
苹果M1芯片机器学习向测评:Mini 比RTX 2080Ti 快14%,Air好于Pro

极市导读
M1芯片在机器学习训练的时候,比RTX 2080Ti GPU快14%! >>加入极市CV技术交流群,走在计算机视觉的最前沿
今年双十一,苹果发布了新Mac系列,拿出了首款自研ARM架构的芯片。这款5nm制程的SoC(系统级芯片)号称大幅度提升了性能。
例如,新款MacBook Air相比于上一代,CPU性能提升3.5倍,GPU性能提升 5 倍,机器学习能力提升9倍,固态硬盘的性能也提升了 2 倍。
新款MacBook Pro,CPU性能比上一代提升了 2.8 倍,GPU提升5 倍,机器学习能力提升 11 倍。
新款Mac Mini,能效提高了60%,CPU速度提高了3倍,图形显示速度提高了6倍。

真实体验如何,众多UP主也在第一时间进行了测评,测评的内容包括:打游戏的速度、听音乐的音质、剪辑视频的效果......
但机器学习方面的测评相对稀少。真就如苹果发布会说的那样,机器学习速度能够提高数倍?在medium上,名为Daniel Bourke博主,发布了一篇博客,从机器学习训练测评的角度论证了苹果M1芯片的强大。
Bourke一共进行了两大块的实验:CreateML和TensorFlow macOS 代码。两个实验的结果都说明了新版M1芯片的电脑比“老”版本Intel芯片电脑运行速度要快。在其他博主的文章中,也有博文论证了:M1芯片在机器学习训练的时候,比RTX 2080Ti GPU快14%!
1 实验一:CreateML:Air好于Pro
在进行CreateML训练之前,作者说,他从未运行过CreateML。这次测评,也就是要看看这款专门为适配苹果而打造的机器学习平台到底有多强大。
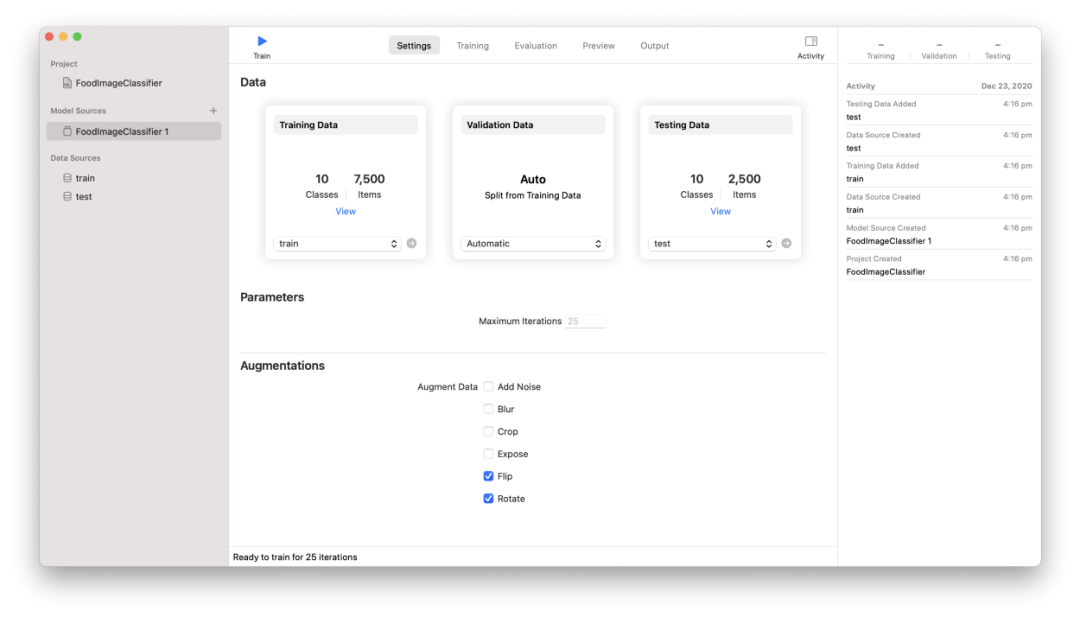
图注:训练操作界面
这次测试中,每台的Mac的设置如下:
问题:多类图像分类
模型:CreateML图像分类(不知道苹果使用的是什么网络架构,猜是ResNet)
数据大小:7500张训练图片,2500张测试图片
最大迭代次数:25
数据增强的方法:翻转,旋转

测评结果如上所示,没有风扇的MacBook Air表现最佳,7核GPU M1完爆MacBook Pro的8核M1 GPU。而16英寸的Macbook pro,在训练没结束之前就已经阵亡了。
很明显,苹果的CreateML平台已经针对M1芯片进行了潜在的优化。因为,尽管拥有8核专用GPU,Intel驱动的MacBook Pro却没能完成实验。
2 实验二:TensorFlow macOS
在11月份M1芯片发布会上,苹果声称新款自研芯片比前几代产品有更快的运行的速度,并特别提到了“类似TensorFlow这样的深度学习框架”。
