
AI首次赢得填字游戏比赛冠军,纵横字谜新霸主也将诞生? | 留言赠书

新智元报道
新智元报道
编辑:小乖熊
【新智元导读】「美国纵横字谜锦标赛」刚刚落下帷幕,人工智能Dr. Fill首次在纵横字谜中战胜人类并获得胜利。尽管如此,该领域人工智能的发展面仍临着诸多挑战,人类依然被认为在解决现实世界问题方更佳现更佳。

填字游戏是一种「约束满足问题(CSP)」

两种AI算法的完美结合
Dr.Fill有没有可能更快?
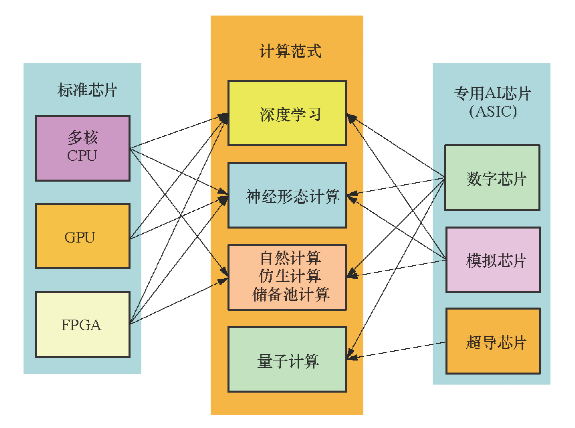
AI芯片的发展步伐

CPU
GPU
FPGA
ASIC
图书信息
书名:AI芯片:前沿技术与创新未来
作者:张臣雄
书号:9787115553195
出版社:人民邮电出版社

AI家,新天地。西山新绿,新智元在等你!
【新智元高薪诚聘】主笔、高级编辑、商务总监、运营经理、实习生等岗位,欢迎投递简历至wangxin@aiera.com.cn (或微信: 13520015375)
办公地址:北京海淀中关村软件园3号楼1100

评论