
仅使用少量数据训练生成对抗网络
【GiantPandaCV导语】今天带来的是nips2020上关于生成对抗网络中数据增广的另一篇文章。该文章的巧思比上一篇更精彩。上篇文章在生成对抗网络中的数据增广:一种可微分的数据增广方法
NIPS 2020 - Training Generative Adversarial Networks with Limited Data
1. 摘要:
和昨天的推文一样,同样是一篇研究在少量样本下,训练生成对抗网络的论文。这篇文章和昨天推文(加一个link)的假设类似:在数据不足的情况下,生成对抗网络中的判别器过拟合了,导致训练崩了(Diverge)。本文提出了一种自适应的判别器数据增广策略,显著稳定了在少量样本下的生成对抗网络的图像生成过程。本文同样是一种即插即用的方法,不需要对网络结构、损失函数等进行修改,并且也可以在基于迁移学习的生成对抗网络任务中使用。
2. Introduction
现今大量的生成对抗网络的令人激动的结果看起来都是由于网络上大量的图像数据训练得来的。但是在很多情况下,由于隐私、版权等原因,本文无法得到数量巨大的高质量图片集。尤其在将生成对抗网络应用到一个新的领域(无任何其他可供参考的数据集)的时候,本文更难得到大量高质量数据集。
在小数目上的数据集上训练生成对抗网络的难点在于:判别器网络很容易在训练数据集上过拟合。过拟合之后的判别器网络反向传播给生成器的信息无用,导致整个网络的训练崩了。在基本上所有的深度学习领域,数据集增广方法是一种避免网络过拟合的标准方法。但是这些图像增广应用于生成对抗网络中,会导致网络倾向于学习网络的增广后的分布,本文把这种现象叫做’Augmentation Leak'。
本文探究了如何使用一系列的图像增广方法来防止判别器的过拟合现象,同时应用这些图像增广方法并不会造成增广后的图像引发的生成对抗网络的Augmentation Leak现象。本文首先对于Augmentation Leak进行了一个全面的分析,接着设计了一个广泛的适用于GAN网络的数据增广操作集合,以及一个自适应的增广操作控制策略。
3. GAN中的过拟合现象
