGAIN {
break
}
//加锁失败,阻塞,进入下一轮操作
if ltype == F_WRLCK {
time.Sleep(time.Millisecond * 1)
} else {
time.Sleep(time.Millisecond * 10)
}
if ctx.Canceled() {
return syscall.EINTR
}
}
return err
}
updateLocks 的代码逻辑如下,通过加上debug输出,更加容易观察其中细节
const (
F_UNLCK = syscall.F_UNLCK
F_RDLCK = syscall.F_RDLCK
F_WRLCK = syscall.F_WRLCK
)
type plockRecord struct {
ltype uint32
pid uint32
start uint64
end uint64
}
func insertLocks(ls []plockRecord, i int, nl plockRecord) []plockRecord {
//fmt.Println(i,"insertLocks before ls=",ls)
nls := make([]plockRecord, len(ls)+1)
copy(nls[:i], ls[:i])
nls[i] = nl
copy(nls[i+1:], ls[i:])
ls = nls
//fmt.Println(i,"insertLocks after ls=",ls)
return ls
}
func updateLocks(ls []plockRecord, nl plockRecord) []plockRecord {
// ls is ordered by l.start without overlap
var i int
for i < len(ls) && nl.end > nl.start {
l := ls[i]
if l.end < nl.start {
fmt.Println("新增锁设定的区域超过当前锁范围,查找下一个")
} else if l.start < nl.start {
//fmt.Println("l.start=",l.start,"l.end=",l.end,"nl.start=",nl.start,"nl.end",nl.end)
fmt.Println("1. 当前锁包含部分新锁区域,拆分成两个锁,调整当前锁范围从[",ls[i].start,"->",ls[i].end,"]调整为[",ls[i].start,"->",nl.start,"],并在当前位置之后插入新锁 [",nl.start,"->",l.end,"]")
//fmt.Println("1-> l.start=",l.start," < nl.start=",nl.start,"l.end=",l.end," < nl.end=",nl.end )
ls = insertLocks(ls, i+1, plockRecord{nl.ltype, nl.pid, nl.start, l.end})
ls[i].end = nl.start
i++
nl.start = l.end
} else if l.end < nl.end {
