
【NLP】PET——文本分类的又一种妙解
作者 | 许明
整理 | NewBeeNLP
之前的一篇《模型增强-从label下手》[1]中,我们提到了通过转换label,将分类转换为NLG的方法,而由于性能没有得到增加,所以就没有继续往下做。今天看到两篇文章,思路略微相似,也让我眼前一亮,发现原来我与顶会思路这么近(误),所以总结对比一下。
Classification to NLG
对于分类任务,我们可以将其转换为一个生成任务。比如此时我们有一个样本:
"context:'「天天特价房」华庭仁和国际 3室2厅2卫仅售65万', label: '房产', label_id: 0"
通常我们直接预测对应的label id,而由于其也有label,所以我们可以将其转换为一个NLG任务,即:
"context:['「天天特价房」华庭仁和国际 3室2厅2卫仅售65万', '房产']"
即通过样本生成label对应的token。借助UniLM同时具有NLU与NLG的能力,只需要很小的改动就可以利用BERT做该任务了,对应的示意图如下:

不过当时考虑到UniLM中提到seq2seq的训练不能提高NLU的能力,所以当时并没有选择使用MLM来尝试,最后得到的结论是:
将分类转为生成后,性能基本一致; 将分类与生成联合起来训练,性能与单个任务性能基本一致。
MLM
MLM,即Masked Language Model,中文翻译又叫“掩码语言模型”,即以自监督的方式,mask 掉一部分,然后通过剩余的部分来还原被mask 掉的部分,示意图如下:
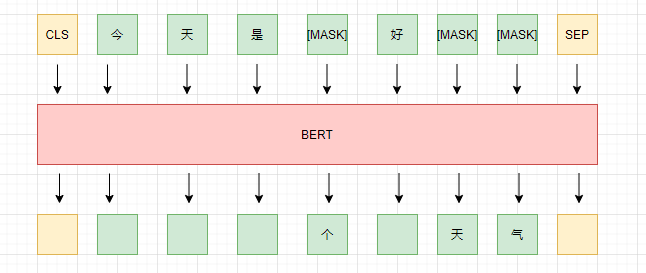
而mask的方式也有多种,如随机选择token进行mask;将token所在的整个词都mask(whole word mask);或者将某个span内的token都mask掉(span mask)。
虽然mlm在预训练任务上已经被证明十分有效,但是通常认为mlm部分的参数是与mlm任务相关的,而通常在下游任务中我们是别的任务,所以会舍弃掉这部分参数,而只使用encoder部分。但是论文《It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》[2] 与 《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》[3]却告诉我们,mlm不仅有用,在few-shot场景下,通过一下简单的融合手段,性能能超过当前的明星GPT-3.
任务转换
与之前的思路类似,我们针对分类任务,不再直接对label进行预测,而是预测其label description,即将其转换为完形填空形式的任务,来预测不同label description的概率。而如何转换成完形填空呢?也很简单,我们添加一个简单的语义通顺的描述,然后将其中与分类有关的内容mask掉即可。举个例子:
假如我们现在的任务是短文本分类,一个样本为“context:'「天天特价房」华庭仁和国际 3室2厅2卫仅售65万', label: '房产'”,我们添加一个统一的描述句,将其变为:"下面是一则__相关新闻标题: 「天天特价房」华庭仁和国际 3室2厅2卫仅售65万",其中的空格可选的内容是所有的label description,对应的真实值是"房产"两个字,这样,我们就将分类任务转换为一个完形填空的形式。而添加的方式也可以分为前缀、后缀两种,完整的方式:
"以下是一则__相关新闻标题: 「天天特价房」华庭仁和国际 3室2厅2卫仅售65万"
"「天天特价房」华庭仁和国际 3室2厅2卫仅售65万,以上是一则__相关新闻标题"
Pattern-Exploiting Training
上面我们添加的前缀/后缀句子称为Pattern, 而label description可以有多种方式,比如,对于“房产”这个label,我们也可以用“地产”来表达,对于“娱乐”label,也可以用“八卦”来表达,所以需要一个token到label的映射,这个映射可以是多对一的,这个被称为Verbalizer。所以在预测时可以将多个token的概率结合起来判断其对应的label。
由于是few-shot,为了提高性能,作者采用了与Knowledge Distillation类似的思路,具体方案如下:
对每个Pattern利用多个pre-train model 进行fine-tuning,得到多个模型.其中 ; 将多个模型的结果进行融合,得到一个融合模型Teacher Model; 利用Teacher Model在大量unlabed数据上进行预测,得到对应的soft labels; 利用soft labels数据,训练一个常规的分类模型(非MLM模型)。
以上就是论文Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference[4]中提到的PET。
此外,该论文中还提到了一个改进:iPET。其中的区别是:在ipet中,得到mlm的多个model后,增加一个迭代:每次会从训练mlm的model中抽取一个 ,然后从剩余的model中选取一部分对unlabeled data进行预测,将其中预测结果确定(不是准确,此时意味着结果的熵很小)的部分打上一个fake label,让 进行训练。重复多次后,融合模型对unlabeled data进行预测,得到一个soft labels data,在此基础上训练一个常规分类器。
可以看到,PET的方式主要适用label description为有限空间,即选择题,此外,每个样本的label description需要长度相同,而且由于mask之间相互独立,所以长度也不能太长。
与NLG差异
在之前的脑洞中,我们将分类任务转变为NLG任务,即利用样本来生成对应的label description,而他与PET中的主要差别主要有几点:
NLG中我们并没有没有限制label description的长度,且不同label对应description也可能是不同长度; NLG中我们每个token的生成是有依赖关系的,即后面的token会依赖之前的token,所以token长度可以比PET中稍微长一些; PET中对应的解码空间大大减小,只需要得到label对应token的概率即可; PET中的pattern可以放在前缀也可以放在后缀,NLG可以看作是后缀PET. PET 中由于pre-train是mlm任务,所以zero-show性能更好。
实验
针对这些差异尝试做了几组实验,验证一下想法。
NLG中label长度同一且解码时利用PET的方式解码,在few-shot下准确率从 上升到 ,所以生成的label越短,解码空间越小越准确; PET前缀pattern下准确率为 , 所以前缀pattern比后缀性能更好,这也与苏剑林《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》[5]的结论一致。 zero-shot情况下,PET的准确率为 , 而NLG只有 ,考虑到数据集全量下目前最好成绩才 ,说明PET的方式在zero-shot下效果相当惊人。
主要实验代码在classification_pet_seq2seq[6] 与 classification_tnews_pet[7]
总结
本文介绍了一种新的转变分类任务获得更好性能的方法:即将分类任务转化为mlm模型进行完形填空,同时与之前脑洞的将分类转变为生成任务进行对比,通过实验验证了两者的差异与有效性。同时也提醒自己,多想几步,也许就能有新的发现。
本文参考资料
《模型增强-从label下手》: https://xv44586.github.io/2020/09/13/classification-label-augment/
[2]It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners: http://arxiv.org/abs/2009.07118
[3]Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference: http://arxiv.org/abs/2001.07676
[4]Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference: http://arxiv.org/abs/2001.07676
[5]《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》: https://spaces.ac.cn/archives/7764
[6]classification_pet_seq2seq: https://github.com/xv44586/toolkit4nlp/blob/master/examples/classification_pet_seq2seq.py
[7]classification_tnews_pet: https://github.com/xv44586/toolkit4nlp/blob/master/examples/classification_tnews_pet.py
- END -
往期精彩回顾
本站qq群851320808,加入微信群请扫码: