
单卡RTX 2080Ti 搞定大模型训练!
大模型训练
转自:机器之心
任何 transformer 变体、任何数据集都通用。
在一块消费级 GPU 上只用一天时间训练,可以得到什么样的 BERT 模型?
最近一段时间,语言模型再次带火了 AI 领域。预训练语言模型的无监督训练属性使其可以在海量样本基础上进行训练,并获得大量语义语法知识,不论分类还是问答,似乎没有 AI 解决不了的问题。
然而,大模型既带来了技术突破,也对算力提出了无穷无尽的需求。
最近,来自马里兰大学的 Jonas Geiping、Tom Goldstein 讨论了所有关于扩大计算规模的研究,深入探讨了缩小计算规模的改进方向。他们的研究引发了机器学习社区的关注。
在新研究中,作者对于单块消费级 GPU(RTX 2080Ti)能训练出什么样的语言模型进行了讨论,并获得了令人兴奋的结果。让我们看看它是如何实现的:
模型规模的扩展
在自然语言处理(NLP)领域,基于 Transformer 架构的预训练模型已经成为主流,并带来诸多突破性进展。很大程度上,这些模型性能强大的原因是它们的规模很大。随着模型参数量和数据量的增长,模型的性能会不断提高。因此,NLP 领域内掀起了一场增大模型规模的竞赛。
然而,很少有研究人员或从业者认为他们有能力训练大型语言模型(LLM),通常只有行业内的科技巨头拥有训练 LLM 的资源。
为了扭转这一趋势,来自马里兰大学的研究者进行了一番探索。
论文
《Cramming: Training a Language Model on a Single GPU in One Day》
:

论文链接:https://arxiv.org/abs/2212.14034
这个问题对于大多数研究人员和从业者来说具有重要意义,因为这将成为模型训练成本的参考,并有望打破 LLM 训练成本超高的瓶颈。该研究的论文迅速在推特上引发关注和讨论。

IBM 的 NLP 研究专家 Leshem Choshen 在推特上评价道:「这篇论文总结了所有你能想到的大模型训练 trick。」
马里兰大学的研究者认为:如果按比例缩小的模型预训练是大型预训练的可行模拟,那么这将开启一系列目前难以实现的大规模模型的进一步学术研究。
此外,该研究尝试对过去几年 NLP 领域的整体进展进行基准测试,而不仅仅局限于模型规模的影响。