然后作者从TensorFlow团队和Apple Machine Learning团队发布的博客文章中,找到机器学习模型在搭载M1芯片和Intel芯片的Mac电脑上的训练结果。
事实证明,苹果最近根据TensorFlowTensor发布了Flow_MacOS,这意味着其允许开发者能够在Mac上运行“原生”TensorFlow代码”。
于是,作者奇迹般的将Apple的TensorFlow fork安装到了Python 3.8环境中,在没有进行8-10个小时的故障排除情况下,创建以下三个小实验。
第一个实验是:基础的卷积神经网络(CNN),具体模型设置代码如下图:

具体而言,作者复制了CNN解析网站上的CNN架构(TinyVGG),并使用了类似于CreateML测试的数据集。
问题:多类图像分类
模型:TinyVGG
数据:7500张训练图片,2500张测试图片
类的数量:10个
epochs的数量:5
Batch size: 32
注:CNN Explainer网址
https://poloclub.github.io/cnn-explainer/
第二个实验是使用EfficientNetB0进行迁移学习。因为当前,从头开始做模型非常麻烦。
作者使用现有的未经训练的架构,并根据具体的数据对其进行训练。或者使用像EfficientNet这样的预先训练的架构,并根据具体的数据对其进行微调。
问题:多类图像分类
模型:Headless EfficientNetBO
数据:750个训练图像,625个测试图像(2500×0.25的validation_steps参数)
类的数量:10个(来自Food101数据集)
epochs数:5
Batch size:4(由于M1没有足够的内存容量来处理较大的Batch size,所以需要较低的批Batch size,作者尝试了32、16、8,但它们都失败了)
第三个实验,是作者在浏览Apple的tensorflow_macos GitHub时,发现的一个问题线程(issue thread)。包含了在不同机器上运行的benchmark,所以作者决定把它加入到测试中。
问题:多类图像分类
模型:LeNet
数据:60,000张训练图片,10,000张测试图片(MNIST)
类的数量:10个
epochs的数量:5
Batch size: 32
3 TensorFlow代码测评结果
除了在MAC 上运行上述三个实验之外,作者还在GPU驱动的Google Colab上运行了(作者的策略是:在Google Colab上进行实验,需要时扩展到更大的云服务器上去)。
