
深度学习CV领域最瞩目的成果top46
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来源:Smarter
前言
如果06年Hinton的深度置信网络是深度学习时代的开启,12年的Alexnet在ImageNet上的独孤求败是深度学习时代的爆发,那么至今也有近15年的发展历程。15年足够让一个青涩懵懂的少年成长为一个成熟稳重的壮年。
本文盘点深度学习CV领域杰出的工作,由于本人方向相关,故从基础研究、分类骨架、语义分割、实例分割、目标检测、生成对抗、loss相关、部署加速、其他方面等筛选出最瞩目的成果。而对于无监督学习、弱监督学习、3D点云、图像配准、姿态估计、目标跟踪、人脸识别、超分辨率、NAS等领域,则不会纳入,或者有小伙伴建议的话,后面考虑收入。
注意,本次盘点具有一定的时效性,是聚焦当下的。有些被后来者居上的工作成为了巨人的肩膀,本文不会涉及。
本文会给出核心创新点解读和论文链接。如果你是大牛的话,可以自查一下。如果你是小白的话,这是一份入门指引。每个工作本文都会有网络结构或核心思想的插图,并会进行导读式解读。水平有限,欢迎讨论!
入围标准
承上启下,继往开来。或开启一个时代,或打开一个领域,或引领一个潮流,或造就一段历史。在学术界或工业界备受追捧,落地成果遍地开花。共同构建成深度学习的大厦,并源源不断地给后人输送灵感和启迪。
入围成果
基础研究:Relu,Dropout,Adam,BN,AtrousConv,DCN系列
分类骨架:VGG,ResNet(系列),SeNet,NIN,Inception系列,MobileNet系列,ShuffleNet系列
语义分割:FCN,U-Net,PSPNet,Deeplab系列
实例分割:Mask R-CNN,PanNet
目标检测:Faster R-CNN,Yolo系列,FPN,SSD,CenterNet,CornerNet,FCOS,Cascade R-CNN,DETR
生成对抗:GAN,CGAN,DCGAN,pix2pix,CycleGAN,W-GAN
loss 相关:Focalloss,IOUloss系列,diceloss, CTCloss
部署加速:tf int8,network-slimming,KD
其他方面:CAM,Grad-CAM,Soft-NMS,CRNN,DBNet
Relu
论文标题:Deep Sparse Rectifier Neural Networks
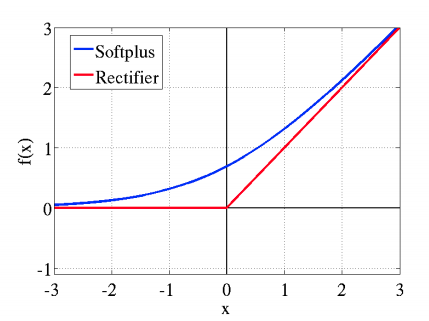
核心解读:Relu相比Sigmoid,训练速度更快,且不存在Sigmoid的梯度消失的问题,让CNN走向更深度成为的可能。因为它大于0区间就是一个线性函数,不会存在饱和的问题。对于Relu也有一些改进,例如pRelu、leaky-Relu、Relu6等激活函数。单纯的Relu在0点是不可导的,因此底层需要特殊实现,放心,框架早已做好了。
Dropout
论文标题: Improving neural networks by preventing co-adaptation of feature detectors
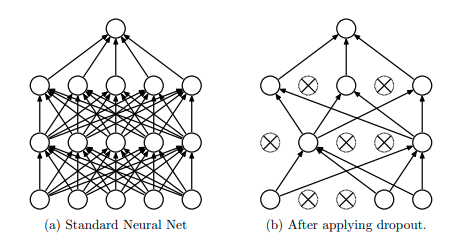
核心解读:在训练时,按照一定概率随机丢弃掉一部分的连接。在测试时,不使用丢弃操作。一般的解释是,Dropout作为一种正则化手段,可以有效缓解过拟合。因为神经元的drop操作是随机的,可以减少神经元之间的依赖,提取独立且有效的特征。为了保证丢弃后该层的数值总量不变,一般会除上(1-丢弃比例p)。多说一句,目前由于BN的存在,很少在CNN网络中看到Dropout的身影了。不过不能忽视其重要的意义,且在其他网络中(例如transformer)依然扮演者重要的角色。
BN
论文标题:Batch Normalization: Accelerating Deep Network Training b y Reducing Internal Covariate Shift

核心解读:首先Normalization被称为标准化,它通过将数据进行偏移和尺度缩放拉到一个特定的分布。BN就是在batch维度上进行数据的标准化,注意FC网络是batch维度,CNN网络由于要保证每一个channel上的所有元素同等对待,因此是在BHW维度上进行的标准化操作。其作用可以加快模型收,使得训练过程更加稳定,避免梯度爆炸或者梯度消失。有了BN,你不必再小心翼翼调整参数。并且BN也起到一定的正则化作用,因此Dropout被替代了。上述公式中均值和方差通过滑动平均的方式在训练的过程中被保存下来,供测试时使用。当今CNN网络,BN已经成为了必不可少的标配操作。另外还有LN(layer Normalization)、IN(instance Normalization )、GN(group Normalization)的标准化操作。不过是作用在不同维度上获取的,不在赘述。
Adam
论文标题:ADAM : A METHOD FOR STOCHASTIC OPTIMIZATION

