
如何用XGBoost做时间序列预测?
本文约3300字,建议阅读10分钟
XGBoost是用于分类和回归问题的梯度提升集成方法的一个实现。 通过使用滑动时间窗口表示,时间序列数据集可以适用于有监督学习。 在时间序列预测问题上,如何使用XGBoost模型进行拟合、评估、预测。
《机器学习中梯度提升算法的简要概括》
链接:https://machinelearningmastery.com/gentle-introduction-gradient-boosting-algorithm-machine-learning/






《Time Series Forecasting as Supervised Learning》
链接:https://machinelearningmastery.com/time-series-forecasting-supervised-learning/
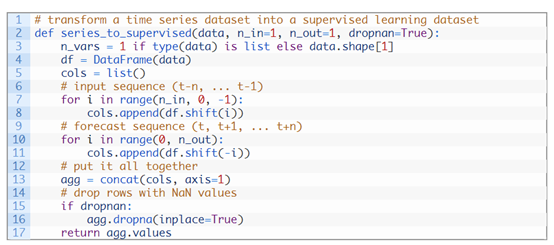
《如何在Python中将时间序列转化为监督学习问题》
链接:https://machinelearningmastery.com/convert-time-series-supervised-learning-problem-python/
《How To Backtest Machine Learning Models for Time Series Forecasting》
链接:https://machinelearningmastery.com/backtest-machine-learning-models-time-series-forecasting/)



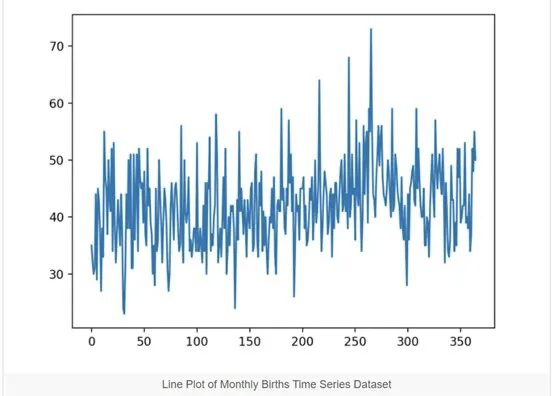
Dataset (daily-total-female-births.csv)
链接:https://raw.githubusercontent.com/jbrownlee/Datasets/master/daily-total-female-births.csv
Description (daily-total-female-births.names)
链接:https://raw.githubusercontent.com/jbrownlee/Datasets/master/daily-total-female-births.names


