
梯度下降是门手艺活
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


极市导读
梯度下降法作为大家耳熟能详的优化算法,极易理解。但虽然和的一些方法比起来在寻找优化方向上比较轻松,可是这个步长却需要点技巧。本文作者通过简单的函数举例说明梯度下降中容易出现的问题。
本文收录在无痛的机器学习第一季(https://zhuanlan.zhihu.com/p/22464594)。
机器学习所涉及的内容实在是太多了,于是我决定挑个软柿子捏起,从最基础的一个优化算法开始聊起。这个算法就是梯度下降法,英文Gradient Descent。
什么是梯度下降法
作为大众耳熟能详的优化算法,梯度下降法受到的关注不要太多。梯度下降法极易理解,但凡学过一点数学的童鞋都知道,梯度方向表示了函数增长速度最快的方向,那么和它相反的方向就是函数减少速度最快的方向了。对于机器学习模型优化的问题,当我们需要求解最小值的时候,朝着梯度下降的方向走,就能找到最优值了。
那么具体来说梯度下降的算法怎么实现呢?我们先来一个最简单的梯度下降算法,最简单的梯度下降算法由两个函数,三个变量组成:
函数1:待求的函数
函数2:待求函数的导数
变量1:当前找到的变量,这个变量是“我们认为”当前找到的最好的变量,可以是函数达到最优值(这里是最小值)。
变量2:梯度,对于绝大多数的函数来说,这个就是函数的负导数。
变量3:步长,也就是沿着梯度下降方向行进的步长。也是这篇文章的主角。
我们可以用python写出一个最简单的梯度下降算法:
def gd(x_start, step, g): # gd代表了Gradient Descentx = x_startfor i in range(20):grad = g(x)x -= grad * stepprint '[ Epoch {0} ] grad = {1}, x = {2}'.format(i, grad, x)if abs(grad) < 1e-6:break;return x关于python的语法在此不再赘述了,看不懂得童鞋自己想办法去补课吧。
优雅的步长
好了,算法搞定了,虽然有点粗糙,但是对于一些问题它是可以用的。我们用一个简单到爆的例子来尝试一下:
def f(x):return x * x - 2 * x + 1def g(x):return 2 * x - 2
这个函数f(x)就是大家在中学喜闻乐见的,大家一眼就可以看出,最小值是x=1,这是函数值为0。为了防止大家对这个函数没有感觉(真不应该没感觉啊……)我们首先把图画出来看一下:
import numpy as npimport matplotlib.pyplot as pltx = np.linspace(-5,7,100)y = f(x)plt.plot(x, y)然后我们就看到了:
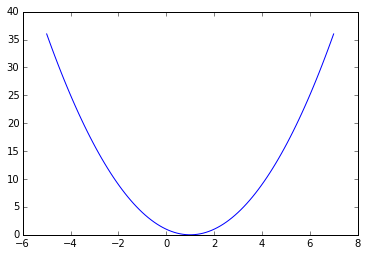
一个很简单的抛物线的函数有木有?x=1是最小点有木有?
来让我用梯度下降法计算一下:
gd(5,0.1,g)于是我们得到了下面的输出:
[ Epoch 0 ] grad = 8, x = 4.2
[ Epoch 1 ] grad = 6.4, x = 3.56
[ Epoch 2 ] grad = 5.12, x = 3.048
[ Epoch 3 ] grad = 4.096, x = 2.6384
[ Epoch 4 ] grad = 3.2768, x = 2.31072
[ Epoch 5 ] grad = 2.62144, x = 2.048576
[ Epoch 6 ] grad = 2.097152, x = 1.8388608
[ Epoch 7 ] grad = 1.6777216, x = 1.67108864
[ Epoch 8 ] grad = 1.34217728, x = 1.536870912
[ Epoch 9 ] grad = 1.073741824, x = 1.4294967296
[ Epoch 10 ] grad = 0.8589934592, x = 1.34359738368
[ Epoch 11 ] grad = 0.68719476736, x = 1.27487790694
[ Epoch 12 ] grad = 0.549755813888, x = 1.21990232556
[ Epoch 13 ] grad = 0.43980465111, x = 1.17592186044
[ Epoch 14 ] grad = 0.351843720888, x = 1.14073748836
[ Epoch 15 ] grad = 0.281474976711, x = 1.11258999068
[ Epoch 16 ] grad = 0.225179981369, x = 1.09007199255
[ Epoch 17 ] grad = 0.180143985095, x = 1.07205759404
[ Epoch 18 ] grad = 0.144115188076, x = 1.05764607523