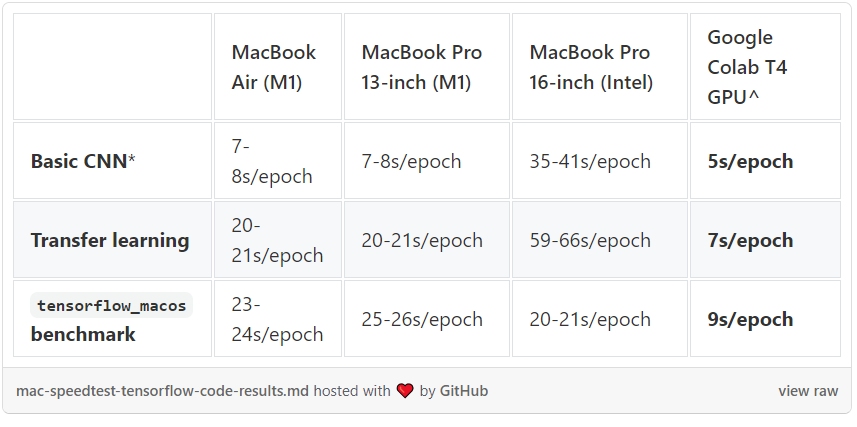
如上图所示,谷歌Colab表现最棒,但搭载M1芯片的MacBook也并没有落后太多。MacBook意味着能够在本地运行实验,无需一直连接到Colab,这会带来极大的方便。
注意,上述对比,由于数据加载,第一个epoch通常时间最长的,因此对比的是第二个epoch之后的训练时间。另外,Google Colab GPU实例使用的是纯TensorFlow而不是tensorflow_macos。
值得注意的是,在基本的CNN和迁移学习实验中,搭载M1电脑的表现明显优于搭载Intel的电脑。而tensorflow_macos基准测试中,Intel也收复了一些失地。作者认为这是明确在训练中使用GPU的结果。
M1 Mac Mini机器学习测评
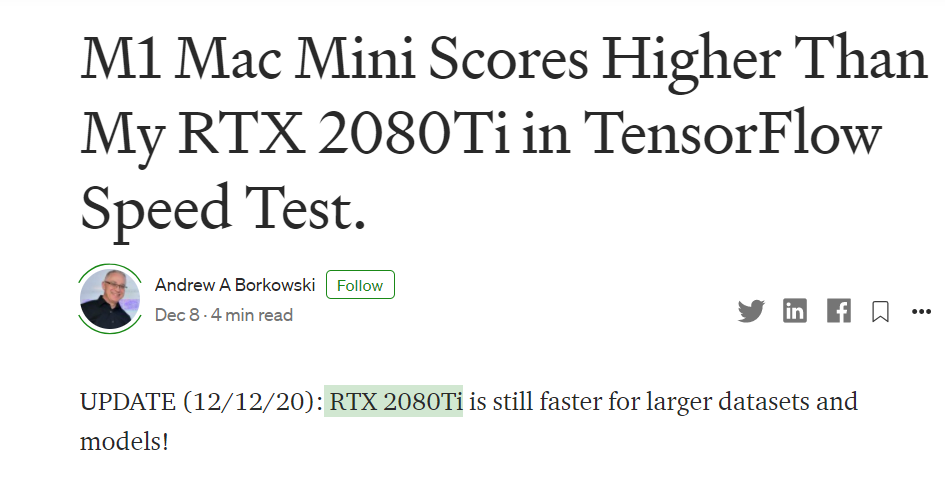
以上是对Air和pro两个版本的测评,那么新版的M1 Mac Mini效果如何呢?在另一篇medium博文上,Andrew A Borkowski测评发现,M1 Mac Mini的训练速度比RTX 2080Ti还要快。
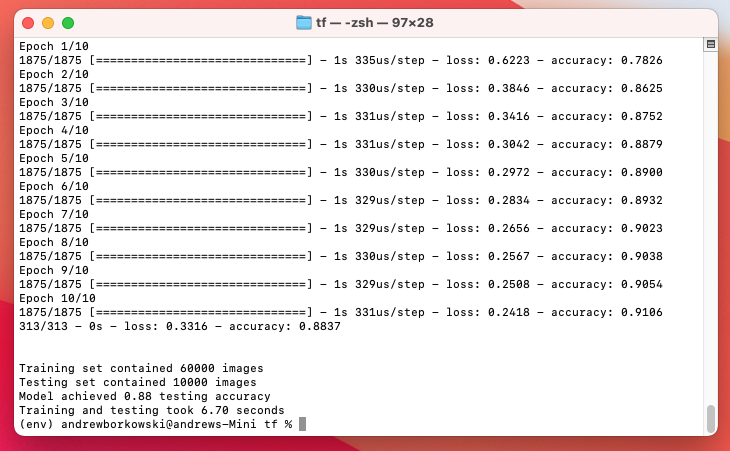
具体而言,是作者根据苹果GitHub网站的说明在Mac Mini上安装了tensorflow_macos,并完成了fashi-MNIST数据集中的分类任务。测试结果是:训练和测试耗时6.70秒,比RTX 2080Ti GPU快14%!
注:RTX 2080Ti 的试验配置是System: Linux;CPU:Intel® Core™ i7–9700K;RAM: 32GB;Storage: 1TB SSD。而苹果电脑的配置是:System: macOS Big Sur;Storage: 512GB SSD;Unified Memory: 8GB ;M1芯片包含8个CPU核,8个GPU核以及16个神经网络引擎核心。
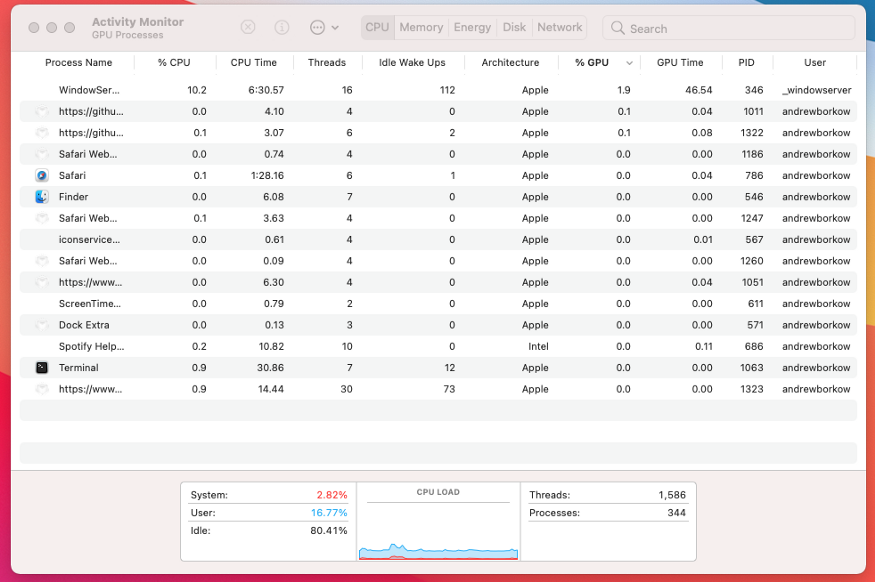
但,在数据集较大的模型上,M1 Mac Mini用了2286.16秒。比使用Nvidia RTX 2080Ti GPU的Linux机器要长5倍多!根据Mac的活动监控器,CPU的使用量极少,完全没有使用到GPU。
总结一下:由于M1 TensorFlow目前还是Alpha版本,未来有希望利用芯片的GPU和神经引擎内核来加速机器学习训练。
参考资料:
https://towardsdatascience.com/apples-new-m1-chip-is-a-machine-learning-beast-70ca8bfa6203
推荐阅读