该研究创建了一项称为「Cramming」的挑战 —— 在测试前一天学习整个语言模型。研究者首先分析了训练 pipeline 的方方面面,以了解哪些修改可以实际提高小规模模拟模型的性能。并且,该研究表明,即使在这种受限环境中,模型性能也严格遵循在大型计算环境中观察到的扩展定律。
虽然较小的模型架构可以加快梯度计算,但随着时间的推移,模型改进的总体速度几乎保持不变。该研究尝试利用扩展定律在不影响模型大小的情况下通过提高梯度计算的有效率获得性能提升。最后,该研究成功训练出性能可观的模型 —— 在 GLUE 任务上接近甚至超过 BERT—— 而且训练成本很低。
资源有限
为了模拟普通从业者和研究人员的资源环境,该研究首先构建了一个资源受限的研究环境:
一个任意大小的基于 transformer 的语言模型,完全从头开始使用掩码语言建模(masked-language modeling)进行训练;
pipeline 中不能包含现有的预训练模型;
任何原始文本(不包括下游数据)都可以包含在训练中,这意味着可以通过明智地选择如何以及何时对数据进行采样来实现加速,前提是采样机制不需要预训练模型;
原始数据的下载和预处理不计入总预算,这里的预处理包括基于 CPU 的 tokenizer 构造、tokenization 和 filtering,但不包括表征学习;
训练仅在单块 GPU 上进行 24 小时;
下游性能在 GLUE 上进行评估,GLUE 上的下游微调仅限于仅使用下游任务的训练数据进行简单训练(5 个 epoch 或者更少),并且需要使用为所有 GLUE 任务设置的全局超参数,下游微调不计算在总预算中。
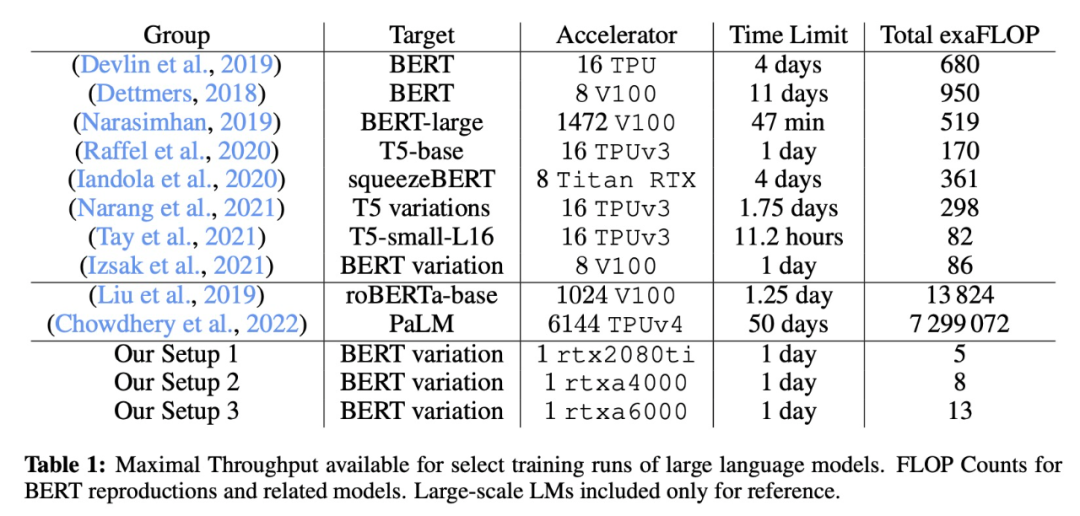
该研究与一些经典大模型的具体训练设置比较如下表所示:
改进方法
研究人员实施并测试了已有工作提出的一些修改方向,包括通用实现和初始数据设置,并尝试了修改架构、训练以及改动数据集的方法。
实验在 PyTorch 中进行,不使用特质化的实现以尽量公平,所有内容都保留在 PyTorch 框架的实现级别上,只允许可应用于所有组件的自动运算符融合,另外只有在选择了最终的架构变体之后,才会重新启用高效注意力内核。
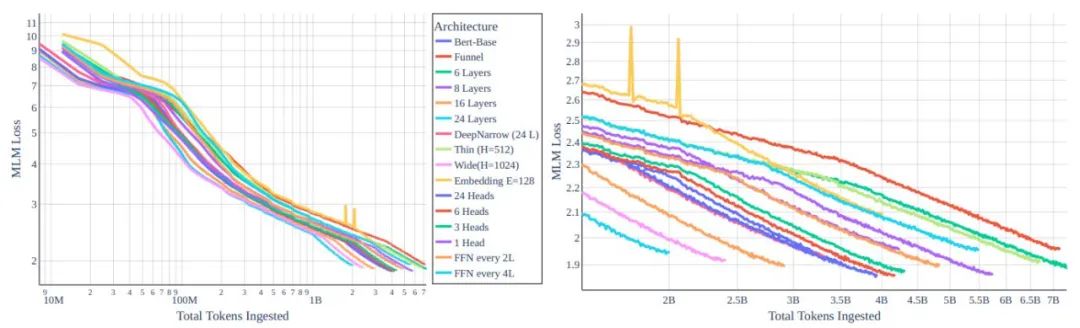
图 1:不同 transformer 架构变体 MLM 损失函数与 token 对比的情况。左:全局视图。右图:放大到 10e8 和更多 token 情况下。所有模型都用相同算力成本训练,我们可以看到:通过架构重塑实现的改进微乎其微。
