
28个数据可视化图表的总结和介绍
来源:DeepHub IMBA 本文约3800字,建议阅读10+分钟
本文是一篇关于数据可视化的完整文章,尤其是展示了地理位置可视化的一些方法。
数据可视化本身就是一种通用语言。我们这里通用语言的意思是:它能够向各行各业的人表示信息。它打破了语言和技术理解的障碍。数据是一些数字和文字的组合,但是可视化可以展示数据包含的信息。
“数据可视化有助于弥合数字和文字之间的差距”——Brie E. Anderson。
有许多无代码/少代码的数据可视化工具,如tableau、Power BI、Microsoft Excel等。但是作为一名数据科学从业者最好的工具还是Python。所以在我们进行数据科学项目的时候,一定要注意数据可视化,因为这是表示信息和洞察数据的最简单方法。

所以在这篇文章中,我们将整理我们能看到的所有数据可视化图表。如果你是数据科学初学者,那么本文将是最适合你的。
数据可视化是一种以图形方式表示数据和信息的方法。它可以被描述为使用图表、动画、信息图等将数据转换为能够可视化的上下文。它有助于发现数据的趋势和模式。
如果给你一个包含数百行的表格格式的数据集,你将感到困惑。但是适当的数据可视化可以帮助你获得数据的正确趋势、异常值和模式等等。
初级数据可视化
这里我们总结了9个基础的数据可视化图,这些都是我们在日常工作中常用的也是最简单的图表。
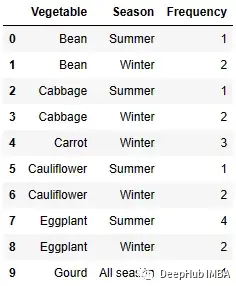
频率表
频率是一个数值出现的次数的计数。频率表是用表格表示频率的一种方式。表格如下所示。
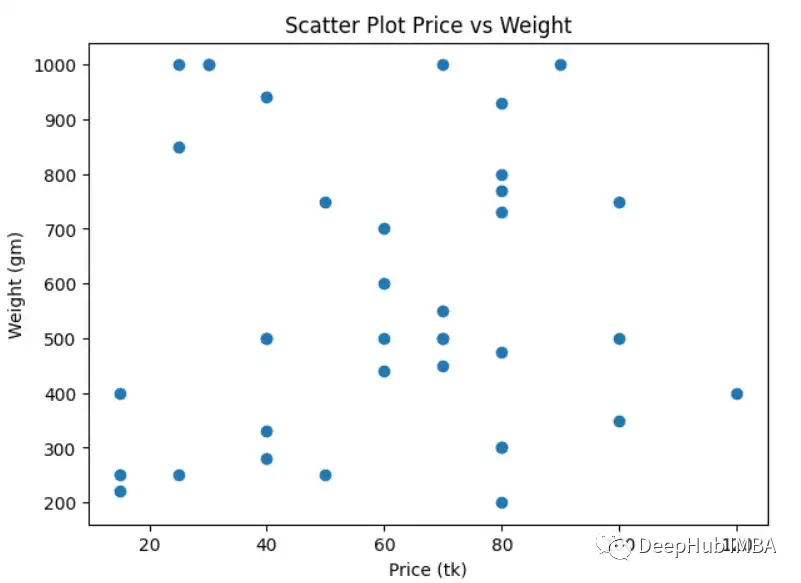
Scatter Plot
散点图是一种在二维坐标系中绘制两个数值变量的方法。通过散点图我们可以很容易地可视化数据分布。
Line Plot
折线图类似于散点图,但点是用连续的线按顺序连接起来的。在二维空间中寻找数据流时,折线图更加直观。
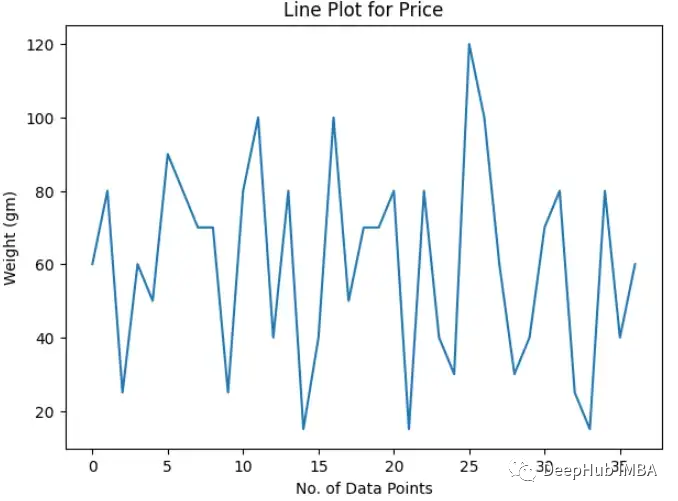
上图可以看到weight是如何连续变化的。
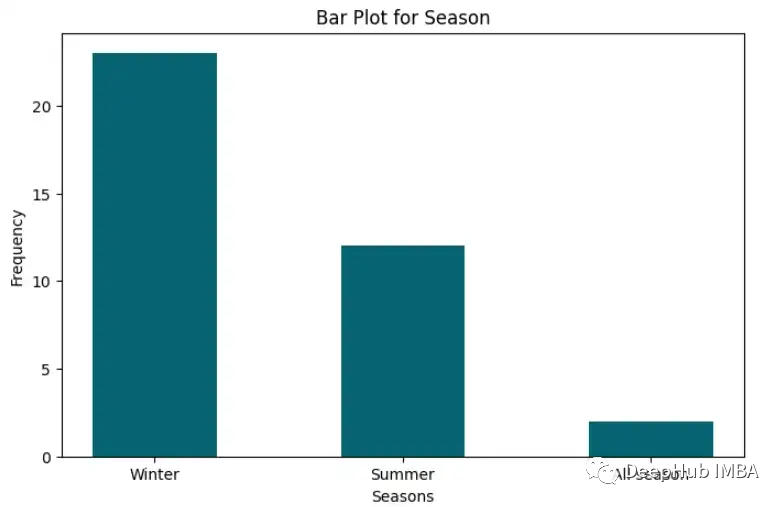
