
ACM MM2021 | 探索基于序列特征对齐的域适应目标检测方法

极市导读
本文提出了一种针对Detection Transformer的域适应方法SFA,该工作是探索研究院在Detection Transformer这一热门方向上的首项成果,已经被MultiMedia2021收录。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
视觉模型在跨域场景下的稳定性和鲁棒性是可信人工智能的重要基础,目前京东探索研究院研究员在跨域场景下的目标检测、语义分割等视觉任务上已有多项研究成果[1, 2, 3, 4],这是提升视觉模型在应用场景下的安全性与可靠性的重要步骤。
针对如何提升Detection Transformer的跨域性能这一问题,本文介绍了探索研究院在域适应目标检测(Domain Adaptive Object Detection)领域的一项新工作“Exploring Sequence Feature Alignment for Domain Adaptive Detection Transformers”。该工作是探索研究院在Detection Transformer这一热门方向上的首项成果,已经被MultiMedia2021收录。

论文地址:https://arxiv.org/abs/2107.12636
代码地址:https://github.com/encounter1997/SFA
一、前言
目标检测是计算机视觉中的基本任务之一,具有广泛的运用价值[5]。尽管近年来现有的目标检测算法取得了长足进展,但是它们往往假设测试数据和训练数据采样自相同的数据分布。然而,在现实生活中,由于天气变化、场景变化、图像采集设备的不稳定性等原因,测试数据和训练数据的分布并不一致,其中往往存在域间隔(domain gap)。由于这些问题,如果直接将目标检测器运用到这些场景下,可能会面临性能下降明显的情况。
无监督域适应目标检测领域试图在有标注的源域数据上训练一个能泛化到目标域的目标检测器,以减少人工标注的成本。 近年来,基于Faster RCNN,SSD,FCOS等的无监督域适应目标检测取得了很多进展。随着Vision Transformer[6, 7]和目标检测中Detection Transformer类方法的迅速发展,我们很自然地会希望这类目标检测器也具有跨域目标检测的能力。在这篇文章中我们将针对这一问题进行深入的探讨。
由于现有的域适应目标检测算法大部分是针对特定目标检测器结构的,例如DA-Faster[8]依赖于Faster RCNN中的RPN结构,EPN[9]需要FCOS中的centerness branch,它们并不能直接运用在Detection Transformer上。为此,我们首先探索一个简单的域适应方法:通过对CNN backbone提取的特征做特征分布对齐实现域适应。
