
自动化机器学习(AutoML)入门简介
导读
近期在学习研究一些关于自动化机器学习方面的论文,本文作为该系列的第一篇文章,就AutoML的一些基本概念和现状进行简单分享,权当抱砖引玉。
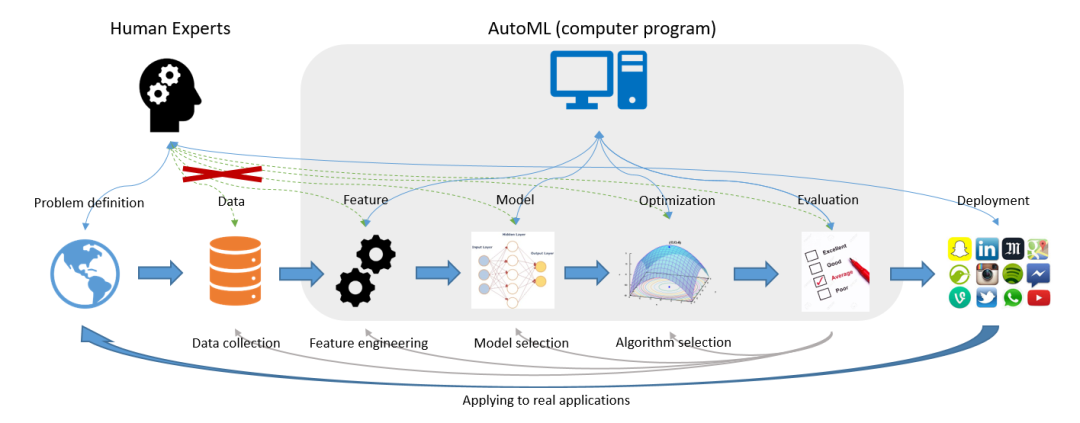
图片源自《Taking Human out of Learning Applications: A Survey on Automated Machine Learning》2018
在算法行业有这样一句话,大意是说80%的时间用在做数据清洗和特征工程,仅有20%的时间用来做算法建模,其核心是在说明数据和特征所占比重之大。与此同时,越来越多的数据从业者们也希望能够降低机器学习的入门门槛,尤其是降低对特定领域的业务经验要求、算法调参经验等。基于这一背景,AutoML应运而生。
如何理解AutoML呢?从字面意思来看,AutoML即为Auto+ML,是自动化+机器学习两个学科的结合体;从技术角度来说,则是泛指在机器学习各阶段流程中有一个或多个阶段采取自动化而无需人工参与的实现方案。例如在本文开篇引用的AutoML经典图例中:其覆盖了特征工程(Feature Engineering)、模型选择(Model Selection)、算法选择(Algorithm Selection)以及模型评估(Model Evaluation)4个典型阶段,而仅有问题定义、数据准备和模型部署这三部分工作交由人工来实现。
数据从业者的懒惰。俗话说,懒惰是人类进步的源动力,这一点在AutoML这件事上体现的淋漓尽致。因为数据从业者们渴望从繁杂冗长的数据清洗、特征工程以及调参炼丹的无趣过程中解脱出来,自然而然的想法就是希望这一过程能够Auto起来!当然,这一过程也可正面解读为对技术精进的不懈追求…… 对降低ML入门门槛的期盼。毫无疑问,以机器学习为代表的AI行业是当下最热门技术之一,也着实在很多场景解决了不少工程化的问题,所以越来越多的数据从业者投身其中。但并不是每名算法工程师或者数据科学家都有充分的业务经验和炼丹技巧,所以更多人是希望能够降低这一入门门槛,简化机器学习建模流程。 足够的数据体量和日益提升的算法算力。客观来讲,没有足够的数据量谈Auto是不切实际的,因为不足以学到足够的知识以实现Auto;而另一方面,AutoML的实现过程其实充满了大量的迭代运算,所以完成单次的AutoML意味着约等于成百上千次的单次ML,其时间成本不得不成为AutoML领域的一个不容忽视的约束条件,而解决这一问题则一般需依赖优秀的算法和充足的算力。
模型选择(Model Selection)以及超参优化(HPO)。这两个阶段可能是AutoML里最早涉及和最为关键的技术,早期的AutoML产品/工具其实也是主攻这两个方向,例如Auto-WEKA和Auto-Sklearn就都是以这两方面的实现为主。其中模型选择其实主要还是枚举为主,即将常用的模型逐一尝试而后选出最好的模型或其组合。而HPO则相当于是加强版的GridSearch,都是解决最优超参数的问题,只是解决的算法不同罢了,其中基于贝叶斯的超参优化是主流。 自动化特征工程(AutoFE)。AutoFE是解决原始特征表达信息不充分或者存在冗余的问题,相应的解决方案就是特征衍生+特征选择,而AutoFE一般是考虑这两个过程的联合实现抑或加一些创新的优化设计。 元学习(Meta Learning)和迁移学习(Transfer Learning)。前面提到的模型选择,虽然多数产品都是对候选模型进行枚举尝试,但也有更为优秀的实现方案,那就是元学习。例如Auto-Sklearn中其实是集成了元学习的功能,在处理新的数据集学习任务时可以借鉴历史任务而会自动选择更为可能得到较好性能的模型,这个过程也称之为warn-start。如果说元学习适用于经典机器学习算法,那么迁移学习其实则主要适用于深度学习技术:通过对历史任务的学习经验对后续类似场景的神经网络架构设计提供一定的先验信息。 神经网络架构搜索(NAS)。同样是针对深度学习的神经网络架构,当没有任何经验可供迁移时,那么如何设计和构建神经网络架构就是一个需要慎重考虑的问题。对此的解决方案即为NAS——neural architecture search!
相关阅读:
评论