核心解读:应用非常广泛,SGD、momentum等方法的集大成者。SGD-momentum在SGD基础上增加了一阶动量,AdaGrad和AdaDelta在SGD基础上增加了二阶动量。而Adam把一阶动量和二阶动量都用起来—Adaptive + Momentum。Adam算法即自适应时刻估计方法(Adaptive Moment Estimation),能计算每个参数的自适应学习率。这个方法不仅存储了AdaDelta先前平方梯度的指数衰减平均值,而且保持了先前梯度的指数衰减平均值,这一点与动量类似。
AtrousConv
论文标题:MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS
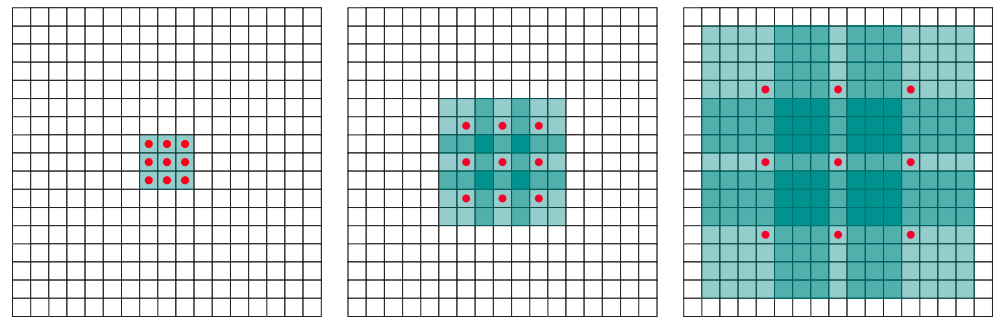
核心解读:我们常说网络的感受野非常重要,没有足够的感受野训练和测试会丢失特征,预测就不准甚至错掉。AtrousConv被称为空洞卷积或膨胀卷积,广泛应用于语义分割与目标检测等任务中,在不增加参数的情况下,提高卷积的感受野。也可以代替pooling操作增加感受野,捕获多尺度上下文信息,并且不会缩小特征图的分辨率。可以通过设置不同的扩张率实现不同感受野大小的空洞卷积。不过在实际的语义分割应用中,发现会出现网格现象。
DCN系列
论文标题:
v1: Deformable Convolutional Networks
v2: Deformable ConvNets v2: More Deformable, Better Results
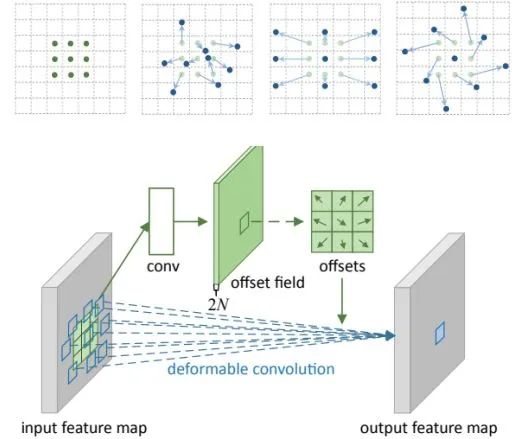
核心解读:传统卷积只是在NXN的正方形区域提取特征,或称为滑动滤波。可变形卷积是卷积的位置是可变形的,为了增加网络提取目标几何信息或形状信息的能力。具体做法就是在每一个卷积采样点加上了一个偏移量,而这个偏移量是可学习的。另外空洞卷积也是可变形卷积的一种特例。类似的还有可变形池化操作。在V2中发现可变形卷积有可能引入了无用的上下文来干扰特征提取,会降低算法的表现。为了解决该问题,在DCN v2中不仅添加每一个采样点的偏移,还添加了一个权重系数 ,来区分引入的区域是否为我们感兴趣的区域。如果该区域无关重要,权重系数学习成0就可以了。在目前的目标检测等任务中,增加变形卷积都会有不同程度的涨点,可谓是涨点必备。
,来区分引入的区域是否为我们感兴趣的区域。如果该区域无关重要,权重系数学习成0就可以了。在目前的目标检测等任务中,增加变形卷积都会有不同程度的涨点,可谓是涨点必备。
VGG
论文标题:Very Deep Convolutional Networks For Large-Scale Image RecognitionVery Deep Convolutional Networks For Large-Scale Image Recognition
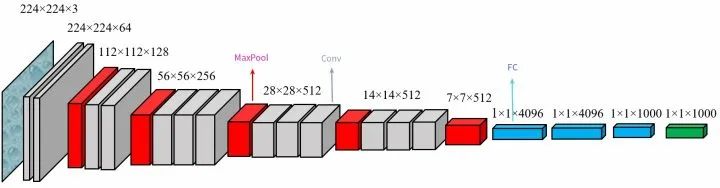
图侵删
核心解读:VGG采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。可以获取等同的感受野,并且增加了网络的深度和非线性表达能力,来保证学习更复杂的模式,并且所需的总参数量还会减小。从VGG开始,深度学习向更深度迈进。该结构亦成为了早期目标检测、语义分割、OCR等任务的骨架网络,例如Faster R-CNN、CRNN等。
NIN
论文标题:Network In Network
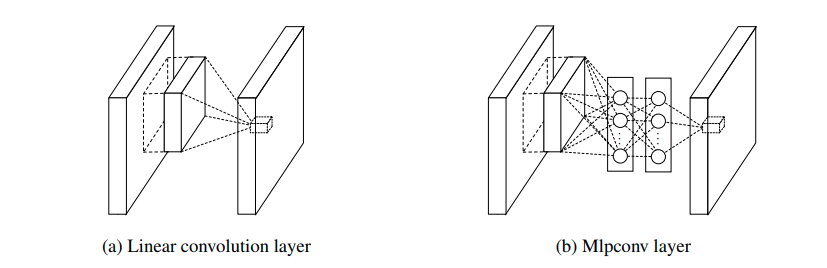
核心解读:本文有两大贡献:1,提出全局平均池化,也就是GAP(global average pooling)。有了GAP操作,可以轻易的将网络适用到不同输入尺度上。另外GAP层是没有参数的,因为参数量少了,GAP也降低了过拟合的风险。GAP直接对特征层的空间信息进行求和,整合了整个空间的信息,所以网络对输入的空间变化的鲁棒性更强。2,提出1X1卷积,几乎出现在目前所有的网络上,起到通道升降维、特征聚合等作用。通过1X1卷积还可以实现全连接操作。单凭这两点贡献,NIN在该名单值得一席地位。
ResNet
论文标题:Deep Residual Learning for Image Recognition
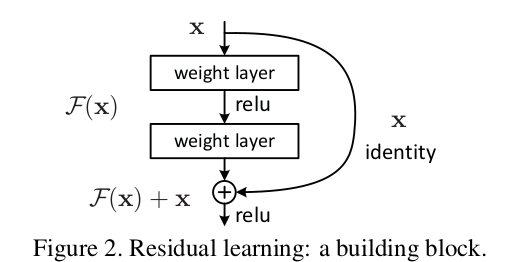
核心解读:cvpr2016最佳论文奖,ImageNet当年的冠军。论文提出的残差连接几乎可以在每一个CNN中看到身影。网络的深度是提高网络性能的关键,但是随着网络深度的加深,梯度消失问题逐渐明显,甚至出现退化现象。所谓退化就是深层网络的性能竟然赶不上较浅的网络。本文提出残差结构,当输入为x时其学习到的特征记为H(x),现在希望可以学习到残差F(x)= H(x) - x,因为残差学习相比原始特征直接学习更容易。当残差为0时,此时仅仅做了恒等映射,至少网络性能不会下降。正如kaiming所说“简单才能接近本质”,就是一条线连一下。让我想到了工程师划线的典故,重点不是画线,而是把线画到哪。该论文提出了resnet18、resnet34、resnet50、resnet101、resnet152不同量级的结构,依然是现在分类网络中的主流,以及目标检测、语义分割等算法的主流骨架网络。
