
Sharding-Jdbc实现读写分离、分库分表,妙!

阅读本文大概需要 15 分钟。
来自:blog.csdn.net/qq_40378034/article/details/115264837
1、概览
2、MySQL主从复制
1)、docker配置mysql主从复制
mkdir -p /usr/local/mysqlData/master/cnf
mkdir -p /usr/local/mysqlData/master/data
vim /usr/local/mysqlData/master/cnf/mysql.cnf
[mysqld]
## 设置server_id,注意要唯一
server-id=1
## 开启binlog
log-bin=mysql-bin
## binlog缓存
binlog_cache_size=1M
## binlog格式(mixed、statement、row,默认格式是statement)
binlog_format=mixed
docker run -itd -p 3306:3306 --name master -v /usr/local/mysqlData/master/cnf:/etc/mysql/conf.d -v /usr/local/mysqlData/master/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7
[root@aliyun /]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6af1df686fff mysql:5.7 "docker-entrypoint..." 5 seconds ago Up 4 seconds 0.0.0.0:3306->3306/tcp, 33060/tcp master
[root@aliyun /]# docker exec -it master /bin/bash
root@41d795785db1:/# mysql -u root -p123456
mysql> GRANT REPLICATION SLAVE ON *.* to 'reader'@'%' identified by 'reader';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
mkdir /usr/local/mysqlData/slave/cnf -p
mkdir /usr/local/mysqlData/slave/cnf -p
vim /usr/local/mysqlData/slave/cnf/mysql.cnf
[mysqld]
## 设置server_id,注意要唯一
server-id=2
## 开启binlog,以备Slave作为其它Slave的Master时使用
log-bin=mysql-slave-bin
## relay_log配置中继日志
relay_log=edu-mysql-relay-bin
## 如果需要同步函数或者存储过程
log_bin_trust_function_creators=true
## binlog缓存
binlog_cache_size=1M
## binlog格式(mixed、statement、row,默认格式是statement)
binlog_format=mixed
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
docker run -itd -p 3307:3306 --name slaver -v /usr/local/mysqlData/slave/cnf:/etc/mysql/conf.d -v /usr/local/mysqlData/slave/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7