Bar Chart
柱状图主要用于用柱状表示类别变量的出现频率。柱的不同高度表示频率大小。
Histogram
方图的概念与条形图相同。在柱状图中频率显示在分类变量的离散条中,而直方图显示连续间隔的频率。它可以用于查找区间内连续变量的频率 。

Pie Chart
饼图以圆形的方式以百分比表示频率。每个元素根据其频率百分比持有圆的面积。
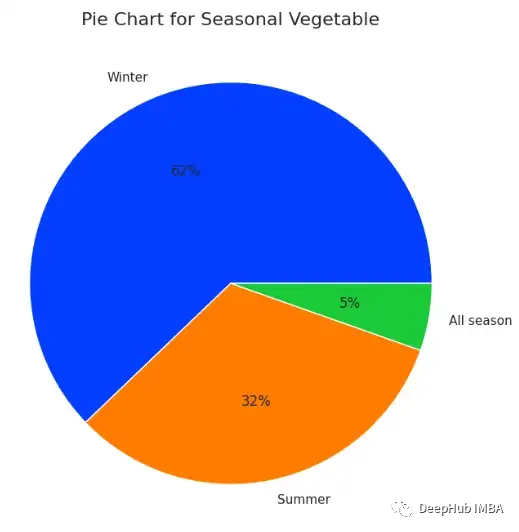
Exploded Pie Chart
展开饼图和饼图是一样的。在展开饼图中,可以展开饼图的一部分以突出显示元素。
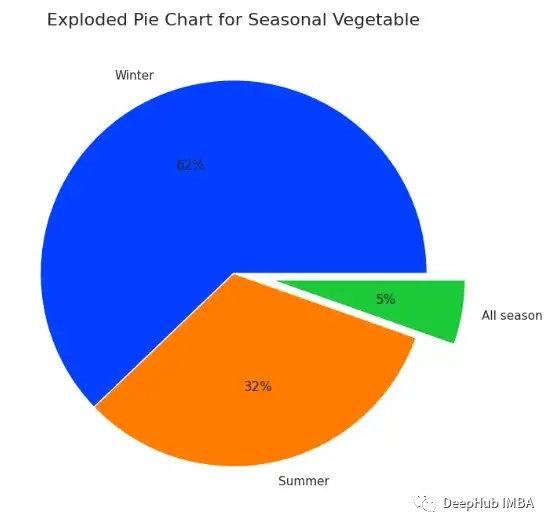
Distribution Plot
分布图可以显示连续变量的分布。
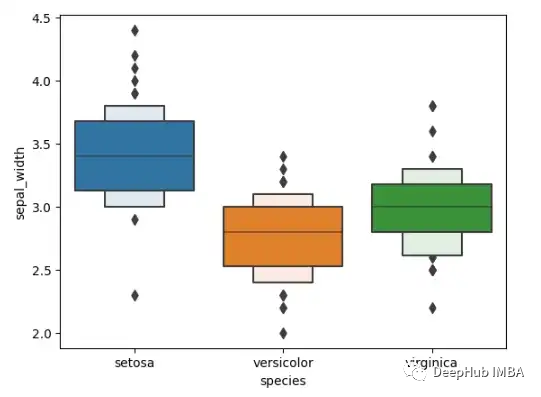
Box Plot
箱线图是一种基于五数汇总(“最小值”、第一四分位数 [Q1]、中位数、第三四分位数 [Q3] 和“最大值”)显示数据分布的标准化方法。它可以显示异常值等信息。

中级数据可视化
中级的可视化图表是对基础可视化图表的延伸,我们这里总结了8个图表。
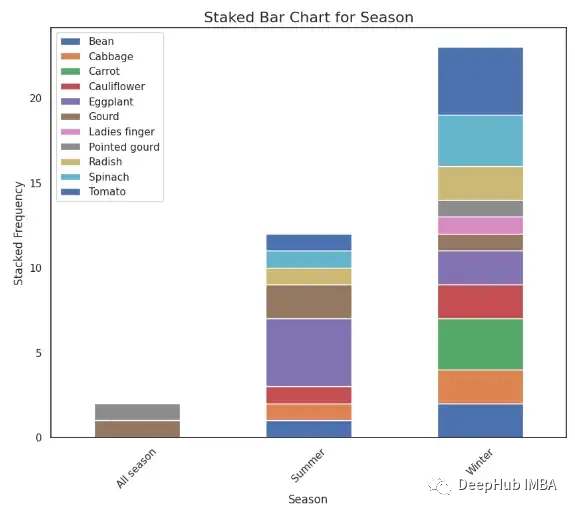
Stacked Bar Chart
堆叠柱状图是一种特殊的柱状图。我们可以在堆叠柱状图中集成比传统柱状图[2]更多的信息。
Grouped Bar Chart
“分组柱状图”这个名字意味着——它是一种分成不同组的特殊类型的柱状图。它主要用于比较两个分类变量。

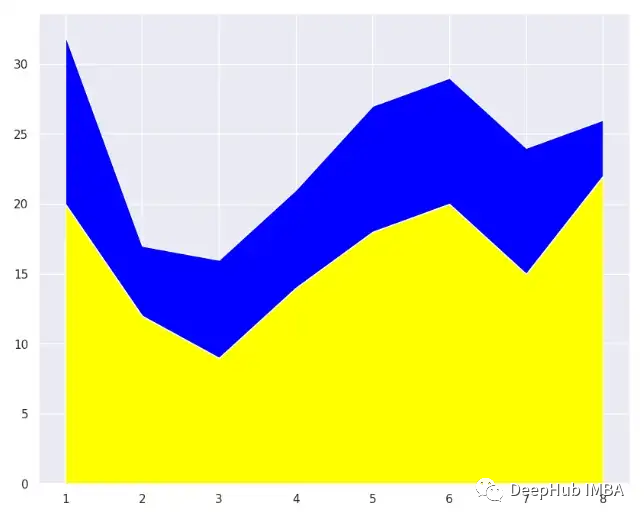
Stacked Area Chart
堆叠面积图将几个区域序列叠加在一起进行绘制。每个序列的高度由每个数据点中的值决定。
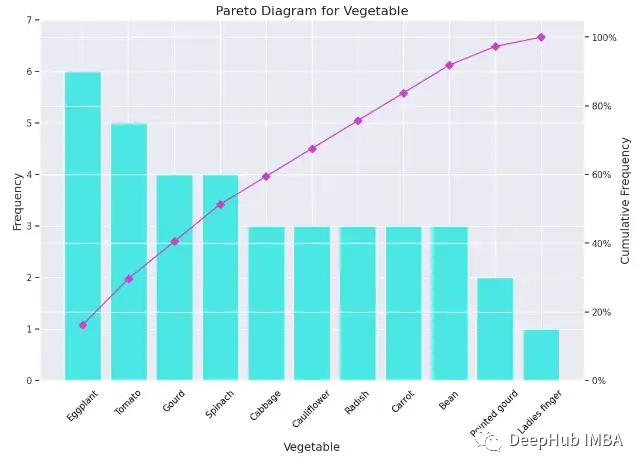
Pareto Diagram
帕累托图包括柱状图和折线图,其中各个值由柱状图降序表示,直线表示累计总数。
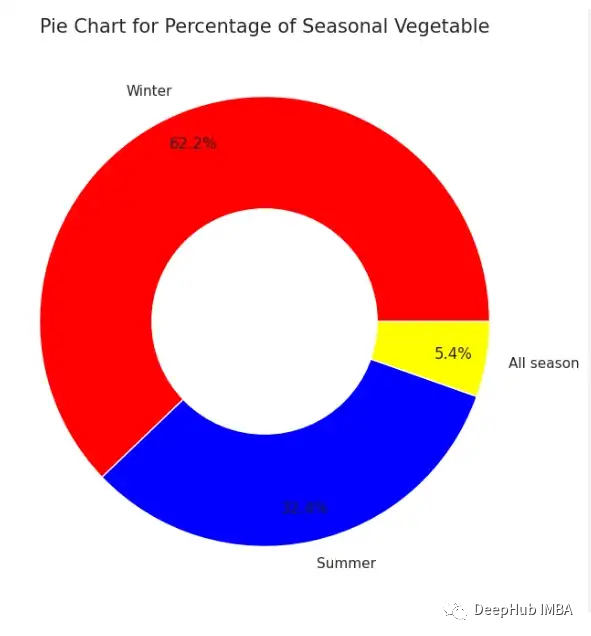
Donut Chart
