
【DS with Python】DataFrame的合并、分组聚合与数据透视表
本节主要介绍数据处理过程中Pandas的常见模块与DataFrame的常见处理方法,建议参数问题可以查查在API reference中有各个功能的详细参数与具体介绍
一、DataFrame的合并
1.1 按列名合并 (pd.merge())
如果需要将两个DataFrame合并,我们可以用pandas中的merge功能
pd.merge(df1,df2,how='inner',on=None,left_index=False,right_index=False,left_on=None,right_on=None,suffixes=('_x', '_y'))
常用的参数:df1和df2是两个DataFrame,how是连接方式,on是按哪一列进行合并,也可以传入一个list,用Multi-index来合并,如果需要合并的列在两张表名字不同,可以用left_on和right_on参数,如果想用index来合并,可以选择left_index=True或者right_index=True。如果两张表中的列名是一样的,新表中来自df1的列名会自动在最后添加'_x',来自df2的列名会自动在最后添加'_y',可以在suffixes中修改。
如何合并?假设我们有两个DataFrame,分别是学生students和职工staff,那我们有几种合并方式?
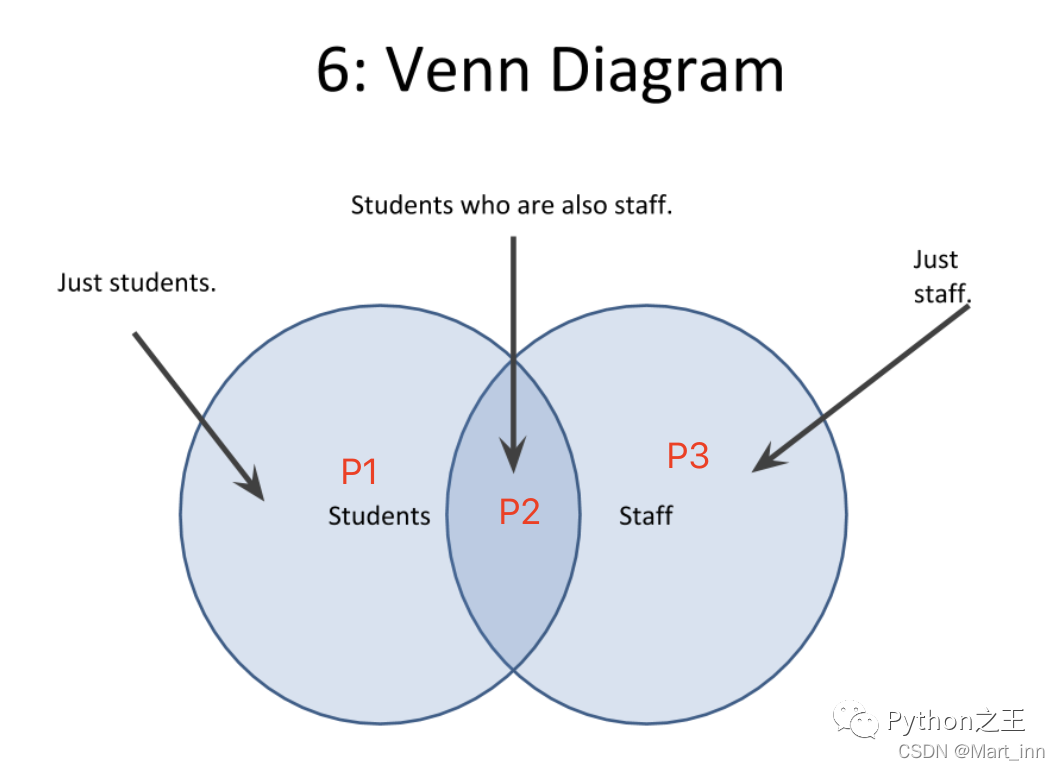 假设我们以Students为df1,staff为df2 (注意:此处P2包含了Student的数据和Staff的数据,直白来说P1+P2不等于Student) 1.只要交集部分P2,可以用内连接,
假设我们以Students为df1,staff为df2 (注意:此处P2包含了Student的数据和Staff的数据,直白来说P1+P2不等于Student) 1.只要交集部分P2,可以用内连接,how='inner'2.要整个图形P1+P2+P3, 可以用外连接,how='outer'3.只要包含所有学生部分P1+P2,可以用左连接,how='left'4.只要包含所有职工部分P2+P3,可以用右连接,how='right'
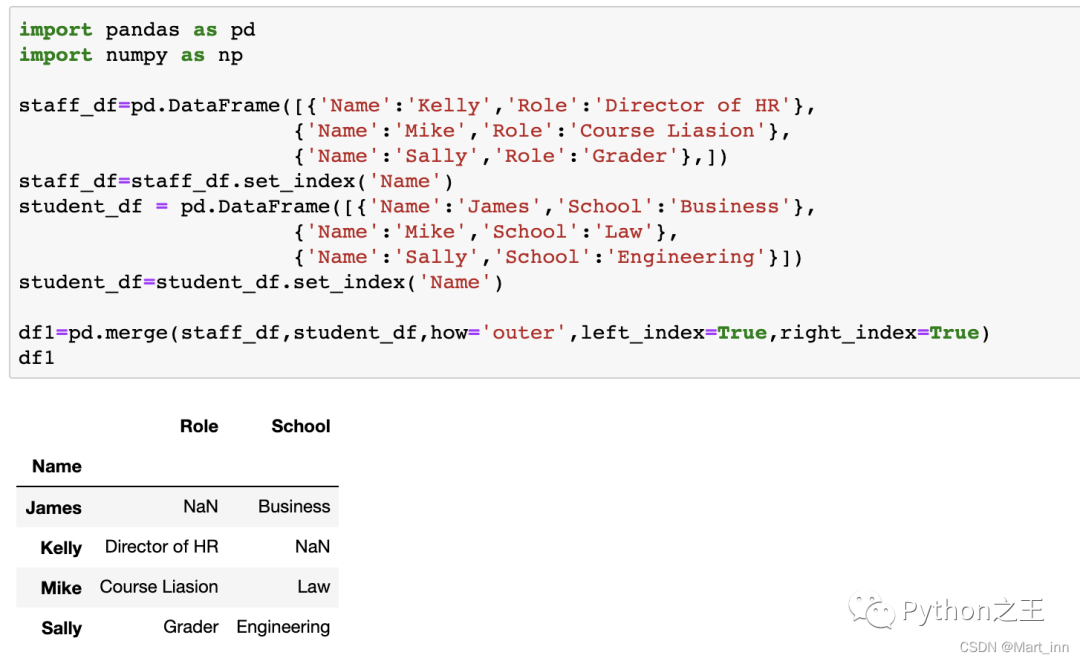
例如,在学校中有的人既是老师,有是职工,我们想要得到所有的人员名单,可以用outer模式来合并,空值会用NaN代替:
import pandas as pd
import numpy as np
staff_df=pd.DataFrame([{<!-- -->'Name':'Kelly','Role':'Director of HR'},
{<!-- -->'Name':'Mike','Role':'Course Liasion'},
{<!-- -->'Name':'Sally','Role':'Grader'},])
staff_df=staff_df.set_index('Name')
student_df = pd.DataFrame([{<!-- -->'Name':'James','School':'Business'},
{<!-- -->'Name':'Mike','School':'Law'},
{<!-- -->'Name':'Sally','School':'Engineering'}])
student_df=student_df.set_index('Name')
df1=pd.merge(staff_df,student_df,how='outer',left_index=True,right_index=True)
df1
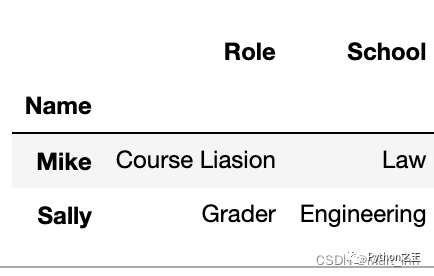
 如果我们想要查看所有学生,并看看他们是否有教职,那就把student_df看作df1并用inner连接
如果我们想要查看所有学生,并看看他们是否有教职,那就把student_df看作df1并用inner连接
df1=pd.merge(staff_df,student_df,how='inner',left_index=True,right_index=True)
df1
 如果学生有姓和名,可以用list来做
如果学生有姓和名,可以用list来做on的参数连接
staff_df = pd.DataFrame([{<!-- -->'First Name': 'Kelly', 'Last Name': 'Desjardins',
