
拯救pandas计划(5)——获取DataFrame分组topN数据
拯救pandas计划(5)——获取DataFrame分组topN数据
最近发现周围的很多小伙伴们都不太乐意使用pandas,转而投向其他的数据操作库,身为一个数据工作者,基本上是张口pandas,闭口pandas了,故而写下此系列以让更多的小伙伴们爱上pandas。
系列文章说明:
系列名(系列文章序号)——此次系列文章具体解决的需求
平台:
windows 10 python 3.8 pandas >=1.2.4
/ 数据需求
现有一组数据,需要根据name进行分组,以date_col顺序排序,获取每组数据的前N项数据。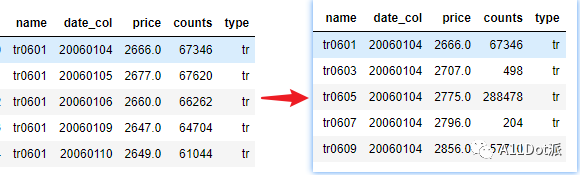
为考虑比较各方案间的耗时,此次数据采用数据类别多量小的数据集。
/ 需求拆解
整个数据框的前几行或者后几行都有相应的方法可以调用,如head()、tail(),分组后的前几行,只需要把整个数据框应用到groupby上再对各个分组进行head()即可,而这里需要取得topN,则分组后不一定能够按顺序取得,故而需要对数据框进行排序。
/ 需求处理
方法一
正如需求拆解里提到过的,使用groupby来完成这部分任务,在取得topN之前是需要对整个数据集进行排序的,这可以先尝试下在groupby之前排序,还是之后排序是否会对整个任务执行时间有影响。
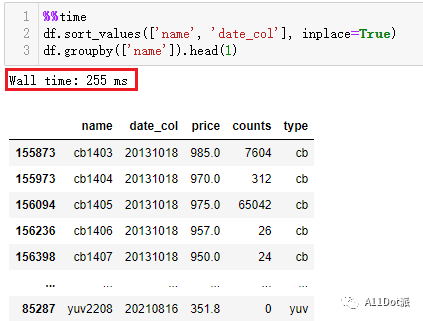
先排序,后分组
df.sort_values(['name', 'date_col'], inplace=True)
df.groupby(['name']).head(1)
先分组,后排序
由于groupby后面不能直接跟sort_values,所以需要调用apply来对每个分组进行排序。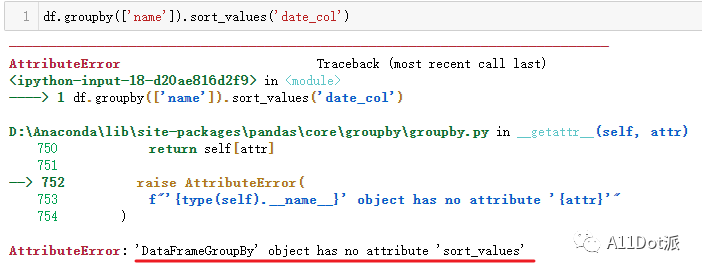
分组后排序用时:
df.groupby(['name']).apply(lambda x: x.sort_values('date_col').head(1)).reset_index(drop=True)
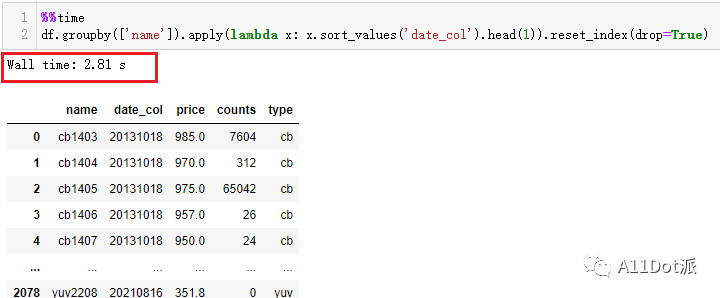 看到这运行时间差了一个数量级,可能会怀疑是不是sort_values的问题,都知道
看到这运行时间差了一个数量级,可能会怀疑是不是sort_values的问题,都知道pandas调用内部函数时运行效率还算是过的去,怎么在这差了这么多,直接在groupby后面运行head()仅200ms,这会可以看看在apply里调用head()。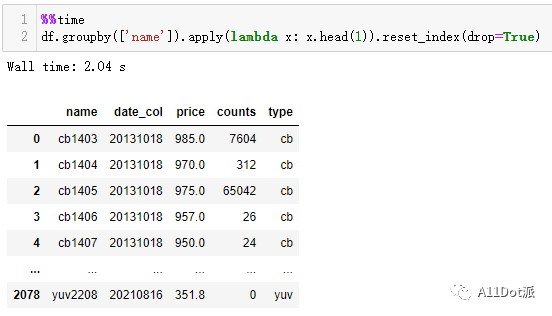 在上图可以看出拖慢运行时间的主要原因不是sort_values,而是apply,虽然apply的工作机制方便了对数据框内的数据进行各种各样的处理操作,但当存在一种内部函数可以满足需求时再选择使用apply就会稍显鸡肋。
在上图可以看出拖慢运行时间的主要原因不是sort_values,而是apply,虽然apply的工作机制方便了对数据框内的数据进行各种各样的处理操作,但当存在一种内部函数可以满足需求时再选择使用apply就会稍显鸡肋。
(手动水印:原创CSDN宿者朽命,https://blog.csdn.net/weixin_46281427?spm=1011.2124.3001.5343,公众号A11Dot派)
简言之,在这种方式处理上,先排序再分组取topN是能够较快的得到目标数据。
方法二
在拯救pandas计划(4)——DataFrame分组条件查找值中有提到过使用drop_duplicates(),同样在这里分组取topN也可以一试,但有限制条件,其drop_duplicates()内的keep参数决定了,仅能保留首个或尾个或者不保留重复数据。因此当只取top1时,可以试用此种方法,在处理时间上也过得去。
df.sort_values(['name', 'date_col'], inplace=True)
df.drop_duplicates(['name']) # 默认保留首个

方法三
虽然说有内部函数直接能达成结果的优先使用内部函数,但在这里不妨想一想如何在不使用groupby的方式求得分组topN。(可以先思考一会儿再继续往下看)
阐述下我的想法,仅做抛砖引玉之用,既然是分组取topN,不就是一种变相的分组排序,取排序靠前的值。以这样的思路,先对组中的每个类型进行计数,再编号即可取得。