//fmt.Println("2-> l.end < nl.end","nl.start=",nl.start,"ls[i].start=",ls[i].start)
fmt.Println("2. 当前锁区间属于新锁区间,缩小当前锁范围,从[",ls[i].start,"->",ls[i].end,"]调整为[",nl.start,"->",ls[i].end,"]")
ls[i].ltype = nl.ltype
ls[i].start = nl.start
nl.start = l.end
} else if l.start < nl.end {
//fmt.Println("3. l.start=",l.start,"l.end=",l.end,"nl.start=",nl.start,"nl.end=",nl.end)
ls = insertLocks(ls, i, nl)
fmt.Println("3. 新锁与当前锁有部分内容重叠,需要在当前位置插入新锁=[",nl.start,nl.end,"],并调整下一个锁的起始位置从[",ls[i+1].start,ls[i+1].end,"] -> [",nl.end,ls[i+1].end,"]")
ls[i+1].start = nl.end
nl.start = nl.end
} else {
fmt.Println("4. l.start=",l.start,"l.end=",l.end,"nl.start=",nl.start,"nl.end",nl.end)
fmt.Println("4. 新锁右侧和当前锁没有重叠(l.start>nl.end),仅需要在当前位置插入新锁=[",nl.start,nl.end,"]")
ls = insertLocks(ls, i, nl)
nl.start = nl.end
}
i++
}
if nl.start < nl.end {
ls = append(ls, nl)
fmt.Println("5. 仍然有部分尾部内容没有,补充末尾部分的锁内容,补充后=",ls)
}
i = 0
//再次遍历锁列表,进行无效内容删除or区间合并操作。
for i < len(ls) {
if ls[i].ltype == F_UNLCK || ls[i].start == ls[i].end {
// remove empty one
//fmt.Println("删除锁列表从i=",i,"位置的内容,删除前ls=",ls)
//fmt.Println("删除锁列表从i=",i,"位置的内容",ls[i:i+1])
copy(ls[i:], ls[i+1:]) //从i位置开始左移1个单位
ls = ls[:len(ls)-1] //删除末尾
fmt.Println("6-1. 删除锁列表从i=",i,"位置的内容,删除后ls=",ls)
} else {
if i+1 < len(ls) && ls[i].ltype == ls[i+1].ltype && ls[i].end == ls[i+1].start {
fmt.Println("6-2. 锁类型相同,且首尾相接,进行区间合并操作",ls)
// combine continuous range
ls[i].end = ls[i+1].end