master_log_file、master_log_pos两个参数,然后切换到从服务器上进行主服务器的连接信息的设置root@6af1df686fff:/# mysql -u root -p123456
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000003 | 591 | | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
[root@aliyun /]# docker inspect --format='{{.NetworkSettings.IPAddress}}' master
172.17.0.2
[root@aliyun /]# docker exec -it slaver /bin/bash
root@fe8b6fc2f1ca:/# mysql -u root -p123456
mysql> change master to master_host='172.17.0.2',master_user='reader',master_password='reader',master_log_file='mysql-bin.000003',master_log_pos=591;
mysql> start slave;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.17.0.2
Master_User: reader
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000003
Read_Master_Log_Pos: 591
Relay_Log_File: edu-mysql-relay-bin.000002
Relay_Log_Pos: 320
Relay_Master_Log_File: mysql-bin.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
2)、binlog和redo log回顾
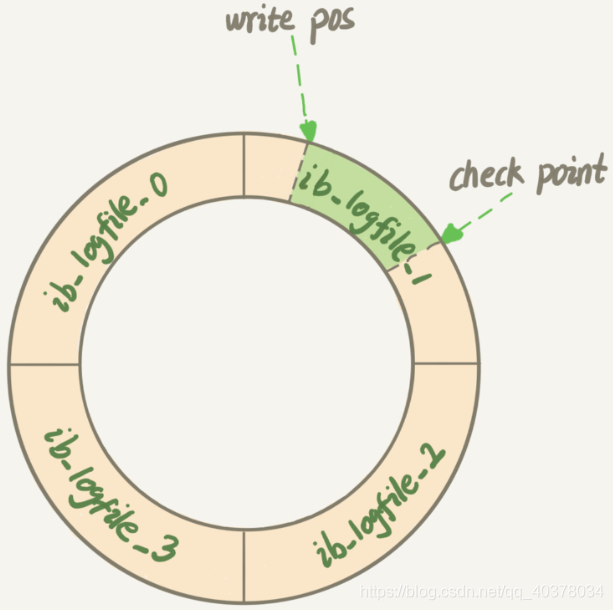
Master Thread每一秒将redo log buffer刷新到redo log file 每个事务提交时会将redo log buffer刷新到redo log file 当redo log缓冲池剩余空间小于1/2时,会将redo log buffer刷新到redo log file
STATEMENT模式:binlog里面记录的就是SQL语句的原文。优点是并不需要记录每一行的数据变化,减少了binlog日志量,节约IO,提高性能。缺点是在某些情况下会导致master-slave中的数据不一致 ROW模式:不记录每条SQL语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了,解决了STATEMENT模式下出现master-slave中的数据不一致。缺点是会产生大量的日志,尤其是alter table的时候会让日志暴涨 MIXED模式:以上两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式
redo log是InnoDB引擎特有的;binlog是MySQL的Server层实现的,所有引擎都可以使用 redo log是物理日志,记录的是在某个数据也上做了什么修改;binlog是逻辑日志,记录的是这个语句的原始逻辑,比如给ID=2这一行的c字段加1 redo log是循环写的,空间固定会用完;binlog是可以追加写入的,binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志
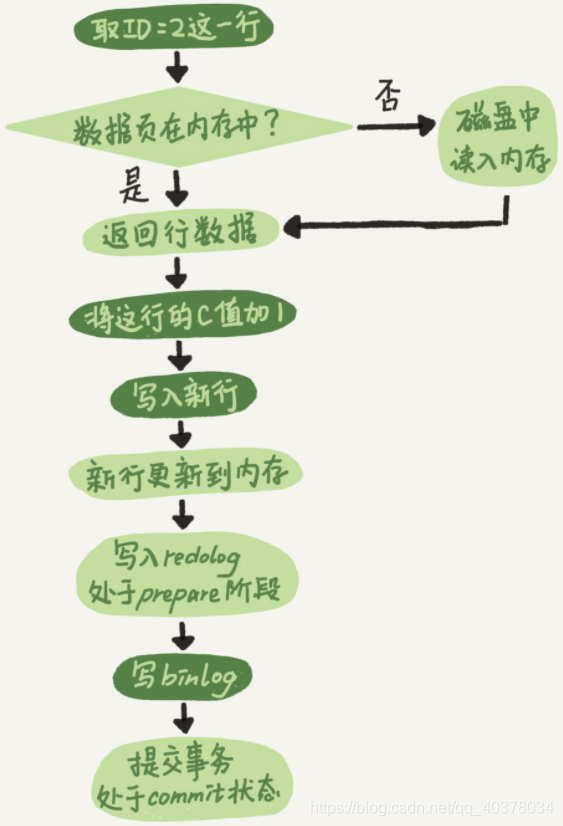
create table T(ID int primary key, c int);
update T set c=c+1 where ID=2;
执行器先找到引擎取ID=2这一行。ID是主键,引擎直接用树搜索找到这一行。如果ID=2这一行所在的数据也本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回 执行器拿到引擎给的行数据,把这个值加上1,得到新的一行数据,再调用引擎接口写入这行新数据 引擎将这行新数据更新到内存中,同时将这个更新操作记录到redo log里面,此时redo log处于prepare状态。然后告知执行器执行完成了,随时可以提交事务 执行器生成这个操作的binlog,并把binlog写入磁盘 执行器调用引擎的提交事务接口,引擎把刚刚写入的redo log改成提交状态,更新完成
3)、MySQL主从复制原理
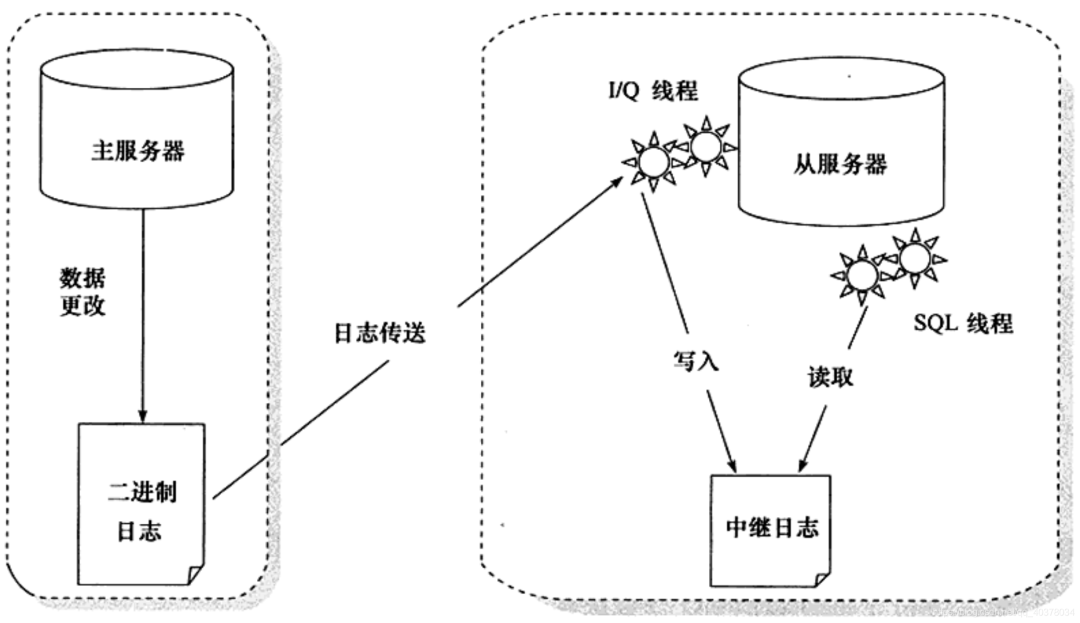
在从库B上通过change master命令,设置主库A的IP、端口、用户名、密码,以及要从哪个位置开始请求binlog,这个位置包含文件名和日志偏移量 在从库B上执行start slave命令,这时从库会启动两个线程,就是图中的I/O线程和SQL线程。其中I/O线程负责与主库建立连接 主库A校验完用户名、密码后,开始按照从库B传过来的位置,从本地读取binlog,发给B 从库B拿到binlog后,写到本地文件,称为中继日志 SQL线程读取中继日志,解析出日志里的命令,并执行
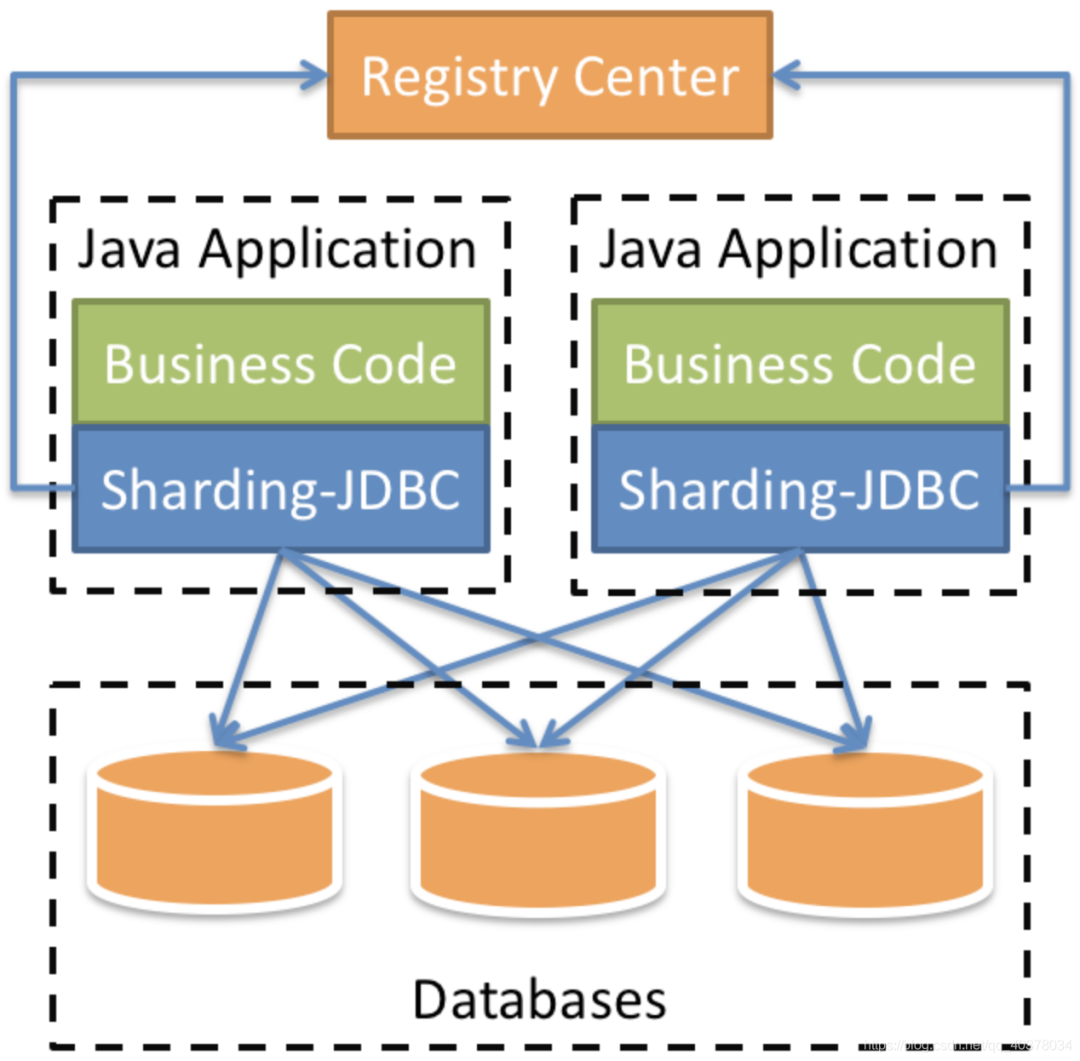
3、Sharding-Jdbc实现读写分离
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.21</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
spring.main.allow-bean-definition-overriding=true
#显示sql
spring.shardingsphere.props.sql.show=true
#配置数据源
spring.shardingsphere.datasource.names=ds1,ds2,ds3
#master-ds1数据库连接信息
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://47.101.58.187:3306/sharding-jdbc-db?useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=123456
spring.shardingsphere.datasource.ds1.maxPoolSize=100
spring.shardingsphere.datasource.ds1.minPoolSize=5
#slave-ds2数据库连接信息
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://47.101.58.187:3307/sharding-jdbc-db?useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.ds2.username=root
spring.shardingsphere.datasource.ds2.password=123456
spring.shardingsphere.datasource.ds2.maxPoolSize=100
spring.shardingsphere.datasource.ds2.minPoolSize=5
#slave-ds3数据库连接信息
