
南京大学提出量化特征蒸馏方法QFD | 完美结合量化与蒸馏,让AI落地更进一步!!!
点击下方卡片,关注「集智书童」公众号
本文首发于 【集智书童】,白名单账号转载请自觉植入本公众号名片并注明来源,非白名单账号请先申请权限,违者必究。

神经网络量化旨在通过使用低位近似加速和修剪全精度神经网络模型。采用量化感知训练(QAT)范式的方法最近有了快速增长,但往往在概念上较为复杂。
本文提出了一种新颖而高效的QAT方法,即量化特征蒸馏(QFD)。QFD首先将量化(或二值化)表示作为教师进行训练,然后使用知识蒸馏(KD)对网络进行量化。
定量结果表明,QFD比先前的量化方法更灵活且更有效(即更适合量化)。QFD在图像分类和目标检测上的性能超过了现有方法,尽管它的实现要简单得多。
此外,QFD在MS-COCO检测和分割上对ViT和Swin-Transformer进行了量化,证明了它在实际部署中的潜力。据作者所知,这是第一次将视觉Transformer应用于目标检测和图像分割任务并进行量化处理。
1、简介
网络量化是将全精度(FP)网络的权重和激活转换为它们的定点近似,而不会出现明显的准确性下降。最近,已经提出了各种方法,而量化感知训练(QAT)由于在极低比特设置下仍能恢复网络准确性的能力而成为一种成熟的范式。
现代QAT方法基于一个通用原理:使用任务损失来优化量化区间(参数)。许多变体已经被提出,例如非均匀量化、复杂梯度近似或手动设计的正则化。这些方法往往较为复杂,而简单性常常受到牺牲。另一类QAT方法将知识蒸馏引入到量化阶段。
虽然量化知识蒸馏的思想很简单(即使用全精度教师来帮助恢复量化学生网络的准确性),但实现却包括启发式随机精度、手动定义的辅助模块或多个阶段。所有这些方法都依赖于logit蒸馏,因此很难应用于其他计算机视觉任务(例如目标检测)。
在本文中,作者提出了一种针对网络量化的新颖、简单且有效的蒸馏方法,即量化特征蒸馏(QFD)。作者的动机来自于Wu和Luo(2018)的一个重要结果:仅将FP模型的输出特征进行二值化就可以实现与全FP模型相似或更好的准确性。因此,使用这些量化特征作为教师信号来帮助量化其余部分的网络(即学生)将是有优势的。
一方面,特征蒸馏与logit蒸馏相比在任务上更加灵活,特别是在像目标检测这样的任务中;另一方面,可以自然地推测,对于完全量化的学生来说,模仿定点特征表示会比直接模仿浮点数logits或特征更容易。

