
图像分类训练技巧之数据增强方法总结
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


导读
一个模型的性能除了和网络结构本身有关,还非常依赖具体的训练策略,比如优化器,数据增强以及正则化策略等。本文简单介绍了图像分类训练技巧中的常用数据增强策略。
一个模型的性能除了和网络结构本身有关,还非常依赖具体的训练策略,比如优化器,数据增强以及正则化策略等(当然也很训练数据强相关,训练数据量往往决定模型性能的上线)。近年来,图像分类模型在ImageNet数据集的top1 acc已经由原来的56.5(AlexNet,2012)提升至90.88(CoAtNet,2021,用了额外的数据集JFT-3B),这进步除了主要归功于模型,算力和数据的提升,也与训练策略的提升紧密相关。最近刚兴起的vision transformer相比CNN模型往往也需要更heavy的数据增强和正则化策略。这里简单介绍图像分类训练技巧中的常用数据增强策略。
baseline
ImageNet数据集训练常用的数据增强策略如下,训练过程的数据增强包括随机缩放裁剪(RandomResizedCrop,这种处理方式源自谷歌的Inception,所以称为 Inception-style pre-processing)和水平翻转(RandomHorizontalFlip),而测试阶段是执行缩放和中心裁剪。这其实是一种轻量级的策略,这里称之为baseline。torchvision的实现的ResNet50训练采用的策略就是这个,在ImageNet上的top1 acc可以达到76.1。
from torchvision import transforms
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
# 训练
train_transform = transforms.Compose([
# 这里的scale指的是面积,ratio是宽高比
# 具体实现每次先随机确定scale和ratio,可以生成w和h,然后随机确定裁剪位置进行crop
# 最后是resize到target size
transforms.RandomResizedCrop(224, scale=(0.08, 1.0), ratio=(3. / 4., 4. / 3.)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize
])
# 测试
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])

AutoAugment
谷歌在2018年提出通过AutoML来自动搜索数据增强策略,称之为AutoAugment(算是自动数据增强开山之作)。搜索方法采用强化学习,和NAS类似,只不过搜索空间是数据增强策略,而不是网络架构。在搜索空间里,一个policy包含5个sub-policies,每个sub-policy包含两个串行的图像增强操作,每个增强操作有两个超参数:进行该操作的概率和图像增强的幅度(magnitude,这个表示数据增强的强度,比如对于旋转,旋转的角度就是增强幅度,旋转角度越大,增强越大)。每个policy在执行时,首先随机从5个策略中随机选择一个sub-policy,然后序列执行两个图像操作。
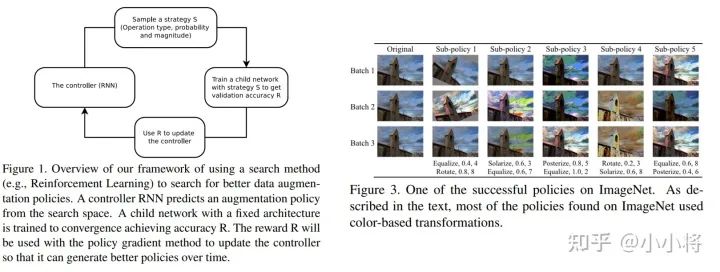
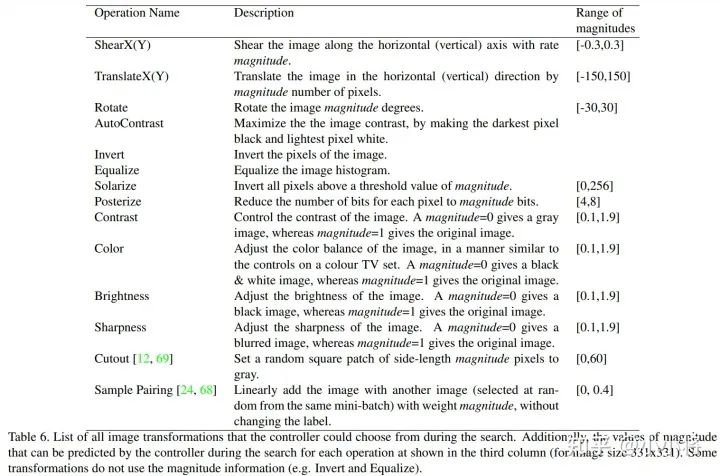
搜索空间一共有16种图像增强类型,具体如下所示,大部分操作都定义了图像增强的幅度范围,在搜索时需要将幅度值离散化,具体地是将幅度值在定义范围内均匀地取10个值。
论文在不同的数据集上( CIFAR-10 , SVHN, ImageNet)做了实验,这里给出在ImageNet数据集上搜索得到的最优policy(最后实际上是将搜索得到的前5个最好的policies合成了一个policy,所以这里包含25个sub-policies):
# operation, probability, magnitude
(("Posterize", 0.4, 8), ("Rotate", 0.6, 9)),
(("Solarize", 0.6, 5), ("AutoContrast", 0.6, None)),
(("Equalize", 0.8, None), ("Equalize", 0.6, None)),
(("Posterize", 0.6, 7), ("Posterize", 0.6, 6)),
(("Equalize", 0.4, None), ("Solarize", 0.2, 4)),
(("Equalize", 0.4, None), ("Rotate", 0.8, 8)),
(("Solarize", 0.6, 3), ("Equalize", 0.6, None)),
(("Posterize", 0.8, 5), ("Equalize", 1.0, None)),
(("Rotate", 0.2, 3), ("Solarize", 0.6, 8)),
(("Equalize", 0.6, None), ("Posterize", 0.4, 6)),
(("Rotate", 0.8, 8), ("Color", 0.4, 0)),
(("Rotate", 0.4, 9), ("Equalize", 0.6, None)),