要想科学的研究生成对抗网络中的过拟合现象,本文首先研究了用什么数量规模的训练数据集能够支持GAN的训练。本文通过对大型GAN数据集(FFHQ和LSUN CAT)进行比例抽样,探究生成图像的质量变化情况。这里作者采用StyleGAN2作为Baseline模型,理由如下:StyleGAN2模型生成了更可预测的结果,并且在训练时,生成样本的偏差更小。对于Baseline模型,作者随机抽样不同的训练集生成新的子训练集。在FFHQ数据集的操作上,作者将训练集降采样到256*256的尺寸,并且设计了一个更轻量化的网络设置,从而实现了在DGX-1服务器上4.6倍的训练加速。作者通过计算5W张生成图像的FID数值以及原始训练集的样本的FID数据作为质量评估指标。
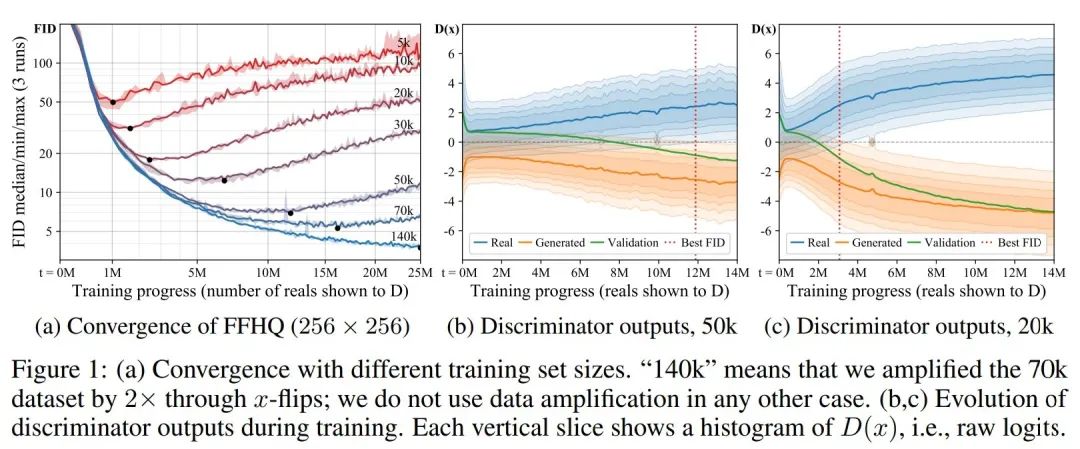
图一展示了本文的对比实验结果:
图1(a)中展示了不同规模的FFHQ数据集子集的生成图像结果。注意(a)图中的黑色点,该点代表生成对抗网络生成的图像质量最优。本文可以看出:训练数据越少,网络的生成图像质量越差;训练时故居越少,生成对抗网络的崩溃点来的越早。 图1(b,c)中展示了训练过程中判别器输出的结果分布,可以看出:本文可以看到,网络的初始阶段,判别器的输出并没有出现明显的误差,伴随着训练的深入,训练集和验证集的overlap越拉越大,这代表网络出现了明显的分布差距。这代表判别器此时已经出现了很严重的过拟合现象。横向比较b,c也可以看出,训练数据越少,过拟合现象越明显。
3.1 随机判别器增广(Stochastic Discriminator Augmentation)

根据[12]所述:任何对于训练集的增广操作都会反映到生成图像上。[43]的工作提出了一个Balanced Consistency Regularization, bCR正则化手段来防止”Augmentation Leakage’。这种consistency regularization方法是希望两组不同的图像增广方法施加在同样的输入图片是,应该得到相同的输出。该方法在判别器的损失中施加了consistency regularization项,强制判别器保持真实图像和生成图像的判断一致性。但这里需要注意,这里的正则化项只施加在判别器,没有施加在生成器上。也就是说:这个consistency regularization项仅仅是让判别器更加鲁棒,让判别器不受图像增广操作的影响(类似昨天推文(加一个link)中防止判别器仅仅识别出进行了图像增广后的图像)。但是,在达到以上目的是,也悄悄打开了Augmentation Leaks的窗口,因为 :生成器将毫无忌惮的生成与数据增广后数据相同的生成图片。
本文的方法与bCR方法类似,本文同样是对输入判别器的图像施加了一系列的图像增广操作。但是:与其简单的添加一个独立的CR loss项,本文仅仅采用增广后的图像进行判别器的评估,并且在训练生成器时,同样采用相同的方法进行生成器的训练。这种方法直接了当,我们称之为:Stochastic Discriminator Augmentation。
这种方法看上去非常的简单粗暴,而且让人怀疑:这种方法都没有让判别器见到真实的训练图像,你确定这玩意能很好地指导生成器生成正确的图像吗?为了打消读者们的疑虑,作者首先针对于这种情况进行了实验,验证了这种方法不会存在Augmentation Leak,并且搭建一个完全的数据pipeline。
3.2 设计一种不会产生泄露的数据增广方法——增加原始图片出现的概率
对判别器的数据增广方法相当于施加了扭曲,目的就是打破判别器的过拟合倾向,让生成器不断地生成有效的训练样本,直到判别器无法区分为止。文献[4]指出:在错误的度量下进行GAN网络的训练,训练得到的网络隐式地消除了损坏,并且找到了正确的分布(只要影像数据的损坏过程能够由一个数据层面的可逆的概率分布变换表示即可)。这一类的数据增广方法在本文中也称之为无泄漏风险(Non-leaking) 的数据增广操作。这一系列的可逆变换的功能在于:他们可以通过观测数据增广后的集合来得出有关基础集合(未增广)的相等性或不等性。这里需要注意的是:可逆变换并不代表我们需要对增广后的图像进行逆变换将其变回原始图片。一方面:以将图片旋转90度为例,这种图像增广方法看似极端,但是对于概率分布来说,这种增广方法是可逆的。但是需要注意:如果我们对于不同种旋转操作集{0度,90度,180度,270度}进行均匀抽样选择一项进行数据增强,此时增广方法就是不可逆的(因为你不知道旋转了多少度数,不知道用哪种逆变换合适)。
但是,这种不可逆的数据增广在执行图像增强的概率小于1时会退化成可逆的变换。当数据增广的执行概率小于1时,相当于增加了原始旋转变换操作集中不进行图像变换的操作被选择的概率。此时,增广后的数据分布将会和原始数据分布保持一致。相似的,很多变换都可以采用相同的策略(提升原始图像出现的概率),进而避免网络无法获知真实的数据分布规律。
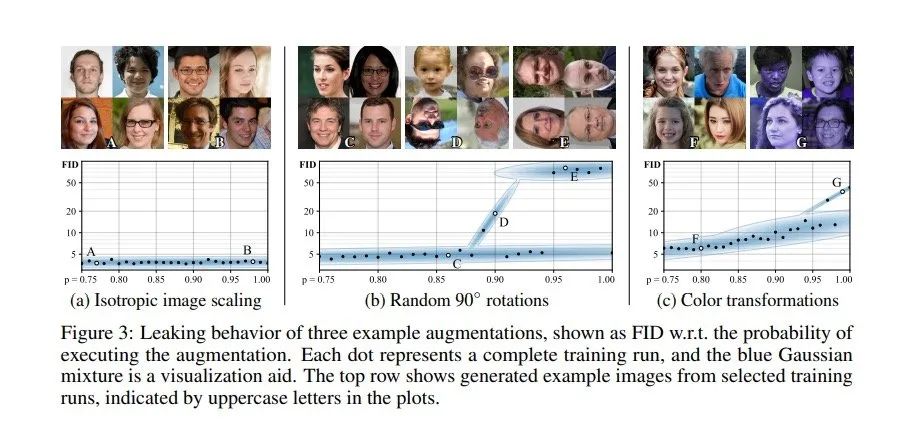
从图3中可以看出实际情况中,不同数据增广过程以及数据增广过程实施的概率对生成对抗网络最终生成图片的影响。我们可以看出:尺度变换是一种安全的数据变换方法,数据增广实施的概率不会影响最终重建的质量;相比之下,对图片进行90度的反转操作是一种较为危险的数据增广方法,在实施操作的概率较大时,网络的性能会出现明显的下降,而伴随着这种数据增广操作的应用比例的减小,网络的性能逐渐恢复;图像的色彩变化对生成对抗网络的影响更加明显,但是我们也可以发现:通过调节实施变换的比例,能够有效提升网络性能。根据以上实验结论可知:把实施“不安全”图像增广操作的概率控制在0.8以下,能够有效提升网络的性能,避免出现Augmentation leak。
3.3 本文提出的数据增广流水线
本文先选择最广泛的数据增广操作,然后根据实验结果逐渐减小数据增广操作的候选范围。本文采用RandAugment[9]操作中的数据增广方法,选取了18种数据变换方法,其中可以分为6大类:1. 像素操作:图像的水平翻转,90度旋转,整数平移;2. 更一般的几何变换;3. 颜色变换;4. 图像空间滤波;5. 图像加性噪声;6. Cutout。这里的数据增广不光应用于判别器的训练,也应用于生成器的训练。因此,本文需要这些变换是可区分的。
在训练阶段,我们将每一个输入判别器的图像施加了一组预先定义的有固定顺序的图像变换方法。其中这些变换的应用概率保持在[0,1]之间。对于变换集中的所有变换方式,我们都采用相同的变换概率p。这里我们对于每一个mini-batch的图片实施的变换集的概率进行随机变化。

根据3.2部分的理论,我们只要保持实际的概率在一定范围内,就不会影响网络对实际概率的学习。同时根据图2(c)钟的图片所示,选取图像增广操作的概率越低,真实图片出现的概率越大,网络也就更不容易被图像增广后的图片干扰。
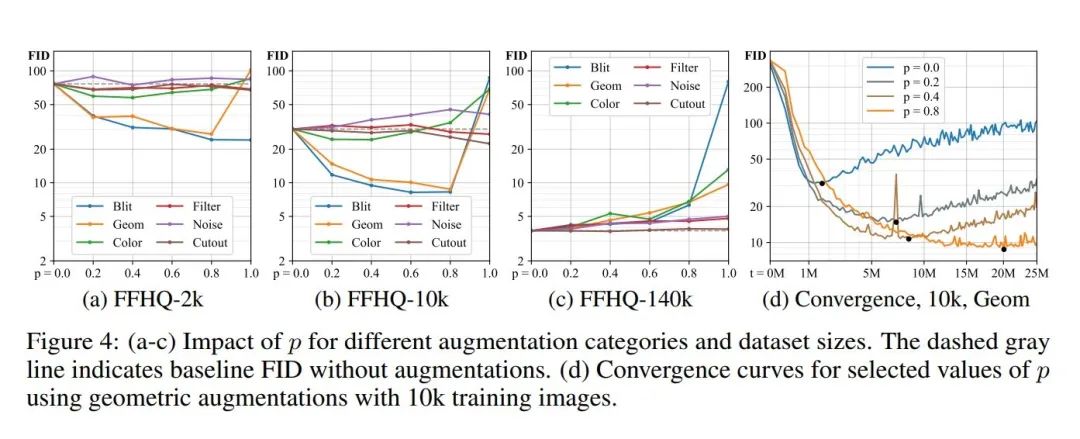
本文在图4中展示了在不同规模的数据集情况下,不同的数据增广方法、不同的数据增广操作集被选取概率对生成对抗网络性能的影响。根据实验结果可以看出,在少量数据集的情况下,数据增广操作的性能提升很大。二在数据集规模逐渐增大时,数据增广的效果反而不够明显。同时我们还发现:在不同规模的数据集上,采用不同的数据增广方法给网络带来的整体增益并不一致。根据以上结果,本文最终选择在模型设计上,仅仅采用“ 像素操作:图像的水平翻转,90度旋转,整数平移”、“几何变换”、“颜色变换”。从图4(d)同样可以看出:较强的数据增广方法(比如CutOut、几何变换)能够有效减少过拟合程度,但是也同样会明显减慢网络的收敛速度。
同时,在实际情况下,对于数据增强概率p这个对数据集敏感、需要经过复杂的调参或是耗时的Grid-Search方法的参数定义过程,依靠固定的p并不是最优选择,因此本文进一步考虑提出自适应判别器数据增强策略。
4. 自适应判别器数据增强策略
自适应的选择判别器数据增强的策略,主要就是需要找到一个调节概率p的参数量,通过不同的过拟合程度动态进行调节。
如图1所示,衡量判别器的过拟合程度可以通过对单独验证集进行判断。当网络出现了过拟合时,验证集越来越表现得像生成器的图像。通过这种现象,可以明确量化出网络的过拟合程度,但是这种现象需要对于本就不多的训练集再进行一次划分,本身就给不够充足的训练集又来了一次致命打击。我们同时还可以看到,StyleGAN2中使用了非饱和损失,判别器输出的数值在网络接近过拟合时会出现生成图像与真实图像在0附近呈现对称分布。
这里我们让:训练集D_train,验证集D_validation和生成图像D_generated表示判别器的输出,以及它们在N个连续小批处理中的平均值E[⋅]。此时,我们可以建模图1中(b)的现象:

根据公式:r=0时代表:网络没有出现过拟合现象;r=1时代表:网络完全过拟合。
r_v计算的是训练集与生成图像的验证集的输出;由于其假设存在单独的验证集,因此我们只将其作为一种比较方法。
r_t用来估计训练集中获得判别器正确判定的部分。
本文在训练的一开始,将p初始化为0,并且根据所选择的描述过拟合程度的描述子,每四个mini-batch更新一次r。如果对应指标r表明过拟合程度过高或者过拟合程度过小,那么对应的调节控制图像增强的p的数值。通过调节p的固定量,p可以从0快速地上升到1。但是当数据量很大时,我们都会将p强制设为0.这种通过网络过拟合程度动态调节对应数据增强过程的操作就成为自适应判别器增强,即Adaptive Discriminator Augmentation (ADA)。
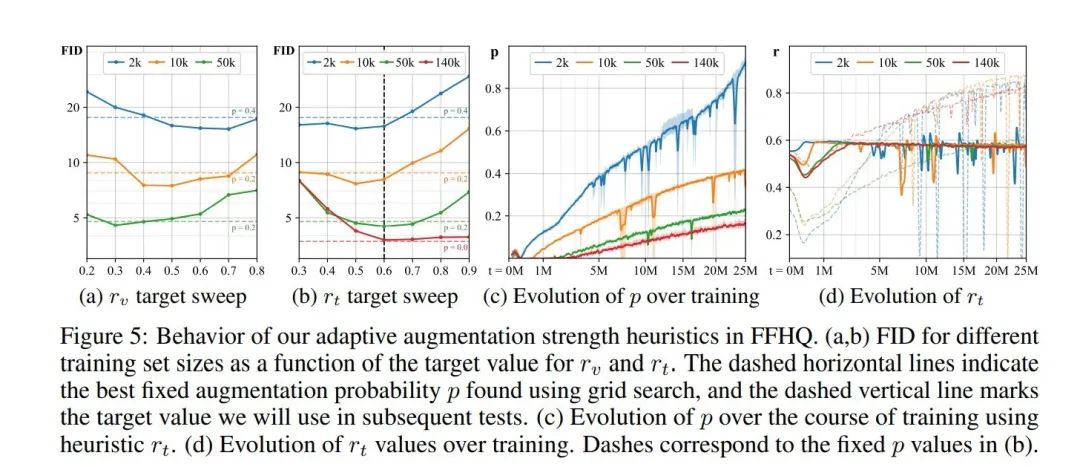
如图5所示。在图5(a), (b)中,我们通过展示r_v与r_t不同取值对网络性能的变化,发现网络可以自动调节图像增强的强度,进而有效的抑制了为网络的过拟合现象。并且我们可以看到,我们的动态变化p的值明显好于网格搜索出的变量值。图5(c)中展示伴随着训练的不断进行,自适应调节的参数P也逐渐递增,这和网络的过拟合风险保持一致。图(d)中展示了:自适应的方法在衡量过拟合成都市,远远好于网格搜索搜出的结果(在网络训练的开始,数据增广用的太猛;在网络的后期,数据增广又使用的不够)。
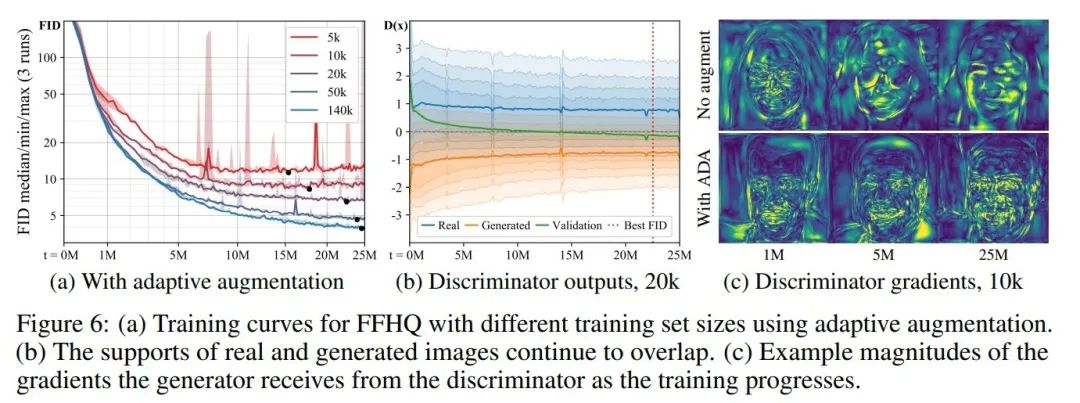
图6展示了:我们使用和图1中相同的实验设置,仅仅采用了ADA策略,我们的数据在不同规模的数据集上都取得了更好的收敛结果,远好于图1时实验的结果。对比图6(c)中我们可以看到,采用了ADA策略的判别器更加关注于符合语义的细节部分。这证明我们的方法的确有效。
5. 实验评估
本文在FFHQ数据集和LSUN Cat数据集上进行了评估。本文同时还比较了从头训练的生成对抗网络和基于预训练模型的生成对抗网络不同的生成效果。
5.1 从头训练的GAN
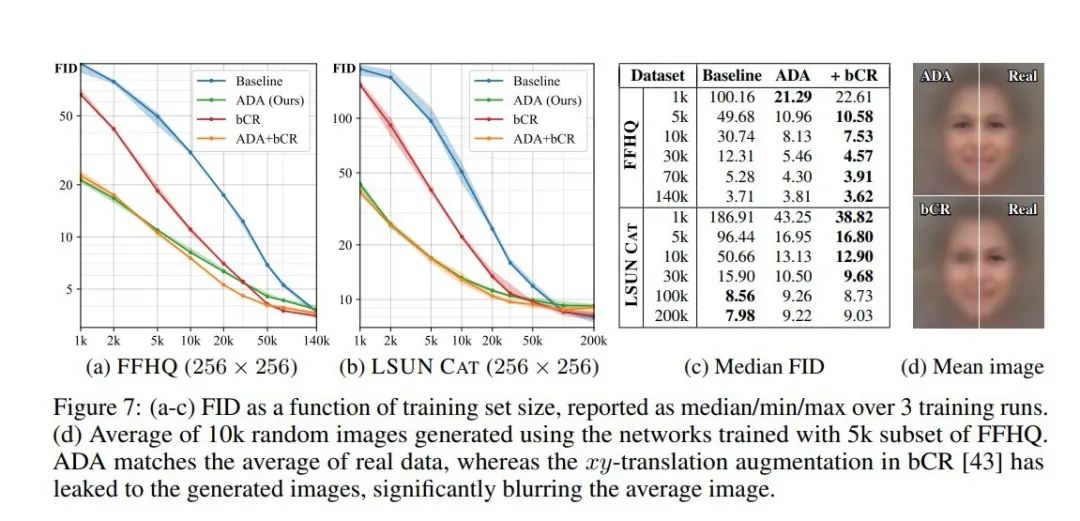