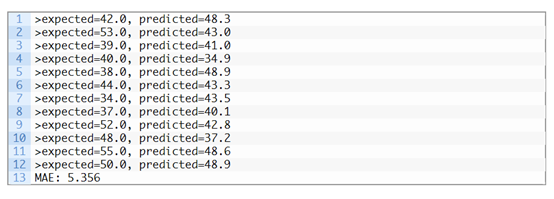
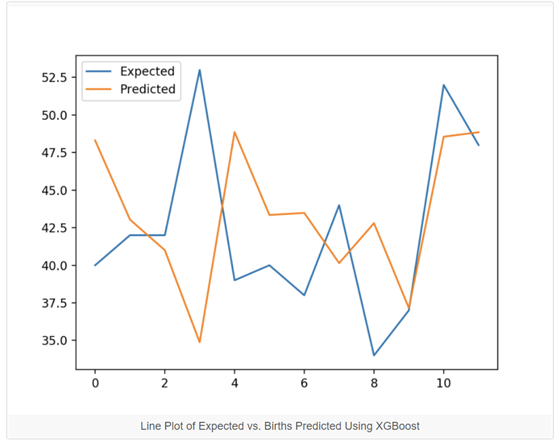
# forecast monthlybirths with xgboostfrom numpy importasarrayfrom pandas importread_csvfrom pandas importDataFramefrom pandas importconcatfrom sklearn.metricsimport mean_absolute_errorfrom xgboost importXGBRegressorfrom matplotlib importpyplot# transform a timeseries dataset into a supervised learning datasetdefseries_to_supervised(data, n_in=1, n_out=1, dropnan=True):n_vars = 1 if type(data) is list elsedata.shape[1]df = DataFrame(data)cols = list()# input sequence (t-n, ... t-1)for i in range(n_in, 0, -1):cols.append(df.shift(i))# forecast sequence (t, t+1, ... t+n)for i in range(0, n_out):cols.append(df.shift(-i))# put it all togetheragg = concat(cols, axis=1)# drop rows with NaN valuesif dropnan:agg.dropna(inplace=True)return agg.values# split a univariatedataset into train/test setsdeftrain_test_split(data, n_test):return data[:-n_test, :], data[-n_test:,:]# fit an xgboost modeland make a one step predictiondef xgboost_forecast(train,testX):# transform list into arraytrain = asarray(train)# split into input and output columnstrainX, trainy = train[:, :-1], train[:,-1]# fit modelmodel =XGBRegressor(objective='reg:squarederror', n_estimators=1000)model.fit(trainX, trainy)# make a one-step predictionyhat = model.predict(asarray([testX]))return yhat[0]# walk-forwardvalidation for univariate datadefwalk_forward_validation(data, n_test):predictions = list()# split datasettrain, test = train_test_split(data,n_test)# seed history with training datasethistory = [x for x in train]# step over each time-step in the testsetfor i in range(len(test)):# split test row into input andoutput columnstestX, testy = test[i, :-1],test[i, -1]# fit model on history and make apredictionyhat = xgboost_forecast(history,testX)# store forecast in list ofpredictionspredictions.append(yhat)# add actual observation tohistory for the next loophistory.append(test[i])# summarize progressprint('>expected=%.1f,predicted=%.1f' % (testy, yhat))# estimate prediction errorerror = mean_absolute_error(test[:, 1],predictions)return error, test[:, 1], predictions# load the datasetseries =read_csv('daily-total-female-births.csv', header=0, index_col=0)values = series.values# transform the timeseries data into supervised learningdata =series_to_supervised(values, n_in=3)# evaluatemae, y, yhat =walk_forward_validation(data, 12)print('MAE: %.3f' %mae)# plot expected vspreductedpyplot.plot(y,label='Expected')pyplot.plot(yhat,label='Predicted')pyplot.legend()pyplot.show()
# finalize model andmake a prediction for monthly births with xgboostfrom numpy importasarrayfrom pandas importread_csvfrom pandas importDataFramefrom pandas importconcatfrom xgboost importXGBRegressor# transform a timeseries dataset into a supervised learning datasetn_in=1, n_out=1, dropnan=True):n_vars = 1 if type(data) is list elsedata.shape[1]df = DataFrame(data)cols = list()# input sequence (t-n, ... t-1)for i in range(n_in, 0, -1):cols.append(df.shift(i))# forecast sequence (t, t+1, ... t+n)for i in range(0, n_out):cols.append(df.shift(-i))# put it all togetheragg = concat(cols, axis=1)# drop rows with NaN valuesif dropnan:=True)return agg.values# load the datasetseries =read_csv('daily-total-female-births.csv', header=0, index_col=0)values = series.values# transform the timeseries data into supervised learningtrain =series_to_supervised(values, n_in=3)# split into input andoutput columnstrainy =train[:, :-1], train[:, -1]# fit modelmodel =XGBRegressor(objective='reg:squarederror', n_estimators=1000)model.fit(trainX,trainy)# construct an inputfor a new preductionrow = values[-3:].flatten()# make a one-steppredictionyhat =model.predict(asarray([row])): %s,Predicted: %.3f' % (row, yhat[0]))

机器学习中梯度提升算法的简要介绍
https://machinelearningmastery.com/gentle-introduction-gradient-boosting-algorithm-machine-learning/
时间序列预测转化为监督学习问题
https://machinelearningmastery.com/time-series-forecasting-supervised-learning/
如何用Python 将时间序列问题转化为有监督学习问题
https://machinelearningmastery.com/convert-time-series-supervised-learning-problem-python/
How To Backtest Machine Learning Models for Time Series Forecasting
https://machinelearningmastery.com/backtest-machine-learning-models-time-series-forecasting/
XGBoost是用于分类和回归的梯度boosting集成算法的实现 时间序列数据集可以通过滑动窗口表示转化为有监督学习。 如何使用XGBoost模型拟合、评估和预测时间序列预测。
原文标题:
How to Use XGBoost for Time Series Forecasting
原文链接:
https://machinelearningmastery.com/xgboost-for-time-series-forecasting/