环形图是一个以圆心为切口简单的饼状图。虽然它和饼图表达的意思是一样的,但它也有一些优点:在饼图中我们经常会混淆每个类别所共享的区域。由于饼图的中心从环形图中移除,所以它可以强调读者要关注饼图的外弧线,同时内圈也可以用来显示额外的信息。
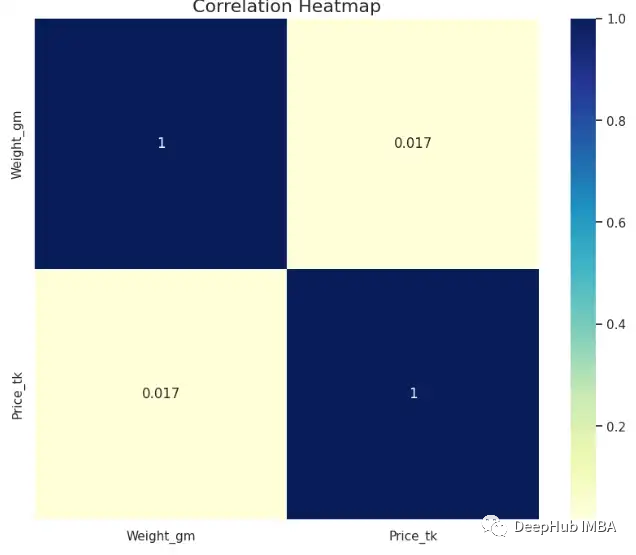
Heatmap
热图是一个可以分为多个子矩形的矩形图,它用不同颜色表示不同的值/强度。
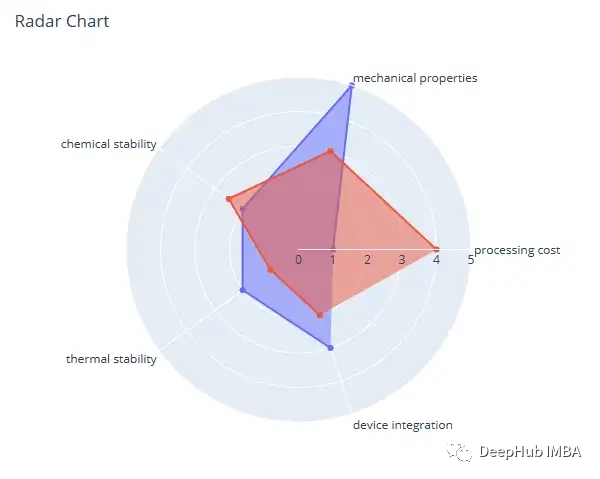
Radar Chart
雷达图是一种以二维图表的形式显示多元数据的图形方法,三个或更多变量在从同一点开始的轴上进行表示。来自中心的辐条称为半径,代表变量的数值。半径之间的角度不包含任何信息。
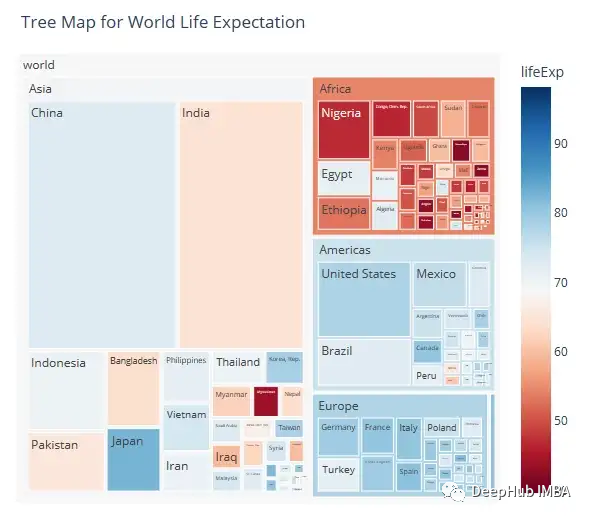
Treemap
矩形树图用嵌套的矩形形式显示层次数据。
高级数据可视化
这些图都比较复杂,一般情况下可能也不太常见,但是在处理特定任务时却非常好用。这里总结了10个相关的图表。
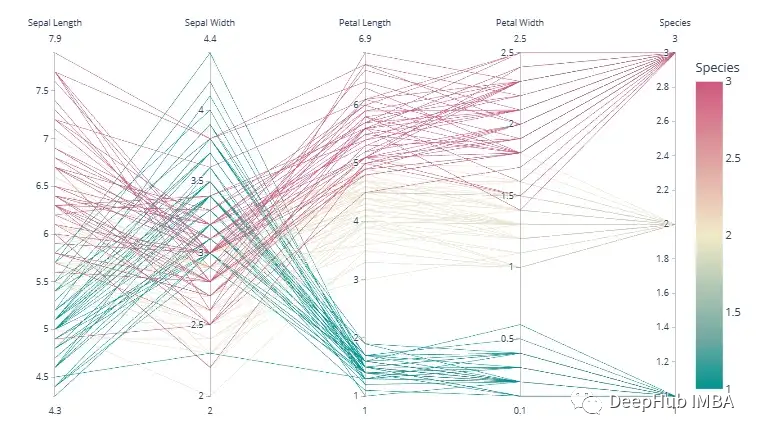
Parallel Coordinate Plot
因为我们生活在三维空间,所以一般的可视化最多处理3维的数据。但有时需要可视化超过 3 维的数据,我们经常使用 PCA 或 t-SNE 来降维并绘制它。在降维的情况下,可能会丢失大量的信息。并且有时我们需要考虑所有特征,这时就需要平行坐标图。
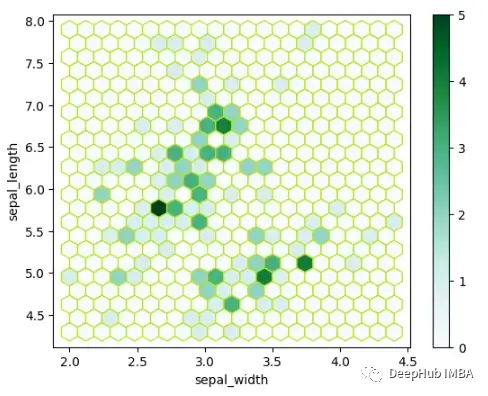
Hexagonal Binning
六边形分箱图是用六边形直观表示二维数值数据点密度方法。
Contour Plot
2D等高线密度图是可视化特定区域内数据点密度的另一种方法。它可以方便地找到两个数值变量的密度。例如下面的图表显示了每个阴影区域中有多少个数据点。
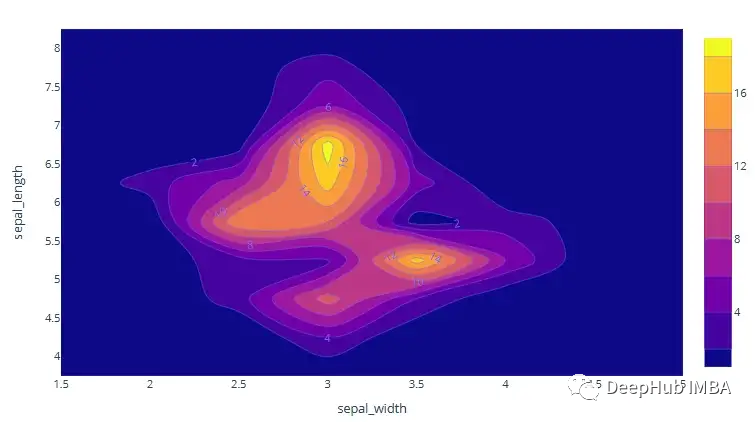
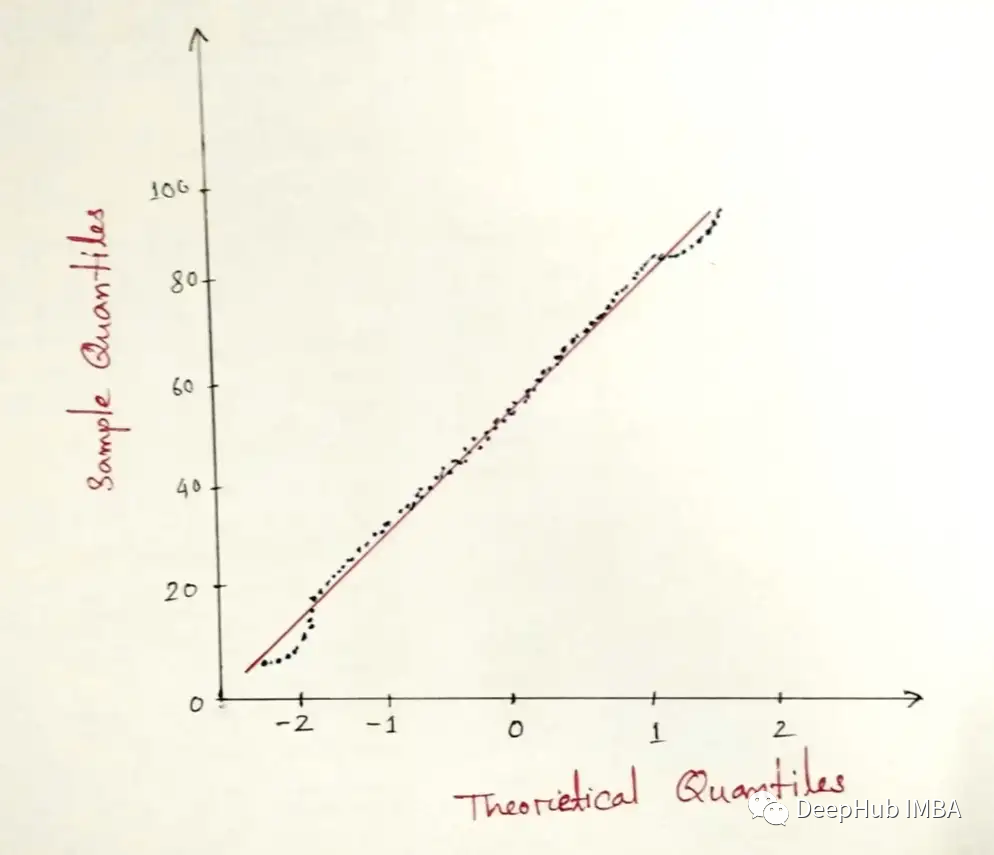
QQ-Plot
QQ代表分位数-分位数图。这是一种直观地检查数值变量是否符合正态分布的方法。
Violin Plot
