
聊聊 Sharding-JDBC 实现 读写分离~
今天聊一下如何通过Sharding-JDBC简单的实现读写分离~
为什么要读写分离?
读写分离则是将事务性的增、改、删操作在主库执行,查询操作在从库执行。
一般业务的写操作都是比较耗时,为了避免写操作影响查询的效率,可以使用读写分离。
当然读写分离并不是万能的,还有前面的分库分表方案。
读写分离如何搭建?
MySQL搭建读写分离非常简单,一般有一主一从、一主多从,对于MySQL的主从的相关概念这里就不再详细介绍了。
下面陈某就以MySQL5.7为例,使用docker搭建一个一主一从的架构,步骤如下:
1. pull镜像
使用如下命令从镜像仓库中下载镜像:
docker pull mysql:5.7.26
2. 创建目录
MySQL数据和配置文件挂载的目录:
mkdir -p /usr/local/mysqlData/master/cnf
mkdir -p /usr/local/mysqlData/master/data
mkdir -p /usr/local/mysqlData/slave/cnf
mkdir -p /usr/local/mysqlData/slave/data
3. 编写配置master节点配置
修改MySQL主节点的配置文件,内容如下:
vim /usr/local/mysqlData/master/cnf/mysql.cnf
[mysqld]
## 设置server_id,注意要唯一
server-id=1
## 开启binlog
log-bin=mysql-bin
## binlog缓存
binlog_cache_size=1M
## binlog格式(mixed、statement、row,默认格式是statement)
binlog_format=mixed
4. 编写配置slave节点配置
修改MySQL从节点的配置文件,内容如下:
vim /usr/local/mysqlData/slave/cnf/mysql.cnf
[mysqld]
## 设置server_id,注意要唯一
server-id=2
## 开启binlog,以备Slave作为其它Slave的Master时使用
log-bin=mysql-slave-bin
## relay_log配置中继日志
relay_log=edu-mysql-relay-bin
## 如果需要同步函数或者存储过程
log_bin_trust_function_creators=true
## binlog缓存
binlog_cache_size=1M
## binlog格式(mixed、statement、row,默认格式是statement)
binlog_format=mixed
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
5. 启动MySQL主节点
命令如下:
docker run -itd -p 3306:3306 --name master -v /usr/local/mysqlData/master/cnf:/etc/mysql/conf.d -v /usr/local/mysqlData/master/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7.26
6. 添加复制master数据的用户reader,供从服务器使用
命令如下:
[root@aliyun /]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6af1df686fff mysql:5.7 "docker-entrypoint..." 5 seconds ago Up 4 seconds 0.0.0.0:3306->3306/tcp, 33060/tcp master
[root@aliyun /]# docker exec -it master /bin/bash
root@41d795785db1:/# mysql -u root -p123456
mysql> GRANT REPLICATION SLAVE ON *.* to 'reader'@'%' identified by 'reader';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
7. 创建并运行mysql从服务器
命令如下:
docker run -itd -p 3307:3306 --name slaver -v /usr/local/mysqlData/slave/cnf:/etc/mysql/conf.d -v /usr/local/mysqlData/slave/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7.26
8. 在从服务器上配置连接主服务器的信息
首先主服务器上查看master_log_file、master_log_pos两个参数,然后切换到从服务器上进行主服务器的连接信息的设置。
主服务上执行:
root@6af1df686fff:/# mysql -u root -p123456
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000003 | 591 | | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
docker查看主服务器容器的ip地址:
[root@aliyun /]# docker inspect --format='{{.NetworkSettings.IPAddress}}' master
172.17.0.2
从服务器上执行:
[root@aliyun /]# docker exec -it slaver /bin/bash
root@fe8b6fc2f1ca:/# mysql -u root -p123456
mysql> change master to master_host='172.17.0.2',master_user='reader',master_password='reader',master_log_file='mysql-bin.000003',master_log_pos=591;
9. 从服务器启动I/O 线程和SQL线程
mysql> start slave;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.17.0.2
Master_User: reader
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000003
Read_Master_Log_Pos: 591
Relay_Log_File: edu-mysql-relay-bin.000002
Relay_Log_Pos: 320
Relay_Master_Log_File: mysql-bin.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Slave_IO_Running: Yes,Slave_SQL_Running: Yes即表示启动成功。
Sharding-JDBC 实现读写分离
上面使用Docker搭建了一个MySQL的一主一从的架构,如下:
| ip:port | 节点 | 数据库 |
|---|---|---|
| 192.168.47.149:3306 | 主节点 | product_db_1 |
| 192.168.47.149:3307 | 从节点 | product_db_1 |
Sharding-JDBC对于读写分离的配置非常简单,分为如下几个步骤:
“
关于数据库中的表的SQL就不再贴了,文末有案例源码,自己下载!
”
1. 数据源配置
无论是分库分表还是读写分离,数据源的声明肯定是必须的,如下:
spring:
# Sharding-JDBC的配置
shardingsphere:
datasource:
# 数据源,这里配置两个,分别是ds1,ds2
names: ds1,ds2
# 主库
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.47.149:3306/product_db1?useUnicode=true&characterEncoding=utf-8
username: root
password: 123456
# 从库
ds2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.47.149:3307/product_db1?useUnicode=true&characterEncoding=utf-8
username: root
password: 123456
“
源码已经上传GitHub,关注公众号:码猿技术专栏,回复关键词:9537 获取
”
2. 主从节点配置
第①步仅仅配置了数据源,并未指定哪个是主库,哪个是从库,Sharding-JDBC 默认是不知道哪个主库还是从库的,因此需要自己配置。
配置规则如下:
#主库数据源名称,名称随意
spring.shardingsphere.masterslave.<master-slave-data-source-name>.master-data-source-name=
#从库数据源名称列表
spring.shardingsphere.masterslave.<master-slave-data-source-name>.slave-data-source-names[0]=
#从库数据源名称列表
spring.shardingsphere.masterslave.<master-slave-data-source-name>.slave-data-source-names[1]=
#从库负载均衡算法类名称。该类需实现MasterSlaveLoadBalanceAlgorithm接口且提供无参数构造器
spring.shardingsphere.masterslave.<master-slave-data-source-name>.load-balance-algorithm-class-name=
#从库负载均衡算法类型,可选值:ROUND_ROBIN,RANDOM。若`load-balance-algorithm-class-name`存在则忽略该配置
spring.shardingsphere.masterslave.<master-slave-data-source-name>.load-balance-algorithm-type=
这里的<master-slave-data-source-name>一定要注意,这个是主从配置的名称(相当于逻辑数据源),名称可以随意,但是一定要唯一。
陈某的配置如下:
spring:
# Sharding-JDBC的配置
shardingsphere:
# 主从节点配置
masterslave:
# 从库负载均衡算法,内置两个值:RANDOM、ROUND_ROBIN
load-balance-algorithm-type: round_robin
# 主从的名称,随意,但是要保证唯一
name: ms
# 指定主数据源
master-data-source-name: ds1
# 指定从数据源
slave-data-source-names:
- ds2
指定的逻辑数据源为ms,主库为ds1,从库为ds2。
“
”
load-balance-algorithm-type:指定从库的负载均衡算法,后面文章介绍
3. 测试
经过上面两步的配置,Sharding-JDBC的读写分离已经配置成功,下面来测试一下。
理想效果:
写操作:任何的写操作都应该在主库数据源ds1中执行
读操作:任何的读操作都应该在从库数据源ds2中执行
1、写操作
直接insert插入一条数据,查看Sharding-JDBC的日志,如下:
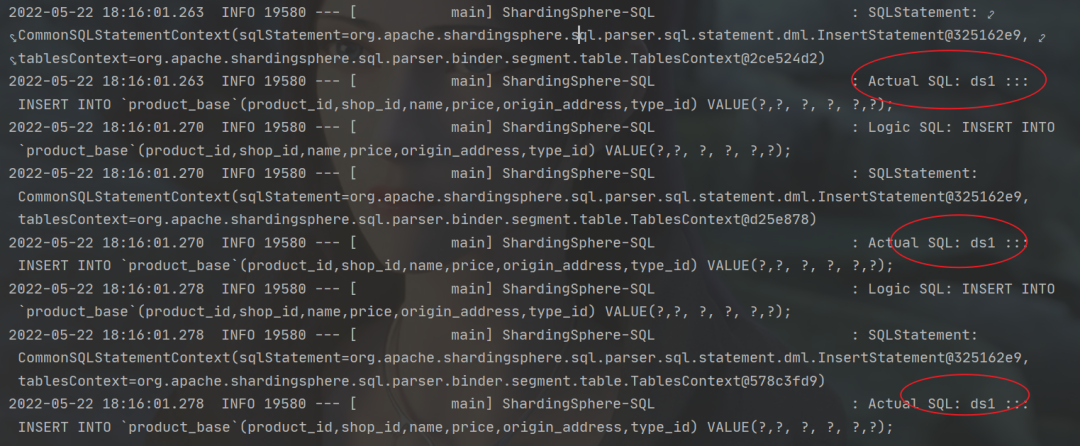
“
可以看到都在ds1中执行了
”
2、读操作
根据商品ID查询一条数据,效果如下:

“
可以看到都在ds2中执行了
”
总结
本篇文章介绍了MySQL的读写分离架构搭建以及使用Sharding-JDBC去实现程序中无感知使用读写分离。
关于读写分离还有一些内容未介绍,将会放在后面文章详细介绍。