换句话说,所提出的QFD将更加灵活且更有效(对量化友好)。这个推测(以及作者提出QFD的动机)在图1中得到了说明,并且在图2和表1中得到了实验证据的支持。

这些实验证实了作者的动机,采用ResNet-18在CIFAR100数据集上使用了4种不同的量化方法:
-
量化基准(不使用KD的均匀量化器)
-
logit蒸馏(logits作为教师信号)
-
特征蒸馏(FP特征作为教师信号)
-
QFD(量化特征作为教师信号)
所有3种蒸馏方法都采用与基准相同的量化器,而在QFD中,教师的特征被二值化(1位)。
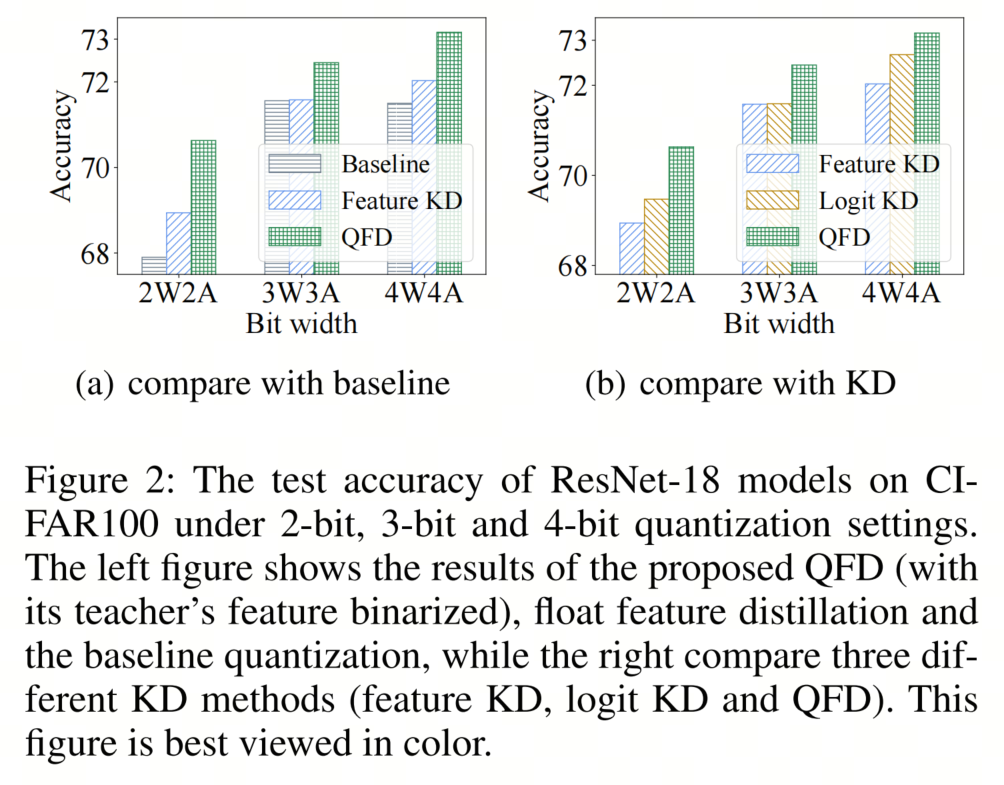
如图2所示,QFD不仅优于浮点特征蒸馏,而且在所有设置中都超过了logit蒸馏。QFD相比基准的改进也是一致的,并且足够大,可以恢复全精度模型的准确性(3位和4位)。作者进一步使用QFD将教师的特征量化为4位和8位。如表1所示,所有特征蒸馏方法都优于基准。随着教师的位宽降低,教师模型的准确性下降,但最终蒸馏结果一直得到改进。这些结果表明,作者的动机是有效的:量化特征对于网络量化来说是更好的教师!
作者不仅在分类任务上测试了QFD,还在检测和分割任务中进行了测试,并在不同网络结构(ResNet、MobileNet和ViT)上实现了最先进的准确性。作者的贡献可以总结如下:
-
一种新颖的量化感知训练蒸馏方法,易于实现。
-
在分类、检测和分割基准测试中相比先前的量化感知训练方法具有显著的准确性优势。
-
在常见的目标检测和分割任务中首次尝试对视觉Transformer结构进行量化处理。
2、相关工作
神经网络量化可以分为两种范式:
-
量化感知训练(QAT)
-
后训练量化(PTQ)
在本文中,作者采用了QAT。在本节中,作者将描述QAT中的基础知识、知识蒸馏以及视觉Transformer。
2.1、量化感知训练
QAT是一种强大的范式,可以在不显著降低准确性的情况下处理低比特(例如3位或4位)量化。将量化操作整合到计算图中是QAT的关键,这样权重和量化参数可以通过反向传播同时学习。早期在这个领域的方法关注如何将模型二值化、用统计信息拟合量化器或最小化局部误差,但它们都存在不完整或次优的问题。
现代的QAT方法采用优化量化区间的原则与任务损失,并采用更复杂的技术,包括非均匀量化器、梯度近似或额外的正则化。然而,它们的简洁性和有效性仍然是重要的挑战。
2.2、量化中的知识蒸馏
知识蒸馏(KD)在各种计算机视觉任务中很受欢迎,并逐渐在量化感知训练中出现。量化知识蒸馏的核心思想是:利用全精度教师来恢复量化学生网络的准确性。然而,最近的方法缺乏简洁性,因为它们涉及复杂的阶段、辅助模块和专门的混合精度调整。
此外,这些方法都采用logit蒸馏,当应用于目标检测量化时不够灵活。相反,作者提出了作者的量化特征蒸馏(QFD),在准确性方面对量化友好,而在流水线设计方面更加灵活。
2.3、量化视觉Transformer
视觉Transformer(ViT)已经在许多视觉任务中取得了重大进展,因此迫切需要将其精确量化以便促进其实际使用。最近的方法尝试使用后训练量化技术将ViT量化为6位或8位,但仅限于图像分类。
对于低比特(3位或4位)量化以及ViT及其变体在检测和分割任务中的适用性,尚未进行探索。作者将首次通过探索所有这些设置和任务中的量化性能来回答这两个问题。
3、本文方法
作者在引言中揭示了所提出的QFD方法的动机,图2和表1中的结果不仅支持了这一动机,而且初步验证了QFD的有效性。在介绍了神经网络量化的初步内容(作者使用的QATBaseline)后,作者将继续详细描述作者提出的方法。
3.1、准备工作
作者采用了Lee,Kim和Ham的方法作为基准方法,该方法是由归一化、量化和反量化步骤组成的均匀量化器。
对于给定的全精度数据
(神经网络中某一层的权重或激活),作者定义量化参数
和
,它们分别表示量化区间的下界和上界。归一化步骤如下:
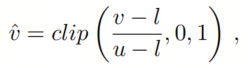
其中,
函数用于将数据裁剪到
和
范围之间。然后,使用量化函数:
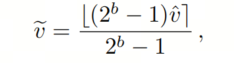
其中,
是取整函数,
表示量化的位宽。操作
将
从[0,1]范围映射到
的离散数值。最后,应用反量化步骤输出量化后的权重
或激活
:
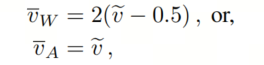
其中,量化后的权重
大致关于零对称,而量化后的激活
考虑了ReLU激活函数的正性。作者使用可训练的缩放参数α与输出的量化激活相乘。
在训练过程中,作者采用直通估计器(STE)来近似取整操作的梯度为1:
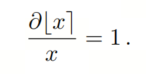
模型的权重和这些量化参数通过反向传播同时学习。
3.2、量化特征蒸馏
作者首先定义量化感知训练中的基本符号表示,然后介绍作者的量化特征蒸馏方法,如图3所示。对于给定的图像I,首先将其送入特征提取器
(例如Backbone网络,如CNN或ViT),以获得全精度特征向量
(通常通过全局平均池化获得)。
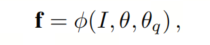
其中
是特征维度,
和
分别表示模型的权重参数和量化参数。特征
经过分类器,得到最终logit概率向量
,其中
是类别数,同时生成交叉熵损失
,其中
是真实的类别标签。参数
和
通过反向传播来学习。
对于作者提出的QFD方法,图像I分别被送入教师网络
和学生网络
,分别得到特征
和
。教师网络的全精度特征
将被量化为较低比特(例如,1比特或4比特)表示:
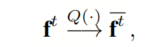
其中,量化器
的定义见方程(1)-(4)。特征量化器
遵循初步介绍中描述的激活量化过程。
然后,教师网络的量化特征作为监督信号,通过均方损失
来指导学生网络的量化,而学生网络仍然使用其通常的交叉熵损失
与真实标签
进行训练。整体优化目标为:
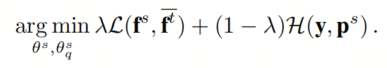
其中
用于平衡蒸馏损失和交叉熵损失的重要性。为简单起见,作者设置
,除非在消融实验中另有说明。
4、实验
4.1、分类结果
1、CIFAR10/100
作者首先在CIFAR10和CIFAR100上使用ResNet模型验证作者提出的QFD方法。其中,CIFAR10包含50000张训练图像和10000张验证图像,而CIFAR100在类别细分上比CIFAR10更细致,有100个类别。
对于CIFAR10上的ResNet-20模型(结果在表2中展示),作者运行了Baseline、特征知识蒸馏(Feature KD)、logit蒸馏(Logit KD)以及作者提出的量化特征蒸馏方法(QFD)。作者将ResNet-20的权重和激活量化为2比特、3比特和4比特("W/A")。遵循之前的工作,作者对除Backbone网络输入和最后的全连接层(即分类器)以外的所有层进行量化。
和
均采用logit蒸馏方法,而LQ-Net是一种量化感知训练方法。