'Role': 'Director of HR'},
{<!-- -->'First Name': 'Sally', 'Last Name': 'Brooks',
'Role': 'Course liasion'},
{<!-- -->'First Name': 'James', 'Last Name': 'Wilde',
'Role': 'Grader'}])
student_df = pd.DataFrame([{<!-- -->'First Name': 'James', 'Last Name': 'Hammond',
'School': 'Business'},
{<!-- -->'First Name': 'Mike', 'Last Name': 'Smith',
'School': 'Law'},
{<!-- -->'First Name': 'Sally', 'Last Name': 'Brooks',
'School': 'Engineering'}])
pd.merge(staff_df, student_df, how='inner', on=['First Name','Last Name'])
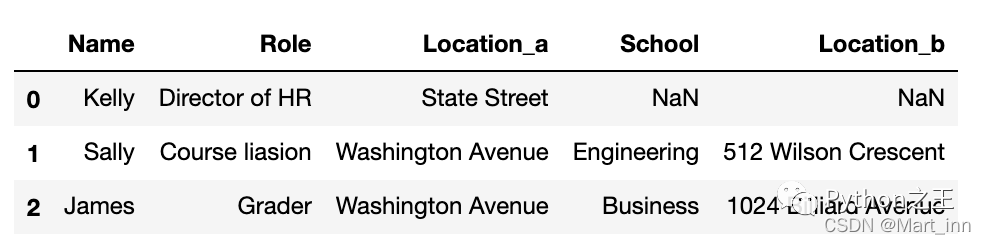
 如果有两列的名字是相同的,df1的列名会添加_x,df2则添加_y,当然也可以在suffixes参数中调整例如
如果有两列的名字是相同的,df1的列名会添加_x,df2则添加_y,当然也可以在suffixes参数中调整例如suffixes=('_a','_b')
staff_df = pd.DataFrame([{<!-- -->'Name': 'Kelly', 'Role': 'Director of HR',
'Location': 'State Street'},
{<!-- -->'Name': 'Sally', 'Role': 'Course liasion',
'Location': 'Washington Avenue'},
{<!-- -->'Name': 'James', 'Role': 'Grader',
'Location': 'Washington Avenue'}])
student_df = pd.DataFrame([{<!-- -->'Name': 'James', 'School': 'Business',
'Location': '1024 Billiard Avenue'},
{<!-- -->'Name': 'Mike', 'School': 'Law',
'Location': 'Fraternity House #22'},
{<!-- -->'Name': 'Sally', 'School': 'Engineering',
'Location': '512 Wilson Crescent'}])
pd.merge(staff_df, student_df, how='left', on='Name',suffixes=('_a','_b'))
1.2 相同列添加行数 (pd.concat()功能)
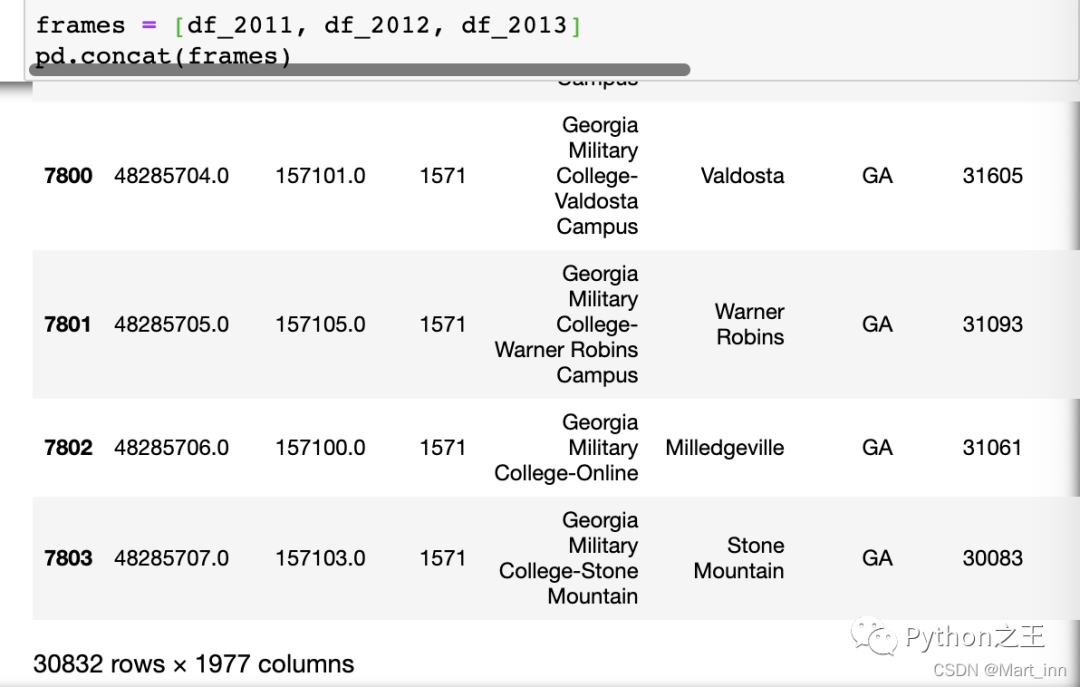
例如,我们将同一个指标的2011年、2012年和2013年的数据合并到一张表中,可以用pd.concat()功能,如下:
frames = [df_2011, df_2012, df_2013]
df=pd.concat(frames)
print(len(df_2011)+len(df_2012)+len(df_2013))
df

二、应用 (.apply()功能)
DataFrame和Series都可以应用.apply()功能,语法为:df.apply() Series.apply() ,在apply中的参数主要是函数,可以是def定义函数,也可以是lambda函数。为了用好apply()功能,需要了解以下问题:
apply()传入参数到底是什么?对于Series使用apply()功能是将Series中的每一个元素作为传入参数放入apply中的函数中,返回单值。 而对DataFrame使用apply()功能,是将DataFrame中的每一个Series作为传入参数放入apply中的函数中,返回Series。
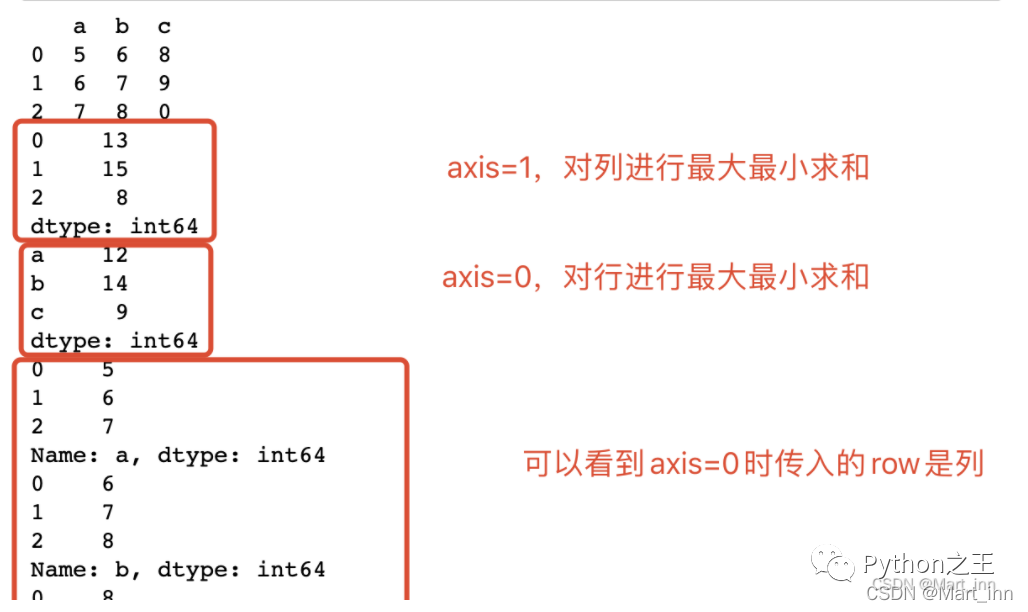
