
基于深度学习的图标型验证码识别系统

| 文件名称 | 文件说明 |
|---|---|
| screenshot/ | 软件截图目录 |
| getData.py | 图像验证码数据采集模块 |
| imageCut.py | 图像验证码数据切分处理模块 |
| dataHelper.py | 模型数据加载预处理模块 |
| myModel.py | 模型训练模块 |
| resnetModel.py | Resnet模块 |
| predict.py | 离线模块预测识别模块 |
| guiDemo.py | 界面可视化模块 |
| texts.txt | 文本标签集合 |
| valid_ip_all.json | IP代理池数据,避免爬虫被封禁 |
| imageModel.h5 | 训练好的图像识别模型文件 |
| textModel.h5 | 训练好的文本识别模块文件 |
#!usr/bin/env python
#encoding:utf-8
from __future__ import division
'''
__Author__:沂水寒城
功能: 网络验证码数据采集模块
'''
def buildProxy():
'''
构建代理信息
'''
header_list=generateRandomUA(num=500)
header={'User-Agent':random.choice(header_list)}
ip_proxy=random.choice(ip_list)
one_type,one_ip,one_port=ip_proxy[0],ip_proxy[1],ip_proxy[2]
proxy={one_type:one_type+'://'+one_ip+':'+one_port}
return header,proxy
def getPageHtml(url,header,proxy,num_retries=3):
'''
多代理形式、超时重试机制,获取数据
'''
try:
response=requests.get(url,headers=header,proxies=proxy,timeout=5)
return response
except Exception as e:
time.sleep(random.randint(3,8))
while num_retries:
num_retries-=1
print('Left tring number is: ', num_retries)
return getPageHtml(url,header,proxy,num_retries)
def getVCPics(img_url,start,end,saveDir):
'''
下载验证码数据
'''
if not os.path.exists(saveDir):
os.makedirs(saveDir)
for i in range(start,end):
print("Downloading",i+1,"......")
header,proxy=buildProxy()
try:
img=getPageHtml(img_url,header,proxy,num_retries=3)
pic_name=saveDir+str(i+1)+'.jpg'
file_pic=open(pic_name,'ab')
file_pic.write(img.content)
file_pic.close()
time.sleep(random.randint(0.1,1))
except:
pass
if __name__ == '__main__':
print('captchaDataCollection!!!')
url="要爬取的验证码链接"
#验证码数据采集
getVCPics(url,0,500,'originalData/play/')



def singleCut(img_path,row,col,cutDir):
'''
单张验证码图像数据切割处理
'''
img=Image.open(img_path)
print('image_shape: ', img.size)
name=img_path.split('/')[-1].strip().split('.')[0].strip()
if not os.path.exists(cutDir):
os.makedirs(cutDir)
w,h=img.size
if row<=h and col<=w:
print('Original image info: %sx%s, %s, %s' % (w,h,img.format,img.mode))
rowheight=h//row
colwidth=w//col
for r in range(row):
for c in range(col):
box=(c*colwidth,r*rowheight,(c+1)*colwidth,(r+1)*rowheight)
if not os.path.exists(cutDir+name+'/'):
os.makedirs(cutDir+name+'/')
num=len(os.listdir(cutDir+name+'/'))
img.crop(box).save(cutDir+name+'/'+str(num)+'.png')
print('Total: ',num)
else:
print('Wrong Parameters!!!')

#截取文字
box=(120,3,177,22) #(左上角坐标,右下角坐标)
res=img.crop(box)
res.save('text.jpg')
res.show()
#截取主体图像数据
box=(0,33,293,190) #(左上角坐标,右下角坐标)
res=img.crop(box)
res.save('image.jpg')
res.show()