[ Epoch 19 ] grad = 0.115292150461, x = 1.04611686018
可以看到,经过20轮迭代,我们从初始值x=5不断地逼近x=1,虽然没有完全等于,但是在后面的迭代中它会不断地逼近的。
好像我们已经解决了这个问题,感觉有点轻松啊。高兴之余,突然回过神来,那个步长我设的好像有点随意啊,迭代了20轮还没有完全收敛,是不是我太保守了,设得有点小?俗话说的好,人有多大胆,地有多大产。咱们设个大点的数字,让它一步到位!(豪迈的表情)
gd(5,100,g)这回设得够大了,来看看结果:
[ Epoch 0 ] grad = 8, x = -795
[ Epoch 1 ] grad = -1592, x = 158405
[ Epoch 2 ] grad = 316808, x = -31522395
[ Epoch 3 ] grad = -63044792, x = 6272956805
[ Epoch 4 ] grad = 12545913608, x = -1248318403995
[ Epoch 5 ] grad = -2496636807992, x = 248415362395205
[ Epoch 6 ] grad = 496830724790408, x = -49434657116645595
[ Epoch 7 ] grad = -98869314233291192, x = 9837496766212473605
[ Epoch 8 ] grad = 19674993532424947208, x = -1957661856476282247195
[ Epoch 9 ] grad = -3915323712952564494392, x = 389574709438780167192005
[ Epoch 10 ] grad = 779149418877560334384008, x = -77525367178317253271208795
[ Epoch 11 ] grad = -155050734356634506542417592, x = 15427548068485133400970550405
[ Epoch 12 ] grad = 30855096136970266801941100808, x = -3070082065628541546793139530395
[ Epoch 13 ] grad = -6140164131257083093586279060792, x = 610946331060079767811834766548805
[ Epoch 14 ] grad = 1221892662120159535623669533097608, x = -121578319880955873794555118543211995
[ Epoch 15 ] grad = -243156639761911747589110237086423992, x = 24194085656310218885116468590099187205
[ Epoch 16 ] grad = 48388171312620437770232937180198374408, x = -4814623045605733558138177249429738253595
[ Epoch 17 ] grad = -9629246091211467116276354498859476507192, x = 958109986075540978069497272636517912465605
[ Epoch 18 ] grad = 1916219972151081956138994545273035824931208, x = -190663887229032654635829957254667064580655195
[ Epoch 19 ] grad = -381327774458065309271659914509334129161310392, x = 37942113558577498272530161493678745851550384005
我去,这是什么结果!不但没有收敛,反而数字越来越大!这是要把python的数字撑爆的节奏啊!(实际上python的数字没这么容易撑爆的……)
需要冷静一下……为什么会出现这样的情况?不是说好了是梯度下降么?怎么还会升上去?这个问题就要回到梯度这个概念本身来。
实际上梯度指的是在当前变量处的梯度,对于这一点来说,它的梯度方向是这个方向,我们也可以利用泰勒公式证明在一定的范围内,沿着这个梯度方向走函数值是会下降的。但是,从函数中也可以看出,如果一步迈得太大,会跳出函数值下降的范围,反而会使函数值越变越大,造成悲剧。
如何避免这种悲剧发生呢?简单的方法就是将步长减少,像我们前面那样设得小点。另外,还有一些Line-search的方法可以避免这样的事情发生,这些方法以后有机会在慢慢聊。
现在,我们要镇定一下,看样子我们只能通过修改步长来完成这个问题了。这时候我们可以开一个脑洞:既然小步长会让优化问题收敛,大步长会让优化问题发散,那么有没有一个步长会让优化问题原地打转呢?