spring.shardingsphere.datasource.ds3.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds3.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds3.url=jdbc:mysql://47.101.58.187:3307/sharding-jdbc-db?useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.ds3.username=root
spring.shardingsphere.datasource.ds3.password=123456
spring.shardingsphere.datasource.ds.maxPoolSize=100
spring.shardingsphere.datasource.ds3.minPoolSize=5
#配置默认数据源ds1 默认数据源,主要用于写
spring.shardingsphere.sharding.default-data-source-name=ds1
#配置主从名称
spring.shardingsphere.masterslave.name=ms
#置主库master,负责数据的写入
spring.shardingsphere.masterslave.master-data-source-name=ds1
#配置从库slave节点
spring.shardingsphere.masterslave.slave-data-source-names=ds2,ds3
#配置slave节点的负载均衡均衡策略,采用轮询机制
spring.shardingsphere.masterslave.load-balance-algorithm-type=round_robin
#整合mybatis的配置
mybatis.type-aliases-package=com.ppdai.shardingjdbc.entity
CREATE TABLE `t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`nickname` varchar(100) DEFAULT NULL,
`password` varchar(100) DEFAULT NULL,
`sex` int(11) DEFAULT NULL,
`birthday` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4;
@Data
public class User {
private Integer id;
private String nickname;
private String password;
private Integer sex;
private String birthday;
}
@RestController
@RequestMapping("/api/user")
public class UserController {
@Autowired
private UserMapper userMapper;
@PostMapping("/save")
public String addUser() {
User user = new User();
user.setNickname("zhangsan" + new Random().nextInt());
user.setPassword("123456");
user.setSex(1);
user.setBirthday("1997-12-03");
userMapper.addUser(user);
return "success";
}
@GetMapping("/findUsers")
public List<User> findUsers() {