小提琴图和箱形图是相关的。从小提琴图中可以得到的另一个信息是密度分布。简单地说它是一个与密度分布集成的箱形图。

Boxen Plot
Boxen Plot是seaborn库引入的一种新型箱形图。对于箱线图的方框是在四分位上创建的。但在Boxen plot中,数据被划分为更多的分位数。它可以提供了关于数据的更多见解。
Point Plot
点坐标图包含了一些名为误差线的线的折线图。
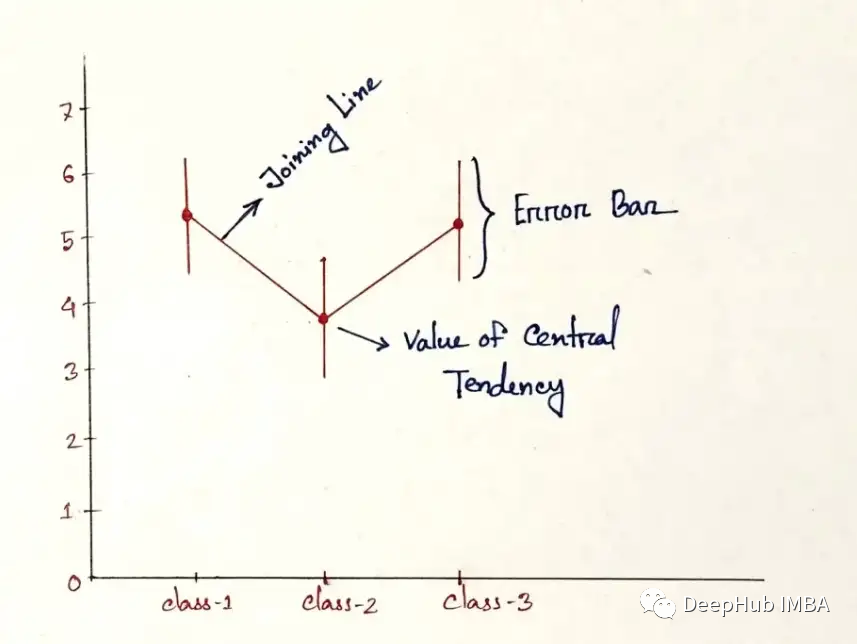
通过上图所示的点的位置来表示数值变量的集中趋势,误差线表示变量的不确定性(置信区间)。绘制折线图是为了比较数值变量在不同类别值下的变异性。
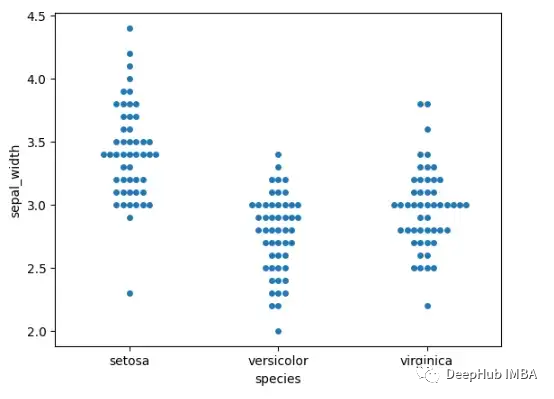
Swarm plot
分簇散点图是另一个受“beeswarm”启发的有趣图表,我们可以了解不同的分类值如何沿数值轴分布 。
Word Cloud
在词云图中,所有的单词都被绘制在一个特定的区域,频繁出现的单词被高亮显示用较大的字体显示。

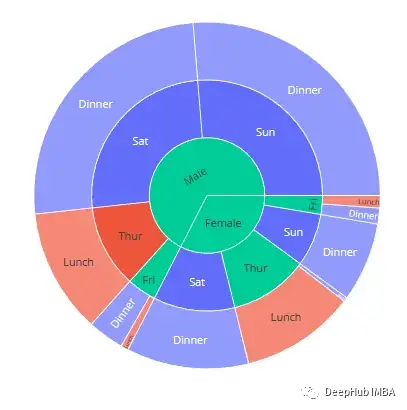
Sunburst Chart
旭日图是环行图或饼图的定制版本,它将一些额外的层次信息集成到图中。
地理空间数据可视化
地理空间数据可视化侧重于数据与其物理位置之间的关系,地理空间可视化的独特之处在于其规模都不较大。
地理可视化将变量叠加在地图上,使用纬度和经度来显示信息。
地图是地理空间可视化的主要焦点。它们的范围从描绘街道、城镇、公园或分区到显示一个国家、大陆或整个星球的边界。它们充当额外数据的容器。它们可以帮助识别问题、跟踪变化、理解趋势,并执行与特定地点和时间相关的预测。所以这里单独将其提出说明
一些用于地理空间数据可视化的python库和工具
tableau, power b.i., ArcGIS, QGIS等都可以用于复杂的地理空间数据可视化。python中也有很多也非常适合地理空间数据可视化的库,例如
Geoplot Folium Geopandas PySAL rworldmap rworldxtra 等等
我将使用Folium来展示可视化的一些实现。