(("Equalize", 0.0, None), ("Equalize", 0.8, None)),
(("Invert", 0.6, None), ("Equalize", 1.0, None)),
(("Color", 0.6, 4), ("Contrast", 1.0, 8)),
(("Rotate", 0.8, 8), ("Color", 1.0, 2)),
(("Color", 0.8, 8), ("Solarize", 0.8, 7)),
(("Sharpness", 0.4, 7), ("Invert", 0.6, None)),
(("ShearX", 0.6, 5), ("Equalize", 1.0, None)),
(("Color", 0.4, 0), ("Equalize", 0.6, None)),
(("Equalize", 0.4, None), ("Solarize", 0.2, 4)),
(("Solarize", 0.6, 5), ("AutoContrast", 0.6, None)),
(("Invert", 0.6, None), ("Equalize", 1.0, None)),
(("Color", 0.6, 4), ("Contrast", 1.0, 8)),
(("Equalize", 0.8, None), ("Equalize", 0.6, None))
基于搜索得到的AutoAugment训练可以将ResNet50在ImageNet数据集上的top1 acc从76.3提升至77.6。一个比较重要的问题,这些从某一个数据集搜索得到的策略是否只对固定的数据集有效,论文也通过具体实验证明了AutoAugment的迁移能力,比如将ImageNet数据集上得到的策略用在5个 FGVC数据集(与ImageNet图像输入大小相似)也均有提升。
目前torchvision库已经实现了AutoAugment,具体使用如下所示(注意AutoAug前也需要包括一个RandomResizedCrop):
from torchvision.transforms import autoaugment, transforms
train_transform = transforms.Compose([
transforms.RandomResizedCrop(crop_size, interpolation=interpolation),
transforms.RandomHorizontalFlip(hflip_prob),
# 这里policy属于torchvision.transforms.autoaugment.AutoAugmentPolicy,
# 对于ImageNet就是 AutoAugmentPolicy.IMAGENET
# 此时aa_policy = autoaugment.AutoAugmentPolicy('imagenet')
autoaugment.AutoAugment(policy=aa_policy, interpolation=interpolation),
transforms.PILToTensor(),
transforms.ConvertImageDtype(torch.float),
transforms.Normalize(mean=mean, std=std)
])

RandAugment
AutoAugment存在的一个问题是搜索空间巨大,这使得搜索只能在代理任务中进行:使用小的模型在ImageNet的一个小的子集( 120类和6000图片)搜索。谷歌在2019年又提出了一个更简单的数据增强策略:RandAugment。这篇论文首先发现AutoAugment这样在小数据集上搜索出来的策略在大的数据集上应用会存在问题,这主要是因为数据增强策略和模型大小和数据量大小存在强相关,如下图所示可以看到模型或者训练数据量越大,其最优的数据增强的幅度越大,这说明AutoAugment得到的结果应该是次优的。另外,Population Based Augmentation这篇论文发现最优的数据增强幅度是随训练过程增加,而且不同的增强操作遵循类似的规律,这启发作者采用固定的增强幅度而不是去搜索。RandAugment相比AutoAugment的策略空间很小( vs ),所以它不需要采用代理任务,甚至直接采用简单的网格搜索。
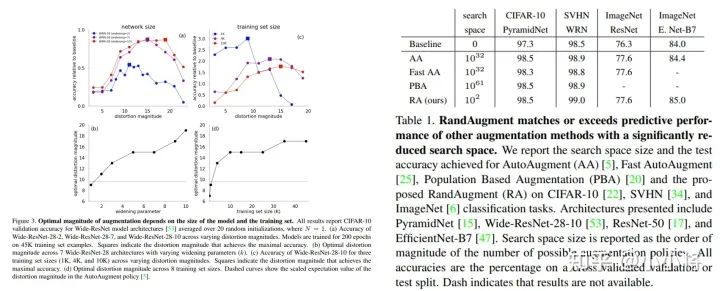
具体地,RandAugment共包含两个超参数:图像增强操作的数量N和一个全局的增强幅度M,其实现代码如下所示,每次从候选操作集合(共14种策略)随机选择N个操作(等概率),然后串行执行(这里没有判断概率,是一定执行)。这里的M取值范围为{0, . . . , 30}(每个图像增强操作归一化到同样的幅度范围),而N取值范围一般为 {1, 2, 3}。
# Identity是恒等变换,不做任何增强
transforms = ['Identity', 'AutoContrast', 'Equalize', 'Rotate', 'Solarize', 'Color', 'Posterize',
'Contrast', 'Brightness', 'Sharpness', 'ShearX', 'ShearY', 'TranslateX', 'TranslateY']
def randaugment(N, M):
"""Generate a set of distortions.
Args:
N: Number of augmentation transformations to
apply sequentially.
M: Magnitude for all the transformations.
"""
sampled_ops = np.random.choice(transforms, N)
return [(op, M) for op in sampled_ops]
对于ResNet50,其搜索得到的N=2,M=9,RandAugment相比AutoAugment可以在ImageNet得到相似的效果(77.6),不过DeiT中发现使用RandAugment效果更好一些( DeiT-B:81.8 vs 81.2)。目前torchvision库也已经实现了RandAugment,具体使用如下所示:
from torchvision.transforms import autoaugment, transforms
train_transform = transforms.Compose([
transforms.RandomResizedCrop(crop_size, interpolation=interpolation),
transforms.RandomHorizontalFlip(hflip_prob),
autoaugment.RandAugment(interpolation=interpolation),
transforms.PILToTensor(),
transforms.ConvertImageDtype(torch.float),
transforms.Normalize(mean=mean, std=std)
])

TrivialAugment
虽然RandAugment的搜索空间极小,但是对于不同的数据集还是需要确定最优的N和M,这依然有较大的实验成本。RandAugment后,华为提出了UniformAugment,这种策略不需要搜索也能取得较好的结果。不过这里我们介绍一项更新的工作:TrivialAugment: Tuning-free Yet State-of-the-Art Data Augmentation。TrivialAugment也不需要任何搜索,整个方法非常简单:每次随机选择一个图像增强操作,然后随机确定它的增强幅度,并对图像进行增强。由于没有任何超参数,所以不需要任何搜索。从实验结果上看,TA可以在多个数据集上取得更好的结果,如在ImageNet数据集上,ResNet50的top1 acc可以达到78.1,超过RandAugment。

TrivialAugment的图像增强集合和RandAugment基本一样,不过TA也定义了一套更宽的增强幅度,目前torchvision中已经实现了TrivialAugmentWide,具体使用代码如下所示:
from torchvision.transforms import autoaugment, transforms
augmentation_space = {
# op_name: (magnitudes, signed)
"Identity": (torch.tensor(0.0), False),
"ShearX": (torch.linspace(0.0, 0.99, num_bins), True),
"ShearY": (torch.linspace(0.0, 0.99, num_bins), True),
"TranslateX": (torch.linspace(0.0, 32.0, num_bins), True),
"TranslateY": (torch.linspace(0.0, 32.0, num_bins), True),
"Rotate": (torch.linspace(0.0, 135.0, num_bins), True),
"Brightness": (torch.linspace(0.0, 0.99, num_bins), True),
"Color": (torch.linspace(0.0, 0.99, num_bins), True),
"Contrast": (torch.linspace(0.0, 0.99, num_bins), True),
"Sharpness": (torch.linspace(0.0, 0.99, num_bins), True),
"Posterize": (8 - (torch.arange(num_bins) / ((num_bins - 1) / 6)).round().int(), False),
"Solarize": (torch.linspace(255.0, 0.0, num_bins), False),
"AutoContrast": (torch.tensor(0.0), False),
"Equalize": (torch.tensor(0.0), False),
}
train_transform = transforms.Compose([
transforms.RandomResizedCrop(crop_size, interpolation=interpolation),
transforms.RandomHorizontalFlip(hflip_prob),
autoaugment.TrivialAugmentWide(interpolation=interpolation),
transforms.PILToTensor(),
transforms.ConvertImageDtype(torch.float),