如图1(a) 所示,尽管这种方法取得了一定效果,但相比于在transformer的序列特征上做分布对齐,带来的提升十分有限。通过图1(b) 中CNN,encoder(编码器)和decoder(解码器)提取的特征的可视化我们可以看出,在CNN backbone上做特征对齐只能保证CNN基础特征的分布的对齐,而被直接用于分类、定位预测的transformer序列特征上依然存在显著的分布差异。这限制了Detection Transformer的跨域性能。
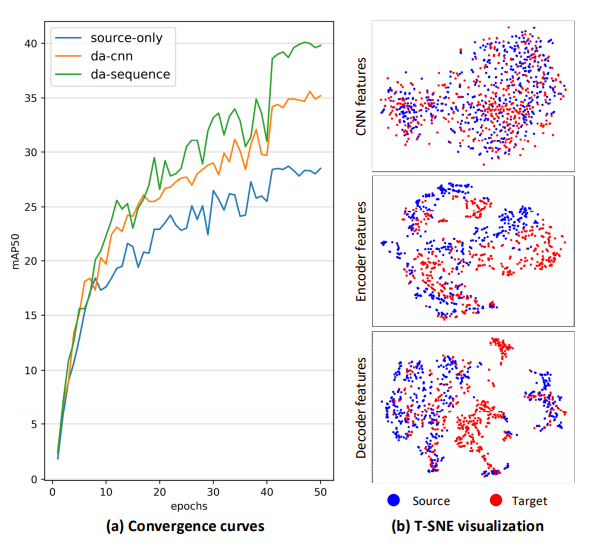
图1 在CNN特征上进行对齐的主客观结果
二、解决方法
基于以上观察,我们提出基于序列特征对齐(Sequence Feature Alignment, SFA) 的域适应方法来提升Detection Transformer的跨域性能。具体来说,它包含基于域查询的序列特征对齐和逐词的序列特征对齐,此外,我们提出二分图匹配一致性约束,进一步提升约束Detection Transformer的序列特征,提升其鲁棒性。我们的Domain Adaptive Detection Transformer整体框架如图2所示。
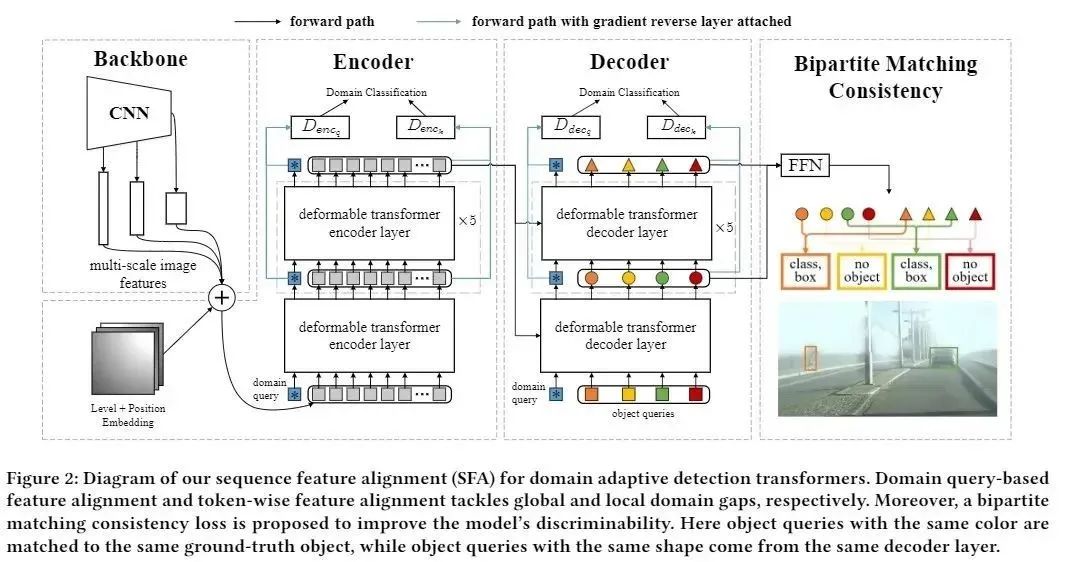
图2 SFA整体框架
基于域查询的序列特征对齐(domain query-based feature alignment) 利用域查询对序列特征中的与域相关的特性做聚合,并在聚合了全局域特性的域查询上做特征对齐,从而在整体上对Transformer序列特征进行对齐。通过在Transformer的encoder和decoder中分别加入域查询token,使得这一方法能够很容易地并用,来对齐encoder和decoder中的序列特征。
值得注意的是,在编码器和解码器端采用这一方法具有不同的意义。具体来说,由于编码器输入的序列特征是由**图像的特征图拉平(flatten)**得到的,此处基于域查询的序列特征对齐从整体上对图像场景布局等层面做迁移。而解码器端的序列特征是由物体查询组成的,此处基于域查询的序列特征对齐是在物体间关系、前景与背景关系等层面上做迁移。
基于域查询的特征对齐只能在全局上对物体间关系和场景布局等层面减少域差异,而不能解决源域和目标域在纹理、风格等细节上的域差异。为了解决这一问题,我们提出对序列特征做逐词的特征对齐(token-wise feature alignment)。同样,该方法也能够很方便的适用于encoder和decoder中不同的序列特征。其中,在编码器端序列中的词代表图片的一块局部区域,因此,此处的逐词的序列特征对齐主要解决图像的局部纹理、表观等层面的差异。而解码器端的词代表物体个体,因此,此处的逐词的序列特征对齐是在图像的前景物体个体层面做特征对齐(类似于DA-Faster中的instance-level feature alignment)。