这里使用了HIFLD的医院数据集,其中包含医院位置和其他医院信息。根据授权信息这个数据是可以被公开展示的
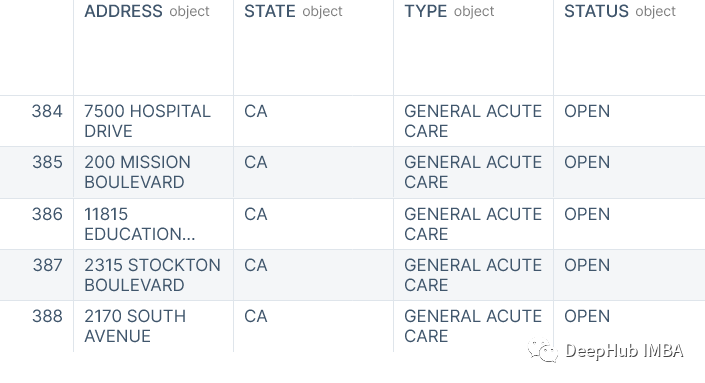
主数据集中有34个特征。出于演示目的,我将使用“ADDRESS”、“STATE”、“TYPE”、“STATUS”、“POPULATION”、“LATITUDE”、“LONGITUDE”这些特征。其中“LATITUDE”和“LONGITUDE”将用于确定医院在地图上的位置,而其他列如STATE、TYPE和STATUS用于过滤,最后ADDRESS和POPULATION用作自定义地图上的标记的元数据。
绘制基本地图
导入绘制地图所需的库:
import pandas as pdimport foliumfrom folium.plugins import MarkerCluster
加载数据集:
hosp_df = pd.read_csv('/work/Hospitals.csv')过滤数据:
WORKING_COLS = ["ADDRESS", "STATE", "TYPE", "STATUS", "POPULATION", "LATITUDE", "LONGITUDE"]STATE = "CA"hosp_df = hosp_df.loc[hosp_df["STATE"] == STATE, WORKING_COLS]hosp_df.head(5)
一些数据预处理:
hosp_df = hosp_df[hosp_df["POPULATION"] >= 0]hosp_df.describe()

绘制地图
Folium提供了.Map() ,它将位置参数作为包含一对纬度和经度的列表,并围绕给定位置生成一个地图,自动将生成的地图会围绕数据居中。
m=folium.Map(location=[hosp_df["LATITUDE"].mean(), hosp_df["LONGITUDE"].mean()],zoom_start=6)m
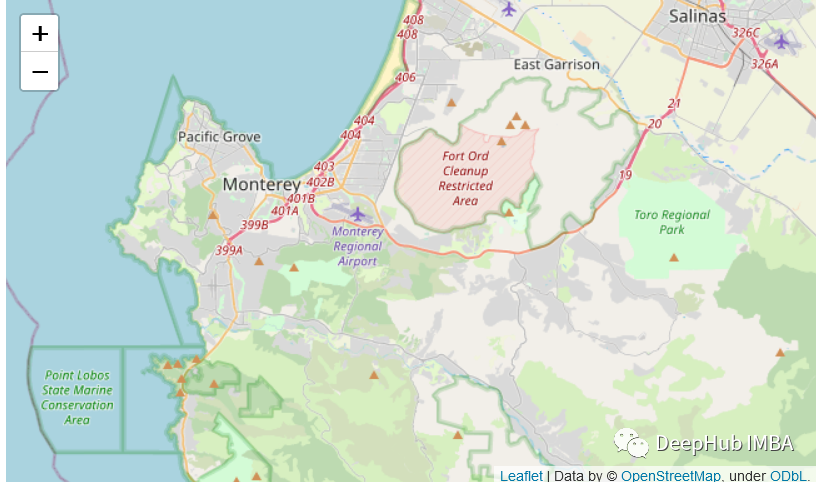
图中三角的点就是我们数据集中包含的数据点
添加图层