从上图中我们可以看到,在小数据量的情况下,本文的ADA方法在数据集数量极其小时,效果明显。但是我们同时还可以看到bCR方法在数据量适中的情况下,效果也较好。同时还带来了一个有意思的结论:我们同样可以将ADA与bCR方法相加起来,进而能够达到更优的结果。
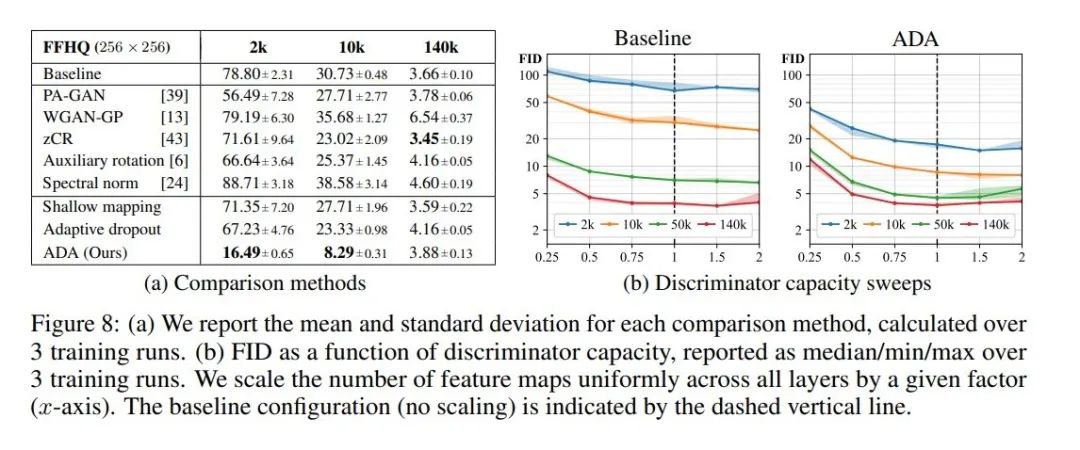
在图8中我们也可以看到,提出的方法在数据集不足的情况下,明显好于其他的对比方法,并且可以说是大幅度优于这些方案。证明本文提出的这一方案是有效的。
5.2 基于预训练模型的GAN
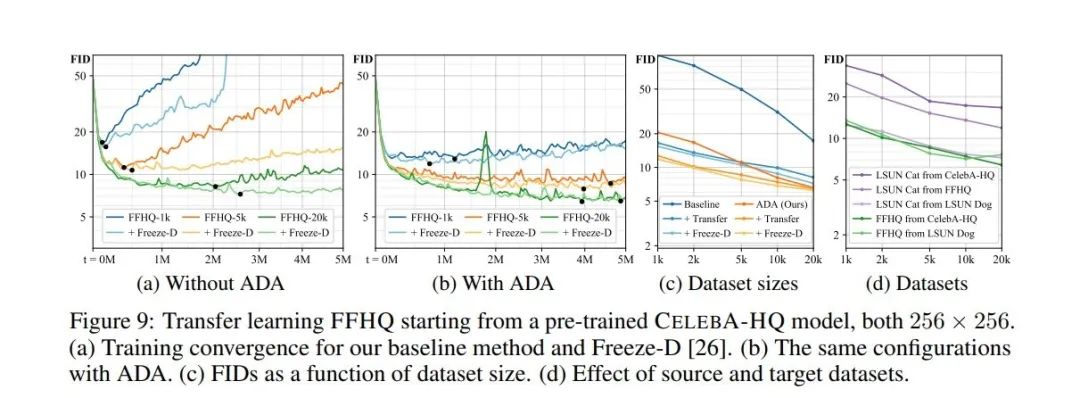
同样在迁移学习的方案上,我们的方法也取得了明显更优的效果,大大增强了生成对抗网络的性能,并且避免了判别器的过拟合问题,Excited!
5.3 小数据集上的图像生成
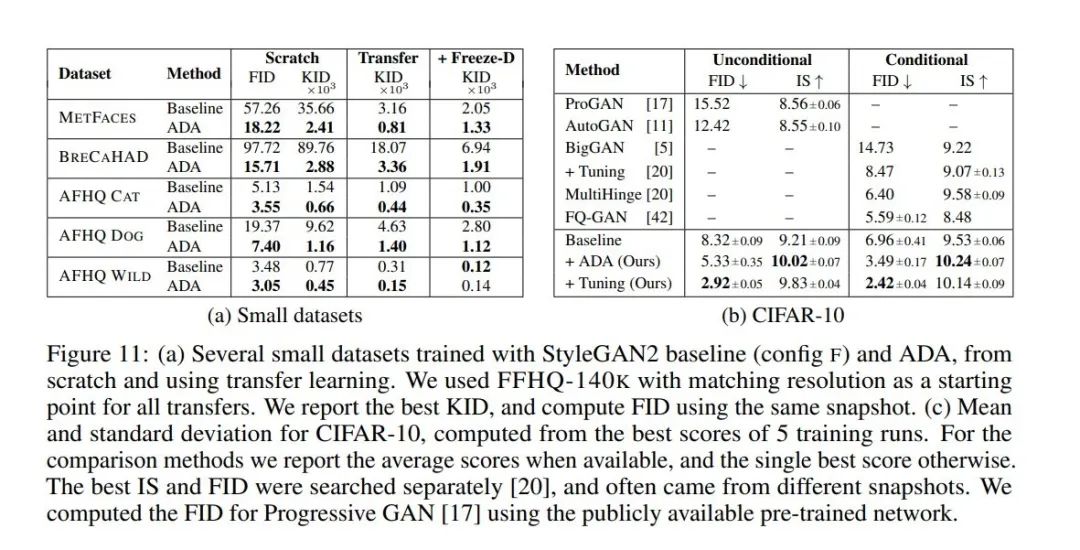
本文还进一步提出了一个受限制大小的训练数据集METFACES,其中包括了1336张高质量的人脸图片。同时本文还采用了医学数据集BRECAHAD、AFHQ数据集进行了图像生成实验。同时,本文甚至还使用了CIFAR-50数据集进行了图像生成的实验。

通过生成结果可以看出,本文提出的方法真的牛逼,生成出来的图片非常逼真。
6. 参考文献
[4] A. Bora, E. Price, and A. Dimakis. AmbientGAN: Generative models from lossy measurements. In Proc. ICLR, 2018.
[12] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial networks. In Proc. NIPS, 2014.
[43] Z. Zhao, S. Singh, H. Lee, Z. Zhang, A. Odena, and H. Zhang. Improved consistency regularization for GANs. CoRR, abs/2002.04724, 2020.
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。