注意:前面我们讲到,DataFrame中的row和columns实际上只是名字不同而已,在DataFrame中的格式和地位都是一样的,所以DataFrame可以传入每一行的Series(对列进行apply,利用apply()功能中的参数axis=1)也可以传入每一列的Series(对行进行apply,利用axis=0,这个是默认值,即如果不加axis参数,apply()功能会将按列传入Series),用两个例子来说明:
import pandas as pd
import numpy as np
dic={<!-- -->'a':[5,6,7],'b':[6,7,8],'c':[8,9,0]}
df=pd.DataFrame(dic)
print(df)
f = lambda x: x.max() + x.min()
def show_series(row):
print(row)
print(df.apply(f,axis=1))
print(df.apply(f,axis=0))
df.apply(show_series)
apply与dict我们知道python的def设计函数的时候可以设定默认参数,参数中有args=()和**kwarge,前者表示可以传入tuple,后者表示可以传入dict,那么我们在设计的时候,利用这一特性,传入字典,这可以帮我们进一步了解apply()的使用,例如我们要设置少数民族加分政策,汉族加0分,回族加10分,藏族加5分(不代表现实生活中真实数据):
data=[{<!-- -->'Name':'张','Nationality':'汉','Score':400},
{<!-- -->'Name':'李','Nationality':'回','Score':450},
{<!-- -->'Name':'王','Nationality':'汉','Score':460}]
df=pd.DataFrame(data)
def add_extra2(nationality,**kwargs):
return kwargs[nationality]
df['extra']=df.Nationality.apply(add_extra2,汉=0,回=10,藏=5)
df
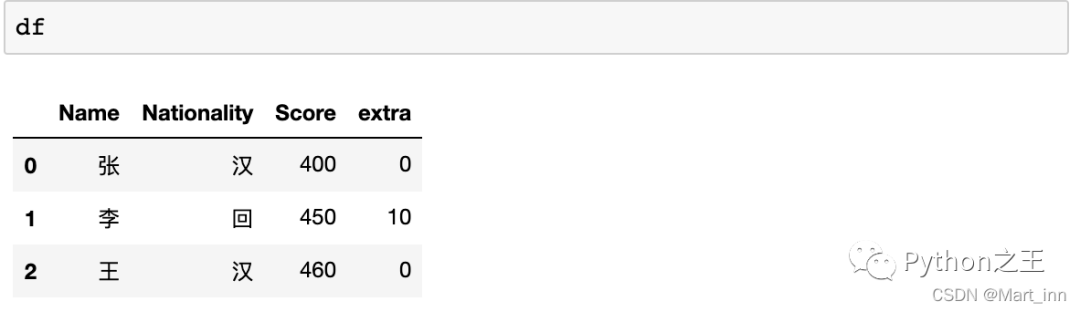 在这里,我们给a的属性是一个dict,对于DataFrame的Nationality列进行apply,传入的就是每一个Nationality的元素,查询字典kwargs中对应的值并返回一个单值,传给df[‘extra’]。
在这里,我们给a的属性是一个dict,对于DataFrame的Nationality列进行apply,传入的就是每一个Nationality的元素,查询字典kwargs中对应的值并返回一个单值,传给df[‘extra’]。
三、分组 (.groupby())
3.1 groupby的原理与返回值
Pandas模块中.groupby() 功能背后的思想是,它获取一些DataFrame,根据一些键值将其拆分(split)为块,对这些块应用(apply)计算,然后将结果合并(combine)回另一个DataFrame。在pandas中,这称为“split-apply-combine”模式,其语法为:
df.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, observed=False, **kwargs)
.groupby()返回的是一个tuple,其中第一个值是用于分类的key值,通常记作group,第二个值是当前key值所对应的DataFrame,通常记作frame。本质上.group()和迭代器计算是很像的,例如以下两段代码,所实现的功能是一样的,但是.groupby()在计算效率上比普通的迭代器要快上不少:
%%timeit -n 3
for group, frame in df.groupby('STNAME'):
avg = np.average(frame['CENSUS2010POP'])
# And print the results
print('Counties in state ' + group +
' have an average population of ' + str(avg))

%%timeit -n 3
for state in df['STNAME'].unique():
avg = np.average(df.where(df['STNAME']==state).dropna()['CENSUS2010POP'])
print('Counties in state ' + state +
