
深刻理解:模型性能之计算量与访存量!
地址:https://zhuanlan.zhihu.com/p/34204282
最近在不同的计算平台上验证几种经典深度学习模型的训练和预测性能时,经常遇到模型的实际测试性能表现和自己计算出的复杂度并不完全吻合的现象,令人十分困惑。
机缘巧合听了Momenta的技术分享后,我意识到问题的答案其实就在于 Roof-line Model 这个理论,于是认真研究了一下相关论文。现在把自己的心得总结出来,分享给大家。
在真实世界中,任何模型(例如 VGG / MobileNet 等)都必须依赖于具体的计算平台(例如CPU / GPU / ASIC 等)才能展现自己的实力。此时,模型和计算平台的"默契程度"会决定模型的实际表现。Roofline Model 提出了使用 Operational Intensity(计算强度)进行定量分析的方法,并给出了模型在计算平台上所能达到理论计算性能上限公式。

01
算力  :也称为计算平台的性能上限,指的是一个计算平台倾尽全力每秒钟所能完成的浮点运算数。单位是 FLOPS or FLOP/s。
:也称为计算平台的性能上限,指的是一个计算平台倾尽全力每秒钟所能完成的浮点运算数。单位是 FLOPS or FLOP/s。

带宽  :也即计算平台的带宽上限,指的是一个计算平台倾尽全力每秒所能完成的内存交换量。单位是Byte/s。
:也即计算平台的带宽上限,指的是一个计算平台倾尽全力每秒所能完成的内存交换量。单位是Byte/s。

计算强度上限  :两个指标相除即可得到计算平台的计算强度上限。它描述的是在这个计算平台上,单位内存交换最多用来进行多少次计算。单位是FLOPs/Byte。
:两个指标相除即可得到计算平台的计算强度上限。它描述的是在这个计算平台上,单位内存交换最多用来进行多少次计算。单位是FLOPs/Byte。
 注:这里所说的“内存”是广义上的内存。对于CPU计算平台而言指的就是真正的内存;而对于GPU计算平台指的则是显存。
注:这里所说的“内存”是广义上的内存。对于CPU计算平台而言指的就是真正的内存;而对于GPU计算平台指的则是显存。
02
计算量:指的是输入单个样本(对于CNN而言就是一张图像),模型进行一次完整的前向传播所发生的浮点运算个数,也即模型的时间复杂度。单位是 #FLOP or FLOPs。其中卷积层的计算量公式如下:

访存量:指的是输入单个样本,模型完成一次前向传播过程中所发生的内存交换总量,也即模型的空间复杂度。在理想情况下(即不考虑片上缓存),模型的访存量就是模型各层权重参数的内存占用(Kernel Mem)与每层所输出的特征图的内存占用(Output Mem)之和。单位是Byte。由于数据类型通常为float32 ,因此需要乘以四。