打字机
调色板
跑步机
毛线
老虎
安全帽
沙包
盘子
本子
药片
双面胶
龙舟
红酒
拖把
卷尺
海苔
红豆
黑板
热水袋
烛台
钟表
路灯
沙拉
海报
公交卡
樱桃
创可贴
牌坊
苍蝇拍
高压锅
电线
网球拍
海鸥
风铃
订书机
冰箱
话梅
排风机
锅铲
绿豆
航母
电子秤
红枣
金字塔
鞭炮
菠萝
开瓶器
电饭煲
仪表盘
棉棒
篮球
狮子
蚂蚁
蜡烛
茶盅
印章
茶几
啤酒
档案袋
挂钟
刺绣
铃铛
护腕
手掌印
锦旗
文具盒
辣椒酱
耳塞
中国结
蜥蜴
剪纸
漏斗
锣
蒸笼
珊瑚
雨靴
薯条
蜜蜂
日历
口哨
def resnetModel(num_classes,deep=18,h=16,w=10,way=1):
'''
resnet 模型
'''
if deep==18:
model=ResnetBuilder.build_resnet_18((way, h, w), num_classes)
elif deep==34:
model=ResnetBuilder.build_resnet_34((way, h, w), num_classes)
elif deep==50:
model=ResnetBuilder.build_resnet_50((way, h, w), num_classes)
model.compile(optimizer='sgd',loss='categorical_crossentropy',metrics=['accuracy'])
print(model.summary())
return model
def vggModel(num_classes,epochs,x_train,h=16,w=10,way=1):
'''
VGG-16模型
'''
print('x_train.shape: ',x_train.shape)
input_shape=(h,w,way)
model=Sequential()
model.add(Conv2D(64,(3,3),strides=(1,1),input_shape=input_shape,padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(64,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(128,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(128,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform')) #512
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(1024,activation='relu')) #4096
model.add(Dropout(0.5))
model.add(Dense(1024,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes,activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])
print(model.summary())
return model
def selfModel(num_classes,epochs,x_train,h=16,w=10,way=1):
'''
自定义基础模型 sparse_categorical_crossentropy
'''
print('x_train.shape: ',x_train.shape)
input_shape=(h,w,way)
model = models.Sequential([
layers.Conv2D(64, (3, 3), padding='same', activation='relu', input_shape=input_shape),
layers.MaxPooling2D(), # 19 -> 9
layers.Conv2D(64, (3, 3), padding='same', activation='relu'),
layers.MaxPooling2D(), # 9 -> 4
layers.Conv2D(64, (3, 3), padding='same', activation='relu'),
layers.MaxPooling2D(), # 4 -> 2
layers.GlobalAveragePooling2D(),
layers.Dropout(0.25),
layers.Dense(256, activation='relu'),