如表2所示,作者的QFD在精度上远远超过之前的知识蒸馏量化方法
和
,并且优于Feature KD和Logit KD。值得注意的是,在3比特(92.64%)和4比特(93.07%)设置下,作者的QFD甚至比全精度模型的精度还要高。
作者还在CIFAR100上使用ResNet-18和ResNet-32验证作者的QFD方法。与CIFAR10上的实验类似,作者重新实现了Baseline、特征蒸馏和logit蒸馏方法。
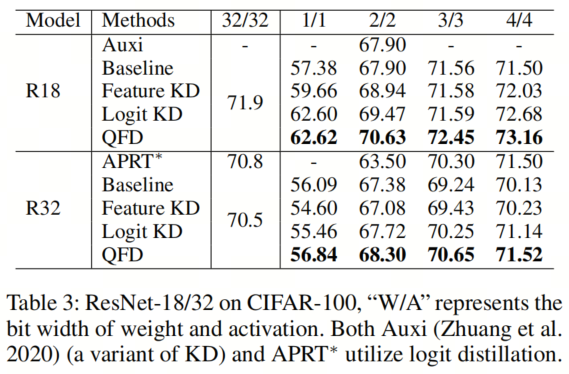
如表3所示,Feature KD和Logit KD通常优于Baseline,显示了知识蒸馏的优势。作者的QFD在所有方法中都表现更好,特别是在极低比特情况下(1比特和2比特)。对于ResNet-18和ResNet-32,在2、3、4比特上,作者的方法几乎可以恢复全精度模型的准确性。尤其对于1比特的ResNet-32,只有作者的QFD相比Baseline有所改进(56.84% vs 56.09%)。
2、ImageNet
作者在ImageNet1k数据集上将作者提出的QFD与其他量化感知训练方法进行了比较,结果见表4。

