
深度学习领域,你心目中 idea 最惊艳的论文是哪篇?

文章转载自知乎问答,仅作学术分享,著作权归属原作者,如涉侵权请联系删除。
https://www.zhihu.com/question/440729199
科研路上我们往往会读到让自己觉得想法很惊艳的论文,心中对不同的论文也会有一个排名。希望本问题下大家能分享自己心目中的排名,同时相互学习。
抛砖引玉,我个人认为最惊艳的一篇论文是Hourglass作者的Associate Embedding(姿态识别)发表于NIPS 2017。
王晋东不在家(微软亚研 Researcher)回答:
有两个: ResNet和Transformer。
时至今日,许多大领域都离不开这两种结构。Transformer更是从NLP领域走入了CV领域,大有一统天下之势。
ResNet大道至简,更倾向于从原来的CNN结构设计出发,通过大量的实验和分析,添加了skip connection,一招封神。
Transformer则另起炉灶,干脆完全抛弃了RNN的结构,从根本上尝试self-attn加全连接层对于序列建模的能力。
今日的你或许通过实验可以大概搞出来ResNet的skip connection结构,但是能想出来跟transformer一样完全不用RNN、并能让这种当时看来“非主流”的结构work的比RNN还好,就能称得上是天才了。
这其中,固然要有科研的敏锐嗅觉,更多的还是源于超强的代码能力,以及愿意为你这种尝试提供资金和设备支持的大环境。
所以说,要想取得绝对的成功,天时(CNN与NLP发展的大环境)、地利(所在单位的资源投入)、人和(老板与同事的支持),三者缺一不可。

rainy(3D视觉/深度学习)回答:
来分享一篇小众方向(视频增稳/Video Stabilization)的论文,可能不是那种推动领域进步的爆炸性工作,这篇论文我认为是一篇比较不错的把传统方法deep化的工作。
https://arxiv.org/pdf/2011.14574.pdf
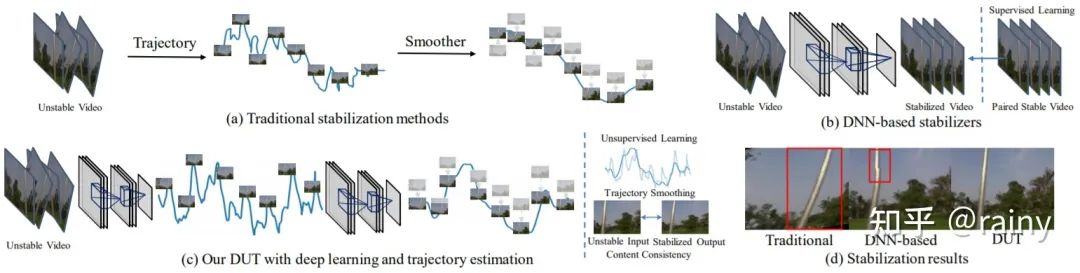
看样子应该是投稿CVPR21,已开源。
https://github.com/Annbless/DUTCode
首先介绍一下视频增稳的定义,如名称所示,视频增稳即为输入一系列连续的,非平稳(抖动较大)的视频帧,输出一系列连续的,平稳的视频帧。
由于方向有点略微小众,因此该领域之前的工作(基于深度学习)可以简单分为基于GAN的直接生成,基于光流的warp,基于插帧(其实也是基于光流的warp)这么几类。这些论文将视频增稳看做了“视频帧生成问题”,但是理想的视频增稳工作应该看做“轨迹平滑”问题更为合适。
而在深度学习之前刘帅成大神做了一系列的视频增稳的工作,其中work的即为meshflow。这里贴一个meshflow解读的链接
https://www.yuque.com/u452427/ling/qs0inc
总结一下,meshflow主要的流程为“估计光流-->估计关键点并筛选出关键点的光流-->基于关键点光流得到mesh中每一个格点的motion/轨迹-->进行轨迹平滑并得到平滑后的轨迹/每一个格点的motion-->基于motion得到满足平滑轨迹的视频帧”。
总结了meshflow之后,这篇DUT主要进行的工作其实很简单,在meshflow的框架下,将其中所有的模块都deep化:
LK光流---->PWCNet
SIFT关键点----->RFNet
基于Median Filters的轨迹平滑------>可学习的1D卷积
除此之外,由于原始的meshflow是基于优化的方法,因此DUT在替换了模块之后依旧保留了原始的约束项,并且可以使用无监督的方式完成训练,效果也好于一票supervised的方法。
波尔德回答:
搞3D的举双脚提议:PointNet/PointNet++。
时间回到2017年之前,那时候想用深度学习处理点云基本只有体素化一条路。那时候稀疏卷积还没有技术上实现,dense 3D CNN处理一下简单CAD模型还行,放到高分辨率的点云上分分钟就会塞爆显存。
PointNet的motivation非常清楚,设计一种网络,可以直接提取点云特征(丢掉体素化),并且保证顺序不变性(从invariance出发设计网络)。具体的实现就是MLP加global max pooling。非常简洁直观。
PointNet++基本是同时期的论文。在PointNet的基础上进了一步,引入了CNN常见的上采样和下采样操作。相当于在不同的scale level上提取特征。
不像图像有CNN,NPL有Transformer。点云处理这一块至今没有一统江湖的最佳基本结构。PointNet开了个头,从此,深度学习方法可以直接处理点云了。新的基本结构一天冒出来八个,基于稀疏卷积的,基于kernel的,基于图卷积的,基于欧氏空间的,基于特征空间的,把transformer借过来用的,以及魔改上述一切的等等。
然而大部分新结构都摆不脱PointNet/PointNet++的影子。
陀飞轮(复旦大学 微电子硕士)回答:

当年看Deformable Convolutional Networks(DCN)的时候最为惊艳,可能看过的文章少,这种打破固定尺寸和位置的卷积方式,让我感觉非常惊叹,网络怎么能够在没有直接监督的情况下,学习到不同位置的offset的,然后可视化出来,能够使得offset后的位置能够刚好捕捉到不同尺寸的物体,太精彩了!
hello 回答:
如果你试过从头开始把一项工作做work,而不是在别人做work的工作上替换掉一个模块,那么这个答案除了AlexNet就不会有其他。
七年前我写第一行深度学习代码的时候觉得自己跟Alex有十年的差距,到了现在觉得这个差距还是十年。
ShiCai Yang(海康威视研究院 算法工程师)回答:
当然是AlexNet论文。
我直到现在,还是很好奇,在当时的情况下,Alex是怎么把这个8层网络设计出来,并调参成功,性能提升到那种水平的,对他的任务执行路径非常好奇,尤其是其中经历了多少失败尝试!!!
推荐阅读
篇幅达2840页、目录就有31页,这位华人小哥的博士论文堪比教材