layers.Dense(num_classes, activation='softmax'),
])
model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])
print(model.summary())
return model
def main(dataDir='dataset/',nepochs=100,h=66,w=66,way=3,deep=18,flag='self',resDir='result/self/'):
'''
主函数
'''
if not os.path.exists(resDir):
os.makedirs(resDir)
X,y=dataHelper.loadDataset(dataDir=dataDir,h=h,w=w)
X=preProcess(X)
y,num_classes=oneHotEncode(y)
#数据集分割
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.30,random_state=7)
#模型定义初始化
if flag=='self':
model=selfModel(num_classes,nepochs,X_train,h=h,w=w,way=way)
elif flag=='vgg':
model=vggModel(num_classes,nepochs,X_train,h=h,w=w,way=way)
else:
model=resnetModel(num_classes,deep=deep,h=h,w=w,way=way)
# 当标准评估停止提升时,降低学习速率
reduce_lr = ReduceLROnPlateau(verbose=1)
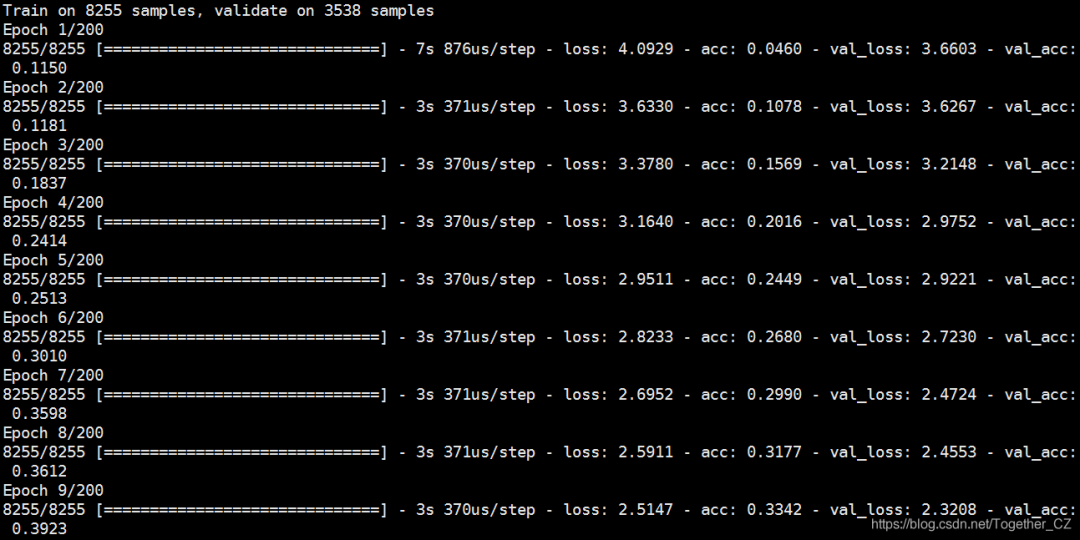
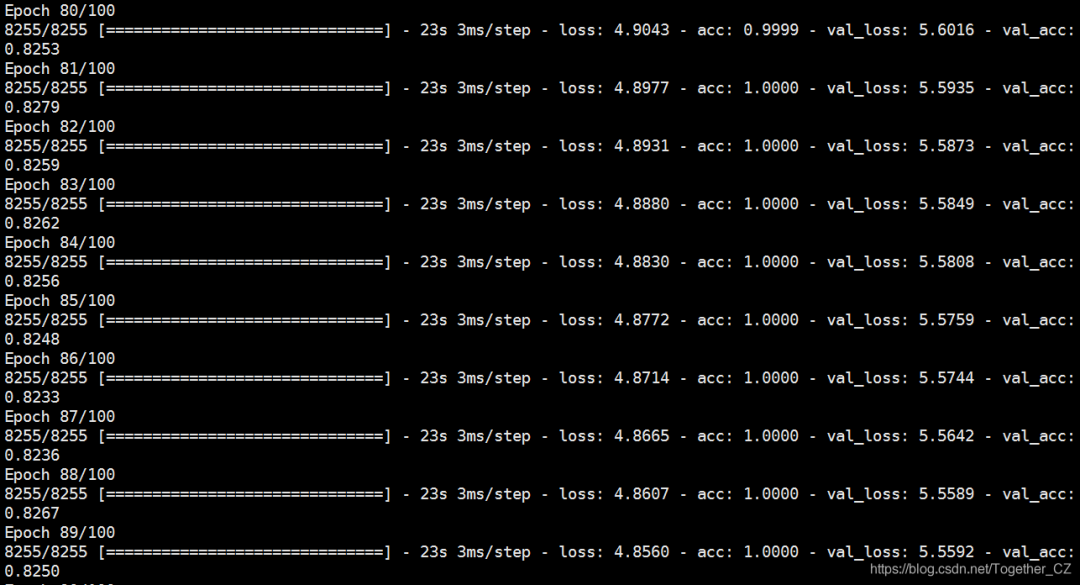
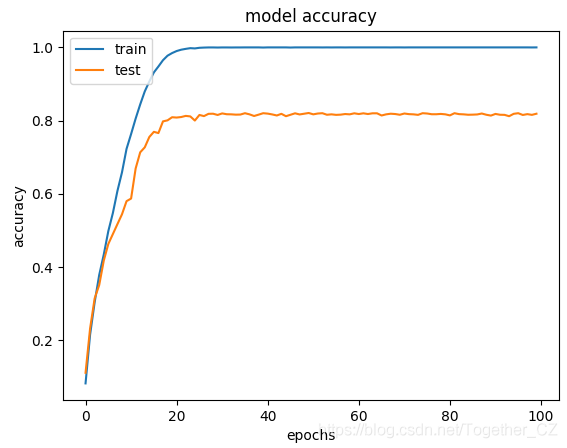
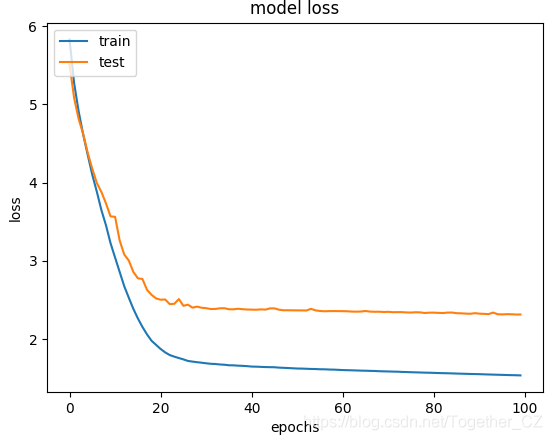
history = model.fit(X_train,y_train,epochs=nepochs,validation_data=(X_test, y_test),callbacks=[reduce_lr])
resHandle(history,resDir,model,X_test,y_test)
print('Finished.....................................................')

def upload_image():
'''
上传图像
'''
try:
file_path=filedialog.askopenfilename()
uploaded=Image.open(file_path)
uploaded.thumbnail(((top.winfo_width()/2.25),(top.winfo_height()/2.25)))
im=ImageTk.PhotoImage(uploaded)
sign_image.configure(image=im)
sign_image.image=im
label.configure(text='')
executeButton(file_path)
except:
pass
upload=Button(top,text=u"点击上传图像",command=upload_image,padx=10,pady=5)
upload.configure(background='#63B8FF', foreground='#364156',font=('arial',20,'bold'))
upload.pack(side=BOTTOM,pady=50)
sign_image.pack(side=BOTTOM,expand=True)
label.pack(side=BOTTOM,expand=True)
heading = Label(top, text=u"12306验证码识别机器人",pady=20, font=('arial',30,'bold'))
heading.configure(background='#40E0D0',foreground='#364156')
heading.pack()
top.mainloop()
使用样例如下:


作者:沂水寒城,CSDN博客专家,个人研究方向:机器学习、深度学习、NLP、CV
Blog: http://yishuihancheng.blog.csdn.net
赞 赏 作 者

更多阅读
特别推荐

点击下方阅读原文加入社区会员
评论