' have an average population of ' + str(avg))

接下来通过介绍主要分组依据用到的参数by,就可以对groupby()有良好的理解
在by中设定规则,你可以传入列名,函数,list,dict或者Series首先,最常规的就是像上面的例子中用DataFrame的列名。
第二是用函数,要注意,在调用函数的时候,传入函数中的数据是DataFrame的index,所以要确保之前已经用set_index()功能实现了对index的设置,例如,我们要根据美国的某个州的第一个字母来分组,如果第一个字母为[A-L]则返回0,为[M-P]返回1,其他则返回2:
df = df.set_index('STNAME')
def set_batch_number(item):
if item[0]<'M':
return 0
if item[0]<'Q':
return 1
return 2
for group, frame in df.groupby(set_batch_number):
print('There are ' + str(len(frame)) + ' records in group ' + str(group) + ' for processing.')
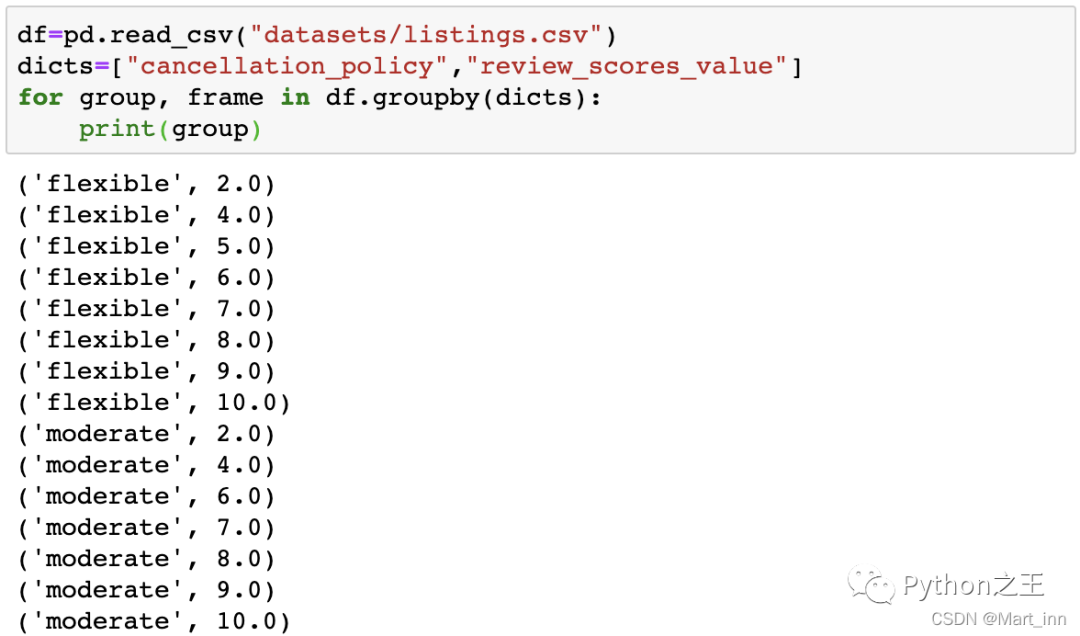
 第三是用list,这用于多重分类的时候,比如我们要按某商品的‘cancellation_policy’和‘review_scores_value’进行分类,可以用如下方法查看分类的依据:
第三是用list,这用于多重分类的时候,比如我们要按某商品的‘cancellation_policy’和‘review_scores_value’进行分类,可以用如下方法查看分类的依据:
df=pd.read_csv("datasets/listings.csv")
dicts=["cancellation_policy","review_scores_value"]
for group, frame in df.groupby(dicts):
print(group)
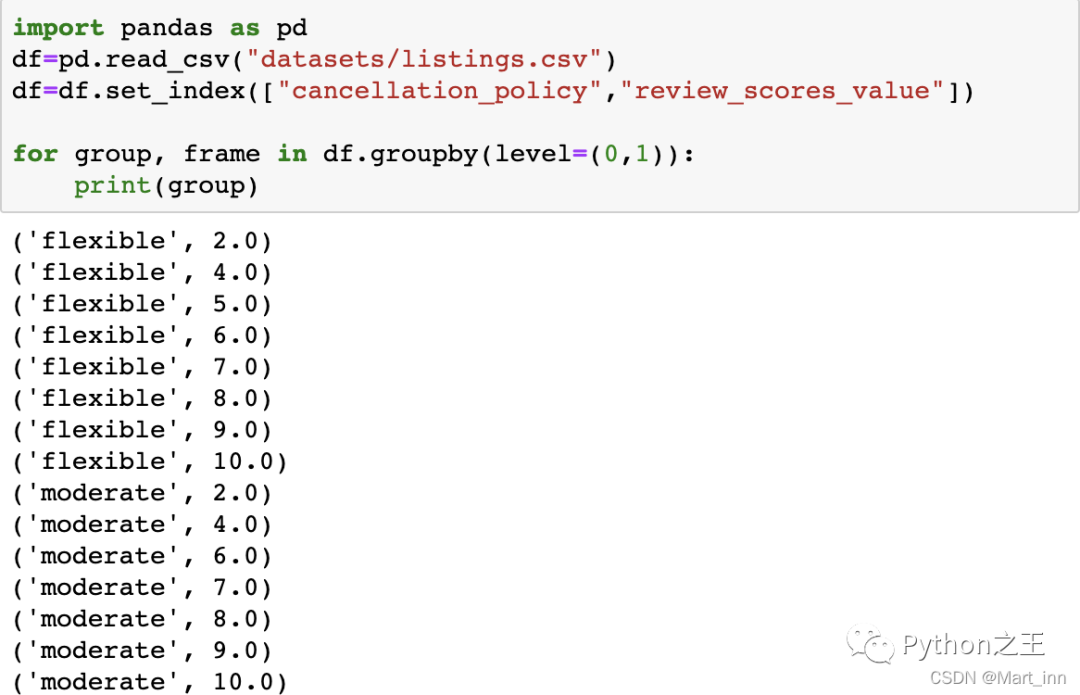
 如果DataFrame是有多重index的,我们可以直接用多重index进行分组,这时需要添加
如果DataFrame是有多重index的,我们可以直接用多重index进行分组,这时需要添加level参数,level参数用于确认index在groupby中的先后顺序
import pandas as pd
df=pd.read_csv("datasets/listings.csv")
df=df.set_index(["cancellation_policy","review_scores_value"])
for group, frame in df.groupby(level=(0,1)):
print(group)
 第四,用Series或者Dict,他和list是很像的,但这往往是对列进行分组,即需要添加
第四,用Series或者Dict,他和list是很像的,但这往往是对列进行分组,即需要添加axis=1,分组时key值是按分组分组,在分组后会将组名改为key值对应的value值
df=pd.read_csv("datasets/listings.csv")
dicts={<!-- -->"cancellation_policy":1,"review_scores_value":2}
for group, frame in df.groupby(dicts,axis=1):
print(group,frame)
3.2 分组后数据聚合 (.agg())
agg的语法为:df.groupby()['列名'].agg({'列名':(函数,函数)}) 或者 df.groupby()['列名'].agg([函数,函数]) 注:列名可以紧跟在groupby()后,也可以在agg()内用dict来表示
在将DataFrame分组后,我们可以对分组后的值进行计算,主要包括以下几种:
|函数|作用 |------ |np.min|求最小值 |np.max|求最大值 |np.sum|求和 |np.mean|求评价值 |np.meadian|求中值 |np.std|求标准差 |np.var|求方差 |np.size|分组大小
(当然,忽略np.,直接用mean或者min也是可以的,想要用np.nanmean或者np.nanmax也是可以的)