SeNet
论文标题:Squeeze-and-Excitation Networks
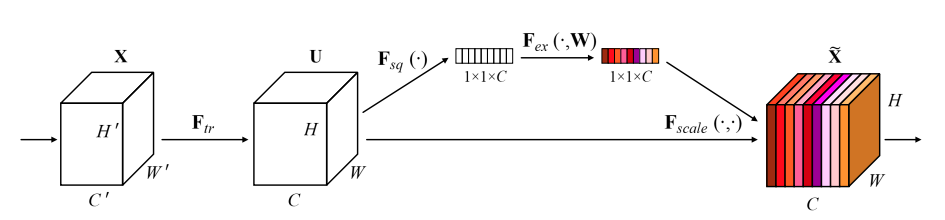
核心解读:它赢得了最后一届ImageNet 2017竞赛分类任务的冠军。重要的一点是SENet思路很简单,很容易扩展在已有网络结构中。SE模块主要包括Squeeze和Excitation两个操作。Squeeze操作:将一个channel上整个空间特征编码为一个全局特征,采用GAP来实现,Sequeeze操作得到了全局描述特征。接下来利用Excitation操作将学习到的各个channel的激活值(sigmoid激活,值0~1)作用到原始特征上去。整个操作可以看成学习到了各个channel的权重系数,从而使得模型对各个channel的特征更有辨别能力,这应该也算一种attention机制。
Inception系列
论文标题:
v1: Going deeper with convolutions
v2: Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
v3: Rethinking the Inception Architecture for Computer Vision
v4: Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
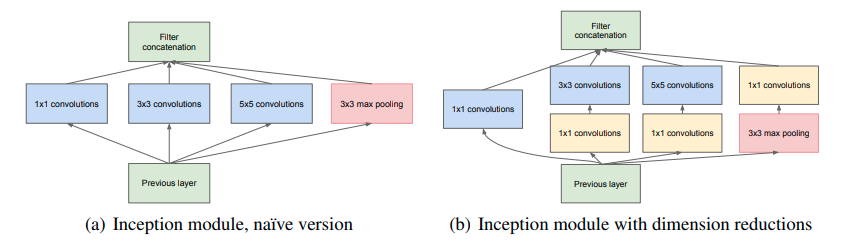
核心解读:该系列的前身都是GoogLenet,其提升网络性能的方式就是增加网络深度和宽度,深度指网络层次数量、宽度指神经元数量。于是就有了上图的经典inception结构,简单来说就是并行采用不同大小的卷积核处理特征,增加网络的处理不同尺度特征的能力,最后将所有的特征concat起来送入下面的结构。
v1: 把GoogLenet一些大的卷积层换成1*1, 3*3, 5*5的小卷积,这样能够大大的减小权值参数量。
v2: 就是大名鼎鼎BN那篇文章,网络方面的改动就是增加了BN操作,可以看BN那部分的介绍。
v3:利用分离卷积的思想,把googLenet里一些7*7的卷积变成了1*7和7*1的两层串联,3*3同理。这样做的目的是为了加速计算,减少过拟合。
v4:把原来的inception加上了resnet中的残差结构。
MobileNet系列
论文标题:
v1: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
v2: MobileNetV2: Inverted Residuals and Linear Bottlenecks
v3: Searching for MobileNetV3
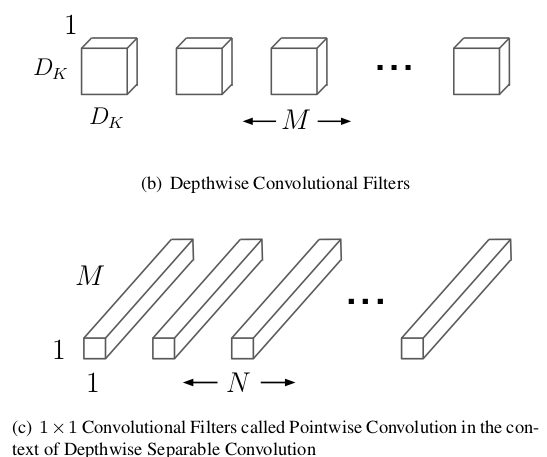
核心解读:轻量级网络的代表作,核心操作就是把VGG中的标准卷积层换成深度可分离卷积,计算量会比下降到原来的九分之一到八分之一左右。
v1:原本标准的卷积操作分解成一个depthwise convolution和一个1*1的pointwise convolution操作;
v2:使用了Inverted residuals(倒置残差)结构,就是先利用1X1卷积将通道数扩大,然后进行卷积,再利用1X1卷积缩小回来,和Resnet的Bottleneck恰好相反。通过将通道数扩大,从而在中间层学到更多的特征,最后再总结筛选出优秀的特征出来。另外使用了Linear bottlenecks来避免Relu函数对特征的损失。
v3: 利用神经结构搜索(NAS)来完成V3,并继承了V1的深度可分离卷积和v2的倒置残差结构。并且使用h-swish激活函数来简化swish的计算量,h的意思就是hard。对于网络输出的后端,也就进行了优化。
ShuffleNet系列
论文标题:
v1: ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
v2: ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
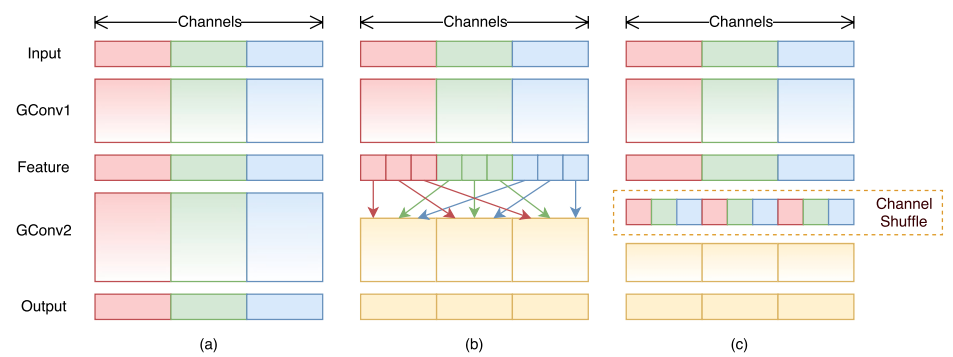
核心解读:ShuffleNet的核心是采用了point wise group convolution和channel shuffle操作,保持了精度的同时大大降低了模型的计算量。这里的shuffle打乱是均匀随机打乱。在V2中,作者从Memory Access Cost和GPU并行性的方向分析了高效网络设计准则:1.使用输入通道和输出通道相同的卷积操作;2.谨慎使用分组卷积;3.减少网络分支数;3.减少element-wise操作。
FCN
论文标题:Fully Convolutional Networks for Semantic Segmentation
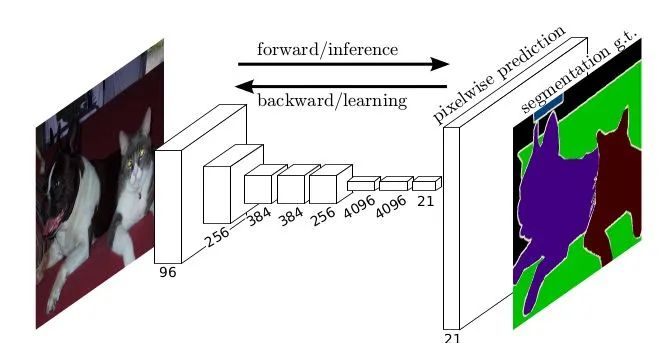