在不同比特设置下,作者提出的量化特征蒸馏方法在ResNet-18、ResNet-34和MobileNetV2模型上均超过了之前的方法(包括其他知识蒸馏方法SPEQ、QKD和Auxi)。
值得注意的是,Auxi使用了手动设计的辅助模块,SPEQ需要对随机精度进行经验探索,而QKD涉及更大的教师模型(例如,使用ResNet-50来蒸馏ResNet-34)。相比之下,作者的方法在概念上更简单,准确性更高,尤其对于MobileNetV2,作者的QFD大幅超越了QKD(在2比特、3比特和4比特量化设置下,分别增加了7.1%、3.8%和3.1%)。
对于ResNet系列模型,在3比特和4比特量化下,作者的QFD完美地恢复了全精度的Top-1准确率(4比特的ResNet-34达到了74.7%的Top-1准确率,甚至超过了其全精度版本1.3%)。与此同时,由于MobileNetV2的通道差异较大,特别是在低比特下恢复其准确性相对较困难,正如Nagel等人(2021年)所指出的。但是作者的QFD仍然比其他方法更优秀。
3、CUB200 with ViT
作者还在图像分类基准CUB200上对视觉Transformer进行量化,该数据集包含200个鸟类别,其中有5994张图像用于训练,5794张图像用于测试。
具体来说,作者将多层感知机(MLP)和多头注意力(MHA)中的线性层量化为3比特或4比特,使用ViT和Deit的不同结构,包括ViT Small、ViT Base、Deit Tiny、Deit Small和Deit Base。作者还列出了使用量化特征的教师网络的准确性(这是作者QFD方法的预处理步骤)。