transforms.Normalize(mean=mean, std=std)
])

RandomErasing
RandomErasing是厦门大学在2017年提出的一种简单的数据增强(这个策略和同期的CutOut基本一样),基本原理是:随机从图像中擦除一个矩形区域而不改变图像的原始标签。DeiT的训练策略中也包括了RandomErasing。

目前torchvision也实现了RandomErasing,其具体使用代码如下(注意这个op不支持PIL图像,需要在转换为torch.tensor后使用):
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224, scale=(0.08, 1.0), ratio=(3. / 4., 4. / 3.)),
transforms.RandomHorizontalFlip(),
transforms.PILToTensor()
transforms.ConvertImageDtype(torch.float),
normalize,
# scale是指相对于原图的擦除面积范围
# ratio是指擦除区域的宽高比
# value是指擦除区域的值,如果是int,也可以是tuple(RGB3个通道值),或者是str,需为'random',表示随机生成
transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False),
])

MixUp
MixUp在FAIR在2017年提出的一种数据增强方法:两张不同的图像随机线性组合,而同时生成线性组合的标签。
这里的和是两张不同的图像,和是它们对应的one-hot标签,而是线性组合系数,每次执行时随机生成。假定图像分类任务是2分类(区分狗和猫),两张输入图像分别是狗和猫(如下图所示),它们对应的one-hot标签分别是[1,0]和[0, 1]。在进行mixup之前,首先对它们进行必要的数据增强得到aug_img1和aug_img2,然后随机生成线性组合系数,对于得到的图像是mix_img1,标签变为[0.7, 0.3],而得到的图像是mix_img2,标签变为[0.3, 0.7]。

目前timm和torchvision中已经实现了mixup,这里以torchvision为例来讲述具体的代码实现。由于mixup需要两个输入,而不单单是对当前图像进行操作,所以一般是在得到batch数据后再进行mixup,这也意味着图像也已经完成了其它的数据增强如RandAugment,对于batch中的每个样本可以随机选择另外一个样本进行mixup。具体的实现代码如下所示:
# from https://github.com/pytorch/vision/blob/main/references/classification/transforms.py
class RandomMixup(torch.nn.Module):
"""Randomly apply Mixup to the provided batch and targets.
The class implements the data augmentations as described in the paper
`"mixup: Beyond Empirical Risk Minimization" `_.
Args:
num_classes (int): number of classes used for one-hot encoding.
p (float): probability of the batch being transformed. Default value is 0.5.
alpha (float): hyperparameter of the Beta distribution used for mixup.
Default value is 1.0. # beta分布超参数
inplace (bool): boolean to make this transform inplace. Default set to False.
"""
def __init__(self, num_classes: int, p: float = 0.5, alpha: float = 1.0, inplace: bool = False) -> None:
super().__init__()
assert num_classes > 0, "Please provide a valid positive value for the num_classes."
assert alpha > 0, "Alpha param can't be zero."
self.num_classes = num_classes
self.p = p
self.alpha = alpha
self.inplace = inplace
def forward(self, batch: Tensor, target: Tensor) -> Tuple[Tensor, Tensor]:
"""
Args:
batch (Tensor): Float tensor of size (B, C, H, W)
target (Tensor): Integer tensor of size (B, )
Returns:
Tensor: Randomly transformed batch.