核心解读:CVPR 2015年的最佳论文提名,也是CNN进行语义分割的开山之作。本文提出的全卷积、上采样、跳跃结构等也是非常具有意义的,对后来者影响巨大。
U-Net
论文标题:U-Net: Convolutional Networks for Biomedical Image Segmentation
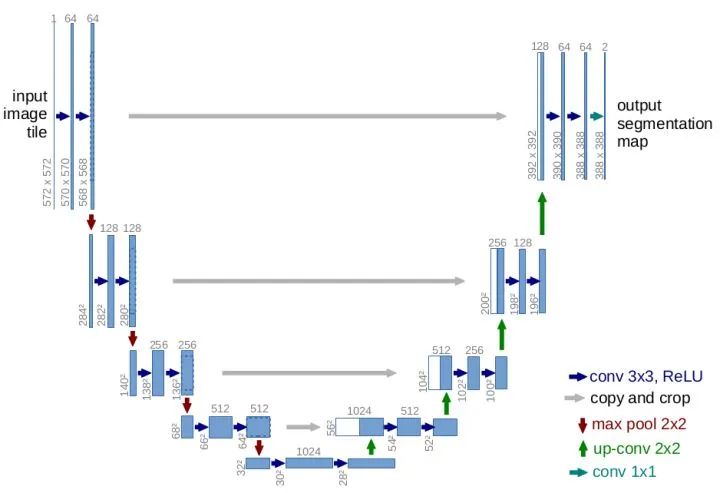
核心解读:Unet 初衷是应用在医学图像上,属于 FCN 的一种变体。由于效果优秀,被广泛的应用在语义分割的各个方向,比如卫星图像分割,工业瑕疵检测等。尤其在工业方向大放异彩。Unet 网络结构是非常对称的,形似英文字母 U 所以被称为 Unet。非常经典的跳层链接也有FPN的影子。另外,该结构也是魔改的对象,类似unet++、res-unet等不下于数十种,侧面反应该作品的确很棒。
PSPNet
论文标题:Pyramid Scene Parsing Network
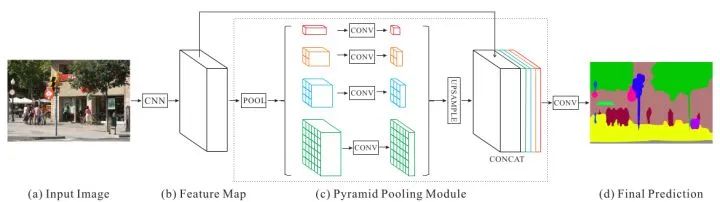
核心解读:PSPNet也是在FCN上的改进,利用金字塔池化引入更多的上下文信息进行解决, 分别用了1x1、2x2、3x3和6x6四个尺寸,最后用1x1的卷积层计算每个金字塔层的权重。最后再通过双线性恢复成原始尺寸。最终得到的特征尺寸是原始图像的1/8。最后在通过卷积将池化得到的所有上下文信息整合,生成最终的分割结果。
DeepLab
论文标题:
v1: SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS
v2:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
v3: Rethinking Atrous Convolution for Semantic Image Segmentation
v3+: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
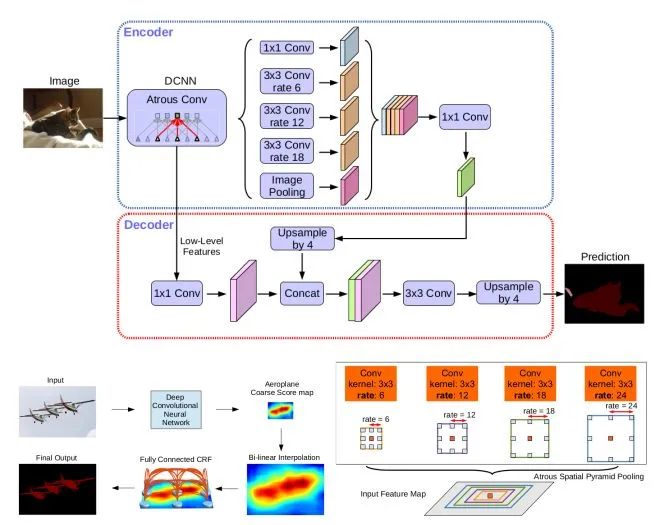
核心解读:
v1:通过空洞卷积提升网络的感受野和上下文的捕捉能力,通过条件随机场(CRF)作为后处理提高模型捕获精细细节的能力。
v2:将最后几个max-pooling用空洞卷积替代下采样,以更高的采样密度计算feature map。提出ASPP(astrous spatial pyramid pooling),既组合不同采样率的空洞卷积进行采样。另外DeepLab基础上将VGG-16换成ResNet。
v3: 改进了ASPP:由不同的采样率的空洞卷积和BN层组成,以级联或并行的方式布局。大采样率的3×33×3空洞卷积由于图像边界效应无法捕获长程信息,将退化为1×11×1的卷积,我们建议将图像特征融入ASPP。
v3+:提出一个encoder-decoder结构,其包含DeepLabv3作为encoder和高效的decoder模块。encoder decoder结构中可以通过空洞卷积来平衡精度和运行时间,现有的encoder-decoder结构是不可行的。在语义分割任务中采用Xception模型并采用depthwise separable convolution,从而更快更有效。
Mask-RCNN
论文标题:Mask R-CNN
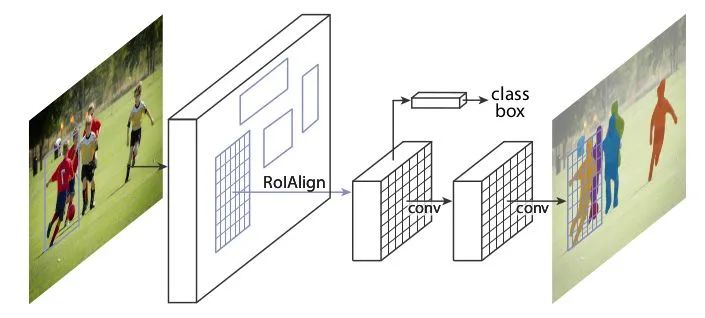
核心解读:本文是做实例分割的,也是经典baseline。Mask-RCNN 在 Faster-RCNN 框架上改进,在基础特征网络之后又加入了全连接的分割子网,由原来两个任务(分类+回归)变为了三个任务(分类+回归+分割)。另外,,Mask RCNN中还有一个很重要的改进,就是ROIAlign。可以将fasterrcnn的中的roipooling类比成最近邻插值,roialign就会类比成双线性插值。
PANet
论文标题:Path Aggregation Network for Instance Segmentation
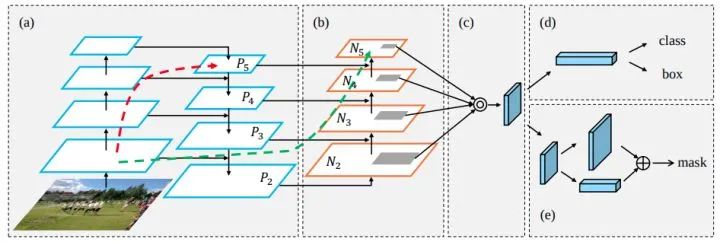
核心解读:实例分割的路径聚合网络,PANet整体上可以看做是对Mask-RCNN做了多个改进。其提出的FPN改进版PAN-FPN增加了自底向上的连接。在目标检测任务上,例如yolov4和v5上也大放异彩,可以看作是FPN非常成功的改进。
Faster R-CNN
论文标题:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
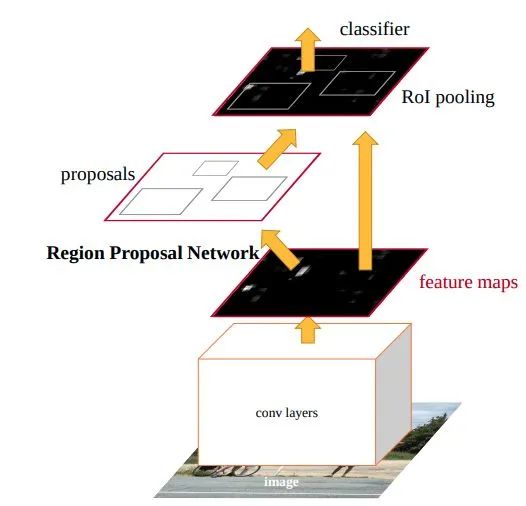
核心解读:经典的不能再经典,随便一搜就可以找到无数篇的解读。两阶段目标检测鼻祖一样的存在,和Yolo等单阶段网络抗衡了3代之久。所谓两阶段就是第一个阶段将前景的候选区域proposal出来,第二个阶段利用proposals进行分类和精修。像RPN、anchor、roipooling、smooth L1 loss等影响深远的概念都来自于此。题外话:最近看了很多任意角度目标检测,其中两阶段的都是以Faster Rcnn作为baseline进行魔改的,足见其地位。