计数:
除了groupby外对类型进行计数还有一个好的方法,value_counts,这里需要将sort参数设置为False,避免内部排序影响外部排序,在计数前依然是先对整个数据框进行排序。
df.sort_values(['name', 'date_col'], inplace=True)
name_count = df.value_counts('name', sort=False)
编号:
而后对name_count进行编号,使用lambda调用range(x)。
name_count.map(lambda x: range(x))
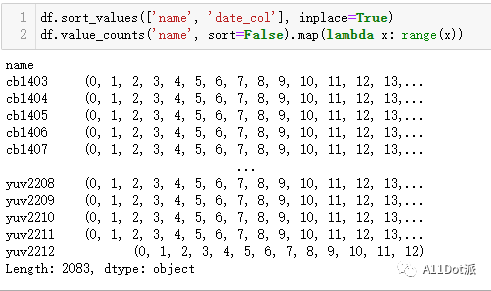 从生成的结果看来,
从生成的结果看来,Series中的values是一个可迭代序列,这种结果不能直接对原始数据框设置编号,取出values,使用np.hstack以行方向组合,对每个分组编号组合成一个一维数组。
import numpy as np
df.sort_values(['name', 'date_col'], inplace=True)
np.hstack(df.value_counts('name', sort=False).map(lambda x: range(x)).values)
 ps:
ps: values中的每个值都是一维数组
取值:
再对生成的值与想要提取的topN的N进行对比,进行布尔索引提取即可得到想要的topN数据。运行结果如下,时间上也能接受: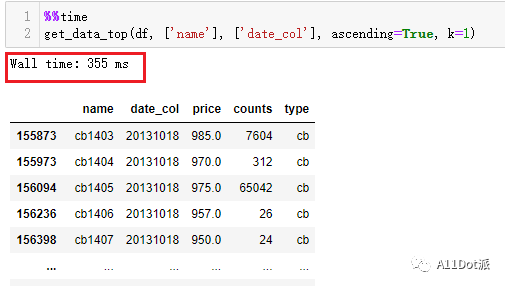 以下是将这段代码进行封装成函数:
以下是将这段代码进行封装成函数:
import numpy as np
import pandas as pd
def get_data_top(data: pd.DataFrame, group_cols: list, val_cols: list, ascending: bool = True, k: int = 1):
"""
自定义获取数据框topN
:param data: pd.DataFrame类型
:param group_cols: list, 需要聚合的列名
:param val_cols: list, 需要排序的列名
:param ascending: 排序方式,默认`True`,顺序排序,接收bool或这个列表里全部为bool的列表
:param k: 取前k项值
:return: 返回topN数据框
"""
# 为了能返回传入数据框的原index,将index保存至values中
datac = data.reset_index().copy()
index_colname = datac.columns[0]
# 对原数据框进行排序
datac.sort_values(group_cols + val_cols, ascending=ascending, inplace=True)
# 主要代码:分组对组内进行编号
rank0 = np.hstack(datac.value_counts(group_cols, sort=False).map(lambda x: range(x)).values)
# 取topN值
datac = datac[rank0 < k]
# 取出原index重置为index值
datac.index = datac[index_colname].values
# 删除额外生成的index值的列
del datac[index_colname]
return datac
ps: 参数冒号后的类型仅做提示,输入其他类型亦能入参,但需要传入正确参数及类型才能正常输出。
/ 总结
文中使用三种方法来取得数据集中的前N项值,过程上略有不同,总的结果呈现也基本相同,在想法及做法上对个人都一种提升。在写这篇之前,我一直在询问我自己,这篇值不值得写下来,把方法三删了改,改了删,起初并没有使用numpy.hstack,而是直接使用list强转range,偶然一次运行时发现运行时间竟然比groupby.head短,当时还窃窃自喜,复盘发现原来是我的把.head()运用在apply中,在方法一也有提到过这样做的耗时。经过几番修改,最终采用np.hstack组合编号,效率上能勉强达到方法一水平。
在书本中,在年长者口中,常常有一种声音提醒我们现在站在了人生的十字路口,需要仔细思考,斟酌,推断这样做会有怎样的结果,但现在还需要磨蹭啥呢,未来不是推断出的未来,是创造的未来,敢于去想,敢于去做!
于二零二二年元月二十四日作