return userMapper.findUsers();
}
}
public interface UserMapper {
@Insert("insert into t_user(nickname,password,sex,birthday) values(#{nickname},#{password},#{sex},#{birthday})")
void addUser(User user);
@Select("select * from t_user")
List<User> findUsers();
}

http://localhost:8080/api/user/save一直进入到ds1主节点
http://localhost:8080/api/user/findUsers一直进入到ds2、ds3节点,并且轮询进入
4、MySQL分库分表原理
1)、分库分表
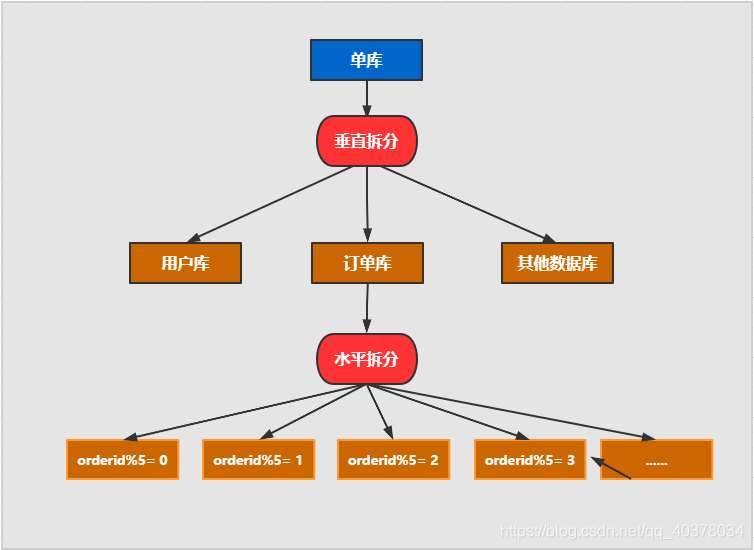
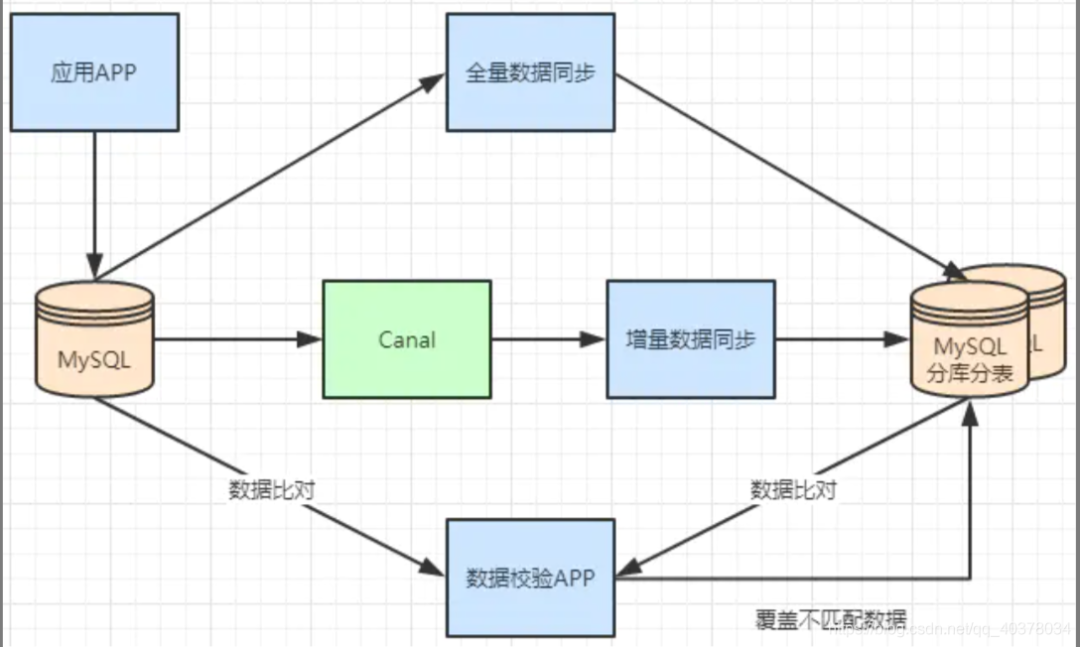
2)、不停机分库分表数据迁移
利用MySQL+Canal做增量数据同步,利用分库分表中间件,将数据路由到对应的新表中 利用分库分表中间件,全量数据导入到对应的新表中 通过单表数据和分库分表数据两两比较,更新不匹配的数据到新表中 数据稳定后,将单表的配置切换到分库分表配置上
5、Sharding-Jdbc实现分库分表
1)、逻辑表
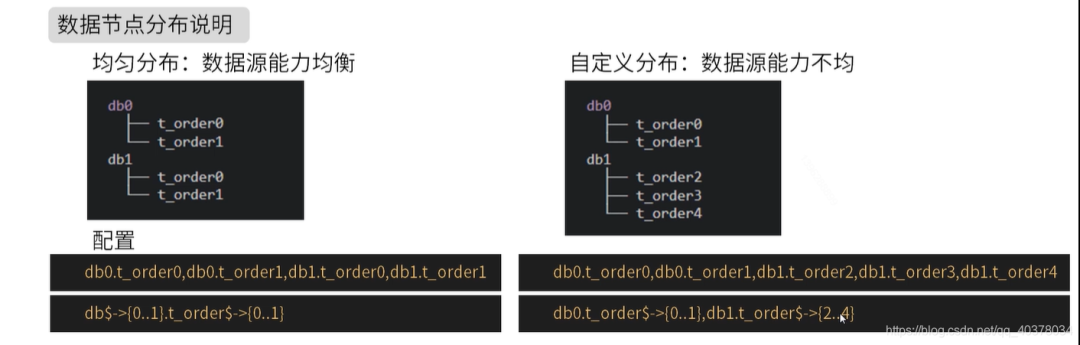
#多数据源$->{0..N}.逻辑表名$->{0..N} 相同表
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}
#多数据源$->{0..N}.逻辑表名$->{0..N} 不同表
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds0.t_order$->{0..1},ds1.t_order$->{2..4}
#单数据源的配置方式
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds0.t_order$->{0..4}
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds0.t_order0,ds1.t_order0,ds0.t_order1,ds1.t_order1
2)、inline分片策略
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}
#数据源分片策略
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column=user_id
#数据源分片算法
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression=ds$->{user_id%2}
#表分片策略
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
#表分片算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id%2}
insert into t_order(user_id,order_id) values(2,3),user_id%2 = 0使用数据源ds0,order_id%2 = 1使用t_order1,insert语句最终操作的是数据源ds0的t_order1表。3)、分布式主键配置
#主键的列名
spring.shardingsphere.sharding.tables.t_order.key-generator.column=id
#主键生成策略
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