YOLO系列
论文标题:
v1: You Only Look Once: Unified, Real-Time Object Detection
v2: YOLO9000: Better, Faster, Stronger
v3: YOLOv3: An Incremental Improvement
v4: YOLOv4: Optimal Speed and Accuracy of Object Detection
v5: github.com/ultralytics/(没有论文,只有代码)
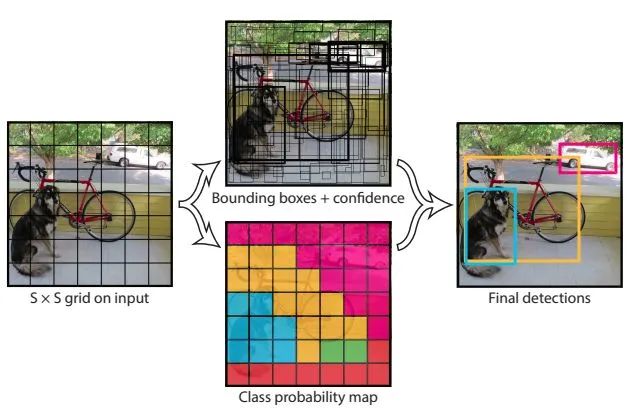
核心解读:如果说Faster RCNN是两阶段的第一人,那么YOLO系列就是单阶段的第一人。单阶段意味着速度更快,实现更简单。针对YOLO的魔改也不在少数,例如poly-YOLO、pp-YOLO、fast-YOLO等。下面分别简述各自的核心特点:
v1:显式地将图片等分为NXN个网格,物体的中心点落入网格内,该网格负责预测该物体。可以这样理解,NXN个网络意味者网络最终输出的tensor的尺度也是NXN,对应特征向量负责回归它该负责的物体。注意v1是没有anchor的概念的,回归的尺度是相对与整图来看的。
v2:最大的改进就是增加了anchor机制,和faster R-CNN、SSD、RetinaNet的手动预设不同,YOLO系列全是利用kmeans聚类出最终的anchor。这里的anchor只有宽高两个属性,位置依然是相对与网格的。有了anchor就有匹配规则,是利用iou来判定正、负、忽略样本的。
v3:基本设定和v2一致,不过是加入个多尺度预测,基本思想和FPN一样。为了适配不同尺度的目标。也是目前工业界应用最广泛的模型。
v4:运用了非常多现有的实用技巧,例如:加权残差连接(WRC)、跨阶段部分连接(CSP)、跨小批量标准化(CmBN)、自对抗训练(SAT)、Mish激活、马赛克数据增强、CIoU Loss等,让精度也上了一个台阶。另外说一句,该团队最近出品的scaled-Yolov4将coco刷到55.4,强的没有对手。
v5:马赛克增强的作者,同样是改进了网络的骨架和FPN等,另外为了增加正样本的数量,改进了匹配规则,就是中心网格附近的也可能分配到正样本,提高了网络的召回率。与v4相比,有过之而无不及。
FPN
论文标题:Feature Pyramid Networks for Object Detection
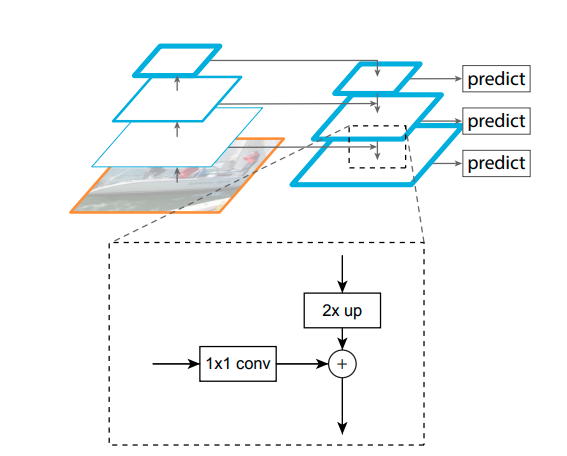
核心解读:本文提出FPN(特征金字塔)结构,就是自上而下的路径和横向连接去结合低层高分辨率的特征。把高层的特征传下来,补充低层的语义,可以获得高分辨率、强语义的特征,有利于小目标的检测。也是目前主流网络的常客,魔改版本也很多,例如前述的PAN-FPN、ASFF、BiFPN、NAS-FPN等等。
SSD
论文标题:SSD: Single Shot MultiBox Detector
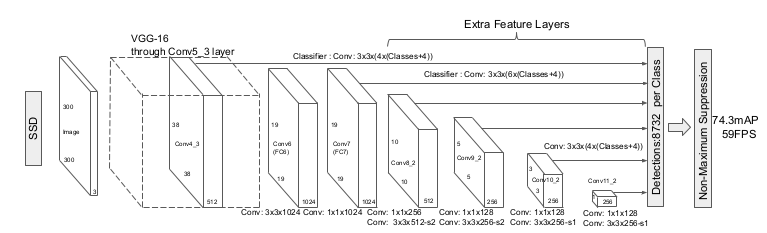
核心解读:多尺度预测的先驱,在没有FPN的时代采用了多尺度的特征图,并设置anchor。采用VGG16作为backbone。名气很大,但目前应用是比较少了。我认为由于不像Yolo有后续的版本持续发力导致的。现在要是设计目标检测,VGG肯定不够用了,换掉。FPN也要加上,等等,即便是baseline是SSD,那么魔改出来肯定不叫SSD了。
CornerNet
论文标题:CornerNet: Detecting Objects as Paired Keypoints
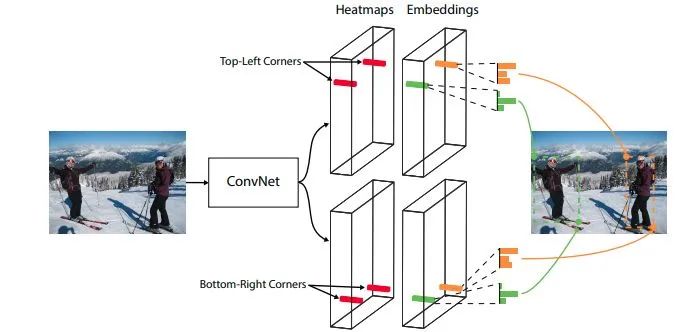
核心解读:虽然不是anchor-free的开山之作,但一定是将anchor-free重新带回大众视野的作品。该论文采用bottom-up的做法,就是先找到所有的关键点,再进行配对。论文使用目标box的左上和右下两个关键点来定位。为了后续的配对,网络会额外预测embedding vector,使用推拉loss,形象比喻是将同一个目标的点拉到一起,不同目标的点推开。bottom-up的思想非常值得借鉴。
CenterNet
论文标题:Objects as Points
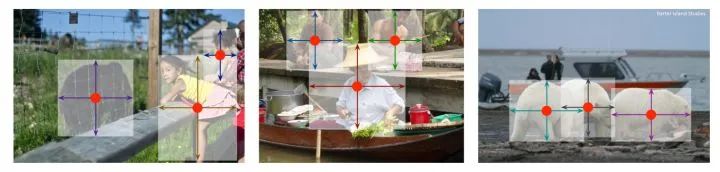
核心解读:anchor-free中的典范之作,CenterNet不仅可以用于目标检测,还可以用于其他的一些任务,如肢体识别或者3D目标检测等等。网络利用热图预测目标中心点位置,增加分支预测宽高或其他属性,为了降低热图缩小尺度输出带来的量化误差,网络还会额外预测offset分支。结构简单,可扩展性极强,并且anchor-free,没有过多的超参可调。受到学术界和工业界的追捧,让anchor-free有火热起来。要说缺点也有,就是没有FPN多尺度的操作。应用的话还是看场景吧!