同时,为了实现更全面的特征对齐,我们采用渐进特征对齐,由浅层到深层,对Transformer编码器各层的输出逐一做特征对齐。
Detection Transformer采用二分图匹配将模型的输出与图像中的物体或背景进行一一对应。由于目标域上没有标签做监督,目标检测器容易在目标域上产生不准确的匹配。为此,我们对不同解码器层的输出做集成,并约束不同解码器层的输出,以产生一致的二分图匹配来实现更准确的检测。
值得注意的是,我们的方法不局限于Detection Transformer结构,而是可以广泛运用在此类目标检测器上,如DETR[5],Deformable DETR[6]。
我们从域适应和泛化性两个角度对SFA的跨域性能进行了理论分析,分析表明,我们的SFA能够显著提升Detection Transformer的跨域性能。
三、实验结果
在实验部分,我们考虑了三种常见的域适应场景,即天气域适应(Cityscapes to Foggy Cityscapes),合成数据到真实数据域适应(Sim10k to Cityscapes)和场景域适应(Cityscapes to BDD100k daytime)。我们的方法在这三种场景下的结果如下表所示。可以看到,我们的方法能够在跨域场景下取得SOTA性能,超越基于Faster RCNN或基于FCOS的域适应方法。同时,我们的方法相比于Source only Deformable DETR基线性能有显著提升。
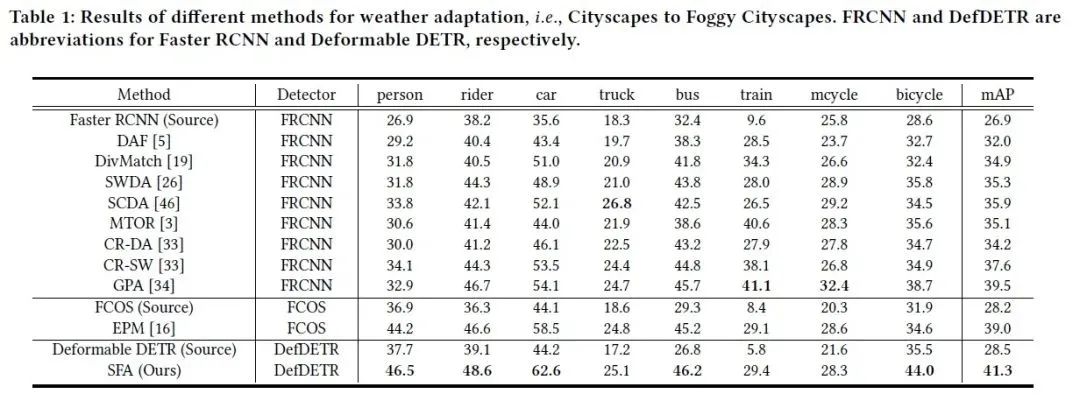
表1 天气域适应(Cityscapes to Foggy Cityscapes)实验结果
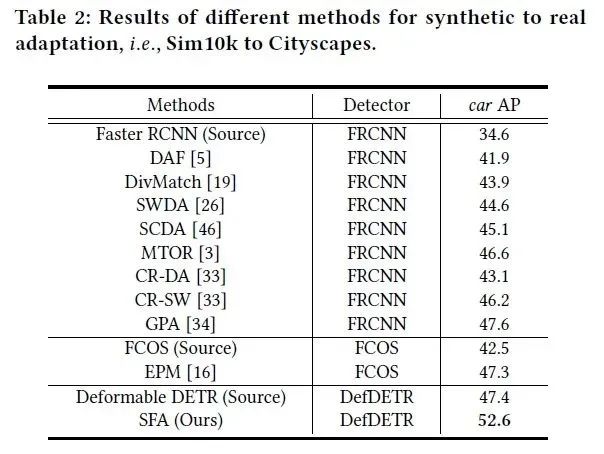
表2 合成数据到真实数据域适应(Sim10k to Cityscapes)实验结果
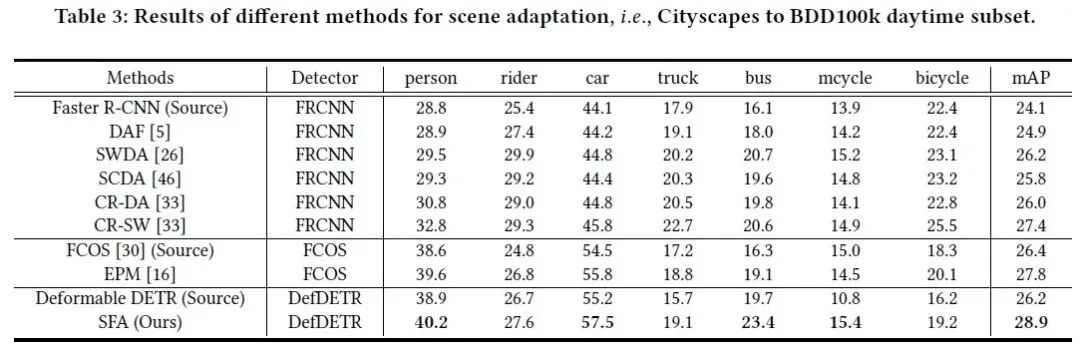
表3 场景域适应(Cityscapes to BDD100k daytime)实验结果
此外,为了深入理解SFA中每个模块的作用,我们对SFA中的主要组件——基于域查询的序列特征对齐(DQ),逐词的特征对齐(TW),二分图匹配一致性约(BMC)和层级式特征对齐(HR)做消融实验。结果如下表所示。
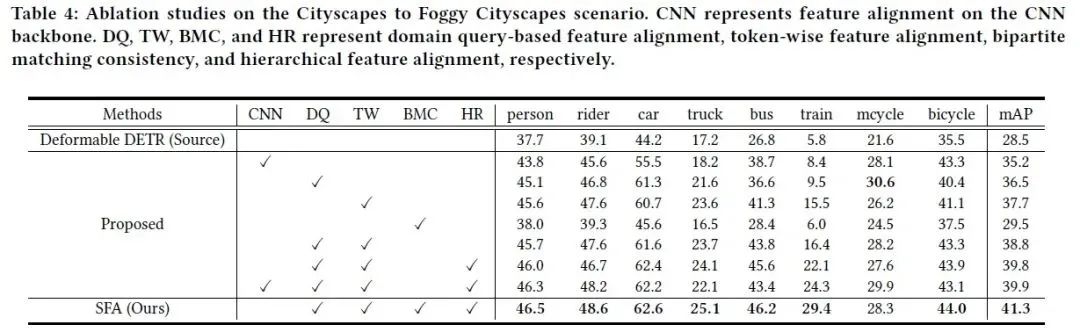
表4 消融实验实验结果