(注意求平均值不能用np.average,因为他不会忽略NaN值,所以如果数据中有NaN,那么np.average就会给你返回NaN)
例如,我们要求某商品按’cancellation_policy’分类后,计算’review_scores_value’的平均值和方差,并计算’reviews_per_month’的平均值,我们可以用agg函数:
df.groupby('cancellation_policy').agg({<!-- -->'review_scores_value':(np.nanmean,np.nanstd),
'reviews_per_month':np.nanmean})
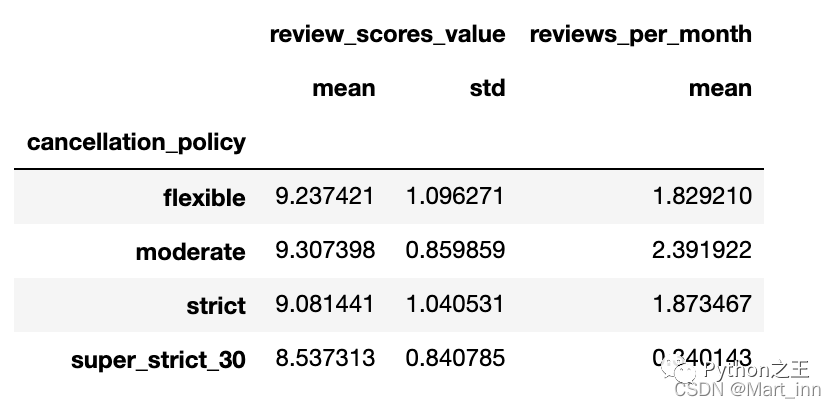 这里我们就能看到多重标签了,在下文会介绍stack()和unstack()来展开、压缩或转换这些多重标签。
这里我们就能看到多重标签了,在下文会介绍stack()和unstack()来展开、压缩或转换这些多重标签。
3.3 分组后数据转换 (.transform())
我们经过对聚合函数agg的练习发现,他对分组进行运算后得到一个单一的值(平均数、最小数、中位数等等)但如果我们要将这个数应用到同一组的所有值上面呢?
第一种方法是用map函数,是可以的,但是我们可以一步到位,就是第二种方法,不用.agg()而用.transform(),他与.agg()最大的区别在于:
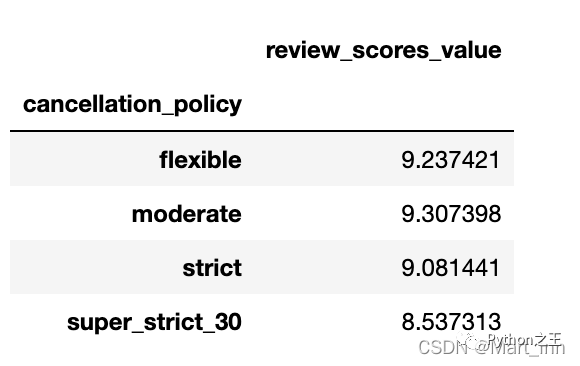
agg()每个组只返回一个值。- tranform()返回与组大小相同的对象。举一个例子,我们将商品按’cancellation_policy’分类后,要查看’review_scores_value’的平均值,如果用agg()会得到以下结果,四个组,一个组对应一个值:
cols=['cancellation_policy','review_scores_value']
transform_df=df[cols].groupby('cancellation_policy').agg(np.nanmean)
transform_df
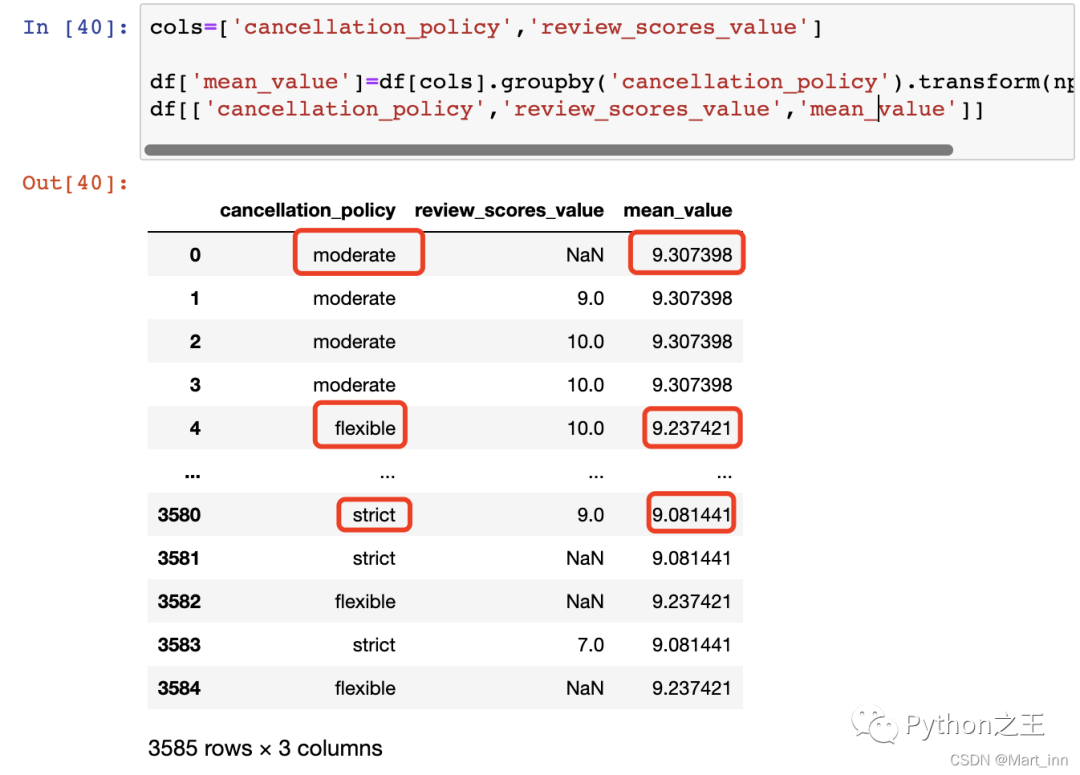
但如果用.transform(),那么所有条数的数据的对应的平均值就都出来了:
cols=['cancellation_policy','review_scores_value']
df['mean_value']=df[cols].groupby('cancellation_policy').transform(np.nanmean)
df[['cancellation_policy','review_scores_value','mean_value']]
3.4 分组后数据过滤 (.filter())
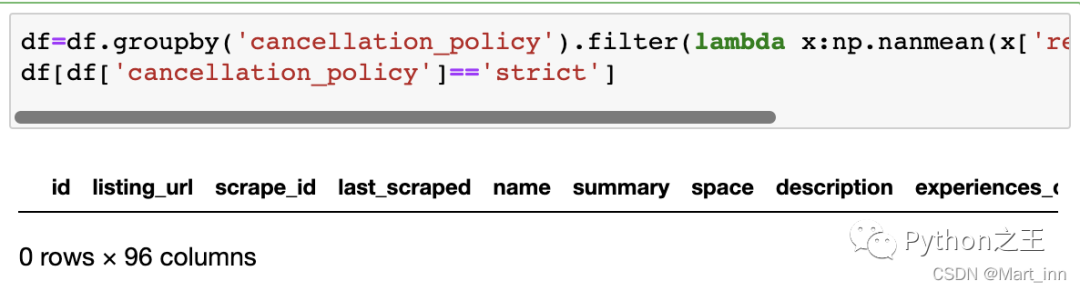
如果想删掉某些数据,用.filter()就可以了,比如我们要把所有平均值>9.2的数据筛选,用lambda函数和filter就可以了,比如我们看到按strict分组后的平均值9.08,那我们看看筛选完后是否还能查到:
df.groupby('cancellation_policy').filter(lambda x:np.nanmean(x['review_scores_value'])>9.2)
df[df['cancellation_policy']=='strict']
3.5 分组后应用 (.apply())
.apply()函数功能也可以用在分组的结果后,与第二章用法一致,要注意,在apply()中调用函数时,传入的参数是.groupby()中返回的frame。
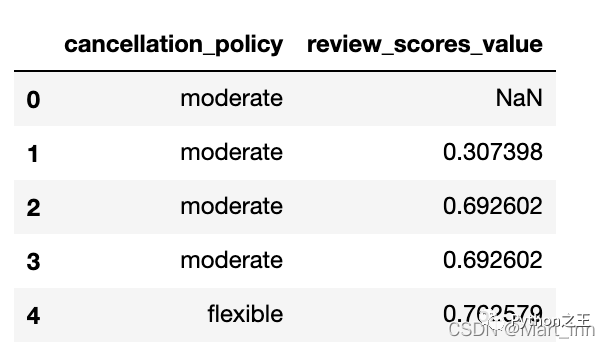
例如,我们想查看按’cancellation_policy’分组后’review_scores_value’与平均值的差,可以写一个calc_mean_review_scores()的函数来实现:
df=pd.read_csv("datasets/listings.csv")
df=df[['cancellation_policy','review_scores_value']]
def calc_mean_review_scores(group):
#print(group)##传入的是.groupby()后的frame
avg=np.nanmean(group['review_scores_value'])
group['review_scores_value']=np.abs(avg-group['review_scores_value'])
return group
df.groupby('cancellation_policy').apply(calc_mean_review_scores).head()
四、数据尺度 (Data Scales)
4.1 四种尺度
在统计学中,主要有四种尺度:
Ratio Scale 等比尺度 可以用等比尺度来测量的变量,属性:任意位置的单位距是相等的;数学运算的+ - * / 都是有效的;没有真0值,0表示测量值不存在,例如:身高、体重。1. Interval Scale 等距尺度 数值之间的单位间隔是等距的一种尺度,存在真0值,例如:年份、温度。1. Ordinal Scale 次序尺度 根据事物的特征对其进行等级排序的一种尺度,属性:每一个数据有特殊含义;有从小到大的顺序,但是间距未必是均匀的。例如:考试等级、用户评价。1. Nominal Scale (or Categorical Data) 名目尺度 根据事物的特征对其进行分类。不具有等级排序。例如,队伍的名称、性别。前两种是连续的,而后两种是离散的。
在DataFrame中默认的是名目尺度,查看DataFrame的type,即dtype往往发现是’object’类型:
import pandas as pd
df=pd.DataFrame(['A+', 'A', 'A-', 'B+', 'B', 'B-', 'C+', 'C', 'C-', 'D+', 'D'],
index=['excellent', 'excellent', 'excellent', 'good', 'good', 'good',
'ok', 'ok', 'ok', 'poor', 'poor'],
columns=['Grades'])
df.dtypes
--Outputs:
Grades object
dtype: object
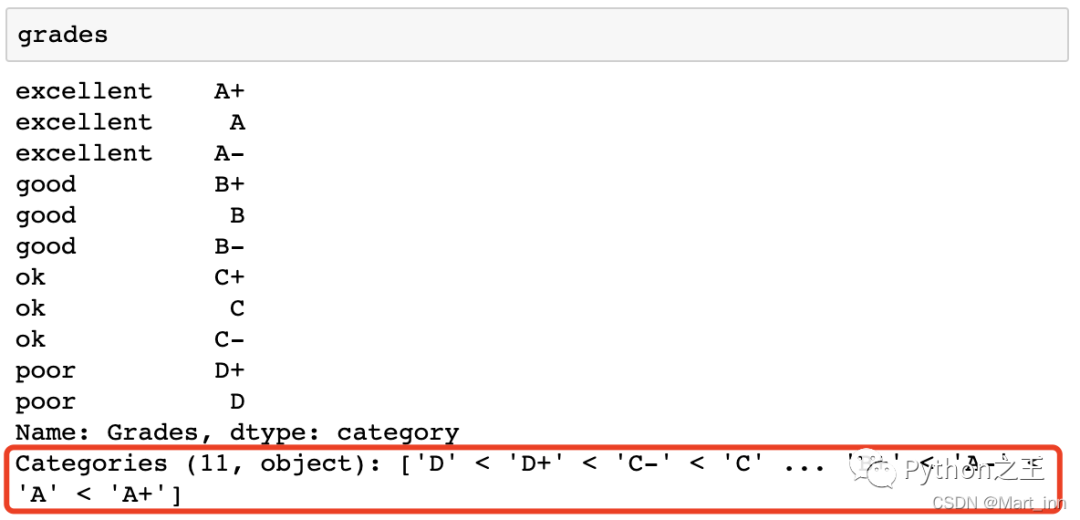
如果我们想把Categorical Data改成Ordinal Data,我们可以用.astype('category'),但此时,我们是没有定义顺序的,要给定顺序,需要调用pd.CategoricalDtype来实现,如下所示
df['Grades'].astype('category')
my_categories=pd.CategoricalDtype(categories=['D', 'D+', 'C-', 'C', 'C+', 'B-', 'B', 'B+', 'A-', 'A', 'A+'],
ordered=True)
grades=df['Grades'].astype(my_categories)
 我们要查看比C大的类型可以直接用
我们要查看比C大的类型可以直接用grades[grades>'C']来实现: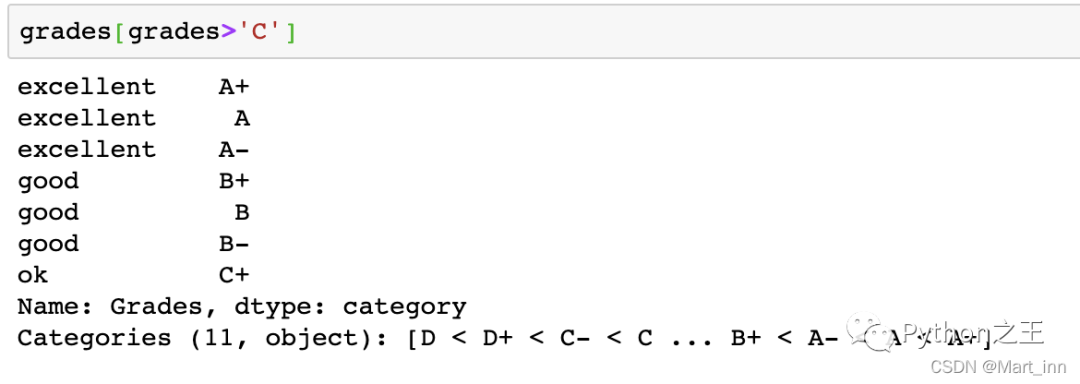
4.2 转化等距/等比尺度为次序尺度 (pd.cut())
事实上,我们常常把等距或等比尺度上的事物,进行等级化,形成次序尺度。这听起来很费解,举个例子来说,在研究某个事情的频率或者其分布区间的时候,我们在数据可视化时会考虑利用到直方图来实现,这是实际上就是对原本的等距或等比的数据进行了重新的分类。这种分类会降低数据的维度,但降维后的数据会有其额外应用价值(比如用于机器学习中的标签分类)
Pandas中我们用到pd.cut()来实现对数据的等距分割,例如我们要计算美国每个州2010年的各个城市的平均人口统计数据
import numpy as np
import pandas as pd
df=pd.read_csv("datasets/census.csv")
#reduce data
df=df[df['SUMLEV']==50]
df=df.set_index('STNAME').groupby(level=0)['CENSUS2010POP'].agg(np.average)
df.head()
 接下来用
接下来用pd.cut(df,10),我们就可以得到10个等距的范围,并看到各个州分别在哪个范围之内: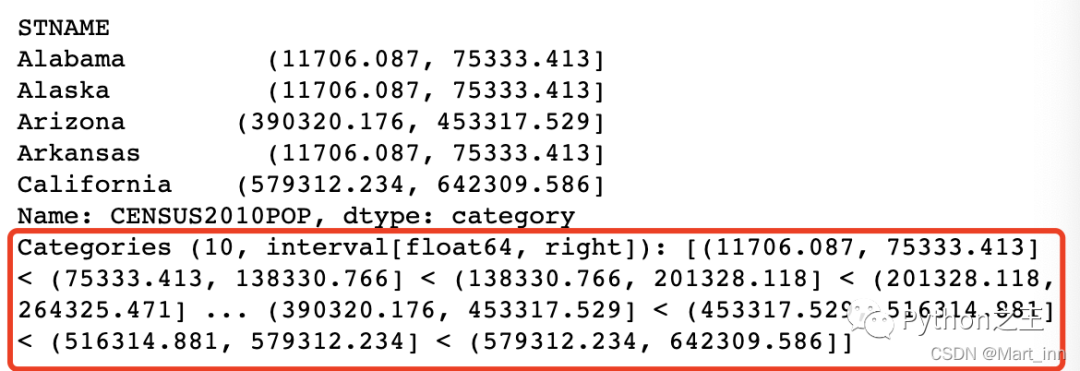
五、数据透视表(Pivot Table)
5.1 数据透视表的理论