FCOS
论文标题:FCOS: Fully Convolutional One-Stage Object Detection
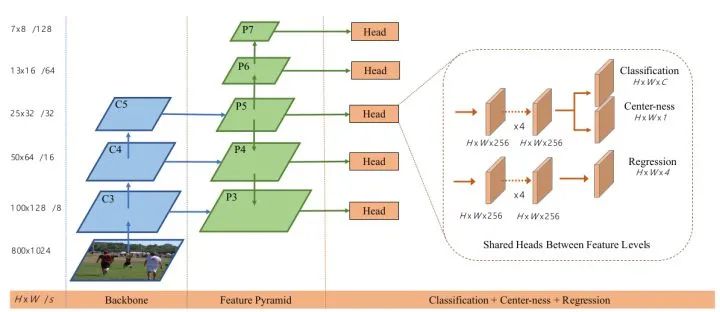
核心解读:CornerNet是将anchor-free带回大众视野,CenterNet是将anchor-free受到追捧,那么FCOS就是使anchor-free走到巅峰,足以和anchor-base抗衡。本文利用FPN处理不同尺度的目标预测,并创造性提出了centerness分支来过滤低质量的样本,提升网络击中的能力,并减轻后端NMS的压力。和CenterNet只采用中心点作为正样本的做法不同,该论文将目标一定大小的中心区域都设置为正样本,大大提高了正样本的数量。不仅可以加速训练收敛,还可以提高召回率,nice work。
Cascade R-CNN
论文标题:Cascade R-CNN: Delving into High Quality Object Detection
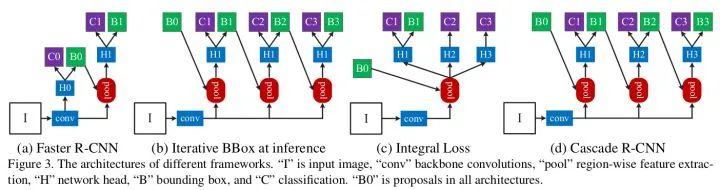
核心解读:比赛的常客,说明精度的确很高。由于Faster R-CNN的RPN提出的proposals大部分质量不高,导致没办法直接使用高阈值的detector,Cascade R-CNN使用cascade回归作为一种重采样的机制,逐stage提高proposal的IoU值,从而使得前一个stage重新采样过的proposals能够适应下一个有更高阈值的stage。利用前一个阶段的输出进行下一阶段的训练,阶段越往后使用更高的IoU阈值,产生更高质量的bbox。是一种refine的思想在里面。
DETR
论文标题:End-to-End Object Detection with Transformers
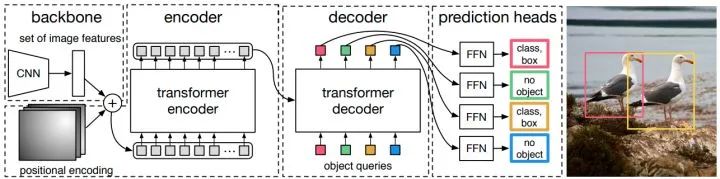
核心解读:真是打败你的不是同行,而是跨界。Transorfmer在NLP领域已经大杀四方,目前它的触角悄悄伸到CV领域,可气的是性能竟然不虚。DETR基于标准的Transorfmer结构,首先利用CNN骨架网络提取到图像的特征,和常见的目标检测的做法一致。不过后端却没有了FPN和pixel-wise的head。替换而来的是Transorfmer的encoder和decoder结构,head也换成了无序boxes的set预测。当然什么anchor、nms统统见鬼去吧。一经提出就引起了轩然大波,在很快的将来,会雨后春笋斑蓬勃发展的,例如后续发力版本Ddformable DETR。我觉得,不过还需要时间的考验。
GAN
论文标题:Generative Adversarial Nets
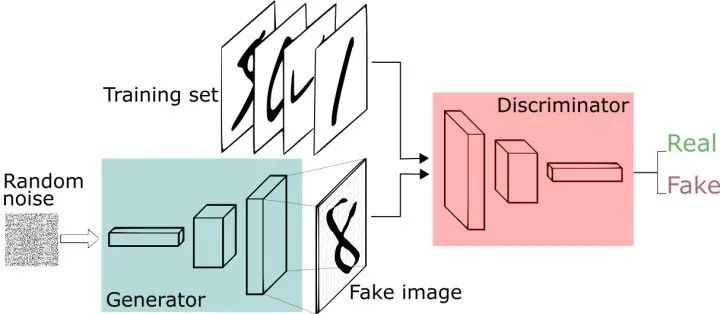
图侵删
核心解读:祖师爷级别,脑洞大开的典范。活生生打开了一个领域,也是目前AI最惊艳到人类的一个领域。思想非常简单:既然无法评价生成的图片质量,干脆交给网络来做吧。GAN的主要结构包括一个生成器G(Generator)和一个判别器D(Discriminator)。生成器负责生成图片,判别器负责判别生成图片的真假,二者交替训练,互利共生。足以以假乱真。
CGAN
论文标题:Conditional Generative Adversarial Networks
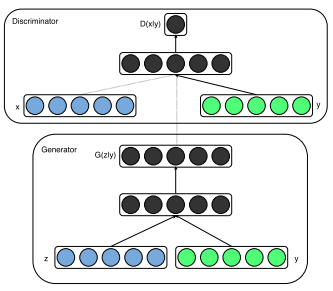
核心解读:GAN能够通过训练学习到数据分布生成新的样本,其输入数据来源随机噪声信号,是无意义且不可控的,因此生成的图像也是随机的,不能控制生成图像类别。如果真的要使用的话,还需要人工或者额外的网络来判定类别。本文将类别编码结合噪声信号共同输入网络,类别编码控制生成图像的类别,噪声信号保证生成图像的多样性。类别标签可以和噪声信号组合作为隐空间表示。同样判别器也需要将类别标签和图像数据进行拼接作为判别器输入。
DCGAN
论文标题:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
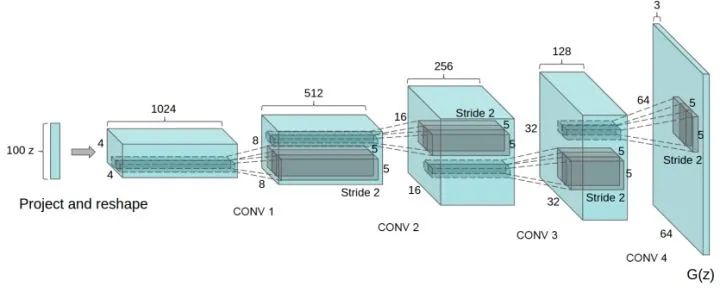
核心解读:DCGAN将CNN与GAN结合的开山之作,因为原始GAN是利用FC实现的。DCGAN的出现极大的推动了GAN的蓬勃发展。其主要特点是:去除了FC层,使用了BN操作和Relu等CNN通用技术。利用不同stride的卷积代替pooling层等等。
pix2pix
论文标题:Image-to-Image Translation with Conditional Adversarial Networks
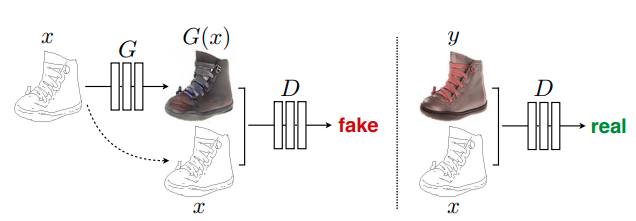
核心解读:本文是用cGAN思想做图像翻译的鼻祖。所谓图像翻译,指从一副图像转换到另一副图像,例如手绘和真实图。本文提出了一个统一的框架解决了图像翻译问题。当然直接利用CNN生成器(例如U-Net)去做图像翻译也可以,只是比较粗暴,并且生成的图像质量比较模糊,效果不好。于是pix2pix增加了GAN的对抗损失,用以提升生成的质量,结果效果显著。后续还有进阶版本pix2pixHD的出现,效果可谓又上一个台阶。视频转换有vid2vid可用。
CycleGAN
论文标题:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
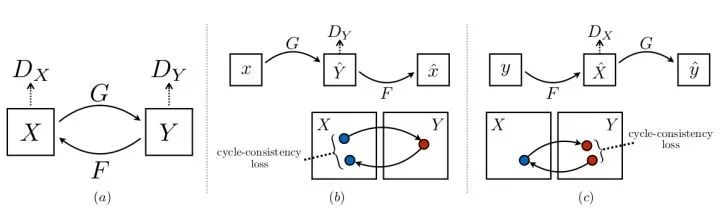