可以看出,我们的各个模块中,基于域查询的序列特征对齐和逐词的特征对齐均能显著提升模型的跨域性能,并且二者是互补的。而二分图匹配一致性和层级式特征对齐能够进一步提升模型的整体性能。
在附加材料中,我们将SFA运用到DETR上来提升其跨域性能,得到的结果如下表所示。
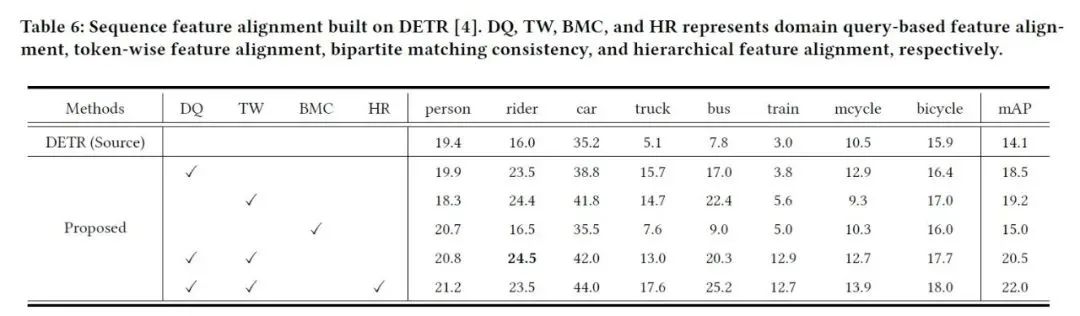
表5 在DETR上运用SFA实验结果
由于DETR相较于Deformable DETR有更少的先验(如稀疏采样),其依赖更多的数据来训练,导致其在Cityscapes to Foggy Cityscape上性能不佳(14.1 mAP50)。尽管如此,我们的方法能够显著提升其跨域性能,提升7.9 mAP50(相对提升56%)。
最后我们对SFA模型的输出以及特征进行可视化,包含:
1. 在不同跨域场景下的主观结果可视化,如图3所示。

图3 SFA模型在不同跨域场景下的主观结果可视化
2. CNN特征,encoder和decoder特征分布的可视化,如图4所示。 可以看出,在不同域的序列特征的分布均已对齐,并且受益于渐进式特征对齐,CNN提取的特征也已对齐。
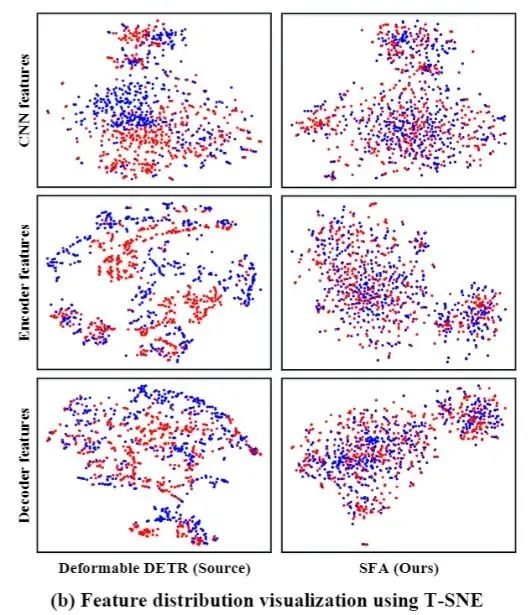
图4 SFA模型特征可视化
3. 对domain query关注区域的可视化,如图5所示。 可以看到,domain query的主要权重出现在图像的上半部分雾比较浓(域差异显著)的区域。

图5 对domain query关注区域的可视化
四、总结与展望
本文提出了一种针对Detection Transformer的域适应方法SFA,其中主要包含基于域查询的序列特征对齐(DQFA)、逐词的序列特征对齐(TDA)和二分图匹配一致性损失,该方法的有效性已经通过实验和理论分析进行证明。希望我们的SFA能够成为基于Detection Transformer的域适应目标检测方法的基线。论文和代码已开源,欢迎大家关注。
参考文献:
[1] Zhang Q, Zhang J, Liu W, et al. Category anchor-guided unsupervised domain adaptation for semantic segmentation[J]. arXiv preprint arXiv:1910.13049, 2019.
[2] Gao L, Zhang J, Zhang L, et al. DSP: Dual Soft-Paste for Unsupervised Domain Adaptive Semantic Segmentation[J]. arXiv preprint arXiv:2107.09600, 2021.
[3] He F, Liu T, Tao D. Control batch size and learning rate to generalize well: Theoretical and empirical evidence[J]. Advances in Neural Information Processing Systems, 2019, 32: 1143-1152.
[4] He F, Liu T, Tao D. Why resnet works? residuals generalize[J]. IEEE transactions on neural networks and learning systems, 2020, 31(12): 5349-5362.
[5] Zhang J, Tao D. Empowering things with intelligence: a survey of the progress, challenges, and opportunities in artificial intelligence of things[J]. IEEE Internet of Things Journal, 2020, 8(10): 7789-7817.
[6] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
[7] Xu Y, Zhang Q, Zhang J, et al. ViTAE: Vision Transformer Advanced by Exploring Intrinsic Inductive Bias[J]. arXiv preprint arXiv:2106.03348, 2021.
[8] Chen Y, Li W, Sakaridis C, et al. Domain adaptive faster r-cnn for object detection in the wild[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 3339-3348.
[9] Hsu C C, Tsai Y H, Lin Y Y, et al. Every pixel matters: Center-aware feature alignment for domain adaptive object detector[C]//European Conference on Computer Vision. Springer, Cham, 2020: 733-748.
Illustrastion__by Natasha Remarchuk from Icons8_\
The End
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