Folium 中的默认地图是 OpenStreetMap。我们可以添加具有不同图层,例如 Stamen Terrain、Stamen Water Color、CartoDB Positron 等,得到不同的图层表示。
使用 folium.TileLayer 将多个图层添加单个地图中,并使用folium.LayerControl以交互方式进行切换。
m=folium.Map(location=[hosp_df["LATITUDE"].mean(), hosp_df["LONGITUDE"].mean()],zoom_start=6)folium.TileLayer('cartodbdark_matter').add_to(m)folium.TileLayer('cartodbpositron').add_to(m)folium.TileLayer('Stamen Terrain').add_to(m)folium.TileLayer('Stamen Toner').add_to(m)folium.TileLayer('Stamen Water Color').add_to(m)folium.LayerControl().add_to(m)m
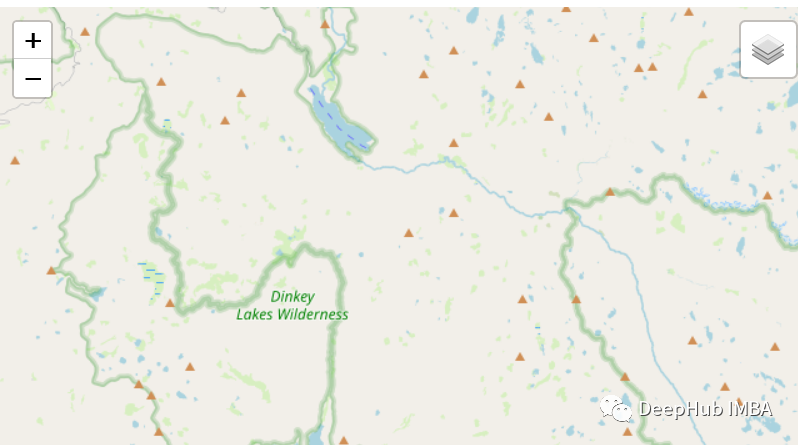
可以看到右上角出现了图层选择的按钮。
生成地图标记
在交互式地图中,标记对于指定位置非常重要。folium.Marker可以在给定位置创建一个标记。
m=folium.Map(location=[hosp_df["LATITUDE"].mean(), hosp_df["LONGITUDE"].mean()],zoom_start=8)hosp_df.apply(lambda row: folium.Marker(location=[row['LATITUDE'], row['LONGITUDE']]).add_to(m),axis=1)m
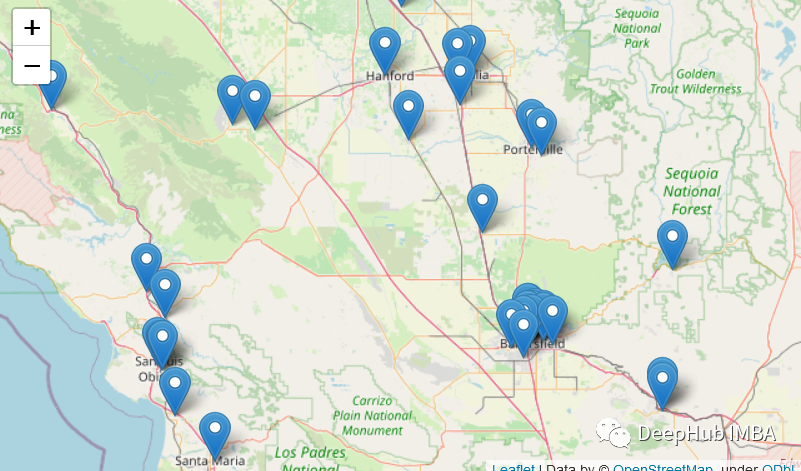
自定义标记
也可以使用自定义标记:
m=folium.Map(location=[hosp_df['LATITUDE'].mean(), hosp_df['LONGITUDE'].mean()],zoom_start=8)def get_icon(status):if status == "OPEN":return folium.Icon(icon='heart',color='black',icon_color='#2ecc71')else:return folium.Icon(icon='glyphicon-off',color='red')hosp_df.apply(lambda row: folium.Marker(location=[row['LATITUDE'], row['LONGITUDE']],#color='red',popup=row['ADDRESS'],tooltip='<h5>Click here for more info</h5>',icon=get_icon(row['STATUS']),).add_to(m),axis=1)m

生成气泡图
为了表示地图上的数值,我们可以通过将圆半径与其在数据集中的值绑定来绘制不同大小的圆。在我们的例子中,我们用每个中心表示覆盖的人口,其半径与其population值成正比。
m=folium.Map(location=[hosp_df['LATITUDE'].mean(), hosp_df['LONGITUDE'].mean()],zoom_start=8)def get_radius(pop):return int(pop / 20)hosp_df.apply(lambda row: folium.CircleMarker(location=[row['LATITUDE'], row['LONGITUDE']],radius=get_radius(row['POPULATION']),popup=row['ADDRESS'],tooltip='<h5>Click here for more info</h5>',stroke=True,weight=1,color="#3186cc",fill=True,fill_color="#3186cc",opacity=0.9,fill_opacity=0.25,).add_to(m),axis=1)m
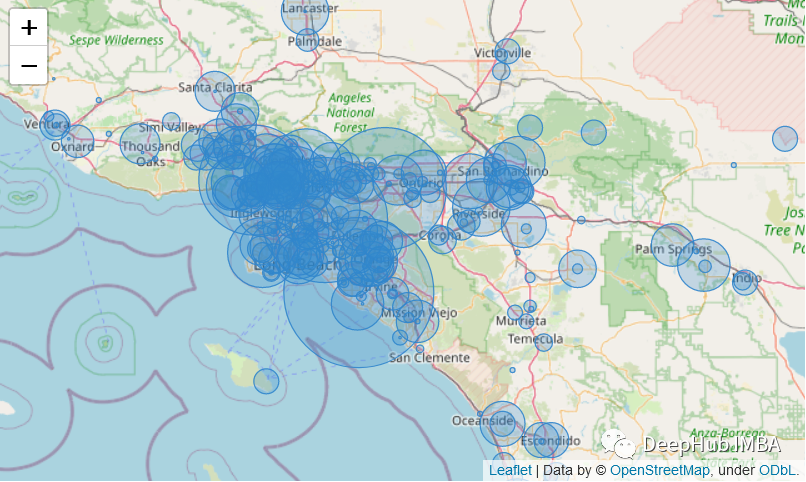