"""
if batch.ndim != 4:
raise ValueError(f"Batch ndim should be 4. Got {batch.ndim}")
if target.ndim != 1:
raise ValueError(f"Target ndim should be 1. Got {target.ndim}")
if not batch.is_floating_point():
raise TypeError(f"Batch dtype should be a float tensor. Got {batch.dtype}.")
if target.dtype != torch.int64:
raise TypeError(f"Target dtype should be torch.int64. Got {target.dtype}")
if not self.inplace:
batch = batch.clone()
target = target.clone()
# 建立one-hot标签
if target.ndim == 1:
target = torch.nn.functional.one_hot(target, num_classes=self.num_classes).to(dtype=batch.dtype)
# 判断是否进行mixup
if torch.rand(1).item() >= self.p:
return batch, target
# 这里将batch数据平移一个单位,产生mixup的图像对,这意味着每个图像与相邻的下一个图像进行mixup
# timm实现是通过flip来做的,这意味着第一个图像和最后一个图像进行mixup
# It's faster to roll the batch by one instead of shuffling it to create image pairs
batch_rolled = batch.roll(1, 0)
target_rolled = target.roll(1, 0)
# 随机生成组合系数
# Implemented as on mixup paper, page 3.
lambda_param = float(torch._sample_dirichlet(torch.tensor([self.alpha, self.alpha]))[0])
batch_rolled.mul_(1.0 - lambda_param)
batch.mul_(lambda_param).add_(batch_rolled) # 得到mixup后的图像
target_rolled.mul_(1.0 - lambda_param)
target.mul_(lambda_param).add_(target_rolled) # 得到mixup后的标签
return batch, target
然后可以将MixUp操作放在DataLoader的collate_fn中,这个函数要实现的是将多个样本合并成一个mini-batch,所以可以将MixUp插在得到mini-batch后,具体实现如下所示:
from torch.utils.data.dataloader import default_collate
mixup_transform = RandomMixup(num_classes, p=1.0, alpha=mixup_alpha)
collate_fn = lambda batch: mixup_transform(*default_collate(batch))
data_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
sampler=train_sampler, collate_fn=collate_fn)
对于MixUp,还要注意两个两点。第一个是如果同时采用了label smoothing,那么在创建one-hot标签时要直接得到smooth后的标签,具体实现如下(参考timm):
def one_hot(x, num_classes, on_value=1., off_value=0., device='cuda'):
x = x.long().view(-1, 1)
return torch.full((x.size()[0], num_classes), off_value, device=device).scatter_(1, x, on_value)
off_value = smoothing / num_classes
on_value = 1. - smoothing + off_value
smooth_one_hot = one_hot(target, num_classes, on_value=on_value, off_value=off_value)
第二个要注意的是MixUp后得到标签时soft label,不能直接采用torch.nn.CrossEntropyLoss来计算loss,而是直接计算交叉熵(参考timm):
class SoftTargetCrossEntropy(nn.Module):
def __init__(self):
super(SoftTargetCrossEntropy, self).__init__()
def forward(self, x: torch.Tensor, target: torch.Tensor) -> torch.Tensor:
loss = torch.sum(-target * F.log_softmax(x, dim=-1), dim=-1)
return loss.mean()
注意在PyTorch1.10版本之后,torch.nn.CrossEntropyLoss已经支持直接送入的target是probabilities for each class,原来只支持target是class indices;而且也支持label_smoothing参数,所以上述两个注意点就不再需要了。