核心解读:CycleGAN的推出将图像风格转换推向了新的高度。简单来说就是能把苹果变为橘子,把马变为斑马,把夏天变为冬天等等。它解决的是非配对的域转换。上文说了pix2pix虽然惊艳,但是存在必须依赖配对样本的缺点。CycleGAN利用循环一致loss解决该问题。说句体外话,真正在使用的时候,能配对尽量配对,可以显著提高生成的图片的质量和训练效率。
W-GAN
论文标题:
上篇:Towards Principled Methods For Training Generative Adversarial Networks
下篇:Wasserstein GAN
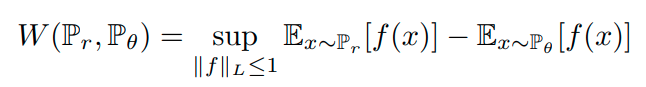
核心解读:本文将GAN理论研究推向新的高度。GAN自提出依赖就存在着训练困难、生成器和判别器的loss不可信赖、生成样本缺乏多样性等问题。本文提出一些实用且简单的trick,并推出Wasserstein距离,又叫Earth-Mover(EM)距离。由于它相对KL散度与JS散度具有优越的平滑特性,理论上可以解决梯度消失问题。另外,本文的理论非常扎实,在业内广受好评,非常值得一读。
Focalloss
论文标题:Focal Loss for Dense Object Detection
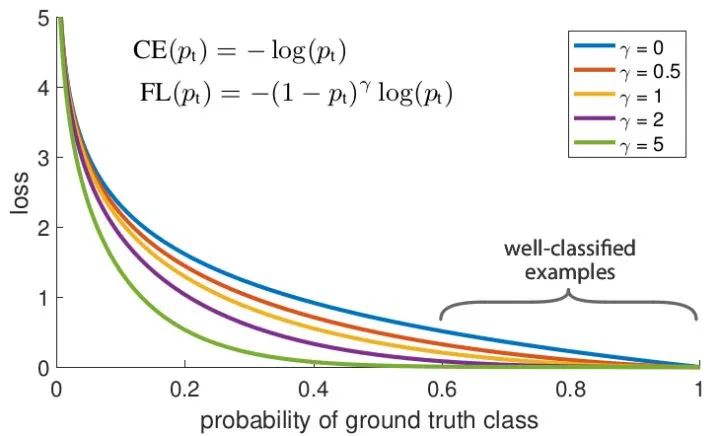
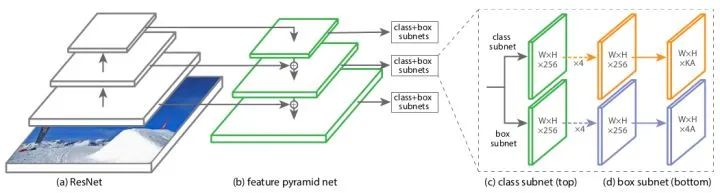
核心解读:focalloss已经惊为天人,RetinaNet又锦上添花。focalloss是解决分类问题中类别不平衡、难样本挖掘的问题。根据预测来调整loss,有一种自适应的思想在里面。retinaNet是anchor-base中的经典作品,结构简单通用,成为很多后继工作的首选baseline。
IOUloss系列
论文标题:
iou: UnitBox: An Advanced Object Detection Network
giou:Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression
diou: Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression
ciou: Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation
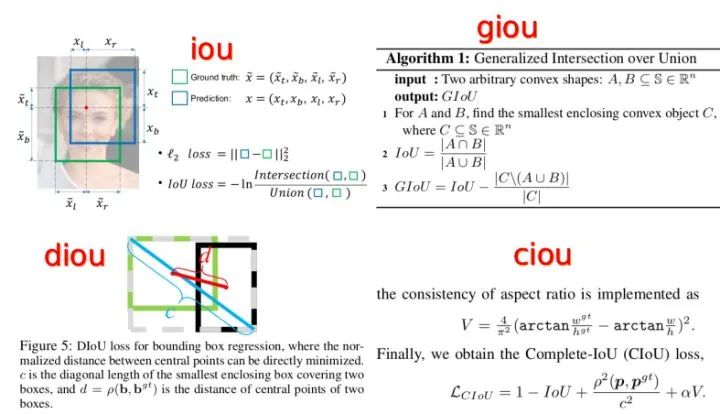
核心解读:IOU是目标检测最根本的指标,因此使用IOUloss理所当然是治标又治本的动作。进化过程如下:
IOU Loss:考虑检测框和目标框重叠面积。问题是:1.两个box不重合时,iou永远是0,作为loss不合理。2. IoU无法精确的反映两者的重合度大小,因为对尺度不敏感。
GIOU Loss:在IOU的基础上,解决边界框不重合时的问题。就是引入两个box的外接矩形,将两个box的外部区域作为加入到loss里面。
DIOU Loss:在GIOU的基础上,考虑边界框中心距离的信息。将目标与anchor之间的距离,重叠率以及尺度都考虑进去。
CIOU Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。也是目前最好的一种IOU loss。
diceloss
论文标题:V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation

核心解读:旨在应对语义分割中正负样本强烈不平衡的场景,并且可以起到加速收敛的功效,简直是语义分割的神器。不过也存在训练不稳定等问题,因此有一些改进操作,主要是结合ce loss等改进,比如: dice+ce loss,dice + focal loss等。
CTCloss
论文标题:Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks
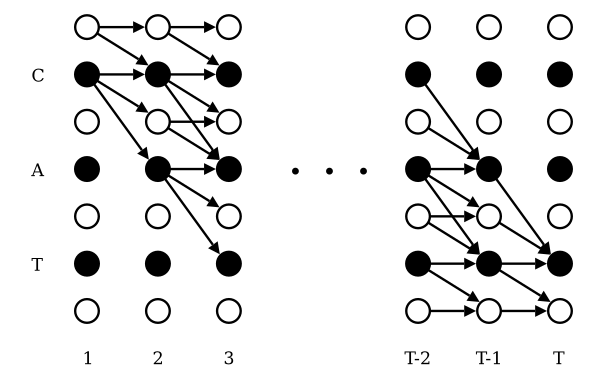
核心解读:解决训练时序列不对齐的问题,在文本识别和语言识别领域中,能够比较灵活地计算损失,进行梯度下降。例如在CV领域的OCR任务中几乎必备。本文应该是这个介绍的当中最难的一篇,不从事相关专业的可以不去深究,但是还是有必要了解它在做什么。
tf int8
论文标题:Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
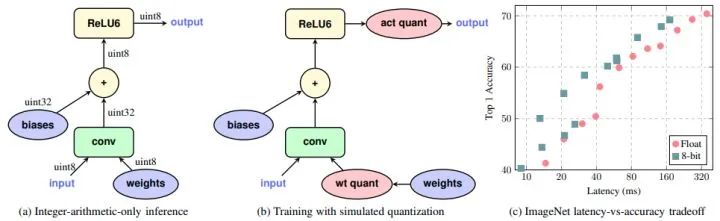
核心解读:这是google发布的8bit的定点方案,几乎又是祖师爷级别的论文。深度学习部署落地才是根本,撑起部署三件套的量化、剪枝、蒸馏三竿大旗中最高的一竿。模型部署的时候,你可以没有剪枝和蒸馏,但是不可以不用量化(土豪用户忽略)。不管是TensorFlow的方案,还是pytorch的方案,或者是GPU端扛把子的tensorrt,其后端精髓都来源于此。
network-slimming
论文标题:Learning Efficient Convolutional Networks through Network Slimming
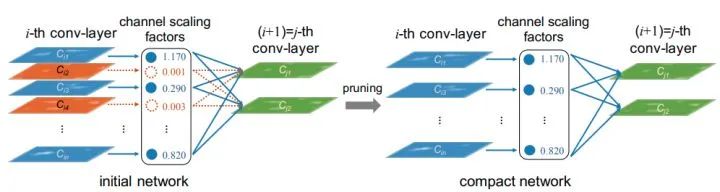
核心解读:CNN网络部署有三个难题:模型大小、运行时间和占用内存、计算量。论文利用BN中的gamma作为通道的缩放因子,因为gamma是直接作用在特征图上的,值越小,说明该通道越不重要,可以剔除压缩模型。为了获取稀疏的gamma分布,便于裁剪。论文将L1正则化增加到gamma上。本文提出的方法简单,对网络结构没有改动,效果显著。因此成为了很多剪枝任务的首选。