我们还是从x=5出发,假设经过一轮迭代,我们求出了另一个x值,再用这个值迭代,x值又回到了5。我们用中学的数学能力建一个方程出来:
x=5, g(x)=8, 新的值x'=5 - 8 * step
g(x')=2 * (5-8*step) - 2,回到过去:x' - g(x') * step = x = 5
合并公式求解得,step=1
也就是说step=1时,求解会原地打转,赶紧试一下:
gd(5,1,g)
[ Epoch 0 ] grad = 8, x = -3
[ Epoch 1 ] grad = -8, x = 5
[ Epoch 2 ] grad = 8, x = -3
[ Epoch 3 ] grad = -8, x = 5
[ Epoch 4 ] grad = 8, x = -3
[ Epoch 5 ] grad = -8, x = 5
[ Epoch 6 ] grad = 8, x = -3
[ Epoch 7 ] grad = -8, x = 5
[ Epoch 8 ] grad = 8, x = -3
[ Epoch 9 ] grad = -8, x = 5
[ Epoch 10 ] grad = 8, x = -3
[ Epoch 11 ] grad = -8, x = 5
[ Epoch 12 ] grad = 8, x = -3
[ Epoch 13 ] grad = -8, x = 5
[ Epoch 14 ] grad = 8, x = -3
[ Epoch 15 ] grad = -8, x = 5
[ Epoch 16 ] grad = 8, x = -3
[ Epoch 17 ] grad = -8, x = 5
[ Epoch 18 ] grad = 8, x = -3
[ Epoch 19 ] grad = -8, x = 5
果然不出我们所料,打转了……
好了,现在我们基本明白了,当步长大于1会出现求解发散,而小于1则不会,那么对于别的初始值,这个规则适用么?
gd(4,1,g)
[ Epoch 0 ] grad = 6, x = -2
[ Epoch 1 ] grad = -6, x = 4
[ Epoch 2 ] grad = 6, x = -2
[ Epoch 3 ] grad = -6, x = 4
[ Epoch 4 ] grad = 6, x = -2
[ Epoch 5 ] grad = -6, x = 4
[ Epoch 6 ] grad = 6, x = -2
[ Epoch 7 ] grad = -6, x = 4
[ Epoch 8 ] grad = 6, x = -2
[ Epoch 9 ] grad = -6, x = 4
[ Epoch 10 ] grad = 6, x = -2
[ Epoch 11 ] grad = -6, x = 4
[ Epoch 12 ] grad = 6, x = -2
[ Epoch 13 ] grad = -6, x = 4
[ Epoch 14 ] grad = 6, x = -2
[ Epoch 15 ] grad = -6, x = 4
[ Epoch 16 ] grad = 6, x = -2
[ Epoch 17 ] grad = -6, x = 4
[ Epoch 18 ] grad = 6, x = -2
[ Epoch 19 ] grad = -6, x = 4
果然试用,这样一来,我们可以“认为”,对于这个优化问题,采用梯度下降法,对于固定步长的算法,步长不能超过1,不然问题会发散!
好了,下面我们换一个函数:,对于这个问题,它的安全阈值是多少呢?不罗嗦了,是0.25:
def f2(x):return 4 * x * x - 4 * x + 1def g2(x):return 8 * x - 4gd(5,0.25,g2)
[ Epoch 0 ] grad = 36, x = -4.0
[ Epoch 1 ] grad = -36.0, x = 5.0
[ Epoch 2 ] grad = 36.0, x = -4.0
[ Epoch 3 ] grad = -36.0, x = 5.0
[ Epoch 4 ] grad = 36.0, x = -4.0
[ Epoch 5 ] grad = -36.0, x = 5.0
[ Epoch 6 ] grad = 36.0, x = -4.0
[ Epoch 7 ] grad = -36.0, x = 5.0
[ Epoch 8 ] grad = 36.0, x = -4.0
[ Epoch 9 ] grad = -36.0, x = 5.0
[ Epoch 10 ] grad = 36.0, x = -4.0
[ Epoch 11 ] grad = -36.0, x = 5.0
[ Epoch 12 ] grad = 36.0, x = -4.0
[ Epoch 13 ] grad = -36.0, x = 5.0
[ Epoch 14 ] grad = 36.0, x = -4.0
[ Epoch 15 ] grad = -36.0, x = 5.0
[ Epoch 16 ] grad = 36.0, x = -4.0
[ Epoch 17 ] grad = -36.0, x = 5.0
[ Epoch 18 ] grad = 36.0, x = -4.0
[ Epoch 19 ] grad = -36.0, x = 5.0
好了,这个故事讲完了。为什么要讲这个故事呢?
这个故事说明了梯度下降法简单中的不简单(划重点啊),虽然和的一些方法比起来在寻找优化方向上比较轻松,可是这个步长真心需要点技巧,即使这样一个一维的优化问题都有这些问题,对于现在大火的深度学习,CNN优化(没错,说得就是你),一个base_lr基础学习率+gamma学习衰减率真的可以轻松跳过像上面这样的坑么?说实话还是需要一定的尝试才能找到感觉。
最后多说一句,对于上面的一元二次函数,有没有发现步长阈值和二阶导数的关系呢?
本文的全部代码可以在https://github.com/hsmyy/zhihuzhuanlan/blob/master/gd.ipynb阅览。
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!