4)、inline分片策略实现分库分表
CREATE TABLE `t_user0` (
`id` bigint(20) DEFAULT NULL,
`nickname` varchar(200) DEFAULT NULL,
`password` varchar(200) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`sex` int(11) DEFAULT NULL,
`birthday` varchar(100) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `t_user1` (
`id` bigint(20) DEFAULT NULL,
`nickname` varchar(200) DEFAULT NULL,
`password` varchar(200) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`sex` int(11) DEFAULT NULL,
`birthday` varchar(100) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
spring.main.allow-bean-definition-overriding=true
#显示sql
spring.shardingsphere.props.sql.show=true
#配置数据源
spring.shardingsphere.datasource.names=ds0,ds1
#ds0数据库连接信息
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://47.101.58.187:3306/t_user_db0?useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=123456
spring.shardingsphere.datasource.ds0.maxPoolSize=100
spring.shardingsphere.datasource.ds0.minPoolSize=5
#ds1数据库连接信息
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://47.101.58.187:3306/t_user_db1?useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=123456
spring.shardingsphere.datasource.ds1.maxPoolSize=100
spring.shardingsphere.datasource.ds1.minPoolSize=5
#整合mybatis的配置
mybatis.type-aliases-package=com.ppdai.shardingjdbc.entity
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=ds$->{0..1}.t_user$->{0..1}
#数据源分片策略
spring.shardingsphere.sharding.tables.t_user.database-strategy.inline.sharding-column=sex
#数据源分片算法
spring.shardingsphere.sharding.tables.t_user.database-strategy.inline.algorithm-expression=ds$->{sex%2}
#表分片策略
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.sharding-column=age