生成标记簇
在数据点密集地图上工作时,使用标记簇可以以避免许多附近标记相互重叠造成的混乱的情况。Folium 提供了一种设置标记簇的简单方法,将它们添加到 folium.plugins.MarkerCluster 实例。
m=folium.Map(location=[hosp_df['LATITUDE'].mean(), hosp_df['LONGITUDE'].mean()],zoom_start=8)cluster = MarkerCluster(name="Hospitals")def get_icon(status):if status == "OPEN":return folium.Icon(icon='heart',color='black',icon_color='#2ecc71')else:return folium.Icon(icon='glyphicon-off',color='red')hosp_df.apply(lambda row: folium.Marker(location=[row['LATITUDE'], row['LONGITUDE']],popup=row['ADDRESS'],tooltip='<h5>Click here for more info</h5>',icon=get_icon(row['STATUS']),).add_to(cluster),axis=1)cluster.add_to(m)m
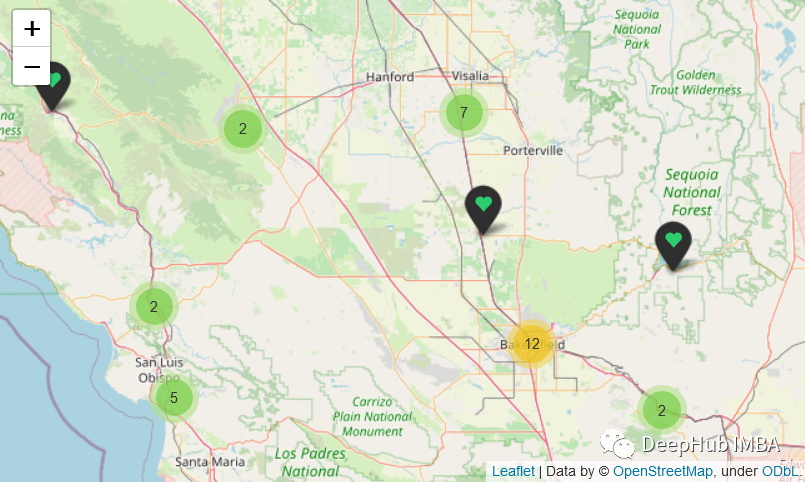
当鼠标悬停在一个标记上时,它会显示该簇所覆盖区域的边界。这种默认行为可以通过将showCoverageOnHover选项设置为false来取消,如下所示:
cluster = MarkerCluster(name="Hospitals", options={"showCoverageOnHover": False})总结
这篇文章有点长,但我完全相信它会对你有很大的帮助。我在本文中整理了几乎所有的可视化图表概述。这将是一篇关于数据可视化的完整文章,尤其是展示了地理位置可视化的一些方法,希望这篇文章对你有所帮助。
作者:Md. Zubair