模型的计算强度  :由计算量除以访存量就可以得到模型的计算强度,它表示此模型在计算过程中,每Byte内存交换到底用于进行多少次浮点运算。单位是FLOPs/Byte。可以看到,模计算强度越大,其内存使用效率越高。
:由计算量除以访存量就可以得到模型的计算强度,它表示此模型在计算过程中,每Byte内存交换到底用于进行多少次浮点运算。单位是FLOPs/Byte。可以看到,模计算强度越大,其内存使用效率越高。
模型的理论性能  :我们最关心的指标,即模型在计算平台上所能达到的每秒浮点运算次数(理论值)。单位是 FLOPS or FLOP/s。下面我们即将介绍的 Roof-line Model 给出的就是计算这个指标的方法。终于可以进入正题了。
:我们最关心的指标,即模型在计算平台上所能达到的每秒浮点运算次数(理论值)。单位是 FLOPS or FLOP/s。下面我们即将介绍的 Roof-line Model 给出的就是计算这个指标的方法。终于可以进入正题了。
03
其实 Roof-line Model 说的是很简单的一件事:模型在一个计算平台的限制下,到底能达到多快的浮点计算速度。更具体的来说,Roof-line Model 解决的,是“计算量为A且访存量为B的模型在算力为C且带宽为D的计算平台所能达到的理论性能上限E是多少”这个问题。
3.1 Roof-line 的形态
所谓“Roof-line”,指的就是由计算平台的算力和带宽上限这两个参数所决定的“屋顶”形态,如下图所示。
算力决定“屋顶”的高度(绿色线段)
带宽决定“房檐”的斜率(红色线段)
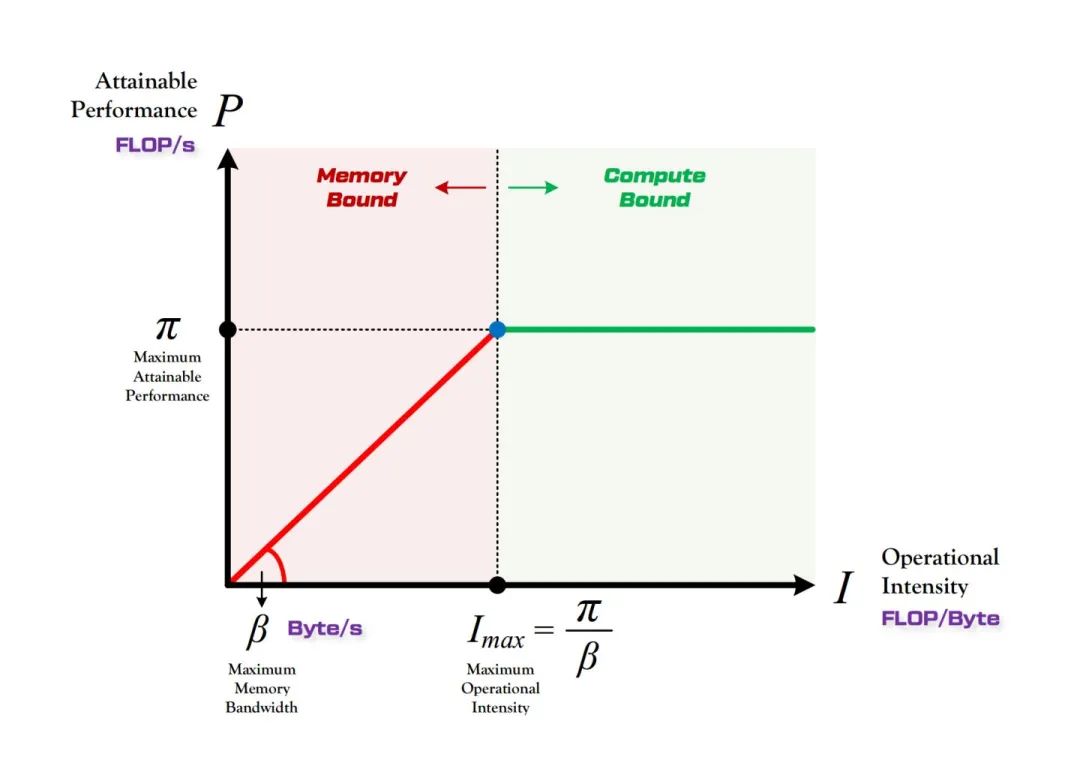
3.2 Roof-line 划分出的两个瓶颈区域