#表分片算法
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.algorithm-expression=t_user$->{age%2}
#主键的列名
spring.shardingsphere.sharding.tables.t_user.key-generator.column=id
spring.shardingsphere.sharding.tables.t_user.key-generator.type=SNOWFLAKE
@SpringBootTest
class ShardingJdbcApplicationTests {
@Autowired
private UserMapper userMapper;
/**
* sex:奇数
* age:奇数
* ds1.t_user1
*/
@Test
public void test01() {
User user = new User();
user.setNickname("zhangsan" + new Random().nextInt());
user.setPassword("123456");
user.setAge(17);
user.setSex(1);
user.setBirthday("1997-12-03");
userMapper.addUser(user);
}
/**
* sex:奇数
* age:偶数
* ds1.t_user0
*/
@Test
public void test02() {
User user = new User();
user.setNickname("zhangsan" + new Random().nextInt());
user.setPassword("123456");
user.setAge(18);
user.setSex(1);
user.setBirthday("1997-12-03");
userMapper.addUser(user);
}
/**
* sex:偶数
* age:奇数
* ds0.t_user1
*/
@Test
public void test03() {
User user = new User();
user.setNickname("zhangsan" + new Random().nextInt());
user.setPassword("123456");
user.setAge(17);
user.setSex(2);
user.setBirthday("1997-12-03");
userMapper.addUser(user);
}
/**
* sex:偶数
* age:偶数
* ds0.t_user0
*/
@Test
public void test04() {
User user = new User();
user.setNickname("zhangsan" + new Random().nextInt());
user.setPassword("123456");
user.setAge(18);
user.setSex(2);
user.setBirthday("1997-12-03");
userMapper.addUser(user);
}
}
https://shardingsphere.apache.org/document/current/cn/overview/
https://www.bilibili.com/video/BV1ei4y1K7dn
推荐阅读:
官宣!字节跳动取消大小周,员工却高兴不起来!内网哀嚎:变相降薪20%,少赚一万!
单点登录解决方案?SpringSecurity结合JWT完美解决(附源码)
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
朕已阅 
评论