说到计算loss,timm作者近期在ResNet strikes back: An improved training procedure in timm指出采用MixUp后可以将多分类改成多标签分类(multi-label classification),即从N分类变成N个2分类(直接采用BinaryCrossEntropy),这应该更符合MixUp后图像的语义,从对比实验来看效果有微弱的提升。MixUp除了可以用于图像分类任务,还可以用于物体检测任务中,比如YOLOX就采用了MixUp,这里面的做法是对图像mixup后,其box为两个图像的box的合并集合,而没有对标签软化,这块也可以见论文Bag of Freebies for Training Object Detection Neural Networks。
CutMix
CutMix是2019年提出的一项和MixUp和类似的数据增强策略,它也是同时对两个图像和标签进行混合,与MixUp不同的是它的图像混合方式。CutMix不是对两个图像线性组合,而是从另外一张图像随机剪切一个patch并粘贴到第一张图像上,patch的起始坐标随机生成,而宽高是由来控制:
这里和是原始图像的宽和高,所以其实决定的是patch和原图的面积比:。下图展示了分别取0.7和0.3的混合效果,越小,粘贴的patch越大。对于标签,其处理方式和MixUp一样,通过来得到两张图像的线性组合。

CutMix做了ImageNet上的对比实验,相比MixUp,ResNet50的top1 acc大约能提升一个点(77.4 vs 78.6):
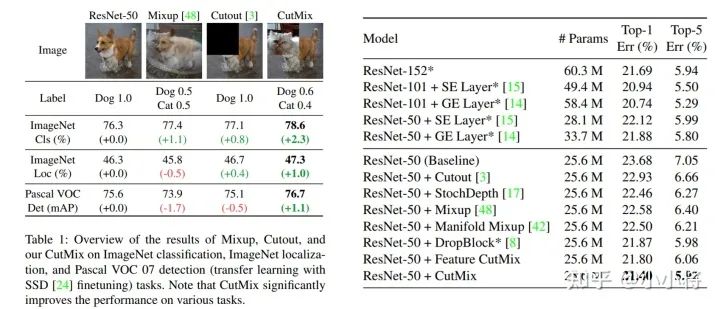
目前timm和torchvision中也已经实现了CutMix,这里还是以torchvision为例来讲述具体的代码实现,如下所示(和MixUp基本类似,只不过内部处理存在差异):
class RandomCutmix(torch.nn.Module):
"""Randomly apply Cutmix to the provided batch and targets.
The class implements the data augmentations as described in the paper
`"CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features"
`_.
Args:
num_classes (int): number of classes used for one-hot encoding.
p (float): probability of the batch being transformed. Default value is 0.5.
alpha (float): hyperparameter of the Beta distribution used for cutmix.
Default value is 1.0.
inplace (bool): boolean to make this transform inplace. Default set to False.
"""
def __init__(self, num_classes: int, p: float = 0.5, alpha: float = 1.0, inplace: bool = False) -> None:
super().__init__()
assert num_classes > 0, "Please provide a valid positive value for the num_classes."
assert alpha > 0, "Alpha param can't be zero."
self.num_classes = num_classes
self.p = p
self.alpha = alpha
self.inplace = inplace
def forward(self, batch: Tensor, target: Tensor) -> Tuple[Tensor, Tensor]:
"""
Args:
batch (Tensor): Float tensor of size (B, C, H, W)
target (Tensor): Integer tensor of size (B, )
Returns:
Tensor: Randomly transformed batch.
"""
if batch.ndim != 4:
raise ValueError(f"Batch ndim should be 4. Got {batch.ndim}")
if target.ndim != 1:
raise ValueError(f"Target ndim should be 1. Got {target.ndim}")
if not batch.is_floating_point():
raise TypeError(f"Batch dtype should be a float tensor. Got {batch.dtype}.")
if target.dtype != torch.int64:
raise TypeError(f"Target dtype should be torch.int64. Got {target.dtype}")
if not self.inplace:
batch = batch.clone()
target = target.clone()
if target.ndim == 1:
target = torch.nn.functional.one_hot(target, num_classes=self.num_classes).to(dtype=batch.dtype)
if torch.rand(1).item() >= self.p:
return batch, target
# It's faster to roll the batch by one instead of shuffling it to create image pairs
batch_rolled = batch.roll(1, 0)
target_rolled = target.roll(1, 0)
# Implemented as on cutmix paper, page 12 (with minor corrections on typos).
lambda_param = float(torch._sample_dirichlet(torch.tensor([self.alpha, self.alpha]))[0])
W, H = F.get_image_size(batch)
# 确定patch的起点
r_x = torch.randint(W, (1,))
r_y = torch.randint(H, (1,))
# 确定patch的w和h(其实是一半大小)
r = 0.5 * math.sqrt(1.0 - lambda_param)
r_w_half = int(r * W)
r_h_half = int(r * H)
# 越界处理
x1 = int(torch.clamp(r_x - r_w_half, min=0))
y1 = int(torch.clamp(r_y - r_h_half, min=0))
x2 = int(torch.clamp(r_x + r_w_half, max=W))
y2 = int(torch.clamp(r_y + r_h_half, max=H))
batch[:, :, y1:y2, x1:x2] = batch_rolled[:, :, y1:y2, x1:x2]
# 由于越界处理, λ可能发生改变,所以要重新计算
lambda_param = float(1.0 - (x2 - x1) * (y2 - y1) / (W * H))
target_rolled.mul_(1.0 - lambda_param)
target.mul_(lambda_param).add_(target_rolled)
return batch, target
其它使用和MixUp一样。
Repeated Augmentation
Repeated Augmentation (RA)是FAIR在MultiGrain提出的一种抽样策略,一般情况下,训练的mini-batch包含的增强过的sample都是来自不同的图像,但是RA这种抽样策略允许一个mini-batch中包含来自同一个图像的不同增强版本,此时mini-batch的各个样本并非是完全独立的,这相当于对同一个样本进行重复抽样,所以称为Repeated Augmentation。这篇论文认为在一个mini-batch学习来自同一个图像的不同增强版本能让模型更容易学习到增强不变的特征。关于RA,其实另外一篇较早的论文Augment your batch: better training with larger batches也提出了类似的策略,另外DeepMind在最近的论文Drawing Multiple Augmentation Samples Per Image During Training Efficiently Decreases Test Error也进一步通过实验来证明这种策略的效果。
DeiT的训练也采用了RA,严格来说RA不属于数据增强策略,而是一种mini-batch抽样方法,这里也简单给出DeiT实现的RA(可以替换torch.utils.data.DistributedSampler):
class RASampler(torch.utils.data.Sampler):
"""Sampler that restricts data loading to a subset of the dataset for distributed,
with repeated augmentation.
It ensures that different each augmented version of a sample will be visible to a
different process (GPU)
Heavily based on torch.utils.data.DistributedSampler
"""
def __init__(self, dataset, num_replicas=None, rank=None, shuffle=True):
if num_replicas is None:
if not dist.is_available():
raise RuntimeError("Requires distributed package to be available")
num_replicas = dist.get_world_size()
if rank is None:
if not dist.is_available():
raise RuntimeError("Requires distributed package to be available")
rank = dist.get_rank()
self.dataset = dataset
self.num_replicas = num_replicas
self.rank = rank
self.epoch = 0
# 重复采样后每个replica的样本量
self.num_samples = int(math.ceil(len(self.dataset) * 3.0 / self.num_replicas))
# 重复采样后的总样本量
self.total_size = self.num_samples * self.num_replicas
# self.num_selected_samples = int(math.ceil(len(self.dataset) / self.num_replicas))
# 每个replica实际样本量,即不重复采样时的每个replica的样本量
self.num_selected_samples = int(math.floor(len(self.dataset) // 256 * 256 / self.num_replicas))
self.shuffle = shuffle
def __iter__(self):
# deterministically shuffle based on epoch
g = torch.Generator()
g.manual_seed(self.epoch)
if self.shuffle:
indices = torch.randperm(len(self.dataset), generator=g).tolist()
else:
indices = list(range(len(self.dataset)))
# add extra samples to make it evenly divisible
indices = [ele for ele in indices for i in range(3)] # 重复3次
indices += indices[:(self.total_size - len(indices))]
assert len(indices) == self.total_size
# subsample: 使得同一个样本的重复版本进入不同的进程(GPU)
indices = indices[self.rank:self.total_size:self.num_replicas]
assert len(indices) == self.num_samples
return iter(indices[:self.num_selected_samples]) # 截取实际样本量
def __len__(self):
return self.num_selected_samples
def set_epoch(self, epoch):
self.epoch = epoch
小结
这里简单介绍了几种常用且有效的数据增强策略,这些策略在vision transformer模型被使用,而且timm训练的ResNet新baseline也使用了这些策略。
参考
Training data-efficient image transformers & distillation through attention (https://arxiv.org/abs/2012.12877) AutoAugment: Learning Augmentation Policies from Data (https://arxiv.org/abs/1805.09501) RandAugment: Practical automated data augmentation with a reduced search space (https://arxiv.org/abs/1909.13719) TrivialAugment: Tuning-free Yet State-of-the-Art Data Augmentation (https://arxiv.org/abs/2103.10158) Random Erasing Data Augmentation(https://arxiv.org/abs/1708.04896) Augment your batch: better training with larger batches (https://arxiv.org/abs/1901.09335) MultiGrain: a unified image embedding for classes and instances(https://arxiv.org/abs/1902.05509) mixup: Beyond Empirical Risk Minimization (https://arxiv.org/abs/1710.09412) CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features (https://arxiv.org/abs/1905.04899)
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!