
使用Pytorch实现频谱归一化生成对抗网络(SN-GAN)

来源:DeepHub IMBA
本文约3800字,建议阅读5分钟
自从扩散模型发布以来,GAN的关注度和论文是越来越少了,但是它们里面的一些思路还是值得我们了解和学习。所以本文我们来使用Pytorch 来实现SN-GAN。
-
更稳定,更容易训练
-
可以生成更高质量的图像
-
更通用,可以用来生成更广泛的内容。
模式崩溃
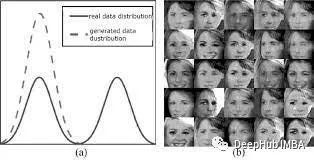
Wassersteian损失



JSD(P∥Q)=1/2(KL(P∥M)+KL(Q∥M))

1-Lipschitz Contiunity
|f(x) — f(y)| <= |x — y|
∥∣D(x)−D(y)∣≤K⋅∥x−y∥

谱范数
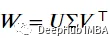



代码实现
import torchfrom torch import nnfrom tqdm.auto import tqdmfrom torchvision import transformsfrom torchvision.datasets import MNISTfrom torchvision.utils import make_gridfrom torch.utils.data import DataLoaderimport matplotlib.pyplot as plttorch.manual_seed(0)def show_tensor_images(image_tensor, num_images=25, size=(1, 28, 28)):image_tensor = (image_tensor + 1) / 2image_unflat = image_tensor.detach().cpu()image_grid = make_grid(image_unflat[:num_images], nrow=5)plt.imshow(image_grid.permute(1, 2, 0).squeeze())plt.show()
class Generator(nn.Module):def __init__(self,z_dim=10,im_chan = 1,hidden_dim = 64):super(Generatoe,self).__init__()self.gen = nn.Sequential(self.make_gen_block(z_dim,hidden_dim * 4),self.make_gen_block(hidden_dim*4,hidden_dim * 2,kernel_size = 4,stride =1),self.make_gen_block(hidden_dim * 2,hidden_dim),self.make_gen_block(hidden_dim,im_chan,kernel_size=4,final_layer = True),)def make_gen_block(self,input_channels,output_channels,kernel_size=3,stride=2,final_layer = False):if not final_layer :return nn.Sequential(nn.ConvTranspose2D(input_layer,output_layer,kernel_size,stride),nn.BatchNorm2d(output_channels),nn.ReLU(inplace = True),)else:return nn.Sequential(nn.ConvTranspose2D(input_layer,output_layer,kernel_size,stride),nn.Tanh(),)def unsqueeze_noise():return noise.view(len(noise), self.z_dim, 1, 1)def forward(self,noise):x = self.unsqueeze_noise(noise)return self.gen(x)def get_noise(n_samples, z_dim, device='cpu'):return torch.randn(n_samples, z_dim, device=device)
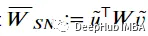
class Discriminator(nn.Module):def __init__(self, im_chan=1, hidden_dim=16):super(Discriminator, self).__init__()self.disc = nn.Sequential(self.make_disc_block(im_chan, hidden_dim),self.make_disc_block(hidden_dim, hidden_dim * 2),self.make_disc_block(hidden_dim * 2, 1, final_layer=True),)def make_disc_block(self, input_channels, output_channels, kernel_size=4, stride=2, final_layer=False):if not final_layer:return nn.Sequential(nn.utils.spectral_norm(nn.Conv2d(input_channels, output_channels, kernel_size, stride)),nn.BatchNorm2d(output_channels),nn.LeakyReLU(0.2, inplace=True),)else:return nn.Sequential(nn.utils.spectral_norm(nn.Conv2d(input_channels, output_channels, kernel_size, stride)),)def forward(self, image):disc_pred = self.disc(image)return disc_pred.view(len(disc_pred), -1)
训练
criterion = nn.BCEWithLogitsLoss()n_epochs = 50z_dim = 64display_step = 500batch_size = 128# A learning rate of 0.0002 works well on DCGANlr = 0.0002beta_1 = 0.5beta_2 = 0.999device = 'cuda'transform = transforms.Compose([transforms.ToTensor(),(0.5,)),])dataloader = DataLoader(download=True, transform=transform),batch_size=batch_size,shuffle=True)
gen = Generator(z_dim).to(device)gen_opt = torch.optim.Adam(gen.parameters(), lr=lr, betas=(beta_1, beta_2))disc = Discriminator().to(device)disc_opt = torch.optim.Adam(disc.parameters(), lr=lr, betas=(beta_1, beta_2))# initialize the weights to the normal distribution# with mean 0 and standard deviation 0.02def weights_init(m):if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):0.0, 0.02)if isinstance(m, nn.BatchNorm2d):0.0, 0.02)0)gen = gen.apply(weights_init)disc = disc.apply(weights_init)
cur_step = 0mean_generator_loss = 0mean_discriminator_loss = 0for epoch in range(n_epochs):# Dataloader returns the batchesfor real, _ in tqdm(dataloader):cur_batch_size = len(real)real = real.to(device)## Update Discriminator ##disc_opt.zero_grad()fake_noise = get_noise(cur_batch_size, z_dim, device=device)fake = gen(fake_noise)disc_fake_pred = disc(fake.detach())disc_fake_loss = criterion(disc_fake_pred, torch.zeros_like(disc_fake_pred))disc_real_pred = disc(real)disc_real_loss = criterion(disc_real_pred, torch.ones_like(disc_real_pred))disc_loss = (disc_fake_loss + disc_real_loss) / 2# Keep track of the average discriminator lossmean_discriminator_loss += disc_loss.item() / display_step# Update gradients=True)# Update optimizerdisc_opt.step()## Update Generator ##gen_opt.zero_grad()fake_noise_2 = get_noise(cur_batch_size, z_dim, device=device)fake_2 = gen(fake_noise_2)disc_fake_pred = disc(fake_2)gen_loss = criterion(disc_fake_pred, torch.ones_like(disc_fake_pred))gen_loss.backward()gen_opt.step()# Keep track of the average generator lossmean_generator_loss += gen_loss.item() / display_step## Visualization code ##if cur_step % display_step == 0 and cur_step > 0:{cur_step}: Generator loss: {mean_generator_loss}, discriminator loss: {mean_discriminator_loss}")show_tensor_images(fake)show_tensor_images(real)mean_generator_loss = 0mean_discriminator_loss = 0cur_step += 1

总结
编辑:文婧
评论