Pandas中的数据透视表是处于特定目的对数据进行汇总,并用DataFrame格式表现的一种方法。他高度依赖聚合函数。 数据透视表本身也是一个DataFrame,他的行代表一个你感兴趣的变量,列代表另一个你感兴趣的变量,中间的每一个格子上是某个聚合函数的数值。有的数据透视表还会包含边界值(merginal value),可能是每一行或者每一列的和,让你能够快速的查看两个变量之间的关系。
5.2 创建数据透视表(.pivot_table())
在创建数据透视表的时候,我们需要明确两个变量一个值和至少一个聚合函数:
索引变量1. 列变量1. 待聚合的值1. 聚合函数 pandas会根据两个变量按索引变量进行分组,对待聚合的值进行聚合函数,并将输出值放在将每一个格子中,语法如下(也可以用pd.pivot_table(DataFrame,...)的形式创建):
df.pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False, sort=True)
这里常用的几个参数:value就是待聚合的值,index就是索引变量(可以双重变量),columns就是列变量(可以双重变量),aggfunc是可以给list用以一次性进行多种聚合操作,如果列变量选了双重变量,也可以给dict,即margins表示边界值,默认是FALSE,名字默认为’ALL’可以在margins_name修改。
例如,我们要对不同国家(索引变量) 不同等级的高校(列变量)(分一等、二等、三等和其他)根据总得分的评分值和最大值(待聚合值)绘制数据透视表,并给出边界值:
df.pivot_table(values='score', index='country', columns='Rank_Level', aggfunc=[np.mean, np.max], margins=True).head()
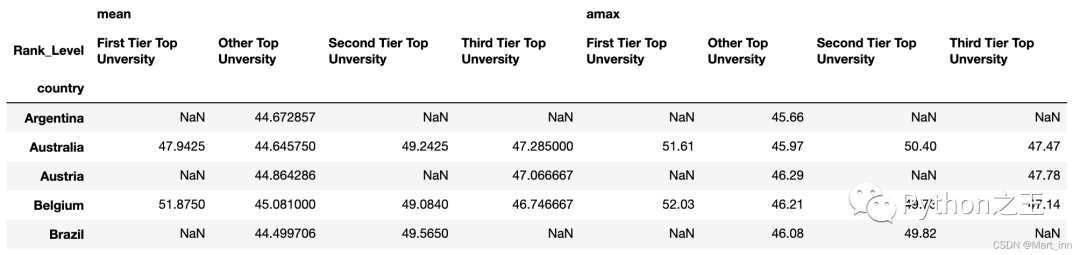
5.3 查询数据透视表
在这里我们发现,返回的DataFrame的列名实际上是MultiIndex,第一层是mean和max,第二层是大学的四个等级,如果需要查询里面某一行的值,也只要按这个顺序来查询即可:
new_df['mean']['First Tier Top Unversity'].head()
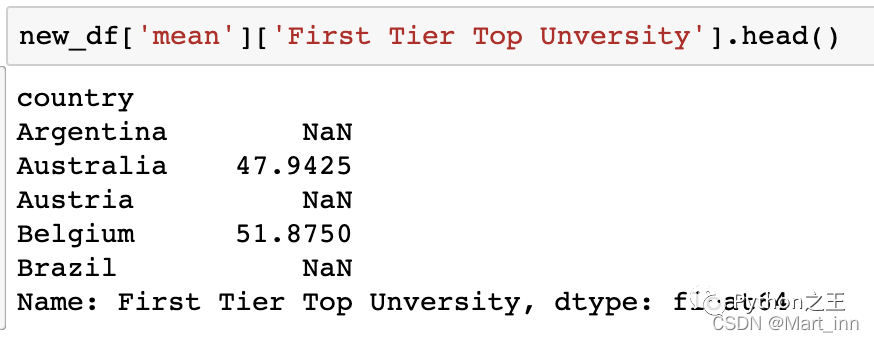 我们发现这实际上是一个Series的格式,那么我们在Series中用到的定位最大值或者最小值的函数
我们发现这实际上是一个Series的格式,那么我们在Series中用到的定位最大值或者最小值的函数.idxmax()和.idxmin()就可以在这使用:
print(new_df['mean']['First Tier Top Unversity'].idxmax())
print(new_df['mean']['First Tier Top Unversity'].idxmin())

5.4 更换数据透视表的形状( .stack() & .unstack() )
我们看到前面的数据透视表中,mean、max和四个大学是列变量,而城市是索引变量,但如果我们想要让城市变成列变量,其他变成索引变量呢?我们先介绍两个概念,innermost row index(最细索引变量)和lowermost column index(最细列变量),如下所示: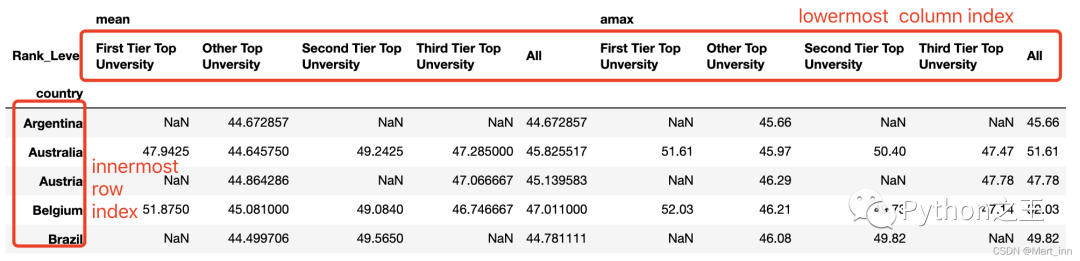
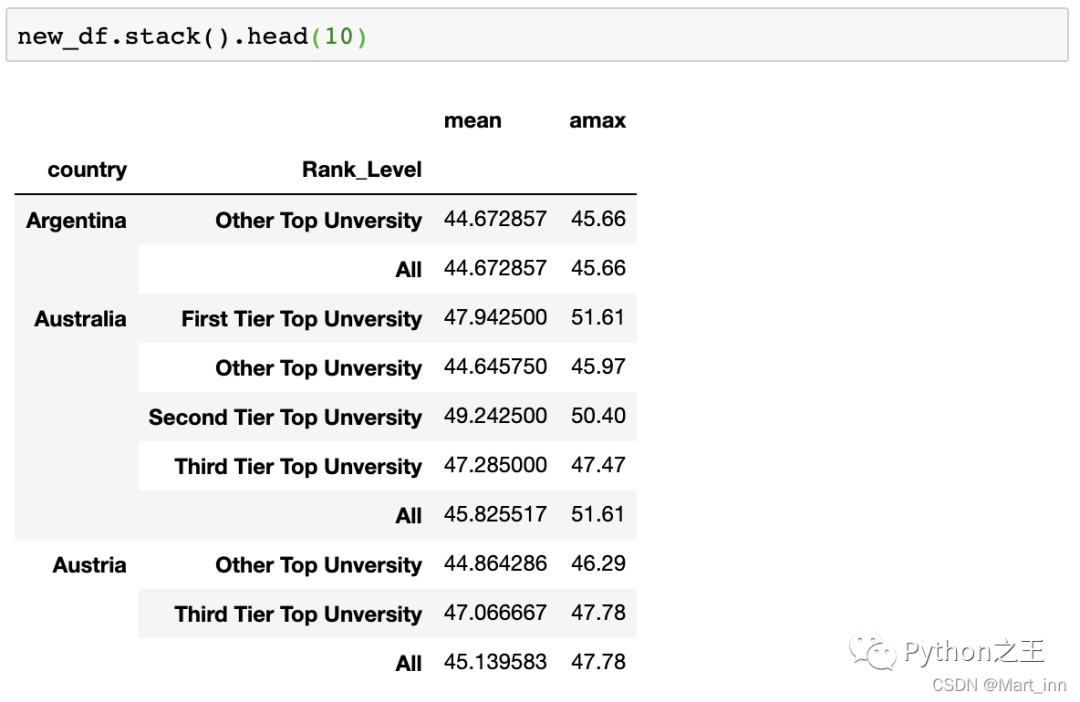
.stack()数据透视表中有一个功能是.stack(),简而言之,它会把最细的列变量变成最细的索引变量,(注意:此时原来的country变量就不再是innermost row index了)中,如下:
new_df.stack().head(10)
 我们可以看到,本来在mean和max下的四个大学等级就到了索引变量下,形成了MultiIndex,再次进行
我们可以看到,本来在mean和max下的四个大学等级就到了索引变量下,形成了MultiIndex,再次进行.stack()
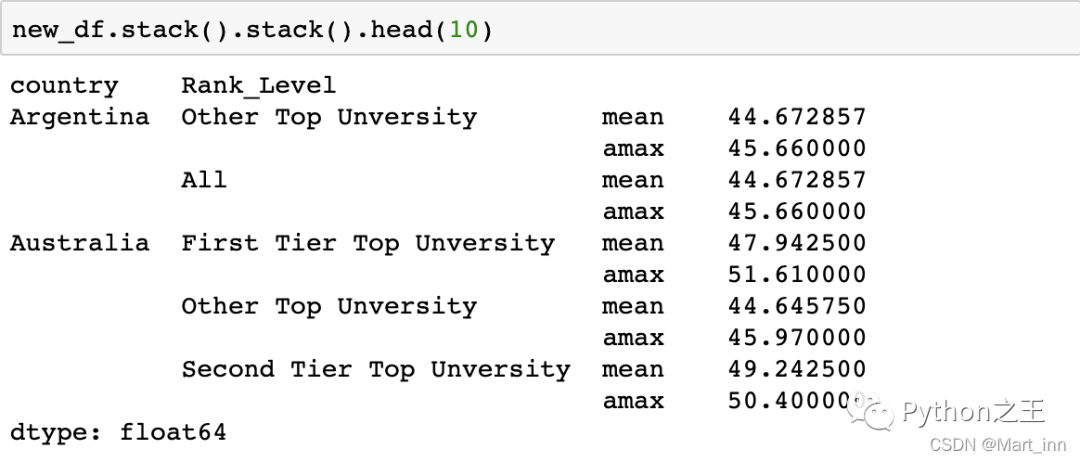 这次连mean和max都到了索引下面去了。
这次连mean和max都到了索引下面去了。
.unstack()有stack,自然就有.unstack(),unstack()与stack()相反,它会把最细的索引变量放到列变量去,我们对new_df进行.unstack()操作看看会发生什么:
new_df.unstack()
 有没有很奇怪,为什么变成了一个Series?
有没有很奇怪,为什么变成了一个Series?