ls[i+1].start = ls[i+1].end
//fmt.Println("锁类型相同,且首尾相接,进行区间合并操作2",ls)
}
i++
}
}
return ls
}
小结
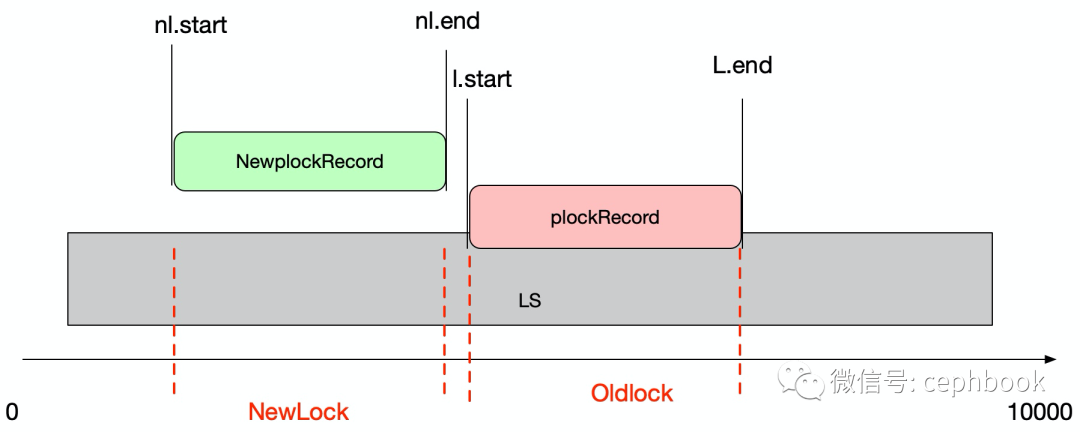
整个POSIX locks的算法主要是通过遍历已有的锁列表ls(数组结构),并按照一定规则进行新增锁记录的插入(简单理解为滑动窗口查找),其中nl代表窗口滑动范围锁,l代表当前已经有的锁。
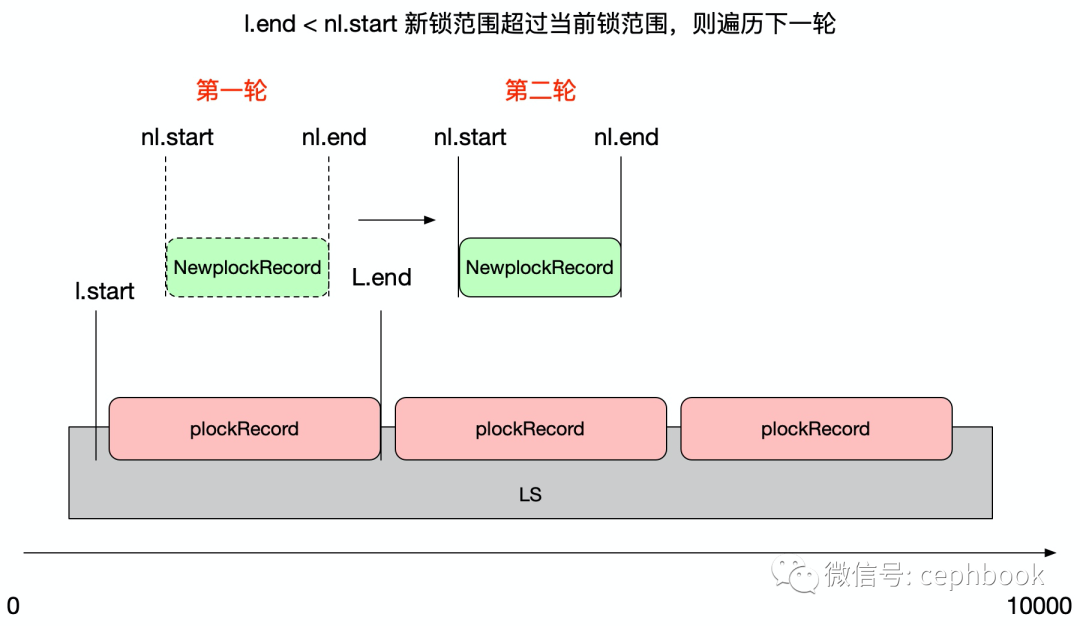
根据代码注释,大概分为4种类型的锁处理。其中lodlock代表已有的锁记录(对应l),Newlock是新增锁的记录(对应nl)
类型1:
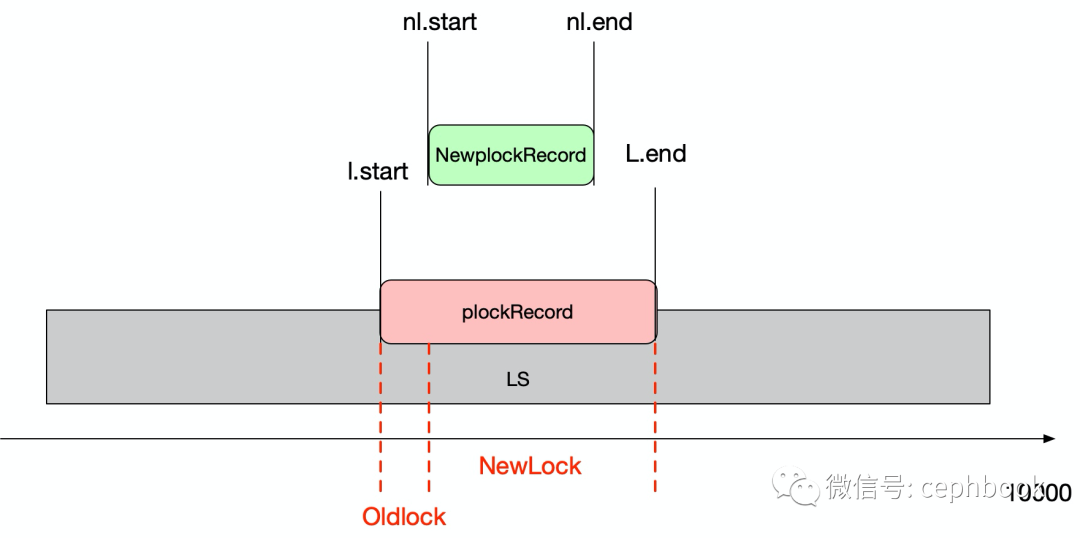
类型2:
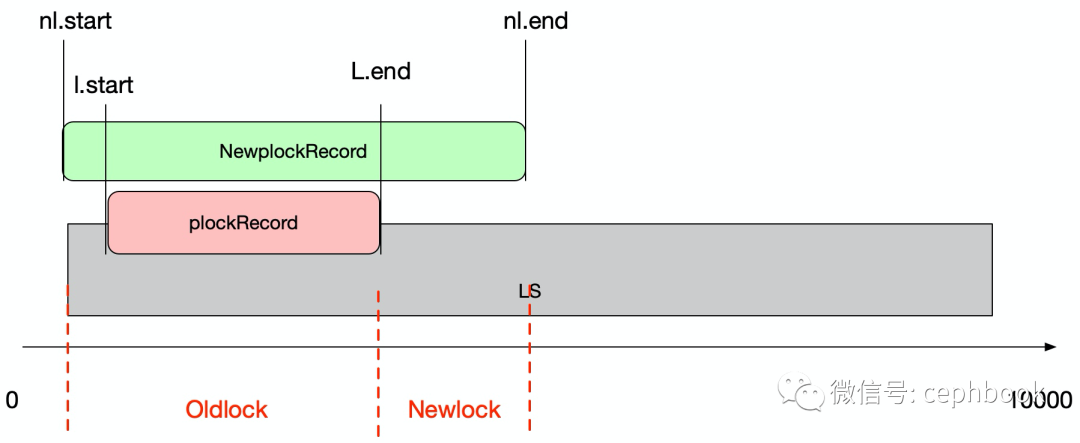
类型3:
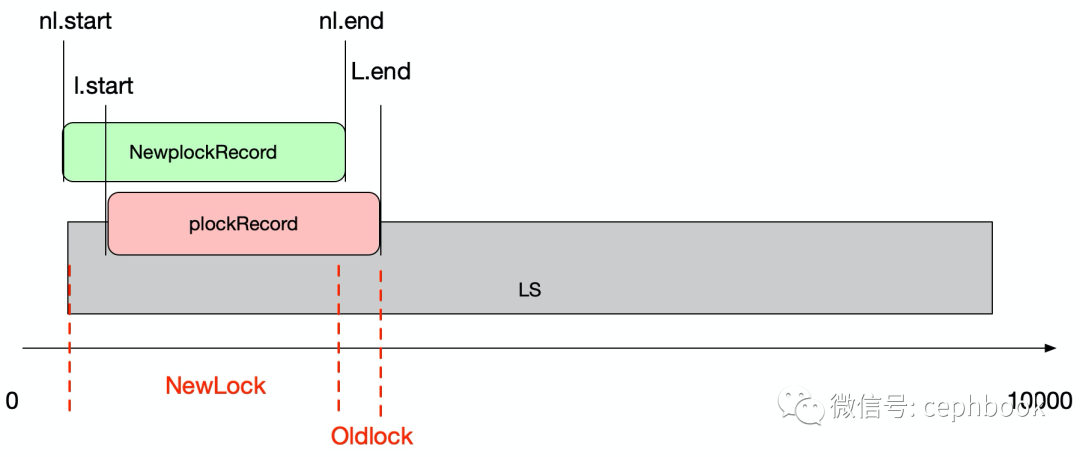
类型4:
发现问题
发现一个pid同步的bug,当新锁的内容覆盖旧锁时,并未更新对应的pid记录,导致加锁虽然成功,但是锁的pid还是指向旧的pid内容。复现代码如下
package main
import (
"fmt"
"syscall"
)
const (
F_UNLCK = syscall.F_UNLCK
F_RDLCK = syscall.F_RDLCK
F_WRLCK = syscall.F_WRLCK
)
type plockRecord struct {
ltype uint32
pid uint32
start uint64
end uint64
}
func insertLocks(ls []plockRecord, i int, nl plockRecord) []plockRecord {
//fmt.Println(i,"insertLocks before ls=",ls)
nls := make([]plockRecord, len(ls)+1)
copy(nls[:i], ls[:i])
nls[i] = nl
copy(nls[i+1:], ls[i:])
ls = nls
//fmt.Println(i,"insertLocks after ls=",ls)
return ls
}
func updateLocks(ls []plockRecord, nl plockRecord) []plockRecord {
// ls is ordered by l.start without overlap
var i int
for i < len(ls) && nl.end > nl.start {
l := ls[i]
if l.end < nl.start {
fmt.Println("新增锁设定的区域超过当前锁范围,查找下一个")
} else if l.start < nl.start {
//fmt.Println("l.start=",l.start,"l.end=",l.end,"nl.start=",nl.start,"nl.end",nl.end)