有关提升性能,我们最先想到的方法肯定是修改模型架构。从直觉上,较小 / 较低容量的模型似乎在一日一卡式的训练中是最优的。然而在研究了模型类型与训练效率之间的关系后,研究人员发现缩放法则为缩小规模设置了巨大的障碍。每个 token 的训练效率在很大程度上取决于模型大小,而不是 transformer 的类型。
此外,较小的模型学习效率较低,这在很大程度上减缓了吞吐量的增加。幸运的是,在相同大小的模型中,训练效率几乎保持不变这一事实,意味着我们可以在参数量类似的架构中寻找合适的,主要根据影响单个梯度步骤的计算时间来做出设计选择。
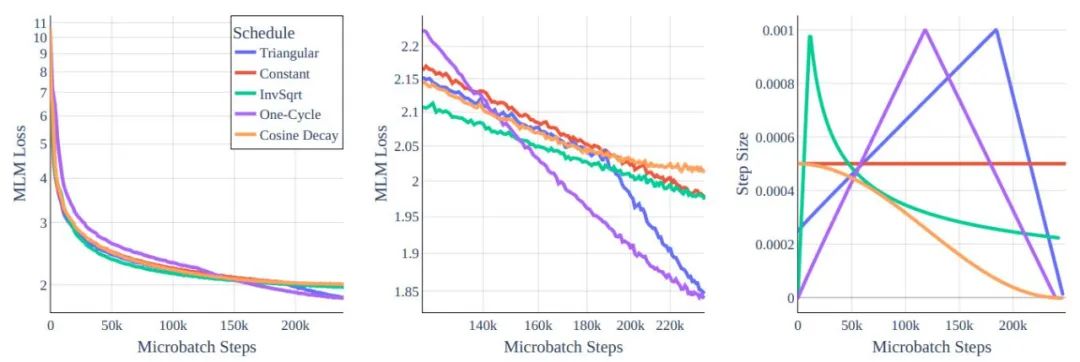
图 2:学习率 Schedule。尽管在全局范围内行为相似,但在中间的放大图里可以看到差异确实存在。
在该工作中,作者研究了训练超参数对 BERT-base 架构的影响。可以理解的是,原始 BERT 训练方法的模型在 Cramming 式训练要求中的表现不佳,因此研究人员重新审视了一些标准选择。
作者也研究了优化数据集的思路。扩展法则阻碍了通过架构修改取得重大收益的方式(超出计算效率),但缩放定律并不妨碍我们在更好的数据上进行训练。如果想在在每秒训练更多的 token,我们应该寻求在更好的 token 上训练。
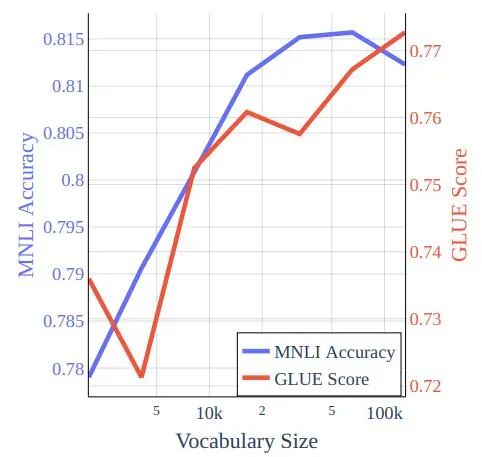
图 3:在 bookcorpus-wikipedia 数据的 Cramming 式训练中训练的模型的词汇量与 GLUE 分数和 MNLI 准确性。
在 GLUE 上的表现
研究人员系统地评估了 GLUE 基准的性能和 WNLI,并注意到在前面的部分中只使用了 MNLI (m),并且没有根据完整的 GLUE 分数调整超参数。在新研究中对于 BERT-base 作者微调了 5 个 epoch 的所有数据集,batch size 为 32,学习率为 2 × 10-5。对于 Cramming 训练的模型这不是最优的,其可以从 16 的 batch size 和 4 × 10−5 的学习率以及余弦衰减中获得微小的改进(此设置不会改进预训练的 BERT check point)。
