
自监督学习看这篇就够了!
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
报道|人工智能前沿讲习
01
02
2.1 什么是基于数据恢复的自监督任务?
第一类任务也是使用最多的一类任务:数据生成任务。
自监督学习的出发点是考虑在缺少标签或者完全没有标签的情况下,依然学习到能够表示原始图片的良好有意义的特征。那么什么样的特征是良好有意义的呢?在第一类自监督任务——数据恢复任务中,能够通过学习到的特征还原生成原始数据的特征,我们认为是良好有意义的。看到这里,实际上大家能够联想到自动编码器类的模型,甚至更简单的PCA。实际上,几乎所有的非监督学习方法都是以这个原则作为基础的。现在十分流行的深度生成模型VAE(后面我会写一篇文章住专门介绍VAE,还在草稿箱里待着。。。)甚至更火的GAN也可以归为这一类方法。
GAN的核心是通过Discriminator去缩小Generator distribution和real distribution之间的距离。GAN的学习过程不需要人为进行数据标注,其监督信号也即是优化目标就是使得上述对抗过程趋向平稳(Goodfellow 想出这个点子真的天才)。
这里我们以两篇具体的paper为例子,介绍数据恢复类的自监督任务如何操作实现。我们的重点依然是视觉问题,这里分别介绍一篇图片上色的文章和一篇视频预测的文章。其余的领域比如NLP,其本质是类似的,在弄清楚了数据本身的特点之后,可以先做一些低级的照猫画虎的工作。
2.2 图片色彩恢复——瓢虫是红色的吗?
设计自监督任务时需要一些巧妙的思考。比如图片色彩恢复任务,我们已有的数据集是一张张的彩色图片,假如去掉色彩,作为感性思考者的我们,是否能够从黑白图片中显示的内容推测原来图片真实的色彩?对于一个婴儿来说可能很难,但是对于我们来说,生活的经历告诉我们瓢虫应当是红色的(下图第二行中)。我们是如何做出预测的?事实上,我们通过观察大量的瓢虫,在脑中建立了从“瓢虫”到“红色”的映射。

把这个学习过程推广到我们的模型上,在给定黑白输入的情况下,我们用正确的彩色的原始图像作为学习的标签,从而模型会试着理解原始黑白图像中“每个区域”是“什么”进而去建立从是“什么”到“不同颜色”的映射。
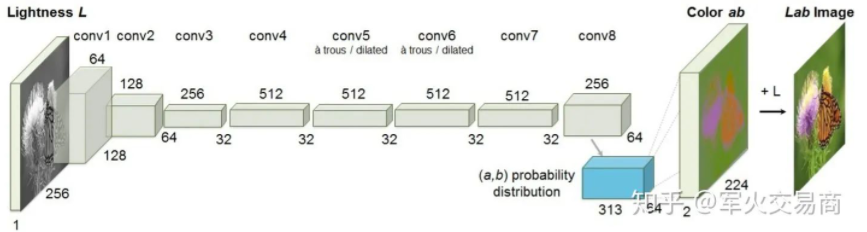
当我们完成训练,模型的中间层feature map就得到了类似人脑对于“瓢虫”以及其他物体的记忆,以向量的形式。
2.3 视频预测——下一秒你会在哪里?
一般来说,视觉问题分成图片和视频两大类,图片数据可以认为具有i.i.d特性,而视频是由多个图片帧构成的,可以认为具有一定的Markov dependency,时序关系是他们之间最大的不同。比如最简单的思路,利用CNN提取单张图片特征可以做图片分类,再加入一个RNN或者LSTM去刻画Markov Dependency,便可以应用到视频上。
视频预测任务十分的耿直。怎么形容呢,他就是那种,你知道的,我们说视频中帧与帧之间存在时空连续性。类似的,人类会利用这种帧与帧之间的连续性,当我们看电影时突然按了暂停,下一秒下几秒会发生什么实际上我们是可以预测的。
同样,把这个学习过程推广到我们的模型上,在给定前一帧或者前几帧的情况下,我们用后续的视频帧作为学习的标签,从而模型会试着理解给定视频帧中的语义信息(发生了啥?)进而去建立从当前到未来的映射关系。

References
https://arxiv.org/abs/1603.08511
N. Srivastava, E. Mansimov, and R. Salakhutdinov, “Unsuper- vised Learning of Video Representations using LSTMs,” in ICML, 2015.
03
第二类自监督学习任务——基于数据变换的任务。事实上,人们现在常常提到的自监督学习通常指的是这一类自监督任务,我个人认为是比较狭义的概念。
用一句话说明这一类任务,事实上原理很简单。对于样本  ,则自监督任务的目标是能够对生成的
,则自监督任务的目标是能够对生成的 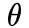 。
。
下面介绍一种原理十分简单但是目前看来非常有效的自监督任务——Rotation Prediction。
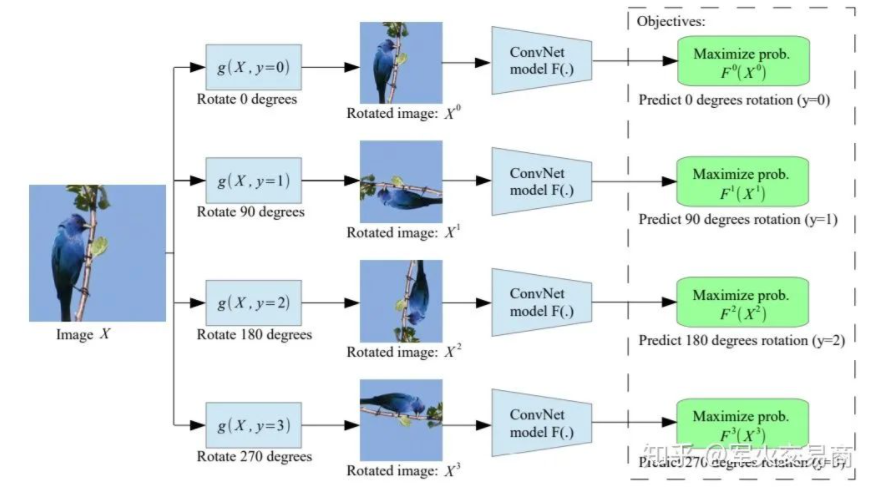
给定输入图片
我始终坚持的观点是自监督学习需要动机明确,这里我们能做的任意变换应当是对目标有益的。比如在Rotation Prediction中,作为人类的我们只有在理解了图片中是一只鸟站在枝头之后才知道X_0的旋转角度应当是。那么我们有理由相信,当模型能够做出同样正确的判断时,其中间的feature map必然携带了有意义的图片语义信息。
参考地址:
https://zhuanlan.zhihu.com/p/125721565
https://zhuanlan.zhihu.com/p/129067097
https://zhuanlan.zhihu.com/p/136108863