计算瓶颈区域 Compute-Bound
不管模型的计算强度 有多大,它的理论性能 最大只能等于计算平台的算力 。当模型的计算强度 大于计算平台的计算强度上限 时,模型在当前计算平台处于 Compute-Bound状态,即模型的理论性能 受到计算平台算力 的限制,无法与计算强度 成正比。但这其实并不是一件坏事,因为从充分利用计算平台算力的角度上看,此时模型已经  的利用了计算平台的全部算力。可见,计算平台的算力 越高,模型进入计算瓶颈区域后的理论性能 也就越大。
的利用了计算平台的全部算力。可见,计算平台的算力 越高,模型进入计算瓶颈区域后的理论性能 也就越大。
带宽瓶颈区域 Memory-Bound
当模型的计算强度 小于计算平台的计算强度上限 时,由于此时模型位于“房檐”区间,因此模型理论性能 的大小完全由计算平台的带宽上限 (房檐的斜率)以及模型自身的计算强度 所决定,因此这时候就称模型处于 Memory-Bound 状态。可见,在模型处于带宽瓶颈区间的前提下,计算平台的带宽 越大(房檐越陡),或者模型的计算强度 越大,模型的理论性能 可呈线性增长。
04
下面让我们先分别给出 VGG16 和 MobileNet 的计算量和访存量统计表格,然后再用 Roof-line Model 理论来对比分析一下下。很有意思哦!
4.1 VGG16
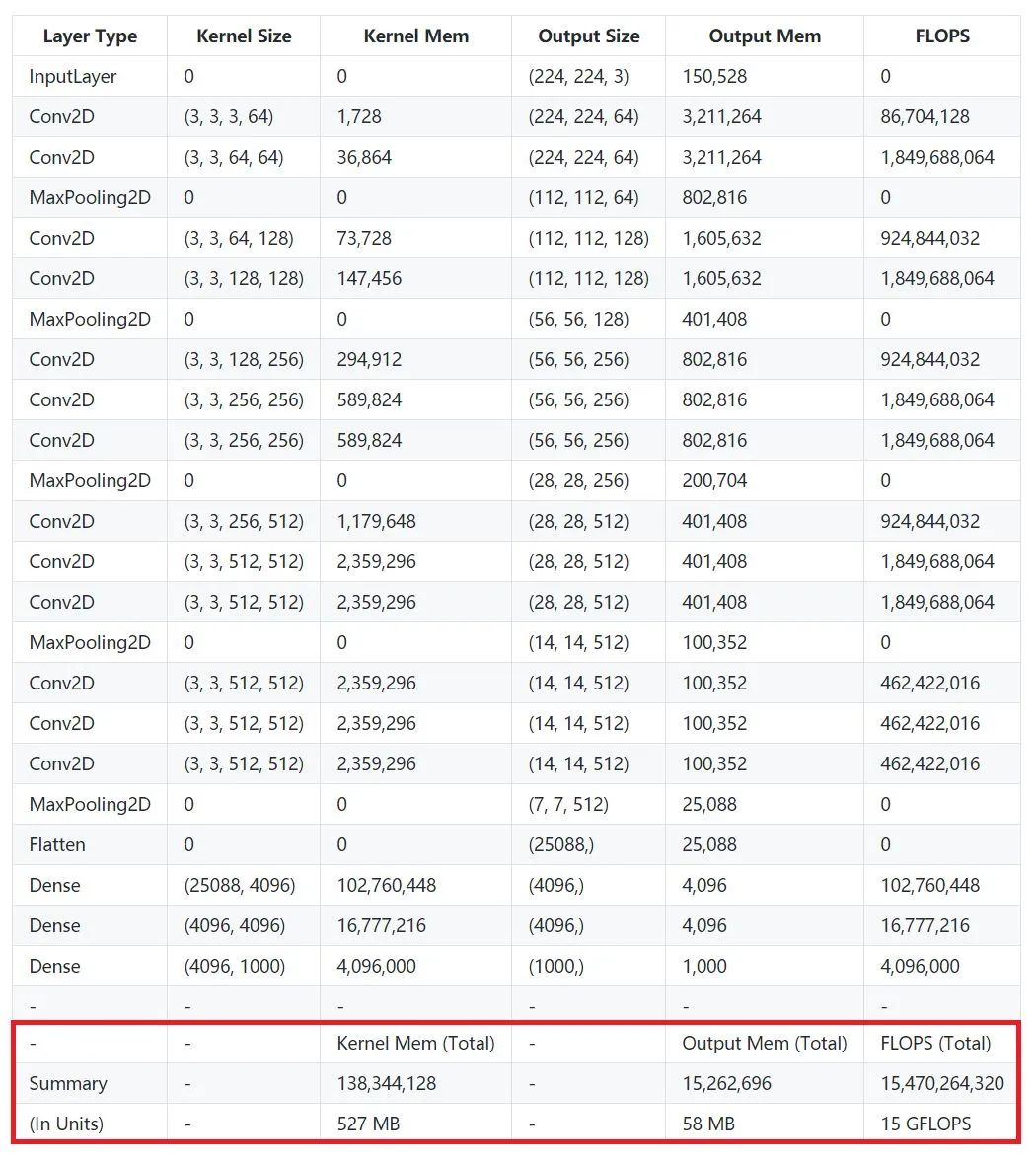
VGG 可以说是在计算强度上登峰造极的一个模型系列,简约不简单。以 VGG16 为例,从上表可以看到,仅包含一次前向传播的计算量就达到了 15 GFLOPs,如果包含反向传播,则需要再乘二。访存量则是 Kernel Mem 和 Output Mem 之和再乘以四,大约是 600MB。因此 VGG16 的计算强度就是 25 FLOPs/Byte。