KD
论文标题:Distilling the Knowledge in a Neural Network
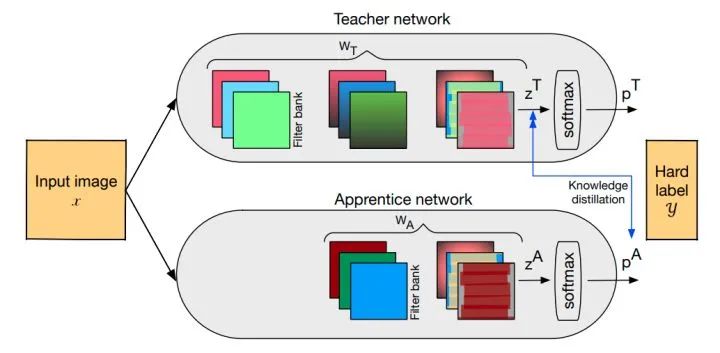
插图:APPRENTICE: USING KNOWLEDGE DISTILLATIONTECHNIQUES TO IMPROVE LOW-PRECISION NETWORK ACCURACY
核心解读:知识蒸馏的开山之作。我们可以先训练好一个teacher网络,然后将teacher的网络的输出结果 作为student网络的目标,训练student网络,使得student网络的结果
作为student网络的目标,训练student网络,使得student网络的结果 接近为了传递给student网络平滑的概率标签,也就是不能置信度太高,太接近onehot。文章提出了softmax-T。实验证明是可以有效提高小模型的泛化能力。
接近为了传递给student网络平滑的概率标签,也就是不能置信度太高,太接近onehot。文章提出了softmax-T。实验证明是可以有效提高小模型的泛化能力。
CAM
论文标题:Learning Deep Features for Discriminative Localizatiion
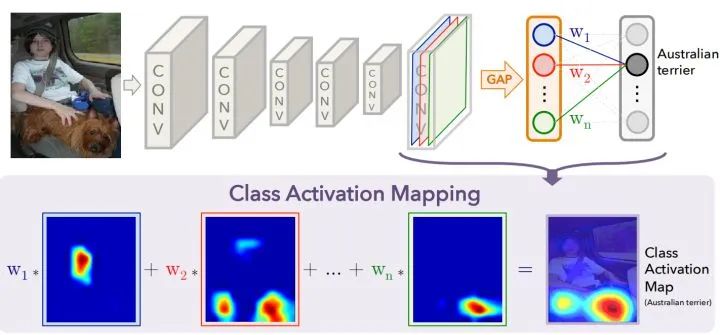
核心解读:特征可视化是可解释研究的一个重要分支。有助于理解和分析神经网络的工作原理及决策过程,引导网络更好的学习,利用CAM作为原始的种子,进行弱监督语义分割或弱监督定位。本文是利用GAP进行的,这个概念来自network in network,利用全局平均池化获取特征向量,再和输出层进行全连接。GAP直接将特征层尺寸 转化成
转化成 ,既每一层的特征图里面的所有像素点值求平均获取对应特征向量值作为GAP输出。GAP后端接的是FC,每一个权重可以看作对应特征图层的重要程度,加权求和就获取了我们的CAM。
,既每一层的特征图里面的所有像素点值求平均获取对应特征向量值作为GAP输出。GAP后端接的是FC,每一个权重可以看作对应特征图层的重要程度,加权求和就获取了我们的CAM。
Grad-CAM
论文标题:Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
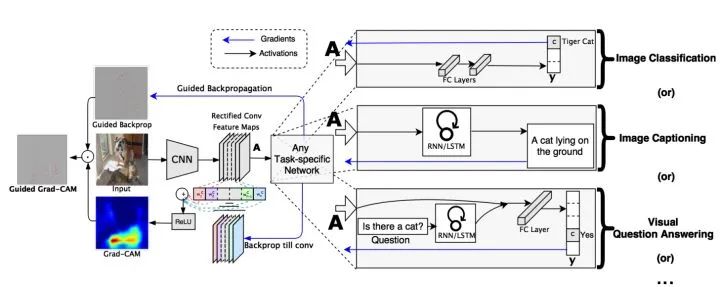
核心解读: CAM的局限性就是网络架构里必须有GAP层,但并不是所有模型都配GAP层的。而本文就是为克服该缺陷提出的,其基本思路是目标特征图的融合权重 可以表达为梯度。Grad-CAM可适用非GAP连接的网络结构;CAM只能提取最后一层特征图的热力图,而gard-CAM可以提取任意一层;
可以表达为梯度。Grad-CAM可适用非GAP连接的网络结构;CAM只能提取最后一层特征图的热力图,而gard-CAM可以提取任意一层;
Soft-NMS
论文标题:Improving Object Detection With One Line of Code

核心解读:NMS算法中的最大问题就是它将相邻检测框的分数均强制归零(即大于阈值的重叠部分), soft-NMS在执行过程中不是简单的对IoU大于阈值的检测框删除,而是降低得分。算法流程同NMS相同,但是对原置信度得分使用函数运算,目标是降低置信度得分.
CRNN
论文标题:An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
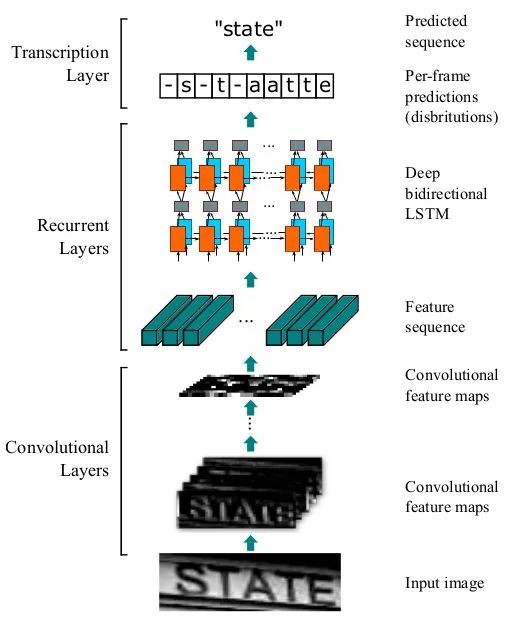
核心解读:文本识别经典做法,也是主流做法,简单有效。主要用于端到端地对不定长的文本序列进行识别,不用对单个文字进行切割,而是将文本识别转化为时序依赖的序列学习问题,就是基于图像的序列识别。使用标准的CNN网络提取文本图像的特征,再利用LSTM将特征向量进行融合以提取字符序列的上下文特征,然后得到每列特征的概率分布,最后通过解码得到文本序列。
DBNet
论文标题:Real-time Scene Text Detection with Differentiable Binarization
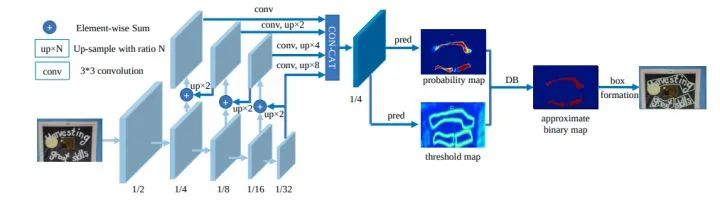
核心解读:本文的最大创新点将可微二值化应用到基于分割的文本检测中。一般分割网络最终的二值化都是使用的固定阈值。本文对每一个像素点进行自适应二值化,二值化阈值由网络学习得到,将二值化这一步骤加入到网络里一起训练。DB(Differentiable Binarization),翻译过来叫可微分二值化(因为标准二值化不可微分)。当然基于分割的文本检测可以适应各种形状,例如水平、多个方向、弯曲的文本等等。
后记
这仅仅是一份入门指南,指引你进入深度学习的海洋。经典之所以称之为经典,一定是每一次阅读都有新的发现,所以强烈建议大家去读原文。共勉!
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:leetcode 开源书
在「AI算法与图像处理」公众号后台回复:leetcode,即可下载。每题都 runtime beats 100% 的开源好书,你值得拥有!
下载3 CVPR2020
在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文
个人微信(如果没有备注不拉群!)
请注明:地区+学校/企业+研究方向+昵称

觉得不错就点亮在看吧