还记得我们说过DataFrame中row和columns实际上是等价的,在这里,所有的索引变量都到列变量去了,没了索引变量,DataFrame自然就成了一个原DataFrame中列变量作index的Series,这时如果把这个Series想象成一般形式的DataFrame,那这三个index也可以看作新的DataFrame中的index,所以,如果我们再进行一次.unstack(),它就会又变成DataFrame了:
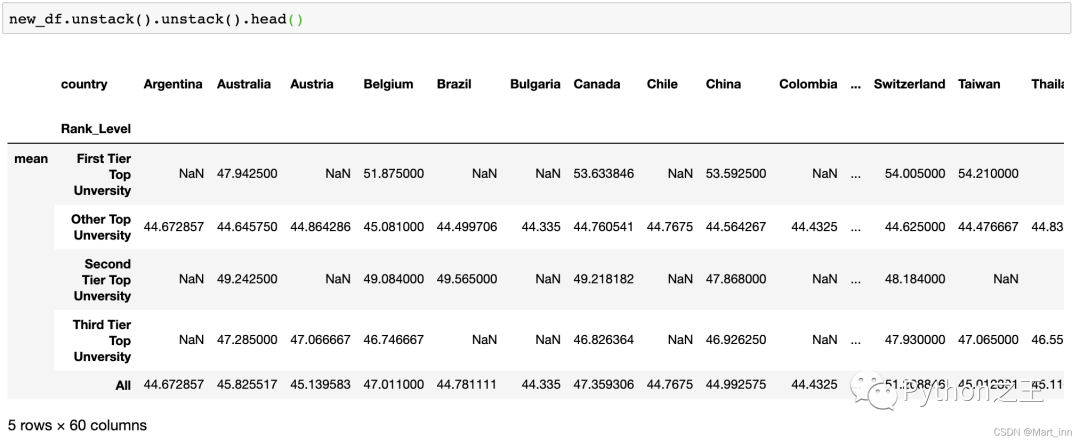 在这里我们就可以看到,原本Series中的最细的index:country就变成了列变量,所以,理论上我们可以添加若干个
在这里我们就可以看到,原本Series中的最细的index:country就变成了列变量,所以,理论上我们可以添加若干个.unstack(),依旧能得到DataFrame,但若干个.stack()一定是不行的,因为你不能对Series进行.stack():
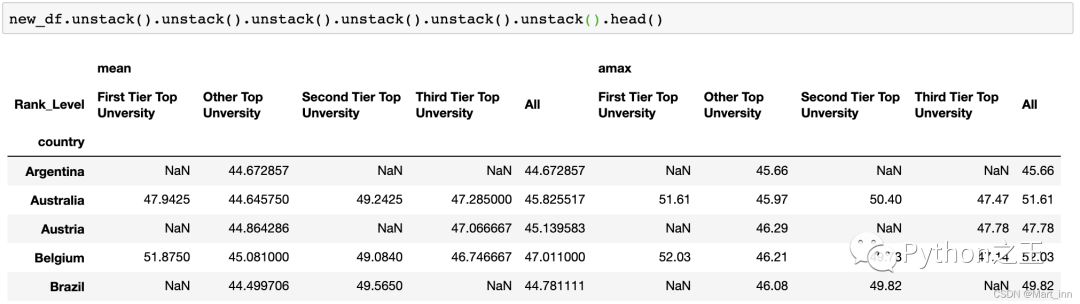
六、Pandas里的时间(Date/Time Functionality)
pandas中的时间函数主要分为四个class:
Timestamp, Period, 以及这两种时间所对应的index:Datetimeindex和Periodindex。
6.1 时间戳(pd.Timestamp()与.isoweekday())
如果想创建一个时间戳,利用pd.Timestamp()就可以了:
pd.Timestamp('9/1/2019 10:05AM')
pd.Timestamp('2019/1/20 10:05AM')
pd.Timestamp('2019-1-9 10:05AM')
pd.Timestamp('20190109 10:05AM')
pd.Timestamp('01-09-2019 10:05AM')
pd.Timestamp('2021 2 SEPT')
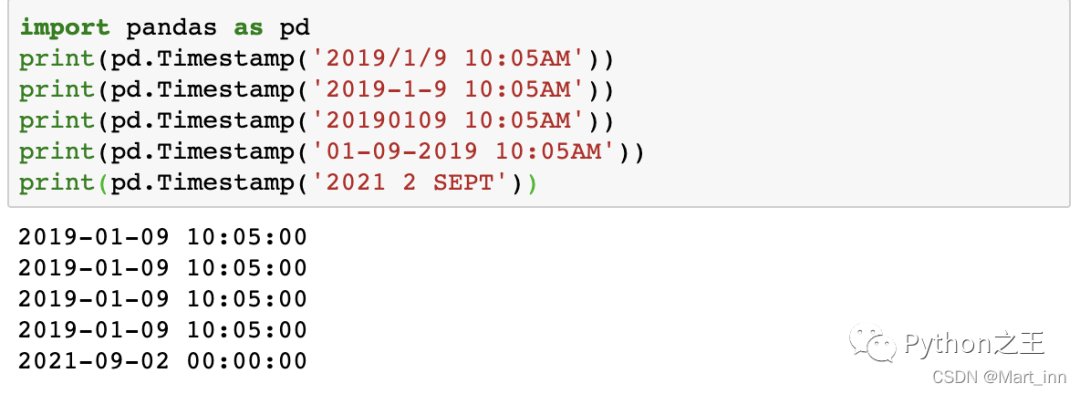
以上几种都是可以的,可以发现Pandas支持欧式时间表达式和美式时间表达式,最后得到的都是’yyyy-mm-dd hh:mm:ss’的Timestamp格式 也可以通过直接给’yyyy-mm-dd hh:mm:ss’赋值的方法创建:
pd.Timestamp(2019, 12, 20, 0, 0)
--Outputs:
Timestamp('2019-12-20 00:00:00')
查询的时候直接.year或者.month…就可以查询对应的年/月/日/时/分/秒了。
如果你想知道这是一周的第几天,可以用.isoweekday()功能:
pd.Timestamp(2019, 12, 20, 0, 0).isoweekday()
--Outputs:
5
Timestamp也可以用Timedelta来表示时间间隔,和datetime中的timedelta是一样的。
pd.Timestamp('9/3/2016')-pd.Timestamp('9/1/2016')
pd.Timestamp('9/2/2016 8:10AM') + pd.Timedelta('12D 3H')

6.2 周期(pd.Period())
如果我们不是对某个时间点感兴趣而是对某个时间区间感兴趣,可以用pd.Period(),他会自动给时间加上单位,比如’M’表示月’D’表示日,'A-DEC’表示以年为周期,可以对Period()值直接做+ -运算,会在对应周期下进行运算:
pd.Period('2021-02')
pd.Period('2021-02')+2
pd.Period('2021-02-10')+2

6.3 时间索引之(Datetimeindex与PeriodIndex)
如果我们将Timestamp作为Series或者DataFrame的索引,那么其格式是DatetimeIndex,如果我们将Period作为Series或者DataFrame的索引,其格式是
PeriodIndex:
A=[2,3]
time1=pd.Timestamp('2021-09-11')
time2=pd.Timestamp('2021-09-23')
s=pd.Series(A,index=[time1,time2])
type(s.index)
--Outputs:
pandas.core.indexes.datetimes.DatetimeIndex
t1=pd.Period('2021-02')
t2=pd.Period('2021-02')
s=pd.Series(A,index=[t1,t2])
type(s.index)
--Outputs:
pandas.core.indexes.period.PeriodIndex
6.4 转化成时间格式(pd.to_dayetime())
用pd.to_dayetime()可以把各种欧式时间格式、美式时间格式转位一般的’yyyy-mm-dd’格式,如下:
time=['2021-09-10','2019/10/12','2021 2 JUNE','JULY 4, 2021','JANUARY 2 2012']
pd.to_datetime(time)

6.5 pd.offsets
可以在Timestamp后添加pd.offsets来实现某个功能,比如,可以用+pd.offsets.Week()来输出一周后的日期,用+pd.offsets.MonthEnd()来查看本月的月末是哪一天
6.6 时间范围(pd.date_range())
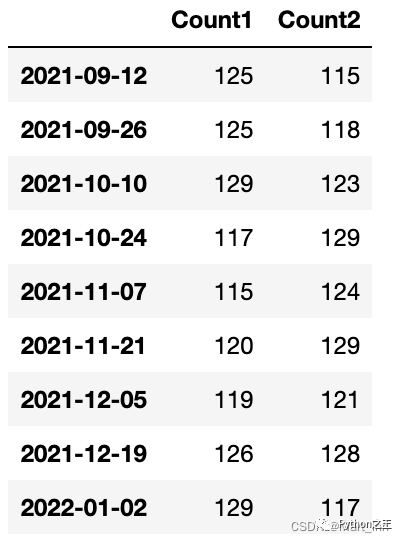
就像生成一个数值列表一样,可以用pd.date_range()来生成一个时间的列表,语法是:pandas.date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs) 设置好起始日期,区间长度periods或者频率freq,tz还可以设置时区,默认’timezone-naive’ 例如,我们想生成2021年9月11日以后每两个周的周末的日期,时间区间长度为9,可以用以下代码:
time1=pd.Timestamp('2021-09-11')
pd.date_range(time1,periods=9,freq='2W-SUN')

可以直接用这个来做DataFrame的index:
time_period=pd.date_range(time1,periods=9,freq='2W-SUN')
data={<!-- -->'Count1':120+np.random.randint(-5,10,9),
'Count2':120+np.random.randint(-5,10,9),
}
dates=pd.DataFrame(data,index=time_period)
6.7 根据Datetime计算每个月的平均值(.resample())
从高频率到低频率可以用resample(),例如我们想计算上面DataFrame中每个月的平均值,可以用:
df.resample('M').mean()



Python“宝藏级”公众号【Python之王】专注于Python领域,会爬虫,数分,C++,tensorflow和Pytorch等等。
近 2年共原创 100+ 篇技术文章。创作的精品文章系列有:
日常收集整理了一批不错的 Python 学习资料,有需要的小伙可以自行免费领取。
获取方式如下:公众号回复资料。领取Python等系列笔记,项目,书籍,直接套上模板就可以用了。资料包含算法、python、算法小抄、力扣刷题手册和 C++ 等学习资料!