另外如果把模型顶端那两个硕大无比的全链接层(其参数量占整个模型的80%以上)替换为GAP以降低访存量(事实证明这样修改并不会影响准确率),那么它的实际计算强度可以再提升四倍以上,简直突破天际。
注:以上分析仅限于前向传播计算过程(即模型预测)。如果涵盖反向传播(即模型训练),则计算量和访存量都要考虑梯度更新的具体方式,例如计算 Momentum 几个变量时引入的时间和空间复杂度。
4.2 MobileNet
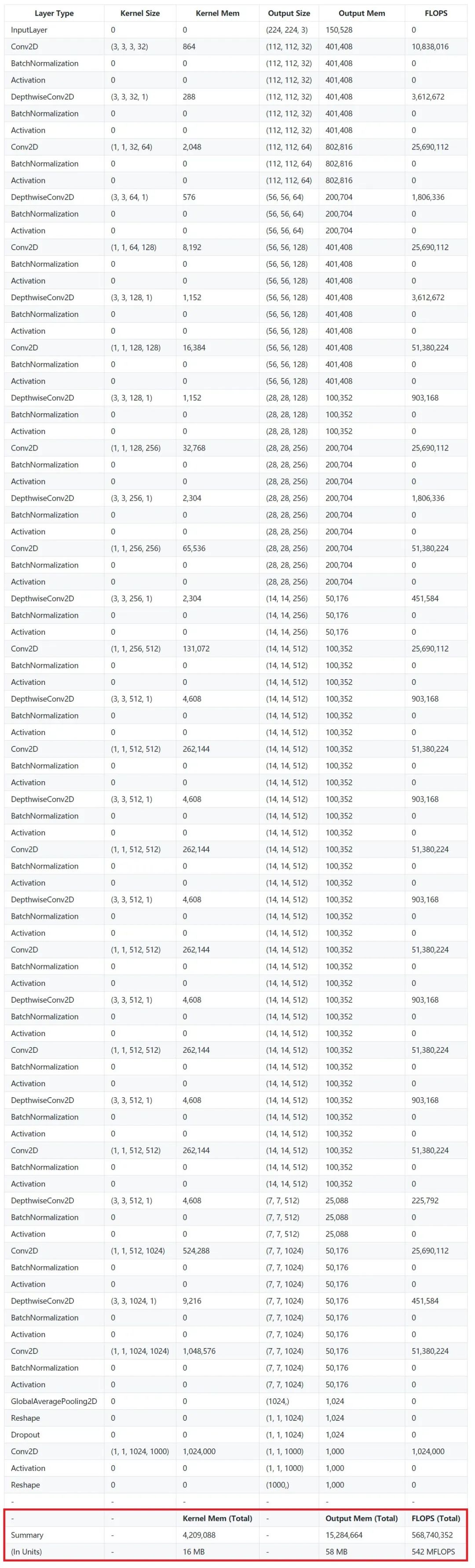
MobileNet 是以轻量著称的小网络代表(最近新出了V2版本)。相比简单而庞大的 VGG16 结构,MobileNet 的网络更为细长,加入了大量的BN,每一层都通过 DW + PW 的方式降低了计算量,同时也付出了计算效率低的代价。从上面超级长的表格就能有一个感性的的认识。
MobileNet 的计算量只有大约 0.5 GFLOPs(VGG16 则是 15 GFLOPs),其访存量也只有 74 MB(VGG16 则是约 600 MB)。这样看上去确实轻量了很多,但是由于计算量和访存量都下降了,而且相比之下计算量下降的更厉害,因此 MobileNet 的计算强度只有 7 FLOPs/Byte。
4.3 两个模型在 1080Ti 上的对比
作为性价比之王的 1080Ti,我们的两个模型 VGG16 和 MobileNet 的性能将分别位于这个计算平台 Roof-line Model 的什么位置呢?
1080Ti 的算力