如表5所示,尽管仅对特征进行量化会导致原始FP模型的轻微准确性下降,但QFD方法对Baseline模型的改进显著且一致。但是,4比特和FP模型之间仍存在差距。量化Transformer仍然是一个具有挑战性的任务。
4.2、目标检测
RetinaNet是一种单阶段目标检测器,由Backbone网络、FPN和检测头组成。在MS-COCO数据集上,作者使用提出的QFD方法将其所有层量化为4比特和3比特(包括跳跃连接中的卷积操作),但不包括Backbone网络输入和检测头的输出。遵循之前的工作,作者使用全精度模型(表6中的FP)对量化训练进行微调。
对于教师网络,作者首先将其输出特征在p3级别量化为8比特,因为在FPN图中它包含了最多的梯度流,然后将其用作蒸馏学生RetinaNet的量化特征。经验上,作者发现利用所有FPN级别(包括p3、p4、p5、p6、p7)的量化特征,这是目标检测蒸馏中的常见方法,可以获得类似的准确性,但不稳定。
为简单起见,作者只使用p3进行特征蒸馏,并且不涉及任何复杂的操作,例如区分前景和背景特征。量化特征蒸馏损失占总检测损失的约1/5,RetinaNet的结构严格遵循之前的量化工作。
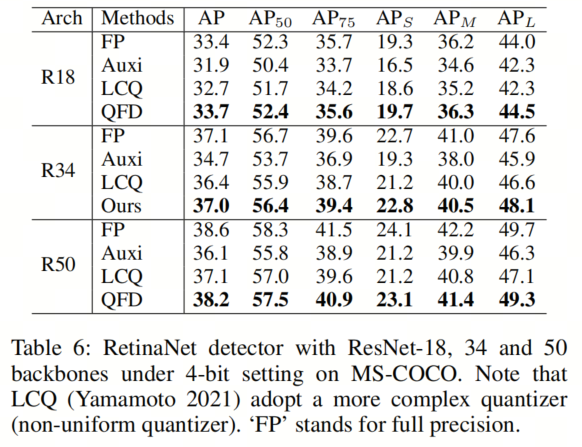
表6显示了将RetinaNet量化为4比特的结果。作者的QFD(使用ResNet18/34/50作为Backbone网络)大幅超过了之前的方法。特别是对于ResNet-18,作者的QFD甚至超过了其全精度对应物(
、
和
分别提高了0.3%、0.4%和0.5%)。对于ResNet-34,与全精度相比,作者的准确性下降几乎可以忽略不计,
和
分别略微降低了0.1%和0.2%。