fmt.Println("1. 当前锁包含部分新锁区域,拆分成两个锁,调整当前锁范围从[",ls[i].start,"->",ls[i].end,"]调整为[",ls[i].start,"->",nl.start,"],并在当前位置之后插入新锁 [",nl.start,"->",l.end,"]")
//fmt.Println("1-> l.start=",l.start," < nl.start=",nl.start,"l.end=",l.end," < nl.end=",nl.end )
ls = insertLocks(ls, i+1, plockRecord{nl.ltype, nl.pid, nl.start, l.end})
ls[i].end = nl.start
i++
nl.start = l.end
} else if l.end < nl.end {
//fmt.Println("2-> l.end < nl.end","nl.start=",nl.start,"ls[i].start=",ls[i].start)
fmt.Println("2. 当前锁区间属于新锁区间,缩小当前锁范围,从[",ls[i].start,"->",ls[i].end,"]调整为[",nl.start,"->",ls[i].end,"]")
ls[i].ltype = nl.ltype
ls[i].start = nl.start
//if ls[i].pid != nl.pid { //patch
// ls[i].pid = nl.pid
//}
nl.start = l.end
} else if l.start < nl.end {
//fmt.Println("3. l.start=",l.start,"l.end=",l.end,"nl.start=",nl.start,"nl.end=",nl.end)
ls = insertLocks(ls, i, nl)
fmt.Println("3. 新锁与当前锁有部分内容重叠,需要在当前位置插入新锁=[",nl.start,nl.end,"],并调整下一个锁的起始位置从[",ls[i+1].start,ls[i+1].end,"] -> [",nl.end,ls[i+1].end,"]")
ls[i+1].start = nl.end
nl.start = nl.end
} else {
fmt.Println("4. l.start=",l.start,"l.end=",l.end,"nl.start=",nl.start,"nl.end",nl.end)
fmt.Println("4. 新锁右侧和当前锁没有重叠(l.start>nl.end),仅需要在当前位置插入新锁=[",nl.start,nl.end,"]")
ls = insertLocks(ls, i, nl)
nl.start = nl.end
}
i++
}
if nl.start < nl.end {
ls = append(ls, nl)
fmt.Println("5. 仍然有部分尾部内容没有,补充末尾部分的锁内容,补充后=",ls)
}
i = 0
//再次遍历锁列表,进行无效内容删除or区间合并操作。
for i < len(ls) {
if ls[i].ltype == F_UNLCK || ls[i].start == ls[i].end {