1080Ti 的带宽

因此 1080Ti 计算平台的最大计算强度

VGG16 的计算强度

MobileNet 的计算强度

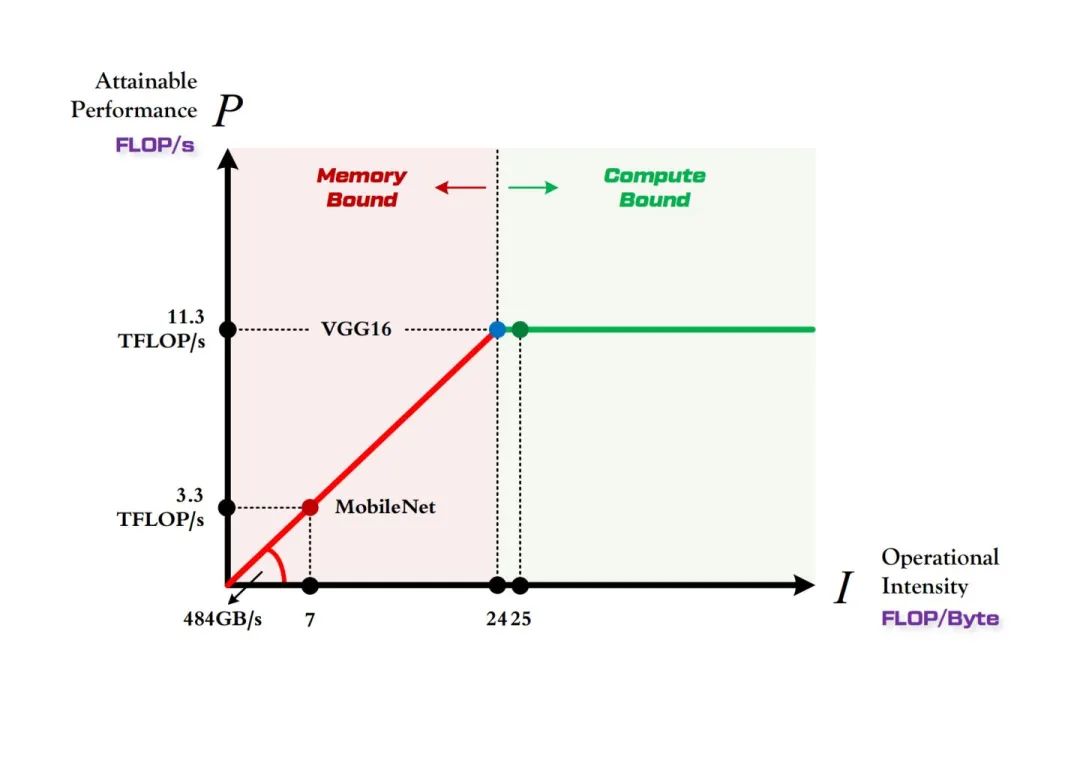
由上图可以非常清晰的看到,
MobileNet 处于 Memory-Bound 区域。在 1080Ti 上的理论性能只有 3.3 TFLOP/s。
VGG16 刚好迈入 Compute-Bound 区域。完全利用 1080Ti 的全部算力。
虽然 MobileNet 进行前向传播的计算量只有 VGG 的三十分之一,但是由于计算平台的带宽限制,它不能像 VGG 那样完全利用 1080Ti 这个计算平台的全部算力,因此它在 1080Ti 上每秒钟可以进行的浮点运算数只能达到 VGG 的 30%,因此理论上的运行速度大约是 VGG 的十倍(实际上会因为各方面其他因素的限制而使得差别更小)。
MobileNet 这类小型网络更适合运行在嵌入式平台之上。首先这类轻量级的计算平台根本就放不下也运行不起来 VGG 这种大模型。更重要的是,由于这类计算平台本身的计算强度上限就很低,可能比 MobileNet 的计算强度还要小,因此 MobileNet 运行在这类计算平台上的时候,它就不再位于 Memory-Bound 区域,而是农奴翻身把歌唱的进入了 Compute-Bound 区域,此时 MobileNet 和 VGG16 一样可以充分利用计算平台的算力,而且内存消耗和计算量都小了一两个数量级,同时分类准确率只下降了1%,所以大家才愿意用它。
所以说,屠龙时用屠龙刀,日常吃鸡用小刀就可以了,否则只会弄巧成拙。
感谢 @谭伟 所指出的:Roofline 模型讲的是程序在计算平台的算力和带宽这两个指标限制下,所能达到的理论性能上界,而不是实际达到的性能,因为实际计算过程中还有除算力和带宽之外的其他重要因素,它们也会影响模型的实际性能,这是 Roofline Model 未考虑到的。例如矩阵乘法,会因为 cache 大小的限制、GEMM 实现的优劣等其他限制,导致你几乎无法达到 Roofline 模型所定义的边界(屋顶)。
05
本文系统的介绍了:
1.计算平台的两个指标:算力和带宽。
2.模型的两个指标:计算量和访存量。
3.使用 Roof-line Model 分析模型在计算平台上所能达到的理论计算性能,并分析模型在计算平台上的两种互斥状态:计算受限状态和带宽受限状态。
4.以 VGG16 和 MobileNet 为例,在 1080Ti 计算平台上分析对比它们的计算性能。
欢迎大家指正。
猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》