表7显示了将RetinaNet量化为3比特的结果。与4比特量化不同,3比特更具挑战性,由于其有限的表示能力,更难优化。经验上,作者发现ResNet-34经常面临不稳定的训练问题,因此作者延长了其预热迭代次数,同时保持总的训练迭代次数不变。
总体上,作者的QFD相对于之前的最先进方法表现更优,尤其是对于ResNet-18,在APM和APL方面相对于LCQ的提高分别为0.7%和2.2%。
4.3、ViT架构
最后,作者探索了对ViT进行量化。据作者所知,这是第一次对ViT在检测和分割任务中进行量化。作者使用了在ImageNet1k和ImageNet21k上使用自监督学习方法MAE预训练的ViT和Swin Transformer。
检测流程遵循新发布的ViTDet。由于大多数参数位于Backbone Transformer块中MLP和MHA的线性层,作者只量化Backbone中的线性层,并在8、6、4比特设置下运行Baseline量化(不包括QFD蒸馏)。
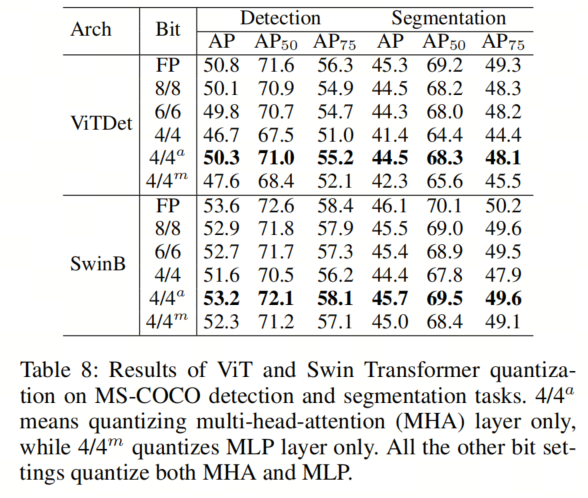
如表8所示,对ViT和Swin Transformer(SwinB表示其基础结构)的线性层进行8比特或6比特量化基本足以恢复其在检测和分割任务上的准确性,这表明在真实世界的硬件设备上部署视觉Transformer的潜力。相反,将视觉Transformer量化为4比特会导致明显的性能下降,可能是由于其有限的表示能力。
作者进一步通过交替量化每个层(仅量化MHA或MLP)来分析MHA和MLP的影响,表8中的结果传达了一个有趣的观察结果:在检测和分割中对视觉Transformer进行量化对注意力层不敏感,而对MLP中的线性层敏感。
值得注意的是,ViT和SwinB中的4/4a性能甚至超过了其8/8对应物。这可能是因为MLP层受到LayerNorm输入的通道间变化的严重影响,而MHA层包含额外的操作,可能有助于缓解这种影响。
4.4、消融实验
1、效果验证:
和特征量化
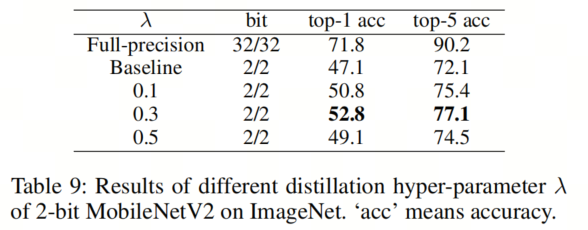

作者验证了公式(8)中定义的唯一超参数λ在ImageNet和CUB数据集上,在不同比特设置下(2比特、3比特和4比特)的效果。结果可以在表9至表11中找到。对于CNN和不同数据集上的视觉Transformer,所有
值都导致了比Baseline量化方法的改进,而且作者的方法对于
的值并不敏感。有
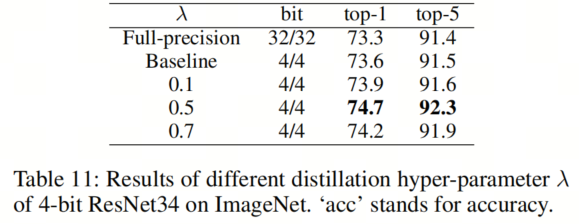
趣的是,在表11中(ImageNet上4比特的ResNet-34量化),即使Baseline量化方法的准确性已经超过了全精度模型,作者的QFD仍然进一步提高了1.1%的Top-1准确性。因此,为了简单起见,作者可以默认选择λ = 0.5。
2、特征量化的影响

同时,作者展示了教师网络的准确性(使用其特征量化)。如表12所示,特征量化的教师网络在准确性方面几乎与原始模型没有区别。因此,准确性的提高是由QFD带来的,而不是因为教师网络的准确性高于Baseline模型。
3、检测结果的一致改进

最后,在这一部分中,作者绘制了在MS-COCO检测任务中使用Baseline量化或作者的QFD蒸馏的RetinaNet的收敛曲线。在3比特量化下,使用ResNet-18和ResNet-50 Backbone的结果可以在图4中找到。毫无疑问,QFD在整个训练过程中都比Baseline有持续的改进,证明了作者方法的普适性:它不仅适用于分类任务,而且还能提高目标检测的性能。
5、参考
[1].Quantized Feature Distillation for Network Quantization.
6、推荐阅读
华为诺亚实验室提出CFT | 大模型打压下语义分割该何去何从?或许这就是答案!
UNet家族最强系列 | UNet、UNet++、TransUNet与SWin-UNet究竟哪个更强!!!
南开大学提出YOLO-MS | 超越YOLOv8与RTMDet,即插即用打破性能瓶颈

扫码加入👉「集智书童」交流群
(备注:方向+学校/公司+昵称)




前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!