// remove empty one
//fmt.Println("删除锁列表从i=",i,"位置的内容,删除前ls=",ls)
//fmt.Println("删除锁列表从i=",i,"位置的内容",ls[i:i+1])
copy(ls[i:], ls[i+1:]) //从i位置开始左移1个单位
ls = ls[:len(ls)-1] //删除末尾
fmt.Println("6-1. 删除锁列表从i=",i,"位置的内容,删除后ls=",ls)
} else {
if i+1 < len(ls) && ls[i].ltype == ls[i+1].ltype && ls[i].end == ls[i+1].start {
fmt.Println("6-2. 锁类型相同,且首尾相接,进行区间合并操作",ls)
// combine continuous range
ls[i].end = ls[i+1].end
ls[i+1].start = ls[i+1].end
//fmt.Println("锁类型相同,且首尾相接,进行区间合并操作2",ls)
}
i++
}
}
return ls
}
func Setlk( ltype uint32, start, end uint64, pid uint32) {
lock := plockRecord{ltype, pid, start, end}
//ls := []plockRecord{plockRecord{F_WRLCK, pid, 0, 4},{F_WRLCK, pid, 7, 10},{F_WRLCK, pid, 13, 16}}
ls := []plockRecord{plockRecord{F_WRLCK, 100, 0, 4},{F_WRLCK, 102, 7, 10}}
//ls := []plockRecord{plockRecord{F_WRLCK, pid, 1, 4}}
fmt.Println("before updateLocks=",ls)
ls = updateLocks(ls, lock)
fmt.Println("after updateLocks=",ls)
}
func main(){
Setlk(F_WRLCK,6,13,103) //理论上加锁以后的记录应该对应pid=103,上面的patch已经修复这个问题
}
输出内容如下:
before updateLocks= [{3 100 0 4} {3 102 7 10}]
新增锁设定的区域超过当前锁范围,查找下一个
2. 当前锁区间属于新锁区间,缩小当前锁范围,从[ 7 -> 10 ]调整为[ 6 -> 10 ]
5. 仍然有部分尾部内容没有,补充末尾部分的锁内容,补充后= [{3 100 0 4} {3 102 6 10} {3 103 10 13}]
6-2. 锁类型相同,且首尾相接,进行区间合并操作 [{3 100 0 4} {3 102 6 10} {3 103 10 13}]
6-1. 删除锁列表从i= 2 位置的内容,删除后ls= [{3 100 0 4} {3 102 6 13}]
after updateLocks= [{3 100 0 4} {3 102 6 13}] //理论上这里的pid=102是对应的是旧锁内容,应该被新增加的锁记录pid=103覆盖评论