表 3 和表 4 描述了此设置在 GLUE 下游任务上的性能。作者比较了原始的 BERT-base check point、在达到算力上限后停止的 BERT 预训练设置、Izsak 等人 2021 年研究中描述的设置和修改后的设置,为每块 GPU 设置训练一天。总体而言,性能出奇地好,尤其是对于 MNLI、QQP、QNLI 和 SST-2 等较大的数据集,下游微调可以消除完整 BERT 模型和 Cramming 设置变体之间的剩余差异。
此外,作者发现新方法与算力有限的普通 BERT 训练及 Izsak 等人描述的方法相比都有很大改进。对于 Izsak 等人的研究,其描述的方法最初是为一个完整的 8 GPU 刀片服务器设计的,并且在新的场景中,将其中的 BERT-large 模型压缩到较小的 GPU 上是导致大部分性能下降的原因。
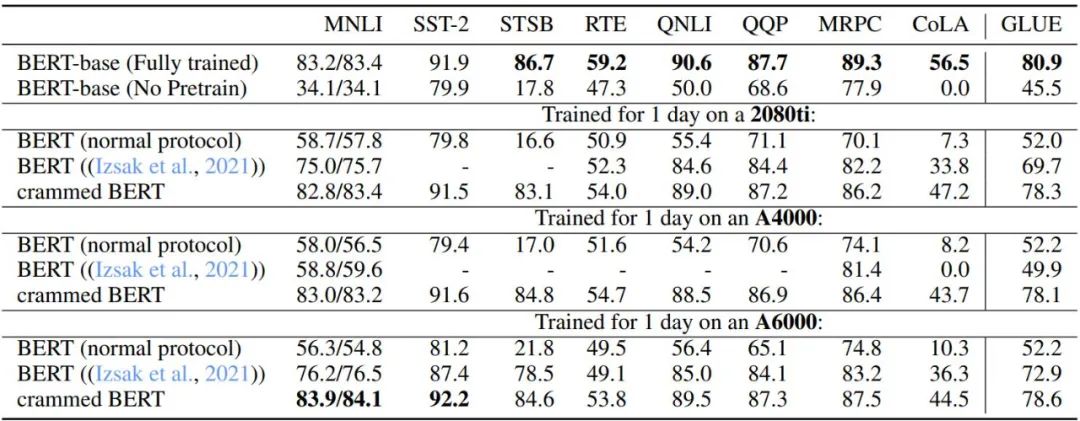
表格 3:基线 BERT 与 Cramming 版本模型的 GLUE-dev 性能比较。其中所有任务的超参数都是固定的,epoch 限制为 5 个,缺失值为 NaN。是为 8 GPU 刀片服务器设计的,而在这里,所有计算被塞进了一块 GPU。
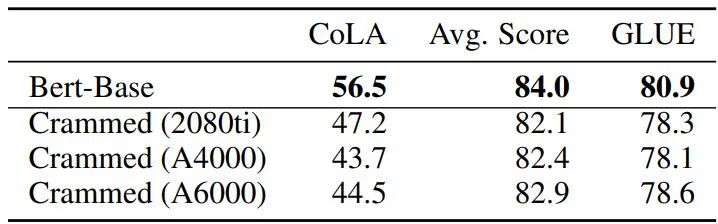
表格 4:基线 BERT 与填充模型的 GLUE-dev 性能比较。
总体而言,使用论文中的方法,训练结果已经非常接近原版 BERT,但要知道后者使用的总 FLOPS 是新方法 45-136 倍(在 16 块 TPU 上要花费四天时间)。而当训练时间延长 16 倍时(在 8 块 GPU 上训练两天),新方法的性能实际上比原始 BERT 提高了很多,达到了 RoBERTa 的水平。
总结
在该工作中,人们讨论了基于 transformer 的语言模型在计算量非常有限的环境中可以实现多少性能,值得庆幸的是,几条修改方向可以让我们在 GLUE 上获得不错的下游性能。研究人员表示,希望这项工作可以为进一步的改进提供一个基线,并进一步给近年来为 transformer 架构提出的许多改进和技巧提供理论支撑。
参考内容:
https://twitter.com/giffmana/status/1608568387583737856
https://www.reddit.com/r/MachineLearning/comments/zy8c99/r_cramming_training_a_language_model_on_a_single/
往期精彩:
深度学习论文精读[14]:Vision Transformer